Beyond Noisy-TVs: Noise-Robust Exploration Via Learning Progress Monitoring
Pith reviewed 2026-05-18 11:47 UTC · model grok-4.3
The pith
Intrinsic rewards based on learning progress let agents explore past unlearnable noise sources instead of getting stuck on them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
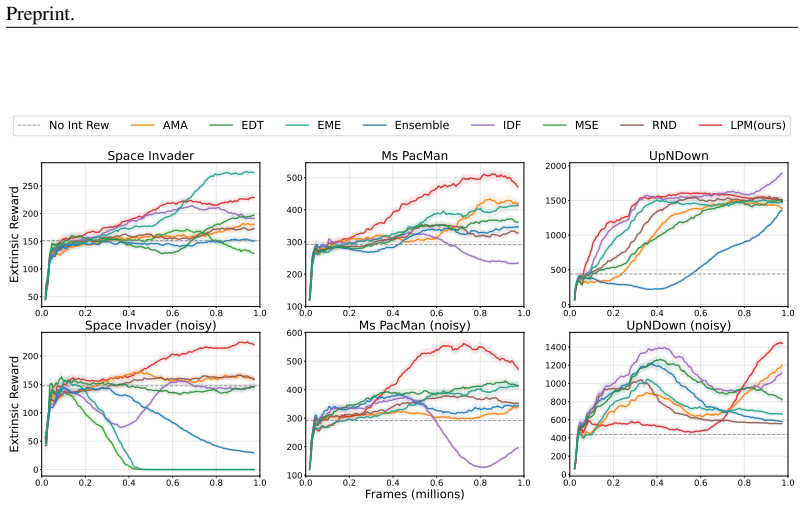
LPM defines the intrinsic reward as the difference between the current iteration's dynamics-model error and the error that an auxiliary error model predicts for the previous iteration. The resulting signal is shown to be zero-equivariant and a monotone indicator of information gain; the error model is required to preserve this monotonic correspondence. Consequently the agent is directed toward learnable transitions while ignoring unlearnable noisy ones, producing more efficient exploration in stochastic settings.
What carries the argument
Dual-network architecture in which an error model predicts the dynamics model's prior error so that their difference supplies the intrinsic reward signal.
If this is right
- Intrinsic reward converges faster than uncertainty or novelty baselines.
- Agents visit more distinct states in image-based maze environments.
- Higher extrinsic task reward is obtained in noisy Atari settings.
- Exploration succeeds without explicit handling of each noise source.
Where Pith is reading between the lines
- The same progress signal could be applied to partially observable or real-robot tasks that contain sensor noise.
- Replacing absolute-error rewards with difference rewards may reduce the sample complexity of curiosity-driven training at scale.
- The necessity of the auxiliary model suggests that any future progress-based method will need a comparable tracking network.
Load-bearing premise
The auxiliary error model can reliably forecast the dynamics model's expected prediction error from the previous iteration.
What would settle it
A controlled test in which the LPM reward fails to increase monotonically with independently measured information gain on learnable versus noisy transitions would disprove the claimed correspondence.
Figures



read the original abstract
When there exists an unlearnable source of randomness (noisy-TV) in the environment, a naively intrinsic reward driven exploring agent gets stuck at that source of randomness and fails at exploration. Intrinsic reward based on uncertainty estimation or distribution similarity, while eventually escapes noisy-TVs as time unfolds, suffers from poor sample efficiency and high computational cost. Inspired by recent findings from neuroscience that humans monitor their improvements during exploration, we propose a novel method for intrinsically-motivated exploration, named Learning Progress Monitoring (LPM). During exploration, LPM rewards model improvements instead of prediction error or novelty, effectively rewards the agent for observing learnable transitions rather than the unlearnable transitions. We introduce a dual-network design that uses an error model to predict the expected prediction error of the dynamics model in its previous iteration, and use the difference between the model errors of the current iteration and previous iteration to guide exploration. We theoretically show that the intrinsic reward of LPM is zero-equivariant and a monotone indicator of Information Gain (IG), and that the error model is necessary to achieve monotonicity correspondence with IG. We empirically compared LPM against state-of-the-art baselines in noisy environments based on MNIST, 3D maze with 160x120 RGB inputs, and Atari. Results show that LPM's intrinsic reward converges faster, explores more states in the maze experiment, and achieves higher extrinsic reward in Atari. This conceptually simple approach marks a shift-of-paradigm of noise-robust exploration. For code to reproduce our experiments, see https://github.com/Akuna23Matata/LPM_exploration
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a new intrinsic motivation method called Learning Progress Monitoring (LPM) to enable robust exploration in environments with unlearnable noise sources (noisy-TVs). LPM uses a dual-network architecture where an error model predicts the dynamics model's previous prediction error, and the difference between current and previous errors serves as the intrinsic reward, focusing on learnable transitions. The authors claim to theoretically demonstrate that this reward is zero-equivariant and monotonically corresponds to Information Gain (IG), with the error model being essential for this property. Empirically, LPM is shown to outperform baselines in noisy MNIST, a 3D maze with RGB inputs, and Atari games by achieving faster reward convergence, more state exploration, and higher extrinsic rewards.
Significance. This work could be significant for the field of intrinsically motivated reinforcement learning if the theoretical results hold, as it offers a noise-robust alternative to uncertainty or novelty-based methods with potentially better sample efficiency. The empirical results in complex domains like Atari support its practical value. Explicitly providing code for reproduction strengthens the contribution by enabling verification.
major comments (2)
- [Abstract] The theoretical result that the LPM intrinsic reward is zero-equivariant and a monotone indicator of IG, along with the necessity of the error model for monotonicity, is stated without any proof details, equations, or lemmas. This is a load-bearing claim for the paper's central contribution and requires detailed derivation to allow verification.
- [Abstract] The empirical claims of faster convergence, more states explored in the maze, and higher extrinsic reward in Atari lack specific quantitative metrics, tables, or ablation results, making it difficult to assess the magnitude and reliability of the improvements over state-of-the-art baselines.
minor comments (1)
- The abstract contains a minor grammatical issue with 'shift-of-paradigm' which should be 'paradigm shift'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comments point by point below, with plans to revise the manuscript for improved clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] The theoretical result that the LPM intrinsic reward is zero-equivariant and a monotone indicator of IG, along with the necessity of the error model for monotonicity, is stated without any proof details, equations, or lemmas. This is a load-bearing claim for the paper's central contribution and requires detailed derivation to allow verification.
Authors: We agree that the abstract summarizes the theoretical claims at a high level without derivations. The full manuscript contains a dedicated theoretical analysis section deriving the zero-equivariance property of the LPM reward and its monotonic correspondence to Information Gain, including a formal proof that the error model is required for monotonicity (via a counterexample showing non-monotonicity without it). To address the concern, we will revise the manuscript to include a concise proof sketch with key equations and lemmas in the main text (e.g., in a new subsection or highlighted box), while retaining full details in the appendix. This ensures the central contribution is more readily verifiable. revision: yes
-
Referee: [Abstract] The empirical claims of faster convergence, more states explored in the maze, and higher extrinsic reward in Atari lack specific quantitative metrics, tables, or ablation results, making it difficult to assess the magnitude and reliability of the improvements over state-of-the-art baselines.
Authors: The abstract offers a qualitative overview of the results. The complete manuscript includes detailed experimental sections with tables providing quantitative metrics (means and standard deviations over multiple seeds), such as specific improvements in convergence speed, number of unique states visited in the maze, and extrinsic rewards in Atari, along with ablation studies comparing variants. We will revise the abstract to incorporate representative quantitative highlights (e.g., percentage gains or key values) and ensure these metrics are prominently referenced in the introduction and results summary for easier assessment of magnitude and reliability. revision: yes
Circularity Check
No circularity detected; derivation chain not inspectable from abstract
full rationale
Only the abstract is available, which states that the authors 'theoretically show that the intrinsic reward of LPM is zero-equivariant and a monotone indicator of Information Gain (IG), and that the error model is necessary to achieve monotonicity correspondence with IG.' No equations, derivation steps, or self-citations are provided in the given text. Without access to the specific mathematical reductions or load-bearing premises, no instance can be quoted where a claimed prediction or result reduces by construction to its inputs, a fitted quantity, or an unverified self-citation. The paper therefore presents as self-contained on the basis of the visible material, warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The difference between current and previous-iteration model errors is a monotone indicator of information gain.
invented entities (1)
-
Error model
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We theoretically show that the intrinsic reward of LPM is zero-equivariant and a monotone indicator of Information Gain (IG), and that the error model is necessary to achieve monotonicity correspondence with IG.
-
IndisputableMonolith/Cost.leanJcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
r_i_t = E_D[ε^{(τ-1)}_t(o_{t+1})] - ε^{(τ)}_t(o_{t+1})
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhiyu An, Zhibo Hou, and Wan Du. Disentangling uncertainties by learning compressed data rep- resentation.arXiv preprint arXiv:2503.15801,
-
[2]
Never give up: Learning directed exploration strategies.arXiv preprint arXiv:2002.06038, 2020
Adri`a Puigdom `enech Badia, Pablo Sprechmann, Alex Vitvitskyi, Daniel Guo, Bilal Piot, Steven Kapturowski, Olivier Tieleman, Mart ´ın Arjovsky, Alexander Pritzel, Andew Bolt, et al. Never give up: Learning directed exploration strategies.arXiv preprint arXiv:2002.06038,
-
[3]
Tom Blau, Lionel Ott, and Fabio Ramos. Bayesian curiosity for efficient exploration in reinforce- ment learning.arXiv preprint arXiv:1911.08701,
-
[4]
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Large-Scale Study of Curiosity-Driven Learning
Yuri Burda, Harri Edwards, Deepak Pathak, Amos Storkey, Trevor Darrell, and Alexei A Efros. Large-scale study of curiosity-driven learning.arXiv preprint arXiv:1808.04355,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks.CoRR, abs/2306.13831,
-
[7]
Adversari- ally guided actor-critic.arXiv preprint arXiv:2102.04376,
Yannis Flet-Berliac, Johan Ferret, Olivier Pietquin, Philippe Preux, and Matthieu Geist. Adversari- ally guided actor-critic.arXiv preprint arXiv:2102.04376,
-
[8]
arXiv preprint arXiv:2501.15418 (2025)
Yuhua Jiang, Qihan Liu, Yiqin Yang, Xiaoteng Ma, Dianyu Zhong, Hao Hu, Jun Yang, Bin Liang, Bo Xu, Chongjie Zhang, et al. Episodic novelty through temporal distance.arXiv preprint arXiv:2501.15418,
-
[9]
Roberta Raileanu and Tim Rockt ¨aschel. Ride: Rewarding impact-driven exploration for procedurally-generated environments.arXiv preprint arXiv:2002.12292,
-
[10]
Episodic curiosity through reachability.arXiv preprint arXiv:1810.02274,
Nikolay Savinov, Anton Raichuk, Rapha ¨el Marinier, Damien Vincent, Marc Pollefeys, Timo- thy Lillicrap, and Sylvain Gelly. Episodic curiosity through reachability.arXiv preprint arXiv:1810.02274,
-
[11]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kai Yang, Jian Tao, Jiafei Lyu, and Xiu Li. Exploration and anti-exploration with distributional random network distillation.arXiv preprint arXiv:2401.09750,
-
[13]
There existθfor whichr i,point <0whileIG>0. Consequently, the expectation in the first term ofri is necessary to guarantee a deterministic mono- tone relationship between intrinsic reward and information gain. Proof.Express each reward in terms of the log-likelihood: log MSE(θ) =− 1 c (logp(D|θ)−const(D)), so that ri,point = 1 c logp(D|θ D)−logp(D|θ) , r ...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.