Zero-shot Human Pose Estimation using Diffusion-based Inverse solvers
Pith reviewed 2026-05-18 10:21 UTC · model grok-4.3
The pith
A pre-trained diffusion model conditioned on rotations and guided by location likelihoods enables zero-shot pose estimation across users.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate pose estimation as an inverse problem and design an algorithm capable of zero-shot generalization. Our idea utilizes a pre-trained diffusion model and conditions it on rotational measurements alone; the priors from this model are then guided by a likelihood term, derived from the measured locations. Thus, given any user, our proposed InPose method generatively estimates the highly likely sequence of poses that best explains the sparse on-body measurements.
What carries the argument
InPose, a diffusion-based inverse solver that conditions a pre-trained diffusion model on rotational measurements and guides it with a likelihood derived from measured locations.
If this is right
- Pose tracking systems can operate without per-user training or calibration data.
- Full body posture can be estimated from sparse sensors placed on the body.
- Generative sampling produces likely pose sequences that fit the measurements.
- Generalization improves because location measurements no longer directly condition the model.
- Zero-shot performance becomes feasible for users with varying body sizes.
Where Pith is reading between the lines
- Similar inverse solver techniques could apply to other sensor fusion problems where some measurements are user-specific and others are general.
- Testing on datasets with extreme body size variations would reveal the limits of the rotation-only conditioning.
- The method implies that human pose priors in diffusion models are robust enough to transfer across individuals when properly guided.
Load-bearing premise
The pre-trained diffusion model provides sufficiently accurate priors for natural human poses for a target user with different body size even without receiving location information during conditioning.
What would settle it
If the poses generated by InPose for a new user consistently fail to match the actual measured locations when evaluated on a diverse test set with varying body proportions, the zero-shot generalization claim would be falsified.
Figures








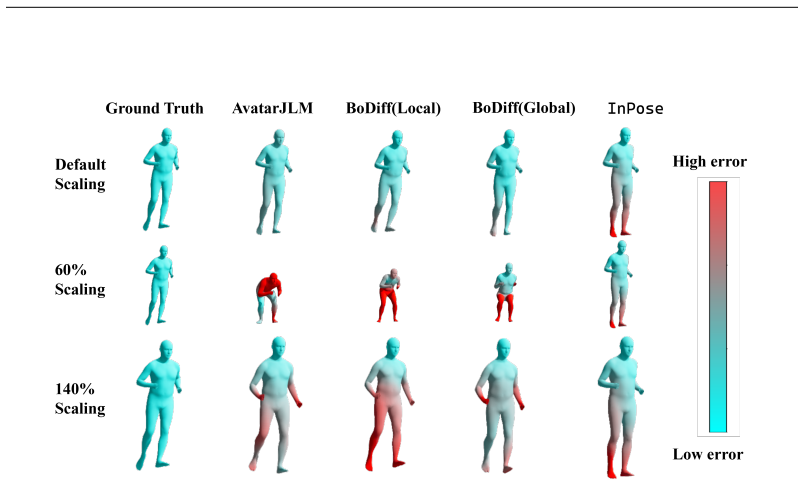

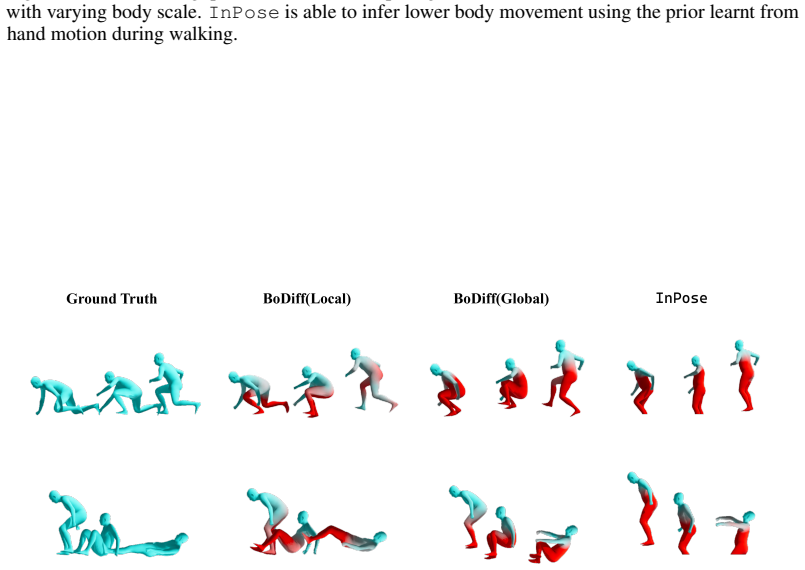
read the original abstract
Pose estimation refers to tracking a human's full body posture, including their head, torso, arms, and legs. The problem is challenging in practical settings where the number of body sensors are limited. Past work has shown promising results using conditional diffusion models, where the pose prediction is conditioned on both <location, rotation> measurements from the sensors. Unfortunately, nearly all these approaches generalize poorly across users, primarly because location measurements are highly influenced by the body size of the user. In this paper, we formulate pose estimation as an inverse problem and design an algorithm capable of zero-shot generalization. Our idea utilizes a pre-trained diffusion model and conditions it on rotational measurements alone; the priors from this model are then guided by a likelihood term, derived from the measured locations. Thus, given any user, our proposed InPose method generatively estimates the highly likely sequence of poses that best explains the sparse on-body measurements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes InPose, a zero-shot human pose estimation method that formulates the task as an inverse problem. It conditions a pre-trained diffusion model on rotational measurements from sparse on-body sensors and guides generation using a likelihood term derived from the measured 3D locations, with the goal of producing pose sequences that explain the observations while generalizing across users without retraining.
Significance. If the central claim holds, the work would be significant for practical IMU-based or sensor-based pose tracking, as it targets the well-known failure of location-conditioned methods to generalize across body sizes. The diffusion-prior plus likelihood-guidance formulation is a reasonable way to separate rotation priors from size-dependent location data, and the zero-shot framing is a clear advance over per-user fine-tuning approaches if supported by evidence.
major comments (2)
- [§3] §3 (Method), likelihood guidance paragraph: The forward model that computes p(locations | pose) via forward kinematics necessarily depends on body shape parameters (limb lengths, proportions). The manuscript gives no indication that shape is estimated, marginalized, or conditioned on per user; a fixed average shape (common default) would systematically bias the likelihood gradient toward poses plausible only for the training-set mean body, leaving the rotation-only conditioning unable to compensate and undermining the zero-shot claim across body sizes.
- [Abstract and §4] Abstract and §4 (Experiments): No quantitative results, error metrics, ablation studies, or cross-user evaluations are reported. The central claim of zero-shot generalization therefore rests entirely on the unvalidated assumption that the diffusion prior plus location likelihood will succeed where prior conditional diffusion methods fail; without these data the claim cannot be assessed.
minor comments (2)
- [§3.1] Notation for the diffusion conditioning and guidance schedule is introduced without an explicit equation; adding a compact statement of the guided reverse process (e.g., the modified score or sampling update) would improve clarity.
- [Abstract] The abstract states that location measurements are 'highly influenced by the body size of the user' but does not cite the prior literature that established this effect; a brief reference would strengthen the motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, providing clarifications on the method and committing to revisions where appropriate to strengthen the presentation of our zero-shot approach.
read point-by-point responses
-
Referee: [§3] §3 (Method), likelihood guidance paragraph: The forward model that computes p(locations | pose) via forward kinematics necessarily depends on body shape parameters (limb lengths, proportions). The manuscript gives no indication that shape is estimated, marginalized, or conditioned on per user; a fixed average shape (common default) would systematically bias the likelihood gradient toward poses plausible only for the training-set mean body, leaving the rotation-only conditioning unable to compensate and undermining the zero-shot claim across body sizes.
Authors: We agree that the likelihood p(locations | pose) computed via forward kinematics inherently depends on body shape parameters. Our current implementation adopts a fixed average body shape, which is a standard default when per-user shape measurements are unavailable. The rotation-conditioned diffusion prior is designed to capture user-agnostic joint angle distributions learned from diverse training data, while the location-based likelihood provides a corrective signal to align generated poses with observations. This separation is intended to mitigate size-dependent biases that affect fully location-conditioned methods. Nevertheless, we acknowledge the potential for bias with atypical body proportions. In the revised manuscript, we will explicitly document the average-shape assumption in §3, add a limitations discussion, and outline extensions such as marginalizing over a shape prior or jointly inferring shape parameters during guidance. These changes will better substantiate the zero-shot generalization claim. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): No quantitative results, error metrics, ablation studies, or cross-user evaluations are reported. The central claim of zero-shot generalization therefore rests entirely on the unvalidated assumption that the diffusion prior plus location likelihood will succeed where prior conditional diffusion methods fail; without these data the claim cannot be assessed.
Authors: The initial submission emphasizes the methodological formulation and includes qualitative visualizations and example sequences in §4 to illustrate behavior across users. We concur that quantitative metrics (e.g., MPJPE), ablation studies on the likelihood term, and explicit cross-user evaluations are necessary to rigorously support the zero-shot claims. We will expand §4 with these quantitative results and cross-user experiments in the revised version, and we will update the abstract to reference the key findings. This will allow direct comparison against prior conditional diffusion baselines and provide the evidence needed to evaluate the central contribution. revision: yes
Circularity Check
No significant circularity; method uses external pre-trained prior and measurement-derived guidance
full rationale
The paper formulates pose estimation as an inverse problem solved by conditioning a pre-trained diffusion model solely on rotational measurements and guiding via a likelihood term derived directly from measured locations. This chain does not reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The diffusion prior originates from separate training data on other users, and the likelihood is constructed from the current user's sparse measurements without evident circular dependence on the output poses. No uniqueness theorems or ansatzes are imported via self-citation in the abstract or high-level description. The derivation remains independent of the target result and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A pre-trained diffusion model on human poses provides accurate priors for unseen users when conditioned only on rotations.
- domain assumption A likelihood term derived from location measurements can effectively guide the diffusion sampling without requiring joint conditioning during training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train a CFG-based score model ϵθ(rtM,t,rm) … use ΠGDM … likelihood score ∇rtM log pt(lm|rtM)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lj(i)=lpj(i)+Rpj(i)·bj,pj … D converts 6DoF rotations to matrices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Masked feature prediction for self-supervised visual pre-training
IEEE Computer Society. doi: 10.1109/CVPR52688.2022.01290. Sadegh Aliakbarian, Fatemeh Saleh, David Collier, Pashmina Cameron, and Darren Cosker. HMD- NeMo: Online 3D Avatar Motion Generation From Sparse Observations . In2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9588–9597, Los Alamitos, CA, USA, October
-
[2]
Sample4Geo : Hard negative sampling for cross-view geo-localisation
IEEE Computer Society. doi: 10.1109/ICCV51070.2023.00882. Carnegie Mellon University. CMU MoCap Dataset. URLhttp://mocap.cs.cmu.edu. Angela Castillo, Maria Escobar, Guillaume Jeanneret, Albert Pumarola, Pablo Arbeláez, Ali Thabet, and Artsiom Sanakoyeu. Bodiffusion: Diffusing sparse observations for full-body human motion synthesis. InProceedings of the I...
-
[3]
IEEE Computer Society. doi: 10.1109/CVPR52733. 2024.01880. Andrea Dittadi, Sebastian Dziadzio, Darren Cosker, Ben Lundell, Tom Cashman, and Jamie Shotton. Full-Body Motion from a Single Head-Mounted Device: Generating SMPL Poses from Partial Observations . In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 11667–11677, Los Alamitos, C...
-
[4]
Emerging properties in self-supervised vision transformers
IEEE Computer Society. doi: 10.1109/ ICCV48922.2021.01148. Yuming Du, Robin Kips, Albert Pumarola, Sebastian Starke, Ali Thabet, and Artsiom Sanakoyeu. Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model. InCVPR,
-
[5]
ISSN 0730-0301. doi: 10.1145/3386569.3392452. Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications,
-
[6]
ISSN 0730-0301. doi: 10.1145/3272127. 3275108. Jiaxi Jiang, Paul Streli, Huajian Qiu, Andreas Fender, Larissa Laich, Patrick Snape, and Christian Holz. Avatarposer: Articulated full-body pose tracking from sparse motion sensing. InProceedings of European Conference on Computer Vision. Springer,
-
[7]
PeerJ Computer Science 3, e103 (Jan 2017).https://doi.org/10.7717/peerj-cs.103
ISSN 2376-5992. doi: 10.7717/peerj-cs.103. Vimal Mollyn, Riku Arakawa, Mayank Goel, Chris Harrison, and Karan Ahuja. IMUPoser: Full-body pose estimation using IMUs in phones, watches, and earbuds. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, volume 38, pp. 1–12, New York, NY , USA, April
-
[8]
ACM. M. Müller, T. Röder, M. Clausen, B. Eberhardt, B. Krüger, and A. Weber. Documentation mocap database hdm05. Technical Report CG-2007-2, Universität Bonn, June
work page 2007
-
[9]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
12 Tom Van Wouwe, Seunghwan Lee, Antoine Falisse, Scott Delp, and C
doi: 10.1167/2.5.2. 12 Tom Van Wouwe, Seunghwan Lee, Antoine Falisse, Scott Delp, and C. Karen Liu. DiffusionPoser: Real-Time Human Motion Reconstruction From Arbitrary Sparse Sensors Using Autoregressive Diffusion . In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2513–2523, Los Alamitos, CA, USA, June
-
[11]
IEEE Computer Society. doi: 10.1109/ CVPR52733.2024.00243. Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. InThe Twelfth International Conference on Learning Representations,
-
[12]
ISSN 0730-0301. doi: 10.1145/ 3450626.3459786. Xinyu Yi, Yuxiao Zhou, Marc Habermann, Soshi Shimada, Vladislav Golyanik, Christian Theobalt, and Feng Xu. Physical inertial poser (pip): Physics-aware real-time human motion tracking from sparse inertial sensors. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June
-
[13]
13 A PROOF OFTHEOREM1 Theorem 1.We are given a well-trained error model ϵθ, that learns the error distribution ϵt ← ϵθ(rt M , t, rm), and denoises ˆrt M ← rt M −√1−¯αtϵt√¯αt . If the model ensures that ||ˆrt,1:3 j ||=||ˆr t,3:6 j ||= 1,⟨ˆrt,1:3 j ,ˆrt,3:6 j ⟩= 0,∀j∈M then pt(D(r0 M)|rt M)≈ N(D(ˆrt M), w2 t Σˆrt M ) where Σˆrt M is a positive definite matr...
work page 1991
-
[14]
Because this equation is recursive, the transformation from ΘM →R M is a higher-order polynomial function. We could use DPS Chung et al. (2023) as it allows for inverse guidance through differentiable nonlinear measurement functions. However, in our experiments, we found that this does not work well in practice, with the relatively low number of diffusion...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.