AISysRev -- LLM-based Tool for Title-abstract Screening
Pith reviewed 2026-05-18 09:36 UTC · model grok-4.3
The pith
An LLM screening tool classifies papers into easy and boundary cases to focus human effort on uncertain ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
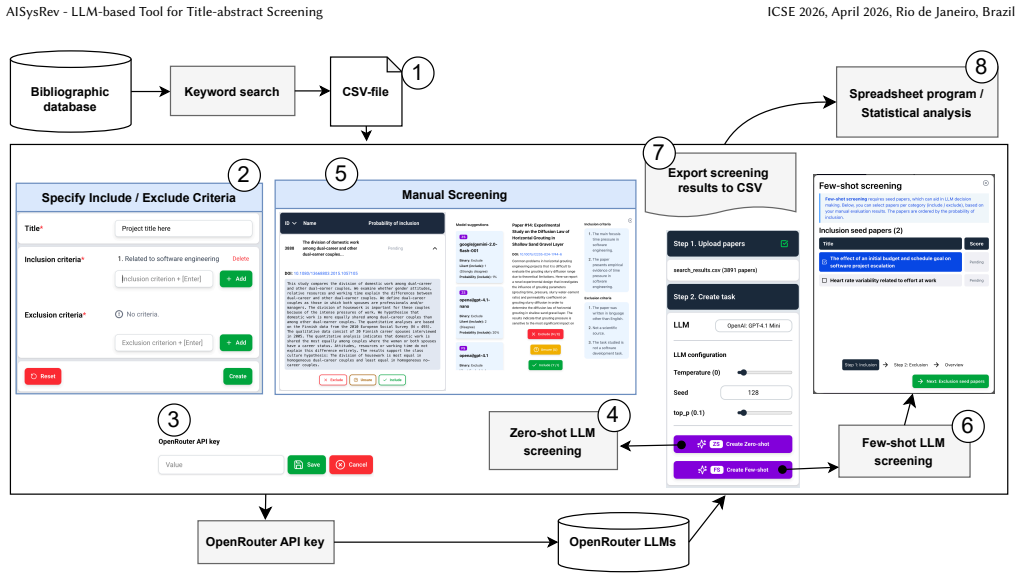
AISysRev accepts CSV files of titles and abstracts, applies user-specified criteria through zero-shot or few-shot prompting with models such as Gemini, Claude, Mistral, ChatGPT, or local OpenAI-compatible models, and provides interfaces that display LLM outputs as guidance for manual review. In the 137-paper trial the outputs fall into four categories—Easy Includes, Easy Excludes, Boundary Includes, and Boundary Excludes—where boundary cases are prone to LLM errors, demonstrating that LLMs can reduce the volume of assessment but do not replace human judgment.
What carries the argument
The four-category classification (Easy Includes, Easy Excludes, Boundary Includes, Boundary Excludes) that separates papers the LLM handles reliably from those that require human intervention.
If this is right
- Screening can proceed at 100 to 300 papers per minute depending on the chosen model.
- Human reviewers can direct attention to the boundary cases flagged by the tool.
- The same interface supports both fully automated runs and assisted manual review.
- Any model compatible with the OpenAI SDK or hosted locally can be swapped in without changing the workflow.
Where Pith is reading between the lines
- The four-category framework could be used in other research fields to measure where LLMs are reliable for literature screening.
- Tool guidance that highlights boundary cases might reduce reviewer fatigue on large projects.
- Iterative use of human corrections on boundary cases could be fed back to refine prompts or fine-tune models.
Load-bearing premise
The pattern of easy and boundary cases seen in the 137-paper trial will appear and be recognizable in other sets of papers, criteria, and models.
What would settle it
A new screening run on a different collection of papers in which error rates are no higher for the boundary category than for the easy categories, or in which human reviewers cannot reliably identify the boundary cases from the tool output.
Figures
read the original abstract
Conducting systematic reviews is laborious. In the screening or study selection phase, the number of papers can be overwhelming. Recent research has demonstrated that large language models (LLMs) can perform title-abstract screening and support humans in the task. To this end, we developed AISysRev, an LLM-based screening tool implemented as a containerized web application. The tool accepts CSV files containing paper titles and abstracts. Users specify inclusion and exclusion criteria. Multiple different LLMs can be used, such as Gemini, Claude, Mistral or ChatGPT via OpenRouter. We also support locally hosted models and any model compatible with the OpenAI SDK. AISysRev implements both zero-shot and few-shot prompting, and also allows for manual screening through interfaces that display LLM results as guidance for human reviewers. LLM calls are parallelized, meaning screening speed is typically between 100 to 300 papers per minute, depending on the model and the host. To demonstrate the tool's use in practice, we conducted a qualitative trial study with 137 papers using the tool. Our findings indicate that papers can be classified into four categories: Easy Includes, Easy Excludes, Boundary Includes, and Boundary Excludes. The Boundary cases, where LLMs are prone to errors, highlight the need for human intervention. While LLMs do not replace human judgment in systematic reviews, they can reduce the burden of assessing large volumes of scientific literature. Video: https://www.youtube.com/watch?v=HeblemlgnAQ Tool: https://github.com/EvoTestOps/AISysRev
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents AISysRev, a containerized web application for LLM-assisted title-abstract screening in systematic reviews. The tool accepts CSV inputs of titles and abstracts, allows users to specify inclusion/exclusion criteria, supports multiple LLMs (Gemini, Claude, Mistral, ChatGPT via OpenRouter, local models, and OpenAI SDK-compatible ones), implements zero-shot and few-shot prompting, and provides manual screening interfaces that display LLM results as guidance. A qualitative trial on 137 papers is used to illustrate that papers fall into four categories (Easy Includes, Easy Excludes, Boundary Includes, Boundary Excludes), with the conclusion that LLMs can reduce screening burden while boundary cases require human intervention.
Significance. The concrete implementation details, support for diverse models and prompting strategies, and parallelized screening (100-300 papers per minute) represent practical contributions to evidence synthesis workflows. If the four-category classification and boundary detection prove reproducible across datasets and models, the work could support hybrid human-LLM screening protocols that direct effort to uncertain cases. However, the absence of quantitative metrics (accuracy, inter-rater agreement, error rates, or category counts) limits the strength of claims about burden reduction and the reliability of the proposed guidance framework.
major comments (1)
- [Qualitative trial description (and abstract)] Qualitative trial on 137 papers: The central claim that papers classify into Easy Includes/Excludes and Boundary Includes/Excludes, with boundary cases highlighting the need for human intervention, rests on a single qualitative observation. No counts per category are reported, no operational definition of 'boundary' (e.g., confidence threshold, prompt disagreement, or uncertainty signal) is provided, and no human-LLM agreement metrics or comparison to a gold-standard screening decision are given. This makes the classification appear post-hoc and weakens support for the practical recommendation that LLMs reduce burden while reliably flagging oversight needs.
minor comments (2)
- [Discussion or Conclusion] The manuscript would benefit from a dedicated limitations section that explicitly discusses generalizability beyond the tested models, criteria, and paper set.
- [Tool features and implementation] Consider clarifying in the tool description whether the few-shot examples are user-provided or system-suggested, and how they are stored or reused across sessions.
Simulated Author's Rebuttal
We thank the referee for their constructive review of our manuscript on AISysRev. We address the major comment below, focusing on the qualitative trial and its presentation.
read point-by-point responses
-
Referee: Qualitative trial on 137 papers: The central claim that papers classify into four categories: Easy Includes/Excludes and Boundary Includes/Excludes, with boundary cases highlighting the need for human intervention, rests on a single qualitative observation. No counts per category are reported, no operational definition of 'boundary' (e.g., confidence threshold, prompt disagreement, or uncertainty signal) is provided, and no human-LLM agreement metrics or comparison to a gold-standard screening decision are given. This makes the classification appear post-hoc and weakens support for the practical recommendation that LLMs reduce burden while reliably flagging oversight needs.
Authors: We thank the referee for this observation. The four-category classification emerged directly from our use of the AISysRev interface while screening the 137 papers: Easy Includes and Easy Excludes were cases where the LLM output aligned clearly with the provided criteria, while Boundary Includes and Boundary Excludes were those requiring human review due to ambiguity in the LLM suggestion or partial match with criteria. This was not a post-hoc invention but an observed pattern during the trial. We agree that the manuscript would benefit from greater clarity on this point. We will revise the relevant section (and abstract) to provide an operational description of how boundary cases were identified in practice (based on LLM output characteristics and human overrides in the tool), to state explicitly that the trial is illustrative rather than a formal evaluation, and to moderate claims about burden reduction to reflect the qualitative nature of the demonstration. We did not collect gold-standard labels or compute agreement metrics because the study focus was tool functionality, not performance benchmarking. revision: partial
Circularity Check
No significant circularity; tool report and qualitative trial are self-contained
full rationale
The paper presents the AISysRev tool implementation and reports observations from one qualitative trial on 137 papers, classifying results into four categories as an empirical finding. No equations, derivations, fitted parameters, predictions, or self-citation chains exist that reduce any claim to its inputs by construction. The four-category observation is stated directly from the trial without mathematical reduction or load-bearing reliance on prior self-authored results. This is a standard tool-development report with independent content and no circular reasoning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs prompted with inclusion/exclusion criteria can produce useful screening decisions for title-abstract pairs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our findings indicate that papers can be classified into four categories: Easy Includes, Easy Excludes, Boundary Includes, and Boundary Excludes.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TiAb Review Plugin: A Browser-Based Tool for AI-Assisted Title and Abstract Screening
A Chrome extension provides no-code, serverless AI-assisted title and abstract screening for systematic reviews by integrating LLMs and ML active learning with Google Sheets.
Reference graph
Works this paper leans on
-
[1]
D., Carbone, A., Slade, S., Baik, C., Hughes- Warrington, M., and Neumann, D
Bearman, M., Smith, C. D., Carbone, A., Slade, S., Baik, C., Hughes- Warrington, M., and Neumann, D. L.Systematic review methodology in higher education.Higher Education Research & Development 31, 5 (2012), 625–640
work page 2012
-
[2]
Clark, J., Glasziou, P., Del Mar, C., Bannach-Brown, A., Stehlik, P., and Scott, A. M.A full systematic review was completed in 2 weeks using automation tools: a case study.Journal of clinical epidemiology 121(2020), 81–90
work page 2020
-
[3]
Felizardo, K. R., Deizepe, A., Coutinho, D., Gomes, G., Meireles, M., Gerosa, M., and Steinmacher, I.On the difficulties of conducting and replicating systematic literature reviews studies using llms in software engineering. In2025 IEEE/ACM International Workshop on Methodological Issues with Empirical Studies in Software Engineering (WSESE)(2025), IEEE, ...
work page 2025
-
[4]
Felizardo, K. R., Lima, M. S., Deizepe, A., Conte, T. U., and Steinmacher, I. ChatGPT application in Systematic Literature Reviews in Software Engineering: An evaluation of its accuracy to support the selection activity. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement(New York, NY, USA, 2024), E...
work page 2024
-
[5]
Garritty, C., Gartlehner, G., Nussbaumer-Streit, B., King, V. J., Hamel, C., Kamel, C., Affengruber, L., and Stevens, A.Cochrane rapid reviews methods group offers evidence-informed guidance to conduct rapid reviews.Journal of clinical epidemiology 130(2021), 13–22
work page 2021
-
[6]
Huotala, A., Kuutila, M., and Mäntylä, M.SESR-Eval: Dataset for Evaluating LLMs in the Title-Abstract Screening of Systematic Reviews. InProceedings of the 18th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement(Oct. 2025), ESEM ’25, IEEE, pp. 1–12
work page 2025
-
[7]
Huotala, A., Kuutila, M., Ralph, P., and Mäntylä, M.The Promise and Challenges of Using LLMs to Accelerate the Screening Process of Systematic Reviews. InProceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering(New York, NY, USA, July 18, 2024), EASE ’24, Association for Computing Machinery, pp. 262–271
work page 2024
-
[8]
Huotala, A., Kuutila, M., Turtio, O.-P., and Mäntylä, M.Dataset for: AISysRev - LLM-based tool for Title-abstract Screening, Oct. 2025. Available at https://doi.org/10.5281/zenodo.17208539
-
[9]
Kersten, R., Harms, J., Liket, K., and Maas, K.Small firms, large impact? a systematic review of the sme finance literature.World development 97(2017), 330–348
work page 2017
-
[10]
A., Dyba, T., and Jorgensen, M.Evidence-based software engineering
Kitchenham, B. A., Dyba, T., and Jorgensen, M.Evidence-based software engineering. InProceedings. 26th International Conference on Software Engineering (2004), IEEE, pp. 273–281
work page 2004
-
[11]
Kuutila, M., Mäntylä, M., Farooq, U., and Claes, M.Time pressure in software engineering: A systematic review.Information and Software Technology 121(2020), 106257
work page 2020
-
[12]
Marshall, I. J., and Wallace, B. C.Toward systematic review automation: a practical guide to using machine learning tools in research synthesis.Systematic reviews 8, 1 (2019), 163
work page 2019
-
[13]
Meade, M. O., and Richardson, W. S.Selecting and appraising studies for a systematic review.Annals of internal medicine 127, 7 (1997), 531–537
work page 1997
-
[14]
Öncü, S., Torun, F., and Ülkü, H. H.Ai-powered standardised patients: evaluat- ing chatgpt-4o’s impact on clinical case management in intern physicians.BMC Medical Education 25, 1 (2025), 278
work page 2025
-
[15]
Petersen, K., and Gerken, J. M.On the road to interactive llm-based systematic mapping studies.Information and Software Technology 178(2025), 107611
work page 2025
-
[16]
Pizard, S., Lezama, J., García, R., Vallespir, D., and Kitchenham, B.Using rapid reviews to support software engineering practice: a systematic review and a replication study.Empirical Software Engineering 30, 1 (2025), 10
work page 2025
-
[17]
Rafi, D. M., Moses, K. R. K., Petersen, K., and Mäntylä, M. V.Benefits and limitations of automated software testing: Systematic literature review and prac- titioner survey. In2012 7th international workshop on automation of software test (AST)(2012), IEEE, pp. 36–42
work page 2012
-
[18]
In International Conference on Product-Focused Software Process Improvement(2024), Springer, pp
Romano, S., Conforti, A., Guidetti, G., Viotti, S., Converso, D., and Scan- niello, G.On job demands and resources in the italian software industry. In International Conference on Product-Focused Software Process Improvement(2024), Springer, pp. 172–188
work page 2024
-
[19]
Shahzeidi, M., Mollahoseini Ardakani, M., Javdani Gandomani, T., and Mirzaie, K.A hybrid model of long short-term memory neural networks and quantum behavior pso for detecting self-admitted technical debt.Cluster Com- puting 28, 3 (2025), 152
work page 2025
-
[20]
Sotaqirá-Gutiérrez, R., Beltran, L. M., and Garzon Ruiz, J. P.Hackathons as experiential learning platforms for engineering design skills.Cogent Education 12, 1 (2025), 2442187
work page 2025
-
[21]
Thode, L., Iftikhar, U., and Mendez, D.Exploring the use of llms for the selec- tion phase in systematic literature studies.Information and Software Technology (2025), 107757
work page 2025
-
[22]
Watt, A., Cameron, A., Sturm, L., Lathlean, T., Babidge, W., Blamey, S., Facey, K., Hailey, D., Norderhaug, I., and Maddern, G.Rapid reviews versus full systematic reviews: an inventory of current methods and practice in health technology assessment.International journal of technology assessment in health care 24, 2 (2008), 133–139
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.