Large Language Model Prompt Datasets: An In-depth Analysis and Insights
Pith reviewed 2026-05-18 08:25 UTC · model grok-4.3
The pith
Syntactic features recover over 93 percent of GPU embedding accuracy for routing LLM prompts while cutting latency by nearly half with no hardware required.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper's central claim is that 62-d syntactic features consisting of POS tag and dependency parse distributions serve as a uniquely efficient routing primitive. These features recover more than 93 percent of the accuracy obtained by GPU-based embedding methods for prompt routing tasks, while delivering 1.9 times lower single-request latency at 3.0 ms versus 5.7 ms, all without any GPU or corpus vocabulary.
What carries the argument
62-dimensional syntactic feature vectors drawn from part-of-speech tag distributions and dependency parse statistics, deployed as a lightweight routing primitive.
Load-bearing premise
The seven representative corpora capture the linguistic properties of the full collection of 129 datasets and the observed feature patterns generalize to unseen prompt distributions.
What would settle it
Measure routing accuracy of the 62-d syntactic features against GPU embeddings on a new collection of LLM prompt datasets drawn from sources outside the original 129 and check whether accuracy remains above 93 percent.
Figures
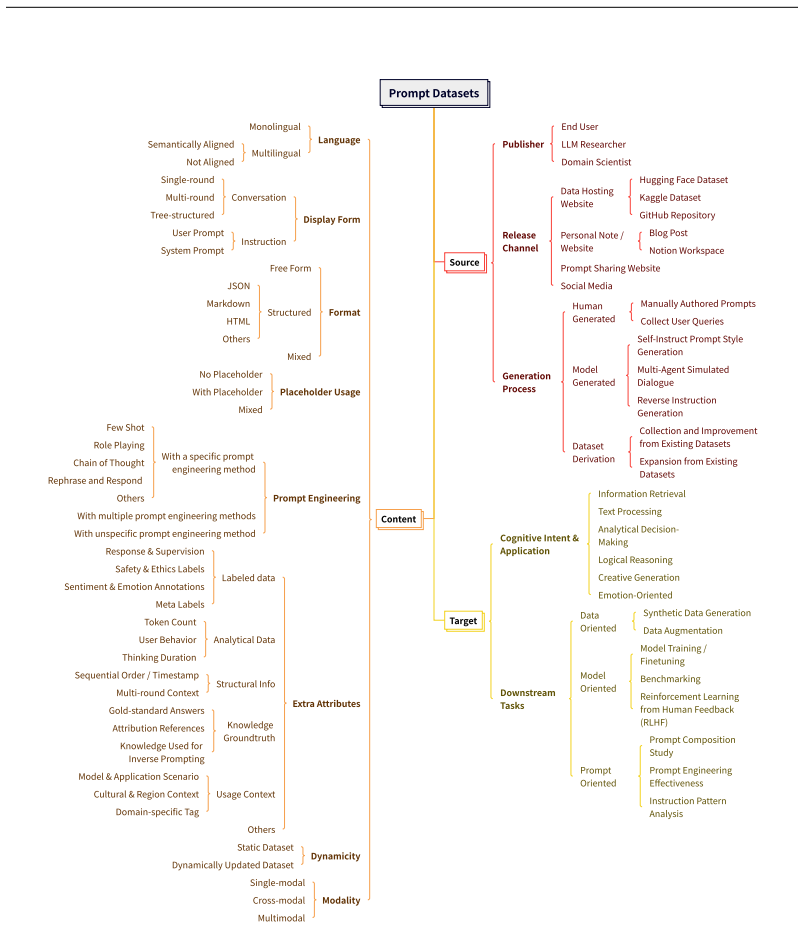









read the original abstract
We compile 129 heterogeneous LLM prompt datasets (>1.22 TB, >673M instances) into a structured taxonomy and conduct a multi-level linguistic analysis (lexical, syntactic, and semantic) on seven representative corpora, surfacing systematic patterns that distinguish prompts from general text. Three downstream experiments validate practical utility: prompt filtering (F1 = 0.90), domain classification (Macro-F1 = 0.975), and prompt quality prediction (AUC = 0.792), all without invoking any additional model. A central finding is that 62-d syntactic features (POS + dependency distributions) serve as a uniquely efficient routing primitive, recovering >93% of GPU-embedding accuracy at 1.9 $\times$ lower single-request latency (3.0 ms vs. 5.7 ms) with no GPU and no corpus vocabulary. A complementary discriminative--predictive divergence shows that features most useful for routing are precisely those most negatively correlated with response quality, while lexical diversity (Cohen's $d$ = 0.71) dominates the quality signal but carries minimal routing weight, directly motivating two-stage pipeline design. Our datasets and code are available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compiles 129 heterogeneous LLM prompt datasets (>1.22 TB, >673M instances) into a structured taxonomy and conducts a multi-level linguistic analysis (lexical, syntactic, and semantic) on seven representative corpora. It validates practical utility through three downstream experiments using standard linguistic tools: prompt filtering (F1 = 0.90), domain classification (Macro-F1 = 0.975), and prompt quality prediction (AUC = 0.792), all without invoking additional models. A central finding is that 62-d syntactic features (POS + dependency distributions) recover >93% of GPU-embedding accuracy for routing at 1.9× lower single-request latency (3.0 ms vs. 5.7 ms) with no GPU and no corpus vocabulary. The work also reports a discriminative-predictive divergence, where features useful for routing are negatively correlated with response quality while lexical diversity (Cohen's d = 0.71) dominates the quality signal, motivating two-stage pipeline designs. Datasets and code are made available.
Significance. If the results hold, the manuscript offers a large-scale empirical characterization of LLM prompts and demonstrates efficient, model-free methods for prompt routing, filtering, and classification using compact syntactic features. Concrete metrics (F1=0.90, Macro-F1=0.975, AUC=0.792, >93% recovery) from off-the-shelf parsers, together with code availability, support verification. The discriminative-predictive divergence provides a concrete rationale for separating routing and quality stages in LLM serving systems. These contributions could inform prompt dataset curation and low-latency routing primitives in production environments.
major comments (1)
- The generalization of the 62-d syntactic feature performance (recovering >93% of embedding accuracy) and the observed patterns from the seven representative corpora to the full collection of 129 datasets and to unseen prompts is load-bearing for the broad utility and routing-primitive claims (abstract). The manuscript should supply explicit selection criteria for the seven corpora, quantitative comparisons of their distributional properties (e.g., length, domain, lexical diversity) against the full >1.22 TB collection, and any statistical controls or hold-out validation demonstrating representativeness. Absent this, the reported latency advantage and discriminative-predictive divergence may not transfer reliably.
minor comments (1)
- Abstract: the term 'discriminative--predictive divergence' is introduced without a brief parenthetical definition; a short clarification on first use would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The concern about representativeness of the seven corpora is well-taken and directly relevant to the strength of our generalization claims. We address it point-by-point below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: The generalization of the 62-d syntactic feature performance (recovering >93% of embedding accuracy) and the observed patterns from the seven representative corpora to the full collection of 129 datasets and to unseen prompts is load-bearing for the broad utility and routing-primitive claims (abstract). The manuscript should supply explicit selection criteria for the seven corpora, quantitative comparisons of their distributional properties (e.g., length, domain, lexical diversity) against the full >1.22 TB collection, and any statistical controls or hold-out validation demonstrating representativeness. Absent this, the reported latency advantage and discriminative-predictive divergence may not transfer reliably.
Authors: We agree that explicit documentation of selection criteria and distributional comparisons is necessary to support the generalization claims. The seven corpora were chosen to maximize coverage across the taxonomy categories (instruction, dialogue, reasoning, creative, domain-specific) while balancing computational feasibility for full linguistic parsing; they include both large-scale public datasets and smaller curated ones to span the observed range of prompt lengths and sources. In the revision we will add: (1) a dedicated subsection stating the selection criteria with a table listing each corpus, its size, primary domain, and taxonomy category; (2) quantitative comparisons (mean/median token length, type-token ratio as lexical diversity proxy, domain label distribution, and syntactic feature variance) between the seven and summary statistics computed over the full 129 datasets using available metadata; (3) a hold-out experiment in which syntactic-feature classifiers trained on the seven are evaluated on a random 10% sample drawn from the remaining 122 datasets, reporting F1 and latency metrics to quantify transfer. These additions will be placed in Section 4 and the appendix. We believe the requested material can be supplied without altering the core results. revision: yes
Circularity Check
No circularity: empirical measurements on external datasets
full rationale
The paper compiles 129 external prompt datasets and performs direct multi-level linguistic analysis on seven representative corpora using off-the-shelf POS and dependency parsers. All reported metrics (prompt filtering F1=0.90, domain classification Macro-F1=0.975, quality prediction AUC=0.792, >93% recovery of GPU-embedding accuracy, 3.0 ms vs 5.7 ms latency) are obtained from straightforward feature extraction and downstream task evaluation on the collected data. No equations, fitted parameters, or self-citations reduce these results to inputs defined within the paper itself. The generalization assumption from seven corpora to the full collection is a validity concern rather than a circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption POS tagging and dependency parsing tools produce reliable distributions on prompt text.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
62-d syntactic features (POS + dependency distributions) serve as a uniquely efficient routing primitive, recovering >93% of GPU-embedding accuracy at 1.9× lower single-request latency
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We perform multi-level linguistic analysis—lexical, syntactic, and semantic—across seven representative prompt datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
1100+ ChatGPT Prompts for Business
1100+ ChatGPT Prompts for Business • Publisher: Chris Porter 15 • Size: 1235 instances • License: - • Link: https://chatgpt-business-prompts.notion.site/ 1100-ChatGPT-Prompts-for-Business-eea03b0bc9b84ae7a5bdbd76a67460f3 • Description: "1100+ ChatGPT Prompts for Business" is a Notion-based dataset containing 1,235 curated prompts tailored for diverse busi...
-
[2]
2.5k-chatgpt-promp-templates • Publisher: TheVeller • Size: 1088 instances • License: - • Link: https://ignacio-velasquez.notion.site/ 2-500-ChatGPT-Prompt-Templates-d9541e901b2b4e8f800e819bdc0256da • Description: This dataset comprises over 1,000 curated ChatGPT prompt templates in Notion Workspace format, spanning diverse domains such as AI, marketing, ...
-
[3]
A Collection of AI’s Prompts for optimal context • Publisher: Marc-Aurele Besner • Size: 70 instances • License: MIT • Link: https://github.com/marc-aurele-besner/ ChatGPT-PromptsList • Description: This repository offers a well-curated collection of conversation prompts tailored for OpenAI’s GPT-3 model
-
[4]
Academic Reasoning and Intuition Chains Dataset • Publisher: Marco De Santis • Size: 2024 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/marcodsn/academic-chains • Description: The Academic Reasoning and Intuition Chains dataset comprises 1,975 ex- amples of chain-of-thought reasoning distilled from open-access arXiv papers across...
work page 2024
-
[5]
AI Short • Publisher: rockbenben • Size: 5867 instances • License: - • Link: https://www.aishort.top/ • Description: AI Short is a public prompt-sharing platform with 5,867 categorized prompts. Each prompt is available in multiple languages, enabling cross-linguistic studies of prompt effectiveness and translation consistency
-
[6]
AI-Generated Prompts Dataset • Publisher: Anthony Therrien 16 • Size: 173574 instances • License: CC-BY-SA-4.0 • Link: https://www.kaggle.com/datasets/anthonytherrien/ ai-generated-prompts-dataset • Description: This dataset features thousands of prompts generated by the teknium/OpenHermes-2p5-Mistral-7B model, each designed to elicit diverse and contextu...
-
[7]
AIPRM • Publisher: AIPRM • Size: 5325 instances • License: - • Link: https://www.aiprm.com/ • Description: AIPRM is a community-curated prompt library and management platform featuring 5,325 publicly accessible prompts categorized by topic and activity. Its user-driven structure offers valuable insights into real-world prompt usage, preferences, and task ...
-
[8]
Alpaca_data • Publisher: Stanford Alpaca • Size: 52K instances • License: Apache-2.0 • Link: https://github.com/tatsu-lab/stanford_alpaca/tree/main • Description: The Stanford Alpaca dataset comprises 52K high-quality, instruction-following examples generated via a modified Self-Instruct pipeline using text-davinci-003. Designed for fine-tuning LLaMA mode...
-
[9]
Alpaca_GPT4_data_zh • Publisher: Microsoft Research • Size: 52K instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/llm-wizard/ alpaca-gpt4-data-zh • Description: Alpaca_GPT4_data_zh is a Chinese instruction-tuning dataset curated by the Instruction Tuning with GPT-4 project. It comprises 48,818 examples, each featuring an instruction,...
-
[10]
AM-DeepSeek-Distilled-40M • Publisher: a-m-team • Size: 40M instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/a-m-team/ AM-DeepSeek-Distilled-40M • Description: AM-DeepSeek-Distilled-40M is a multilingual (zh/en) reasoning dataset com- prising 3.34 million prompts paired with 40 million model-generated responses across code, math, ...
-
[11]
AM-DeepSeek-R1-Distilled-1.4M 17 • Publisher: a-m-team • Size: 1.4M instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/a-m-team/ AM-DeepSeek-R1-Distilled-1.4M • Description: AM-DeepSeek-R1-Distilled-1.4M is a bilingual (Chinese and English) rea- soning dataset of 1.4 million challenging problem-solution pairs. Collected from diverse...
-
[12]
It contains 100k+ problems from repositories and categorized by pass rates of Qwen models
AM-Math-Difficulty-RL • Publisher: a-m-team • Size: 234729 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/a-m-team/ AM-Math-Difficulty-RL • Description: AM-Math-Difficulty-RL is an English math dataset comprising three difficulty tiers designed for RL of LLMs. It contains 100k+ problems from repositories and categorized by pass ...
-
[13]
APIGen-MT -5k • Publisher: Salesforce AI Research • Size: 5K instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/Salesforce/APIGen-MT-5k • Description: The APIGen-MT-5k dataset comprises 5000 realistic, high-quality, multi-turn function-calling dialogues generated by APIGen-MT, a scalable automated agentic pipeline simulating agent-h...
-
[14]
awesome-chatgpt-prompts • Publisher: Fatih Kadir Akın • Size: 211 instances • License: CC0-1.0 • Link: https://github.com/f/awesome-chatgpt-prompts • Description: The Awesome ChatGPT Prompts dataset is a collaboratively curated collection of diverse prompts optimized for interactive AI models, including ChatGPT, Claude, and LLaMA. Featuring both human- an...
-
[15]
Aya Collection • Publisher: Cohere For AI Community et al. • Size: 513M instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/CohereLabs/aya_ collection 18 • Description: Aya Collection is a massive multilingual instruction tuning dataset comprising over 513 million prompt-completion pairs across 115 languages. It integrates three source...
-
[16]
Aya Dataset • Publisher: Cohere For AI Community et al. • Size: 204K instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/CohereLabs/aya_dataset • Description: The Aya Dataset is a multilingual, human-annotated instruction fine-tuning resource encompassing 204K prompt-completion pairs across 65 languages and dialects. It includes origin...
-
[17]
BABILong • Publisher: AIRI et al. • Size: 25K instances • License: Apache 2.0 • Link: https://huggingface.co/datasets/RMT-team/babilong • Description: BABILong is a generative benchmark designed to evaluate large language mod- els’ ability to perform reasoning over extremely long contexts. It embeds the ten bAbI tasks within irrelevant PG19 background tex...
-
[18]
Bactrain-X • Publisher: MBZUAI • Size: 3484884 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/MBZUAI/Bactrian-X • Description: Bactrian-X is a multilingual instruction-following dataset containing 3.4 million instruction-input-response triplets across 52 languages. It builds upon 67K unique English prompts drawn from Alpaca and ...
-
[19]
Baize • Publisher: University of California et al. • Size: 210311 instances • License: GPL-3.0 • Link: https://huggingface.co/datasets/linkanjarad/ baize-chat-data • Description: Baize Chat Data is an instruction-finetuning corpus combining four sources: Alpaca, Medical, Quora, and StackOverflow. It contains about 210,000 conversational exam- ples, each f...
-
[20]
400k personalized Chinese character dialogues generated by the BELLE project
BELLE_Generated_Chat • Publisher: BELLE • Size: 396004 instances • License: GPL-3.0 • Link: https://huggingface.co/datasets/BelleGroup/generated_ chat_0.4M • Description: BELLE_Generated_Chat contains approx. 400k personalized Chinese character dialogues generated by the BELLE project. Each record includes an instruction, an (empty) input, and a generated...
-
[21]
BELLE_Multiturn_Chat • Publisher: BELLE • Size: 831036 instances • License: GPL-3.0 • Link: https://huggingface.co/datasets/BelleGroup/multiturn_ chat_0.8M • Description: BELLE_Multiturn_Chat is a Chinese multi-turn conversational dataset com- prising approximately 0.8 million human-assistant dialogues generated by the BELLE project using ChatGPT. Each re...
-
[22]
It includes human-assistant exchanges across 13 instruction categories
BELLE_train_3.5M_CN • Publisher: BELLE • Size: 3606402 instances • License: GPL-3.0 • Link: https://huggingface.co/datasets/BelleGroup/train_3.5M_CN • Description: The BELLE_train_3.5M_CN dataset comprises approximately 3.5 million monolingual Chinese instruction-response pairs generated by the BELLE project, format- ted as multi-turn and single-turn dial...
-
[23]
best-chinese-prompt • Publisher: K-Render • Size: 141 instances • License: - • Link: https://github.com/K-Render/best-chinese-prompt • Description: The Best Chinese Prompt dataset is a comprehensive, well-structured collection of Chinese-language prompts spanning diverse categories such as casual chat, knowledge Q&A, creative planning, copywriting, and co...
-
[24]
BigDocs-Bench • Publisher: ServiceNow Research et al. • Size: 415740 instances 20 • License: CC-BY-4.0 • Link: https://huggingface.co/datasets/ServiceNow/BigDocs-Bench • Description: BigDocs-Bench is a CC-BY-4.0 benchmark suite for training and evaluating multimodal models on document and code tasks. It comprises seven configurations: GUI- VQA, GUI2BBox, ...
-
[25]
BoredHumans • Publisher: Impulse Communications, Inc. • Size: 964 instances • License: - • Link: https://boredhumans.com/prompts.php • Description: BoredHumans is a diverse and extensive prompt dataset compiled from multiple sources, including Awesome ChatGPT Prompts, Data Science Prompts, and Tree-of-Thought Prompting, among others. Its rich variety cove...
-
[26]
CAMEL • Publisher: KAUST • Size: 1659328 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/camel-ai/ai_society • Description: CAMEL AI Society is a synthetic dialogue corpus comprising 25,000 simulated conversations between GPT-3.5-turbo agents role-playing across 50 distinct user roles and 50 assistant roles on ten tasks per pairi...
-
[27]
ChatGPT & Bing AI Prompts • Publisher: yokoffing • Size: 35 instances • License: CC0-1.0 • Link: https://github.com/yokoffing/ChatGPT-Prompts • Description: The ChatGPT & Bing AI Prompts dataset offers a diverse collection of prompts designed to optimize interaction with advanced conversational AI models, including ChatGPT and Bing AI. It enables research...
-
[28]
ChatGPT Data Science Prompts • Publisher: Travis Tang • Size: 60 instances • License: - • Link: https://github.com/travistangvh/ChatGPT-Data-Science-Prompts • Description: The ChatGPT Prompts for Data Science dataset offers a curated collection of specialized prompts designed to enhance AI applications in data science tasks. It facilitates research on nat...
-
[29]
ChatGPT Prompts 21 • Publisher: PrathamKumar14 • Size: 84 instances • License: - • Link: https://github.com/PrathamKumar14/ChatGPT-Prompts • Description: The ChatGPT-Prompts dataset compiles diverse prompt templates focused on educational and productivity applications, including tutoring in web development, algorithm explanation, Excel formulas, social me...
-
[30]
ChatGPT Prompts • Publisher: ColorblindAdam • Size: 19 instances • License: - • Link: https://github.com/ColorblindAdam/ChatGPTPrompts • Description: The ChatGPT Prompts dataset offers a broad collection of prompts covering diverse topics, designed for use with GPT 3.5. Its value lies in providing versatile, real-world prompt examples that support researc...
-
[31]
ChatGPT Prompts • Publisher: Matheus Nunes Puppe • Size: 36 instances • License: - • Link: https://github.com/puppe1990/useful_chatgpt_prompts/ blob/main/src/promptsData.js • Description: The ChatGPT Prompts dataset originates from a web application offering a diverse set of prompts generated by OpenAI’s GPT-3 model. These prompts serve multiple research ...
-
[32]
Chinese-DeepSeek-R1-Distill-data-110k • Publisher: Cong Liu et al. • Size: 110K instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/Congliu/ Chinese-DeepSeek-R1-Distill-data-110k • Description: Chinese-DeepSeek-R1-Distill-data-110k is a 110K-entry Chinese dataset dis- tilled from DeepSeek-R1, supporting text generation, text2text gener...
-
[33]
Chinese-DeepSeek-R1-Distill-data-110k-SFT • Publisher: Cong Liu et al. • Size: 110K instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/Congliu/ Chinese-DeepSeek-R1-Distill-data-110k-SFT • Description: Licensed under Apache-2.0, Chinese-DeepSeek-R1-Distill-data-110k-SFT is an open-source, Chinese-language instruction-tuning dataset dis...
-
[34]
CoCoNot • Publisher: Allen Institute for AI et al. • Size: 13784 instances • License: ODC-BY-1.0 • Link: https://huggingface.co/datasets/allenai/coconot • Description: CoCoNot is a novel English dataset for benchmarking and improving contextual noncompliance in chat-based language models. It offers three configurations: “original” contains 11K training an...
-
[35]
COIG-CQIA • Publisher: Shenzhen Institute of Advanced Technology et al. • Size: 44694 instances • License: - • Link: https://huggingface.co/datasets/m-a-p/COIG-CQIA • Description: COIG-CQIA (Chinese Open Instruction Generalist - Quality is All You Need) is a high-quality, open-source Chinese instruction tuning dataset designed to align language models wit...
-
[36]
CVQA • Publisher: MBZUAI • Size: 10374 instances • License: Mixed • Link: https://huggingface.co/datasets/afaji/cvqa • Description: CVQA is a culturally diverse, multilingual visual question-answering bench- mark featuring over 10,000 image-based questions across 39 country-language pairs. Each sample includes a locally posed query, its English translatio...
-
[37]
databricks-dolly-15K • Publisher: Databricks • Size: 15011 instances • License: CC-BY-SA-3.0 • Link: https://huggingface.co/datasets/databricks/ databricks-dolly-15k • Description: Databricks-dolly-15K is an open-source corpus of over 15,000 human- generated instruction-response pairs created by Databricks employees across eight behavioral categories defi...
-
[38]
DeepMath-103K 23 • Publisher: Tencent et al. • Size: 103110 instances • License: MIT • Link: https://huggingface.co/datasets/zwhe99/DeepMath-103K • Description: DeepMath-103K is a large-scale, MIT-licensed dataset comprising 103K chal- lenging mathematical problems tailored for text-to-text and text-generation tasks. Each example includes a problem statem...
-
[39]
DeepSeek-Prover-V1 • Publisher: DeepSeek • Size: 27503 instances • License: deepseek-license • Link: https://huggingface.co/datasets/deepseek-ai/ DeepSeek-Prover-V1 • Description: DeepSeek-Prover-V1 is a large-scale synthetic proof dataset for Lean 4 theo- rem proving. It comprises 8 million formal statements and corresponding proofs generated from high-s...
-
[40]
DialogStudio • Publisher: Salesforce AI et al. • Size: 87 datasets • License: Apache-2.0 • Link: https://huggingface.co/datasets/Salesforce/dialogstudio • Description: DialogStudio is a large-scale, unified collection of dialogue datasets curated to advance conversational AI. It integrates a wide range of domains—such as task-oriented dialogue, open-domai...
-
[41]
DMind_Benchmark • Publisher: Zhejiang Univerisity et al. • Size: 1869 instances • License: - • Link: https://huggingface.co/datasets/DMindAI/DMind_Benchmark • Description: DMind_Benchmark is a comprehensive dataset for evaluating large language models on blockchain, cryptocurrency, and Web3 knowledge. It provides objective (mul- tiple choice) and subjecti...
-
[42]
Dynosaur • Publisher: UCLA et al. 24 • Size: 801900 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/Dynosaur/ dynosaur-sub-superni • Description: Dynosaur introduces a dynamic and low-cost paradigm for curating instruction- tuning datasets. It automatically generates diverse instructions by leveraging metadata from HuggingFace data...
-
[43]
Exploring the Possibilities of AI Prompts Over 200 Ideas
Exploring the Possibilities of AI Prompts Over 200 Ideas • Publisher: Muhammad Bilal • Size: 165 instances • License: MIT • Link: https://github.com/bilalnawaz072/AI-Prompts-200-Ideas • Description: "Exploring the Possibilities of AI Prompts Over 200 Ideas" is a comprehen- sive dataset featuring over 200 prompts spanning diverse marketing and content crea...
-
[44]
Firefly • Publisher: YeungNLP • Size: 1649399 instances • License: - • Link: https://huggingface.co/datasets/YeungNLP/firefly-train-1. 1M • Description: Firefly is a Chinese instruction-tuning dataset comprising 1.15 million high- quality examples drawn from 23 common Chinese natural language processing datasets. Each example includes a task type, an inpu...
-
[45]
Flan 2021 • Publisher: Google Research • Size: 62 datasets • License: Apache-2.0 • Link: https://github.com/google-research/FLAN • Description: The FLAN Instruction Tuning Repository provides datasets and code to generate instruction tuning collections that improve language model generalization and zero-shot performance. Originating with FLAN 2021 and exp...
work page 2021
-
[46]
Flan 2022 • Publisher: Google Research • Size: 1836 datasets • License: Apache-2.0 • Link: https://huggingface.co/datasets/SirNeural/flan_v2 25 • Description: This dataset aggregates tasks from Flan, T0, Super-Natural Instructions, Chain- of-Thought, and Dialog into a training split. Each task is provided in zero-/few-shot and option/no-option formats as ...
work page 2022
-
[47]
Flan-mini • Publisher: Singapore University of Technology and Design • Size: 1.34M instances • License: CC • Link: https://huggingface.co/datasets/declare-lab/flan-mini • Description: Flan-mini is a curated 1.34 M-example subset of the FLAN instruction-tuning collection augmented with code and conversational tasks. It pools 388K Flan2021 in- structions, 3...
-
[48]
GEdit-Bench • Publisher: StepFun • Size: 1212 instances • License: MIT • Link: https://huggingface.co/datasets/stepfun-ai/GEdit-Bench • Description: GEdit-Bench is a novel benchmark dataset designed to facilitate authentic evaluation of general-purpose image editing models. Developed alongside the Step1X-Edit framework, it emphasizes real-world usage scen...
-
[49]
GPT4All • Publisher: nomic-ai • Size: 739259 instances • License: MIT • Link: https://huggingface.co/datasets/nomic-ai/gpt4all_prompt_ generations • Description: The GPT4All dataset comprises 437,604 English prompt-response pairs drawn from diverse sources to facilitate training and fine-tuning of open-source text generation mod- els. It pairs user prompt...
-
[50]
GraphWalks • Publisher: OpenAI • Size: 1150 instances • License: MIT • Link: https://huggingface.co/datasets/openai/graphwalks • Description: GraphWalks is an open-source benchmark dataset designed to evaluate multi- hop reasoning over long graph contexts. Released under the MIT license, it provides directed graphs as edge lists alongside user-specified o...
-
[51]
GSM8K • Publisher: OpenAI • Size: 17584 instances • License: MIT • Link: https://huggingface.co/datasets/openai/gsm8k • Description: GSM8K (Grade School Math 8K) is an English monolingual dataset of 8.8K crowd-sourced grade school math word problems paired with multi-step solutions. It contains a main configuration and a Socratic variant, each offering qu...
-
[52]
HARDMath • Publisher: Harvard University • Size: 1060 instances • License: MIT • Link: https://github.com/sarahmart/HARDMath • Description: HARDMath is a benchmark dataset designed to evaluate advanced mathe- matical reasoning in large language models, focusing on challenging graduate-level applied mathematics problems. Unlike existing benchmarks that emp...
-
[53]
HC3 • Publisher: SimpleAI • Size: 37175 instances • License: CC-BY-SA-4.0 • Link: https://huggingface.co/datasets/Hello-SimpleAI/HC3 • Description: The Human ChatGPT Comparison Corpus (HC3) is the first large-scale bilin- gual dataset enabling direct comparison of human and ChatGPT-generated text. Spanning English and Chinese samples, it encompasses betwe...
-
[54]
hh-rlhf • Publisher: Anthropic • Size: 14M instances • License: MIT • Link: https://github.com/anthropics/hh-rlhf • Description: hh-rlhf provides valuable human preference data focused on helpfulness and harmlessness for training safer AI assistants using Reinforcement Learning from Human Feedback. It includes paired comparison data from base and iterated...
-
[55]
InstructDial • Publisher: Carnegie Mellon University • Size: 59 datasets • License: Apache-2.0 • Link: https://github.com/prakharguptaz/Instructdial 27 • Description: InstructDial is a comprehensive instruction tuning framework designed to improve zero-shot and few-shot generalization in dialogue systems. It unifies 48 diverse dialogue tasks from 59 datas...
-
[56]
InstructionWild_v1 • Publisher: National University of Singapore • Size: 104K instances • License: Non-Commercial Research Purpose • Link: https://github.com/XueFuzhao/InstructionWild • Description: InstructWild is a large-scale, user-sourced instruction dataset comprising over 110K high-quality, diverse instructions collected from real ChatGPT usage shar...
-
[57]
InstructionWild_v2 • Publisher: National University of Singapore • Size: 110K instances • License: Non-Commercial Research Purpose • Link: https://github.com/XueFuzhao/InstructionWild
-
[58]
Intellect-2-RL-Dataset • Publisher: PrimeIntellect • Size: 284741 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/PrimeIntellect/ INTELLECT-2-RL-Dataset • Description: Intellect-2-RL-Dataset is a large-scale collection of 284,741 training examples, designed for reinforcement learning in mathematical and coding problem solving. Each...
-
[59]
LaMini-instruction • Publisher: Monash University et al. • Size: 2585615 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/MBZUAI/ LaMini-instruction • Description: LaMini-Instruction is an English text-to-text generation dataset comprising 2.58M instruction-response pairs distilled from GPT-3.5-Turbo. Each sample includes an instr...
-
[60]
LCCC • Publisher: Tsinghua University et al. • Size: 12M instances • License: MIT • Link: https://huggingface.co/datasets/thu-coai/lccc 28 • Description: LCCC (Large-scale Cleaned Chinese Conversation Corpus) is a monolingual Chinese dialogue dataset with over 12 million conversations collected from social media. A strict and rigorous cleaning pipeline—in...
-
[61]
LIMA-sft • Publisher: Meta AI et al. • Size: 1330 instances • License: CC-BY-NC-SA • Link: https://huggingface.co/datasets/GAIR/lima • Description: The LIMA dataset contains 1,000 high-quality prompt-response pairs designed to align language models with the style of a helpful AI assistant. Prompts are diverse, sourced from Stack Exchange, wikiHow, Writing...
-
[62]
Llama-Nemotron-Post-Training-Dataset • Publisher: NVIDIA • Size: 33011757 instances • License: CC-BY-4.0 • Link: https://huggingface.co/datasets/nvidia/ Llama-Nemotron-Post-Training-Dataset • Description: The Llama-Nemotron-Post-Training-Dataset is a comprehensive dataset of synthetic SFT and RL samples designed to bolster reasoning, code, math, science, ...
-
[63]
LMSYS-Chat-1M • Publisher: UC Berkeley et al. • Size: 1M instances • License: LMSYS-Chat-1M license • Link: https://huggingface.co/datasets/lmsys/lmsys-chat-1m • Description: LMSYS-Chat-1M is a large-scale dataset of one million real-world LLM conver- sations, collected from 210K users interacting with 25 models via Chatbot Arena and Vicuna demo (April-Au...
work page 2023
-
[64]
LongForm • Publisher: LMU Munich et al. • Size: 27739 instances • License: MIT • Link: https://huggingface.co/datasets/akoksal/LongForm • Description: LongForm is a 27K-example English instruction-following dataset under MIT license, for tasks like table QA, summarization, text generation, question answering. It collects human-written documents from C4 (1...
-
[65]
Math_CoT_Arabic_English_Reasoning • Publisher: Miscovery AI • Size: 2834 instances • License: MIT • Link: https://huggingface.co/datasets/miscovery/Math_CoT_ Arabic_English_Reasoning • Description: Math CoT Arabic English Reasoning is a bilingual dataset of 1K-10K meticu- lously curated English and Arabic math problems with explicit chain-of-thought solut...
-
[66]
medical-o1-reasoning-SFT • Publisher: The Chinese University of Hong Kong, Shenzhen et al. • Size: 90120 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/FreedomIntelligence/ medical-o1-reasoning-SFT • Description: medical-o1-reasoning-SFT is a supervised fine-tuning dataset designed to enhance advanced medical reasoning in HuatuoGP...
-
[67]
medical-o1-verifiable-problem • Publisher: The Chinese University of Hong Kong, Shenzhen et al. • Size: 40644 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/FreedomIntelligence/ medical-o1-verifiable-problem • Description: medical-o1-verifiable-problem is an Apache-2.0 licensed dataset comprising open-ended medical reasoning probl...
-
[68]
Medical-R1-Distill-Data • Publisher: The Chinese University of Hong Kong, Shenzhen et al. • Size: 22000 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/FreedomIntelligence/ Medical-R1-Distill-Data • Description: Medical-R1-Distill-Data is an Apache-2.0 licensed instruction fine-tuning dataset distilled from Deepseek-R1’s Full Power...
-
[69]
MedReason • Publisher: UC Santa Cruz et al. • Size: 32682 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/UCSC-VLAA/MedReason • Description: MedReason is a large-scale medical reasoning dataset combining seven clinical question-answer sources with a structured knowledge graph to produce detailed chains of reasoning. It contains 32,...
-
[70]
Medtrinity-25M • Publisher: Huazhong University of Science and Technology et al. • Size: 24922190 instances • License: Mixed • Link: https://huggingface.co/datasets/UCSC-VLAA/MedTrinity-25M • Description: MedTrinity-25M is a large-scale multimodal medical dataset featuring over 25 million images from 10 imaging modalities. It provides multigranular annota...
-
[71]
MMInstruct-GPT4V • Publisher: Shanghai AI Laboratory et al. • Size: 378186 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/yuecao0119/ MMInstruct-GPT4V • Description: MMInstruct-GPT4V is a multilingual multi-modal instruction tuning dataset for visual question answering and image captioning, licensed under Apache-2.0. It comprises ...
-
[72]
Comprised of three core components—148.4K molecule- oriented instructions (e.g
Mol-Instructions • Publisher: Zhejiang University • Size: over 2 million instances • License: CC-BY-4.0 • Link: https://huggingface.co/datasets/zjunlp/Mol-Instructions • Description: Mol-Instructions is an open-access, large-scale biomolecular instruction dataset with 100M-1B examples designed to facilitate instruction-tuning of large language models on c...
-
[73]
MOSS_002_sft_data • Publisher: Fudan University • Size: 1161137 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/fnlp/moss-002-sft-data • Description: MOSS_002_sft_data is an open-source bilingual conversational dataset de- signed for fine-tuning MOSS-002. It encompasses over one million samples in English and Chinese across five ...
-
[74]
MRCR • Publisher: OpenAI • Size: 2400 instances • License: MIT • Link: https://huggingface.co/datasets/openai/mrcr • Description: OpenAI MRCR (Multi-round co-reference resolution) is a long-context bench- mark evaluating LLMs’ ability to find multiple identical requests (“needles”) hidden within multi-turn conversations. Inspired by Gemini’s MRCR, it embe...
-
[75]
NATURAL INSTRUCTIONS • Publisher: Allen Institute for AI et al. • Size: 61 datasets • License: Apache-2.0 • Link: https://huggingface.co/datasets/Muennighoff/ natural-instructions • Description: NATURAL INSTRUCTIONS is a monolingual English dataset derived from Super-Natural-Instructions, offering 1,600+ NLP tasks for training, validation, and testing. Si...
-
[76]
Nemotron-CrossThink • Publisher: NVIDIA • Size: 588645 instances • License: CC-BY-4.0 • Link: https://huggingface.co/datasets/nvidia/ Nemotron-CrossThink • Description: Nemotron-CrossThink is a multi-domain reinforcement learning dataset de- signed to enhance both general-purpose and mathematical reasoning in large language models. It comprises two subset...
-
[77]
New Y orker Caption Ranking • Publisher: University of Wisconsin-Madison et al. • Size: 2183522 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/yguooo/newyorker_ caption_ranking • Description: The New Yorker Caption Ranking dataset comprises over 250 million massive crowdsourced humor ratings on more than 2.2 million captions col...
-
[78]
No Robots • Publisher: Hugging Face H4 • Size: 10000 instances • License: CC-BY-NC-4.0 • Link: https://huggingface.co/datasets/HuggingFaceH4/no_robots • Description: No Robots is a high-quality, human-curated instruction dataset comprising 10,000 examples for supervised fine-tuning of language models. It includes 9,500 training and 500 test instances acro...
-
[79]
NuminaMath-1.5 • Publisher: Numina • Size: 896215 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/AI-MO/NuminaMath-1.5 • Description: NuminaMath-1.5 is an open-source, large-scale post-training dataset compris- ing about 900 000 competition-level mathematics problems paired with chain-of-thought solutions. It covers diverse sources...
-
[80]
It includes over 461,000 quality ratings and more than 10,000 fully annotated trees
OASST1 • Publisher: OpenAssistant • Size: 161443 instances • License: Apache-2.0 • Link: https://huggingface.co/datasets/OpenAssistant/oasst1 • Description: OpenAssistant Conversations (OASST1) is a human-generated, human- annotated corpus with 161,443 messages in 66,497 conversation trees across 35 languages. It includes over 461,000 quality ratings and ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.