AMORE: Adaptive Multi-Output Operator Network for Stiff Chemical Kinetics
Pith reviewed 2026-05-21 21:02 UTC · model grok-4.3
The pith
AMORE learns stiff chemical kinetics by weighting errors per variable and sample while enforcing exact mass conservation through an analytical map.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
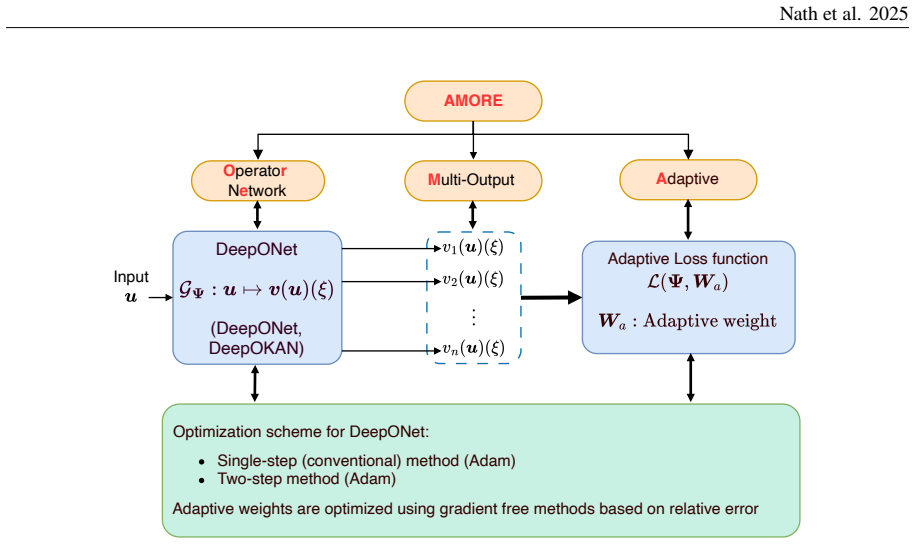
AMORE supplies an operator that maps initial conditions to all thermochemical states using two adaptive loss functions that penalize each state variable and each sample according to its individual error. The trunk is built to satisfy partition of unity, and an invertible analytical map transforms the n-dimensional species mass-fraction vector into an (n-1)-dimensional space so that the unity mass-fraction constraint holds exactly. The adaptive losses are extended to the two-step training procedure for DeepONet with multiple outputs, and the same constraint is also realized via a softmax function in an alternative implementation. The framework is tested on a syngas mechanism (12 states) and G
What carries the argument
Adaptive loss functions that weight errors by both output variable and training sample, paired with an invertible analytical map that reduces the mass-fraction vector while preserving exact unity.
If this is right
- The operator can serve as a drop-in surrogate for stiff integration steps inside CFD codes for turbulent combustion.
- Exact enforcement of the mass-fraction constraint removes unphysical drift that would otherwise accumulate in long integrations.
- The same adaptive-loss and map construction applies directly to other operator architectures such as FNO.
- Two-step training with per-variable and per-sample weighting improves accuracy across all output channels in multi-output stiff problems.
Where Pith is reading between the lines
- If the operator remains accurate on wider ranges of initial conditions, it could enable ensemble or real-time reactive-flow calculations that are currently too expensive.
- The per-variable error weighting idea may transfer to other stiff multi-physics operator-learning tasks such as atmospheric chemistry or plasma kinetics.
- Coupling the surrogate to a fluid solver would still require separate verification that the combined system does not excite numerical instabilities at the fluid-chemistry interface.
Load-bearing premise
The adaptive loss functions and constraint maps, when trained on the chosen mechanisms and initial-condition distributions, will produce accurate long-term predictions for unseen initial states and will remain stable when embedded inside a larger CFD time-stepper.
What would settle it
Integrate the trained operator forward in time from a set of initial conditions withheld from training and check whether species mass fractions remain positive, sum exactly to one, and track a reference stiff integrator within a chosen tolerance over hundreds of steps.
Figures











read the original abstract
Time integration of stiff systems is a primary source of computational cost in combustion, hypersonics, and other reactive transport systems. This stiffness can introduce time scales significantly smaller than those associated with other physical processes, requiring extremely small time steps in explicit schemes or computationally intensive implicit methods. Consequently, strategies to alleviate challenges posed by stiffness are important. While neural operators (DeepONets) can act as surrogates for stiff kinetics, a reliable operator learning strategy is required to appropriately account for differences in error between output variables and samples. Here, we develop AMORE, Adaptive Multi-Output Operator Network, a framework comprising an operator capable of predicting multiple outputs and adaptive loss functions ensuring reliable operator learning. The operator predicts all thermochemical states from given initial conditions. We propose two adaptive loss functions within the framework, considering each state variable's and sample's error to penalize the loss function. We designed the trunk to automatically satisfy Partition of Unity. To enforce unity mass-fraction constraint exactly, we propose an invertible analytical map that transforms the $n$-dimensional species mass-fraction vector into an ($n-1$)-dimensional space. We extend the proposed adaptive loss functions to trunk and branch training in two-step training of DeepONet with multiple outputs. We implemented another unity mass fraction constraint exactly using a softmax function on the predicted mass fraction. We demonstrate efficacy and applicability of our models through two examples: syngas (12 states), GRI-Mech 3.0 (24 active states out of 54). The proposed DeepONet will be a backbone for future CFD studies to accelerate turbulent combustion simulations. AMORE is a general framework, and here, we also demonstrate it for FNO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AMORE, an adaptive multi-output operator network (primarily DeepONet, with an FNO extension) for learning stiff chemical kinetics as a surrogate for time integration. It proposes two adaptive loss functions that reweight errors across output variables and training samples, an invertible analytical map that transforms the n-dimensional mass-fraction vector into an (n-1)-dimensional space to enforce the unity-sum constraint exactly, and a trunk design that satisfies partition of unity. The framework is demonstrated on a 12-state syngas mechanism and a 24-active-species subset of GRI-Mech 3.0, with the stated goal of providing a reliable backbone for accelerating CFD simulations of turbulent combustion.
Significance. If the operator remains stable and accurate under iterative time-stepping on out-of-distribution initial conditions, the work would supply a practical route to replace stiff ODE integrators in reactive-flow solvers with fast, constraint-preserving neural evaluations. The exact analytical mass-fraction map and the per-variable/per-sample adaptive weighting are technically attractive contributions that directly address two common failure modes in multi-output operator learning for chemistry.
major comments (2)
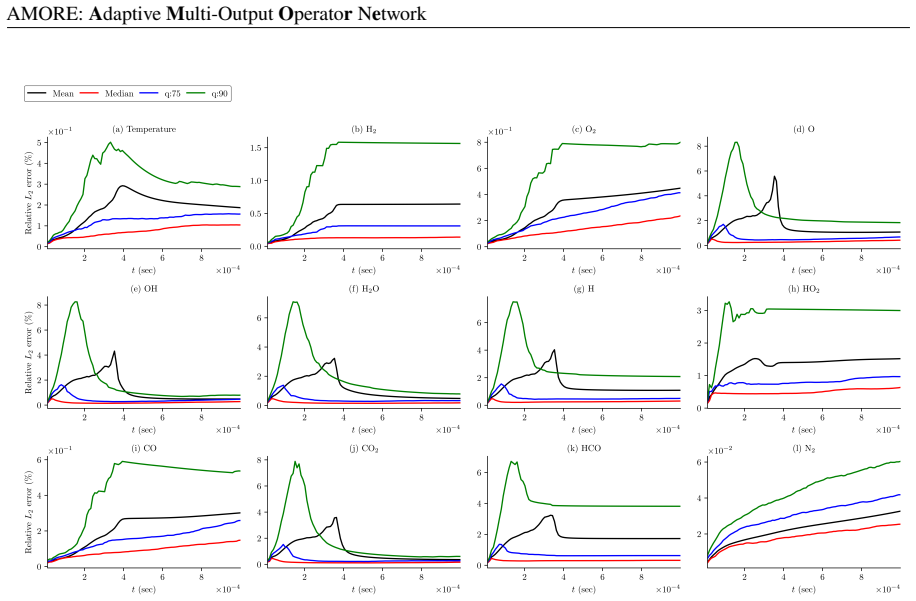
- [§4] §4 (Numerical Results): The reported experiments show one-step and short-horizon accuracy on initial-condition distributions drawn from the training ranges for both syngas and GRI-Mech, together with exact satisfaction of the mass-fraction sum at each output. No closed-loop multi-step rollouts inside an explicit or implicit CFD time-stepper are presented, nor are results for initial states drawn from meaningfully shifted distributions (different pressure, equivalence ratio, or temperature ranges). Because stiffness amplifies per-step errors, these missing tests are load-bearing for the central claim that AMORE supplies a “reliable operator-learning strategy” for stiff kinetics.
- [§3.1–3.2] §3.1–3.2 (Adaptive Loss Functions): The two adaptive loss functions are described at a high level but lack explicit formulas showing how the per-variable and per-sample weights are computed from the current batch errors and whether any additional hyperparameters (e.g., temperature or scaling factors) are introduced. Without these equations it is impossible to assess whether the adaptation is parameter-free or whether it could inadvertently bias the learned operator toward certain species or regimes.
minor comments (2)
- [§3] The manuscript states that the trunk is designed to “automatically satisfy Partition of Unity,” yet the precise architectural modification (e.g., final-layer normalization or activation) is not shown in a figure or equation.
- [§4] Table captions and axis labels in the numerical-results section should explicitly state whether the plotted errors are L2 norms, relative errors, or maximum errors, and over what time horizon the statistics are collected.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and presentation of our work. We address each major comment below and have revised the manuscript accordingly where possible to improve clarity and strengthen the supporting evidence.
read point-by-point responses
-
Referee: [§4] §4 (Numerical Results): The reported experiments show one-step and short-horizon accuracy on initial-condition distributions drawn from the training ranges for both syngas and GRI-Mech, together with exact satisfaction of the mass-fraction sum at each output. No closed-loop multi-step rollouts inside an explicit or implicit CFD time-stepper are presented, nor are results for initial states drawn from meaningfully shifted distributions (different pressure, equivalence ratio, or temperature ranges). Because stiffness amplifies per-step errors, these missing tests are load-bearing for the central claim that AMORE supplies a “reliable operator-learning strategy” for stiff kinetics.
Authors: We acknowledge that closed-loop multi-step rollouts and tests on out-of-distribution initial conditions would provide stronger support for the claim of reliability in CFD contexts, as stiffness can indeed amplify errors over iterations. The current experiments focus on establishing the core contributions—one-step and short-horizon accuracy with exact mass-fraction constraint satisfaction—within the training distribution, which directly validates the adaptive losses, partition-of-unity trunk, and analytical/softmax maps. In the revised manuscript, we have added a dedicated limitations subsection in §4 discussing potential error accumulation in long-term rollouts and included supplementary results for a small number of multi-step predictions. Full CFD integration and extensive OOD testing remain important future directions, as they require coupling with a complete reactive-flow solver. revision: partial
-
Referee: [§3.1–3.2] §3.1–3.2 (Adaptive Loss Functions): The two adaptive loss functions are described at a high level but lack explicit formulas showing how the per-variable and per-sample weights are computed from the current batch errors and whether any additional hyperparameters (e.g., temperature or scaling factors) are introduced. Without these equations it is impossible to assess whether the adaptation is parameter-free or whether it could inadvertently bias the learned operator toward certain species or regimes.
Authors: We appreciate this feedback on the presentation of the adaptive losses. In the original manuscript the weighting mechanism was described conceptually; we have now inserted the explicit formulas into Sections 3.1 and 3.2 of the revised version. The per-variable weight for output dimension j is defined as w_j = (sum_i |e_{i,j}| / N) / (max_k (sum_i |e_{i,k}| / N) + ε), and the per-sample weight for training point i is w_i = (sum_j |e_{i,j}| / M) / (max_l (sum_j |e_{l,j}| / M) + ε), where e denotes the pointwise error, N and M are batch sizes, and ε is a small positive constant (set to 1e-8) to ensure numerical stability. No temperature, scaling, or other tunable hyperparameters are introduced. This formulation is computed directly from the current batch errors, remains essentially parameter-free, and balances contributions across species and samples without manual intervention. revision: yes
- Full closed-loop multi-step rollouts inside an explicit or implicit CFD time-stepper on out-of-distribution initial conditions, as these require integration with a complete reactive-flow solver and substantial additional computational experiments beyond the scope of the present study.
Circularity Check
No significant circularity detected
full rationale
The paper introduces adaptive per-variable and per-sample loss functions plus an invertible analytical map (and softmax alternative) to enforce the mass-fraction unity constraint exactly inside a multi-output DeepONet. These components are defined and trained on data drawn from the syngas and GRI-Mech 3.0 mechanisms; the reported accuracy and constraint satisfaction are measured on held-out samples from the same distributions rather than being tautologically forced by the definitions themselves. No equation or central claim reduces the claimed reliability to a fitted quantity or self-citation chain that is itself unverified; the demonstrations function as external validation against the training distributions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Branch and trunk network weights
axioms (1)
- domain assumption The mapping from initial thermochemical state to future state can be learned by a DeepONet operator
invented entities (2)
-
Adaptive per-variable and per-sample loss functions
no independent evidence
-
Invertible analytical map for mass fractions
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose two adaptive loss functions... invertible analytical map that transforms the n-dimensional species mass-fraction vector into an (n−1)-dimensional space
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design our trunk network to automatically satisfy the partition of unity (PoU) constraint... softmax function
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Kinetic-Mamba: Mamba-Assisted Predictions of Stiff Chemical Kinetics
Mamba-based neural operators predict stiff chemical kinetics evolution with high fidelity from initial states on Syngas and GRI-Mech 3.0 mechanisms.
-
Model synthesis and identifiability analysis of stiff chemical reaction systems with inVAErt networks
Neural emulators and inVAErt networks enable fast forward modeling of stiff chemical kinetics and recovery of non-identifiable reaction-rate manifolds from species concentrations.
Reference graph
Works this paper leans on
-
[1]
U. Maas and S. B. Pope. Simplifying chemical kinetics: Intrinsic low-dimensional manifolds in composition space. Combustion and Flame, 88(3):239–264, 1992. doi: https://doi.org/10.1016/0010-2180(92)90034-M. URL https://www.sciencedirect.com/science/article/pii/001021809290034M. 26 AMORE: Adaptive Multi-Output Operator Network
-
[2]
V. Bykov and U. Maas. The extension of the ildm concept to reaction–diffusion manifolds. Combustion Theory and Modelling, 11(6):839–862, 11 2007. doi: 10.1080/13647830701242531. URL https://doi. org/10.1080/13647830701242531
-
[3]
S. H. Lam and D. A. Goussis. The csp method for simplifying kinetics. International Journal of Chemical Kinetics, 26(4):461–486, 2021/06/10 1994. doi: https://doi.org/10.1002/kin.550260408. URL https: //doi.org/10.1002/kin.550260408
-
[4]
K. S. Jung, C. E. Lacey, H. Babaee, and J. H. Chen. Accelerating high-fidelity simulations of chemically reacting flows using reduced-order modeling with time-dependent bases. Computer Methods in Applied Mechanics and Engineering , 437:117758, 2025. doi: https://doi.org/10.1016/j.cma.2025.117758. URL https://www.sciencedirect.com/science/article/pii/S0045...
-
[5]
Deep learning for scalable chemical kinetics
Alisha J Sharma, Ryan F Johnson, David A Kessler, and Adam Moses. Deep learning for scalable chemical kinetics. In AIAA scitech 2020 forum, page 0181, 2020
work page 2020
-
[6]
Brown, Harbir Antil, Rainald L¨ohner, Fumiya Togashi, and Deepanshu Verma
Thomas S. Brown, Harbir Antil, Rainald L¨ohner, Fumiya Togashi, and Deepanshu Verma. Novel DNNs for Stiff ODEs with Applications to Chemically Reacting Flows. In Heike Jagode, Hartwig Anzt, Hatem Ltaief, and Piotr Luszczek, editors, High Performance Computing, pages 23–39, Cham, 2021. Springer International Publishing. ISBN 978-3-030-90539-2
work page 2021
-
[7]
Physics-informed neural networks and functional interpolation for stiff chemical kinetics
Mario De Florio, Enrico Schiassi, and Roberto Furfaro. Physics-informed neural networks and functional interpolation for stiff chemical kinetics. Chaos (Woodbury, N.Y.), 32, 06 2022. doi: 10.1063/5.0086649
-
[8]
Matthew Frankel, Mario De Florio, Enrico Schiassi, and Lina Sela. Hybrid chemical and data-driven model for stiff chemical kinetics using a physics-informed neural network. Engineering Proceedings, 69(1):40, 2024
work page 2024
-
[9]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019
work page 2019
-
[10]
Enrico Schiassi, Roberto Furfaro, Carl Leake, Mario De Florio, Hunter Johnston, and Daniele Mortari. Extreme theory of functional connections: A fast physics-informed neural network method for solving ordinary and partial differential equations. Neurocomputing, 457:334–356, 2021
work page 2021
-
[11]
Stiff-PINN: Physics-Informed Neural Network for Stiff Chemical Kinetics
Weiqi Ji, Weilun Qiu, Zhiyu Shi, Shaowu Pan, and Sili Deng. Stiff-PINN: Physics-Informed Neural Network for Stiff Chemical Kinetics. The Journal of Physical Chemistry A, 125(36):8098–8106, 2021. doi: 10.1021/acs.jpca.1c05102. URL https://doi.org/10.1021/acs.jpca.1c05102. PMID: 34463510
-
[12]
SVD perspectives for augmenting DeepONet flexibility and interpretability
Simone Venturi and Tiernan Casey. SVD perspectives for augmenting DeepONet flexibility and interpretability. Computer Methods in Applied Mechanics and Engineering, 403:115718, 2023. ISSN 0045-7825. doi: https:// doi.org/10.1016/j.cma.2022.115718. URL https://www.sciencedirect.com/science/article/pii/ S0045782522006739
-
[13]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, mar 2021. ISSN 2522-5839. doi: 10.1038/s42256-021-00302-5. URL http: //dx.doi.org/10.1038/s42256-021-00302-5
-
[14]
Jagtap, Hessam Babaee, Bryan T
Somdatta Goswami, Ameya D. Jagtap, Hessam Babaee, Bryan T. Susi, and George Em Karniadakis. Learning stiff chemical kinetics using extended deep neural operators. Computer Methods in Applied Mechanics and Engineering, 419:116674, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2023.116674. URL https://www.sciencedirect.com/science/article/pii/S00...
-
[15]
Combustion chemistry acceleration with DeepONets.Fuel, 365:131212, 2024
Anuj Kumar and Tarek Echekki. Combustion chemistry acceleration with DeepONets.Fuel, 365:131212, 2024. ISSN 0016-2361. doi: https://doi.org/10.1016/j.fuel.2024.131212. URL https://www.sciencedirect. com/science/article/pii/S0016236124003582
-
[16]
Yuting Weng, Han Li, Hao Zhang, Zhi X. Chen, and Dezhi Zhou. Extended Fourier Neural Operators to learn stiff chemical kinetics under unseen conditions. Combustion and Flame, 272:113847, 2025. ISSN 0010-2180. doi: https://doi.org/10.1016/j.combustflame.2024.113847. URL https://www.sciencedirect. com/science/article/pii/S001021802400556X
-
[17]
G. E. P. Box and D. R. Cox. An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological), 26(2):211–243, 07 1964. ISSN 0035-9246. doi: 10.1111/j.2517-6161.1964.tb00553.x. URL https://doi.org/10.1111/j.2517-6161.1964.tb00553.x
-
[18]
Tianping Chen and Hong Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Transactions on Neural Networks, 6(4):911–917, 1995
work page 1995
-
[19]
MIONet: Learning Multiple-Input Operators via Tensor Product
Pengzhan Jin, Shuai Meng, and Lu Lu. MIONet: Learning Multiple-Input Operators via Tensor Product. SIAM Journal on Scientific Computing , 44(6):A3490–A3514, 2022. doi: 10.1137/22M1477751. URL https://doi.org/10.1137/22M1477751. 27 Nath et al. 2025
-
[20]
Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators (with practical extensions) based on FAIR data. Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2022.114778. URL ...
-
[21]
A Causality-DeepONet for Causal Responses of Linear Dynamical Systems
Lizuo Liu, Kamaljyoti Nath, and Wei Cai. A Causality-DeepONet for Causal Responses of Linear Dynamical Systems. Communications in Computational Physics , 35(5):1194–1228, 2024. ISSN 1991-7120. doi: https://doi.org/10.4208/cicp.OA-2023-0078. URL http://global-sci.org/intro/article_detail/ cicp/23189.html
-
[22]
Min Zhu, Shihang Feng, Youzuo Lin, and Lu Lu. Fourier-DeepONet: Fourier-enhanced deep operator networks for full waveform inversion with improved accuracy, generalizability, and robustness.Computer Methods in Applied Mechanics and Engineering, 416:116300, 2023. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma. 2023.116300. URL https://www.sciencedirect....
-
[23]
Elham Kiyani, Manav Manav, Nikhil Kadivar, Laura De Lorenzis, and George Em Karniadakis. Predicting crack nucleation and propagation in brittle materials using Deep Operator Networks with diverse trunk architectures. Computer Methods in Applied Mechanics and Engineering, 441:117984, 2025. ISSN 0045-7825. doi: 10.1016/j.cma.2025.117984
-
[24]
A Neural Operator-Based Emulator for Regional Shallow Water Dynamics.arXiv pre-print
Peter Rivera-Casillas, Sourav Dutta, Shukai Cai, Mark Loveland, Kamaljyoti Nath, Khemraj Shukla, Corey Trahan, Jonghyun Lee, Matthew Farthing, and Clint Dawson. A Neural Operator-Based Emulator for Regional Shallow Water Dynamics.arXiv pre-print. 2502.14782, 2025. URL https://arxiv.org/abs/2502.14782
-
[25]
Tsai, Umair bin Waheed, Christian Huber, Omer Alpak, Chuen-Song Chen, Ligang Lu, and Amik St-Cyr
Kamaljyoti Nath, Khemraj Shukla, Victor C. Tsai, Umair bin Waheed, Christian Huber, Omer Alpak, Chuen-Song Chen, Ligang Lu, and Amik St-Cyr. Leveraging Deep Operator Networks (DeepONet) for Acoustic Full Waveform Inversion (FWI). arXiv preprint arXiv:2504.10720 , 2025. URL https: //arxiv.org/abs/2504.10720
-
[26]
Generalizing universal function approximators
Irina Higgins. Generalizing universal function approximators. Nature Machine Intelligence, 3(3):192–193, 2021
work page 2021
-
[27]
KAN: Kolmogorov-Arnold Networks
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljaˇci´c, Thomas Y Hou, and Max Tegmark. Kan: Kolmogorov-arnold networks. arXiv preprint arXiv:2404.19756, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Abueidda, Panos Pantidis, and Mostafa E
Diab W. Abueidda, Panos Pantidis, and Mostafa E. Mobasher. DeepOKAN: Deep operator network based on Kolmogorov Arnold networks for mechanics problems. Computer Methods in Applied Mechanics and Engineering, 436:117699, 2025. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2024.117699. URL https://www.sciencedirect.com/science/article/pii/S0045782524009538
-
[29]
Khemraj Shukla, Juan Diego Toscano, Zhicheng Wang, Zongren Zou, and George Em Karniadakis. A comprehensive and FAIR comparison between MLP and KAN representations for differential equations and operator networks. Computer Methods in Applied Mechanics and Engineering, 431:117290, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2024.117290. URL htt...
-
[30]
On the Training and Generalization of Deep Operator Networks
Sanghyun Lee and Yeonjong Shin. On the Training and Generalization of Deep Operator Networks. SIAM Journal on Scientific Computing , 46(4):C273–C296, 2024. doi: 10.1137/23M1598751. URL https://doi.org/10.1137/23M1598751
-
[31]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Ivo Babuˇska and Jens M Melenk. The partition of unity method. International Journal for Numerical Methods in Engineering, 40(4):727–758, 1997
work page 1997
-
[34]
Kookjin Lee, Nathaniel A. Trask, Ravi G. Patel, Mamikon A. Gulian, and Eric C. Cyr. Partition of unity networks: deep hp-approximation. CoRR, abs/2101.11256, 2021. URL https://arxiv.org/abs/2101.11256
-
[35]
Hierarchical partition of unity networks: fast multilevel training
Nathaniel Trask, Amelia Henriksen, Carianne Martinez, and Eric Cyr. Hierarchical partition of unity networks: fast multilevel training. In Mathematical and Scientific Machine Learning, pages 271–286. PMLR, 2022
work page 2022
-
[36]
Ensemble and Mixture-of-Experts DeepONets For Operator Learning
Ramansh Sharma and Varun Shankar. Ensemble and Mixture-of-Experts DeepONets For Operator Learning. arXiv preprint arXiv:2405.11907, 2025
-
[37]
Self-adaptive physics-informed neural networks
Levi D McClenny and Ulisses M Braga-Neto. Self-adaptive physics-informed neural networks. Journal of Computational Physics, 474:111722, 2023
work page 2023
-
[38]
Residual-based attention in physics-informed neural networks
Sokratis J Anagnostopoulos, Juan Diego Toscano, Nikolaos Stergiopulos, and George Em Karniadakis. Residual-based attention in physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 421:116805, 2024. 28 AMORE: Adaptive Multi-Output Operator Network
work page 2024
-
[39]
Physics-informed deep neural operator networks
Somdatta Goswami, Aniruddha Bora, Yue Yu, and George Em Karniadakis. Physics-informed deep neural operator networks. In Timon Rabczuk and Klaus-J¨ urgen Bathe, editors, Machine Learning in Modeling and Simulation: Methods and Applications , pages 219–254. Springer International Publishing, Cham,
-
[40]
doi: 10.1007/978-3-031-36644-4 6
ISBN 978-3-031-36644-4. doi: 10.1007/978-3-031-36644-4 6. URL https://doi.org/10.1007/ 978-3-031-36644-4_6
-
[41]
Shields, and George Em Karniadakis
Katiana Kontolati, Somdatta Goswami, Michael D. Shields, and George Em Karniadakis. On the influence of over-parameterization in manifold based surrogates and deep neural operators. Journal of Computational Physics, 479:112008, April 2023. ISSN 0021-9991. doi: 10.1016/j.jcp.2023.112008. URL http://dx.doi. org/10.1016/j.jcp.2023.112008
-
[42]
Ahmad Peyvan, Vivek Oommen, Ameya D. Jagtap, and George Em Karniadakis. RiemannONets: Interpretable neural operators for Riemann problems. Computer Methods in Applied Mechanics and Engineering , 426:116996, 2024. ISSN 0045-7825. doi: https://doi.org/10.1016/j.cma.2024.116996. URL https: //www.sciencedirect.com/science/article/pii/S0045782524002524
-
[43]
Hanxun Jin, Boyu Zhang, Qianying Cao, Enrui Zhang, Aniruddha Bora, Sridhar Krishnaswamy, George Em Karniadakis, and Horacio D. Espinosa. Characterization and Inverse Design of Stochastic Mechanical Metamaterials Using Neural Operators. Advanced Materials, page 2420063, 2025. ISSN 0935-9648, 1521-4095. doi: 10.1002/adma.202420063
-
[44]
Spectral/hp element methods for computational fluid dynamics
George Karniadakis and Spencer J Sherwin. Spectral/hp element methods for computational fluid dynamics. Oxford University Press, 2005
work page 2005
-
[45]
Amin Paykani, Hamed Chehrmonavari, Athanasios Tsolakis, Terry Alger, William F. Northrop, and Rolf D. Reitz. Synthesis gas as a fuel for internal combustion engines in transportation. Progress in Energy and Combustion Science, 90:100995, 2022. ISSN 0360-1285. doi: https://doi.org/10.1016/j.pecs.2022.100995. URL https://www.sciencedirect.com/science/articl...
-
[46]
David G Goodwin, Harry K Moffat, and Raymond L Speth. Cantera: An Object-oriented Software Toolkit for Chemical Kinetics, Thermodynamics, and Transport Processes. Version 2.3.0. Zenodo, 2017. doi: 10.5281/zenodo.170284
-
[47]
Kamaljyoti Nath, Varun Kumar, Daniel J Smith, and George Em Karniadakis. A Digital Twin for Diesel Engines: Operator-infused Physics-Informed Neural Networks with Transfer Learning for Engine Health Monitoring. arXiv preprint arXiv:2412.11967, 2025. 29 Nath et al. 2025 Appendices • Appendix A: A brief discussion on the network architectures considered in ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.