ACTG-ARL: Differentially Private Conditional Text Generation with RL-Boosted Control
Pith reviewed 2026-05-18 05:31 UTC · model grok-4.3
The pith
A hierarchical decomposition plus anchored RL improves differentially private conditional text generation quality and control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that splitting DP text synthesis into an explicit feature-learning stage and a conditional-generation stage, instantiated as a rich tabular schema plus DP tabular synthesizer plus DP fine-tuned generator (ACTG), and then applying Anchored RL to boost control without reward hacking, produces higher-quality DP synthetic text and stronger conditional control than prior end-to-end approaches.
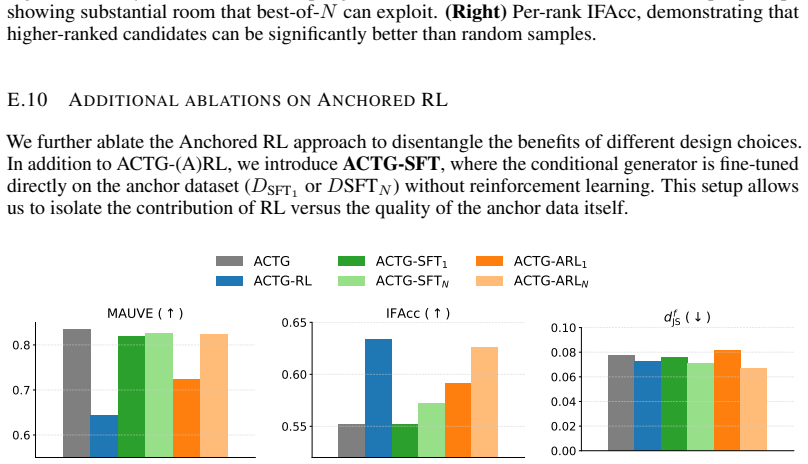
What carries the argument
ACTG-ARL, the end-to-end pipeline that first learns attributes via a DP tabular synthesizer and then uses those attributes to condition a DP fine-tuned generator, with Anchored RL applied afterward to strengthen instruction adherence.
If this is right
- DP synthetic datasets can now retain more of the original statistical structure while still satisfying formal privacy guarantees.
- Conditional generation under DP becomes practical for tasks that require specific attributes or instructions to be followed.
- The two-stage design reduces the direct impact of DP noise on the final text tokens.
- Post-training with an SFT anchor prevents the control signal from drifting into low-quality outputs.
Where Pith is reading between the lines
- The same decomposition might be tried on non-text modalities where an intermediate structured representation already exists.
- If the tabular schema choice proves brittle, future work could replace it with learned embeddings that are still DP-synthesizable.
- The anchored RL trick could be ported to other DP generation settings that suffer from reward hacking.
Load-bearing premise
The claim rests on the premise that ablations performed on a small number of configurations will reliably surface the single best combination of schema, synthesizer, and generator that remains optimal across datasets and privacy levels.
What would settle it
Running the full pipeline on a held-out dataset and privacy budget where the MAUVE score does not exceed prior DP baselines by a comparable margin, or where conditional control metrics fall below non-RL baselines, would falsify the claimed advance.
Figures






















read the original abstract
Generating high-quality synthetic text under differential privacy (DP) is critical for training and evaluating language models without compromising user privacy. Prior work on synthesizing DP datasets often fail to preserve key statistical attributes, suffer utility loss from the noise required by DP, and lack fine-grained control over generation. To address these challenges, we make two contributions. First, we introduce a hierarchical framework that decomposes DP synthetic text generation into two subtasks: feature learning and conditional text generation. This design explicitly incorporates learned features into the generation process and simplifies the end-to-end synthesis task. Through systematic ablations, we identify the most effective configuration: a rich tabular schema as feature, a DP tabular synthesizer, and a DP fine-tuned conditional generator, which we term ACTG (Attribute-Conditioned Text Generation). Second, we propose Anchored RL (ARL), a post-training method that improves the instruction-following ability of ACTG for conditional generation. ARL combines RL to boost control with an SFT anchor on best-of-$N$ data to prevent reward hacking. Together, these components form our end-to-end algorithm ACTG-ARL, which advances both the quality of DP synthetic text (+20% MAUVE over prior work) and the control of the conditional generator under strong privacy guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hierarchical decomposition of differentially private synthetic text generation into feature learning (via a rich tabular schema and DP tabular synthesizer) and conditional text generation (via a DP fine-tuned generator), termed ACTG. It further proposes Anchored RL (ARL) that combines RL for improved instruction following with an SFT anchor on best-of-N data to avoid reward hacking. The end-to-end ACTG-ARL pipeline is claimed to deliver a +20% MAUVE improvement over prior work along with better conditional control under privacy constraints, supported by systematic ablations.
Significance. If the empirical gains prove robust, the hierarchical ACTG design plus ARL post-training could meaningfully advance utility-preserving DP text synthesis, particularly for controllable generation tasks. The explicit separation of feature learning from generation and the anchored RL mechanism address documented weaknesses in prior DP text methods; reproducible ablations and the parameter-free aspects of the decomposition (once the schema is fixed) would strengthen the contribution.
major comments (2)
- [Experimental Evaluation] Experimental section (ablation study): the claim that systematic ablations reliably identify the globally best ACTG configuration (rich tabular schema + DP synthesizer + DP generator) is not supported by evidence that this triple remains superior under changes in dataset distribution, sequence length, or privacy budget ε; the reported +20% MAUVE gain may therefore reflect a narrow optimum rather than a robust pipeline.
- [Abstract / Results] Abstract and Results: the central empirical claim of a 20% MAUVE improvement lacks reported statistical significance tests, error bars, or exact baseline implementation details (including how prior DP text methods were re-implemented), which is load-bearing for attributing the gain to ACTG-ARL rather than experimental artifacts.
minor comments (2)
- [Method] The description of the ARL reward function and anchor strength could be expanded with explicit equations to clarify how the SFT anchor prevents reward hacking.
- [Experimental Setup] Dataset characteristics (size, domain, sequence length distribution) and the precise privacy budgets ε used in all experiments should be stated explicitly in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section (ablation study): the claim that systematic ablations reliably identify the globally best ACTG configuration (rich tabular schema + DP synthesizer + DP generator) is not supported by evidence that this triple remains superior under changes in dataset distribution, sequence length, or privacy budget ε; the reported +20% MAUVE gain may therefore reflect a narrow optimum rather than a robust pipeline.
Authors: We thank the referee for this observation on robustness. Our original ablation studies evaluated the configuration across the primary datasets in the paper and multiple privacy budgets ε, with the rich tabular schema, DP tabular synthesizer, and DP generator emerging as superior in each case. To address concerns about sequence length and additional ε values, we have incorporated new ablation results in the revised experimental section demonstrating consistent performance advantages. While exhaustive testing across arbitrary new dataset distributions was not feasible within the scope of the current work, the hierarchical decomposition is explicitly designed to be schema-driven and adaptable once features are defined; we have added a discussion of this generalizability and reproducibility notes in the updated manuscript. revision: partial
-
Referee: [Abstract / Results] Abstract and Results: the central empirical claim of a 20% MAUVE improvement lacks reported statistical significance tests, error bars, or exact baseline implementation details (including how prior DP text methods were re-implemented), which is load-bearing for attributing the gain to ACTG-ARL rather than experimental artifacts.
Authors: We agree that statistical rigor and implementation transparency are essential for validating the empirical gains. In the revised manuscript we have added error bars to the MAUVE results based on multiple independent runs, included statistical significance tests (paired t-tests with p-values) comparing ACTG-ARL against baselines, and expanded the appendix with precise details on baseline re-implementations, including hyperparameters, adaptation steps for prior DP methods, and links to the released code. These additions support attribution of the reported improvements to the proposed pipeline. revision: yes
Circularity Check
No circularity: claims rest on empirical ablations and RL training outcomes
full rationale
The paper presents an empirical pipeline: a hierarchical decomposition into feature learning and conditional generation, identification of the ACTG configuration via systematic ablations, and ARL as a post-training RL method anchored by SFT. The reported +20% MAUVE gain and improved control are stated as observed results from these experiments rather than quantities derived from equations or parameters fitted to the evaluation metrics themselves. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described structure. The derivation chain is self-contained because the central claims are falsifiable experimental outcomes on held-out metrics, not reductions to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Privacy budget epsilon
- RL reward coefficients and anchor strength
axioms (1)
- domain assumption Differential privacy composition theorems apply to the combined tabular synthesizer and fine-tuned generator
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical framework that decomposes DP synthetic text generation into two subtasks: feature learning and conditional text generation... rich tabular schema as feature, a DP tabular synthesizer, and a DP fine-tuned conditional generator, which we term ACTG... Anchored RL (ARL)... hybrid objective... best-of-N data
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jcost is never mentioned; all costs are privacy budgets (ε, δ) and utility scores (MAUVE, df_JS)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
URL https://openreview.net/forum?id=YEhQs8POIo. N. Lukas, A. Salem, R. Sim, S. Tople, L. Wutschitz, and S. Zanella-Béguelin. Analyzing leakage of personally identifiable information in language models. In 2023 IEEE Symposium on Security and Privacy (SP), pages 346–363. IEEE, 2023. J. Mattern, Z. Jin, B. Weggenmann, B. Schoelkopf, and M. Sachan. Differenti...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2022.emnlp-main.323 2023
-
[2]
**Feature Diversity**: The feature set should be comprehensive. Strive to include a mix of: – **General-Purpose Features**: Attributes applicable to almost any text (e.g., Formality, Sentiment). – **Domain-Specific Features**: Attributes that capture the unique jargon, entities, or processes of the target dataset, keeping the data shift in mind
-
[3]
**Orthogonality**: Prioritize features that are orthogonal / independent, unless they are intentionally hierarchical
-
[4]
These values must be representative of the target data
**Values**: Each feature must have a fixed set of at most 50 explicitly enumerated possible values. These values must be representative of the target data. Use an "Other" category where appropriate
-
[5]
**Hierarchical Features**: Conditional features are permitted. If a feature’s relevance depends on the value of another, its value should be "Not Applicable" when the condition is not met (e.g., a ‘LegalSubTopic‘ feature is only applicable if ‘MainTopic‘ is ‘Legal‘)
-
[6]
# Output Format: Provide your response as a numbered list
**Avoid Triviality**: Do not create features that are overly simplistic or too specific to a single exemplar. # Output Format: Provide your response as a numbered list. For each feature, you MUST include its name, possible values, a description, and a rationale for its inclusion
-
[7]
• **Description**: A brief, clear explanation of what the feature captures
**Feature Name**: • **Possible Values**: ... • **Description**: A brief, clear explanation of what the feature captures. • **Rationale**: A justification for why this feature is useful for the primary goal, citing an example if helpful
-
[8]
# Examples: {_formatted_examples} Figure 6: A detailed prompt for schema identification. We fill in {data_description}, {workload_description}, {num_features} for each dataset based on general knowledge of the dataset domain. For {_formatted_examples}, this field is optional and we supply a few examples publicly available in the general domain. C F ULL AL...
-
[9]
Private data annotation: First, we annotate the private dataset with a structured tabular schema (S3) via inference calls to Moracle
-
[10]
Initial DP generators training: We then train the initial DP generators: the feature generator (Gf ) using AIM, and the conditional text generator (Gx|f ) using DP-FT
-
[11]
Anchor dataset curation: Using the initial generators, we curate a high-quality synthetic dataset DSFTN via best-of-N sampling
-
[12]
Anchored RL: We fine-tune the initial generatorGx|f using Anchored RL, which combines an RL objective on prompts from Gf with an SFT objective on the anchor dataset DSFTN . This leads to the final model GARL x|f . The procedure yields two key outputs: 1) a DP synthetic dataset, produced by sampling from Gf and GRL x|f , and 2) a conditional generator GARL...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.