Insights into the Unknown: Federated Data Diversity Analysis on Molecular Data
Pith reviewed 2026-05-18 04:15 UTC · model grok-4.3
The pith
Federated clustering with chemistry-informed metrics assesses molecular data diversity across private silos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
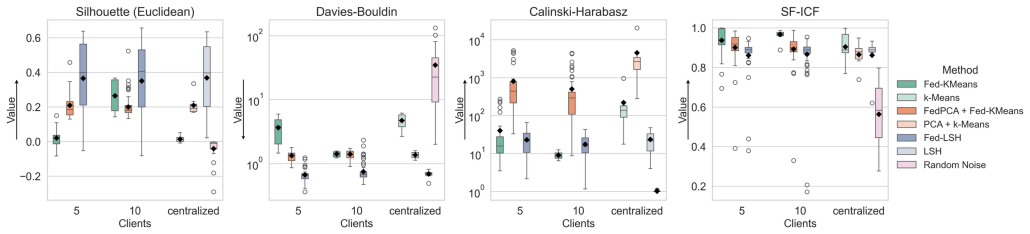
We benchmark Federated kMeans, Federated PCA combined with Fed-kMeans, and Federated Locality-Sensitive Hashing against their centralized counterparts on eight diverse molecular datasets. Evaluation with standard mathematical metrics and the introduced SF-ICF chemistry-informed metric, plus in-depth explainability analysis, demonstrates that incorporating domain knowledge through chemistry-informed metrics and on-client explainability analyses is essential for federated diversity analysis on molecular data.
What carries the argument
The SF-ICF chemistry-informed metric together with on-client explainability analyses applied to federated clustering methods for representing the structure of distributed molecular data.
Load-bearing premise
Federated clustering methods can accurately disentangle and represent the structure of the combined chemical space across data silos without direct access to all data.
What would settle it
A side-by-side test in which a centralized clustering recovers known chemical clusters from the full combined dataset that none of the federated methods recover when the same data is partitioned across clients.
Figures



read the original abstract
AI methods are increasingly shaping pharmaceutical drug discovery. However, their translation to industrial applications remains limited due to their reliance on public datasets, lacking scale and diversity of proprietary pharmaceutical data. Federated learning (FL) offers a promising approach to integrate private data into privacy-preserving, collaborative model training across data silos. This federated data access complicates important data-centric tasks such as estimating dataset diversity, performing informed data splits, and understanding the structure of the combined chemical space. To address this gap, we investigate how well federated clustering methods can disentangle and represent distributed molecular data. We benchmark three approaches, Federated kMeans (Fed-kMeans), Federated Principal Component Analysis combined with Fed-kMeans (Fed-PCA+Fed-kMeans), and Federated Locality-Sensitive Hashing (Fed-LSH), against their centralized counterparts on eight diverse molecular datasets. Our evaluation utilizes both, standard mathematical and a chemistry-informed evaluation metrics, SF-ICF, that we introduce in this work. The large-scale benchmarking combined with an in-depth explainability analysis shows the importance of incorporating domain knowledge through chemistry-informed metrics, and on-client explainability analyses for federated diversity analysis on molecular data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates federated clustering methods for privacy-preserving diversity analysis on distributed molecular datasets. It benchmarks Fed-kMeans, Fed-PCA+Fed-kMeans, and Fed-LSH against centralized counterparts on eight molecular datasets, introduces the chemistry-informed SF-ICF metric, and performs on-client explainability analyses to argue that domain knowledge is essential for meaningful global insights into combined chemical space.
Significance. If the central claims hold under realistic heterogeneity, the work is significant for pharmaceutical applications where proprietary data silos prevent pooled analysis. The large-scale benchmarking, new SF-ICF metric, and emphasis on explainability provide concrete guidance on when federated methods can approximate global chemical-space structure without direct data sharing.
major comments (1)
- §5 (Experimental Evaluation): The central claim that the federated methods enable meaningful global insights rests on their ability to recover (or approximate) the clustering structure of the pooled data. However, the reported splits across the eight datasets do not include controlled non-IID partitions by chemical class, scaffold, or property range. In such regimes Fed-kMeans and Fed-LSH can converge to spurious local modes; without explicit tests demonstrating robustness under disjoint molecular subspaces, the benchmarking does not fully substantiate the claim that the methods disentangle the combined chemical space.
minor comments (3)
- Abstract: The SF-ICF metric is introduced without a one-sentence definition or expansion; please supply a brief description on first use so readers immediately grasp its chemistry-informed character.
- §3.2 (Fed-LSH description): The adaptation of locality-sensitive hashing to molecular fingerprints (e.g., choice of hash family, number of tables, and distance metric) is only sketched; add the precise parameter settings used in the experiments.
- Figure 4 (explainability panels): The on-client SHAP or attention visualizations would benefit from explicit annotation of which molecular substructures drive the diversity scores, to strengthen the domain-knowledge argument.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the major comment point by point below and outline the revisions we will make to strengthen the experimental evaluation.
read point-by-point responses
-
Referee: §5 (Experimental Evaluation): The central claim that the federated methods enable meaningful global insights rests on their ability to recover (or approximate) the clustering structure of the pooled data. However, the reported splits across the eight datasets do not include controlled non-IID partitions by chemical class, scaffold, or property range. In such regimes Fed-kMeans and Fed-LSH can converge to spurious local modes; without explicit tests demonstrating robustness under disjoint molecular subspaces, the benchmarking does not fully substantiate the claim that the methods disentangle the combined chemical space.
Authors: We agree that controlled non-IID partitions would provide a stronger test of robustness. Our original experiments used random partitioning across clients to reflect realistic pharmaceutical data silos, where distributions are not deliberately aligned with chemical classes or scaffolds. We acknowledge this does not fully address the most heterogeneous regimes. In the revision we will add new experiments with partitions stratified by molecular scaffolds and property ranges, reporting both standard and SF-ICF metrics. These results will be included in an expanded Section 5 to demonstrate that the federated methods still approximate centralized structure under such conditions. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper reports empirical benchmarking of three federated clustering methods (Fed-kMeans, Fed-PCA+Fed-kMeans, Fed-LSH) against centralized counterparts across eight molecular datasets, using both standard metrics and a newly introduced chemistry-informed metric SF-ICF. No mathematical derivations, equations, or predictions are presented that reduce by construction to fitted parameters or self-referential definitions. The evaluation relies on external comparisons to centralized results and on-client explainability, providing independent grounding rather than any self-definition or load-bearing self-citation chain. The central claims about the value of domain-informed metrics for federated diversity analysis are supported by these direct empirical contrasts and do not collapse into the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We benchmark three approaches, Federated kMeans (Fed-kMeans), Federated Principal Component Analysis combined with Fed-kMeans (Fed-PCA+Fed-kMeans), and Federated Locality-Sensitive Hashing (Fed-LSH)... introduce... SF-ICF
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Accurate structure prediction of biomolec- ular interactions with alphafold 3,
J. Abramson, J. Adleret al., “Accurate structure prediction of biomolec- ular interactions with alphafold 3,”Nature, vol. 630, no. 8016, pp. 493– 500, 2024
work page 2024
-
[2]
Large-scale chemical language repre- sentations capture molecular structure and properties,
J. Ross, B. Belgodereet al., “Large-scale chemical language repre- sentations capture molecular structure and properties,”Nature Machine Intelligence, vol. 4, no. 12, pp. 1256–1264, 2022
work page 2022
-
[3]
As alphafold runs out of data, drug firms make their own model,
E. Callaway, “As alphafold runs out of data, drug firms make their own model,”Nature, vol. 640, p. 297, 2025
work page 2025
-
[4]
W. Heyndrickx, L. Mervinet al., “Melloddy: cross-pharma federated learning at unprecedented scale unlocks benefits in qsar without com- promising proprietary information,”Journal of chemical information and modeling, vol. 64, no. 7, pp. 2331–2344, 2023
work page 2023
-
[5]
Splitting chemical structure data sets for federated privacy-preserving machine learning,
J. Simm, L. Humbecket al., “Splitting chemical structure data sets for federated privacy-preserving machine learning,”Journal of cheminfor- matics, vol. 13, pp. 1–14, 2021
work page 2021
-
[6]
On the best way to cluster nci-60 molecules,
S. Hern ´andez-Hern´andez and P. J. Ballester, “On the best way to cluster nci-60 molecules,”Biomolecules, vol. 13, no. 3, p. 498, 2023
work page 2023
-
[7]
Deep clustering of small molecules at large-scale via variational autoencoder embedding and k-means,
H. Hadipour, C. Liuet al., “Deep clustering of small molecules at large-scale via variational autoencoder embedding and k-means,”BMC bioinformatics, vol. 23, no. Suppl 4, p. 132, 2022
work page 2022
-
[8]
Chemmine tools: an online service for analyzing and clustering small molecules,
T. W. Backman, Y . Caoet al., “Chemmine tools: an online service for analyzing and clustering small molecules,”Nucleic acids research, vol. 39, no. suppl 2, pp. W486–W491, 2011
work page 2011
-
[9]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healyet al., “Umap: Uniform manifold approx- imation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
work page 2008
-
[11]
Visualization of very large high- dimensional data sets as minimum spanning trees,
D. Probst and J.-L. Reymond, “Visualization of very large high- dimensional data sets as minimum spanning trees,”Journal of Chemin- formatics, vol. 12, no. 1, p. 12, 2020
work page 2020
-
[12]
A. A. Orlov, T. N. Akhmetshinet al., “From high dimensions to human insight: Exploring dimensionality reduction for chemical space visualization,”Molecular Informatics, vol. 44, no. 1, p. e202400265, 2025
work page 2025
-
[13]
Federated t-sne and umap for distributed data visualization,
D. Qiao, X. Maet al., “Federated t-sne and umap for distributed data visualization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 19, 2025, pp. 20 014–20 023
work page 2025
-
[14]
Federated k-means clustering: A novel edge ai based approach for privacy preservation,
H. H. Kumar, V . Karthiket al., “Federated k-means clustering: A novel edge ai based approach for privacy preservation,” in2020 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM). IEEE, 2020, pp. 52–56
work page 2020
-
[15]
S. Garst and M. Reinders, “Federated k-means clustering,” inInterna- tional Conference on Pattern Recognition. Springer, 2024, pp. 107–122
work page 2024
-
[16]
Federated spectral clustering via secure similarity reconstruction,
D. Qiao, C. Dinget al., “Federated spectral clustering via secure similarity reconstruction,”Advances in Neural Information Processing Systems, vol. 36, pp. 58 520–58 555, 2023
work page 2023
-
[17]
Federated principal com- ponent analysis,
A. Grammenos, R. Mendoza Smithet al., “Federated principal com- ponent analysis,”Advances in neural information processing systems, vol. 33, pp. 6453–6464, 2020
work page 2020
-
[18]
Similarity search in high dimensions via hashing,
A. Gionis, P. Indyket al., “Similarity search in high dimensions via hashing,” inVldb, vol. 99, no. 6, 1999, pp. 518–529
work page 1999
-
[19]
D. Butina, “Unsupervised data base clustering based on daylight’s finger- print and tanimoto similarity: A fast and automated way to cluster small and large data sets,”Journal of Chemical Information and Computer Sciences, vol. 39, no. 4, pp. 747–750, 1999
work page 1999
-
[20]
Pharmabench: Enhancing admet benchmarks with large language models,
Z. Niu, X. Xiaoet al., “Pharmabench: Enhancing admet benchmarks with large language models,”Scientific Data, vol. 11, no. 1, p. 985, 2024
work page 2024
-
[21]
The scaffold tree- visualization of the scaffold universe by hierarchical scaffold classification,
A. Schuffenhauer, P. Ertlet al., “The scaffold tree- visualization of the scaffold universe by hierarchical scaffold classification,”Journal of chemical information and modeling, vol. 47, no. 1, pp. 47–58, 2007
work page 2007
-
[22]
Extended-connectivity fingerprints,
D. Rogers and M. Hahn, “Extended-connectivity fingerprints,”Journal of chemical information and modeling, vol. 50, no. 5, pp. 742–754, 2010
work page 2010
-
[23]
G. Landrum, “Rdkit documentation,”Release, vol. 1, no. 1-79, p. 4, 2013
work page 2013
-
[24]
k-means++: The advantages of careful seeding,
D. Arthur and S. Vassilvitskii, “k-means++: The advantages of careful seeding,” Stanford, Tech. Rep., 2006
work page 2006
-
[25]
Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,
P. J. Rousseeuw, “Silhouettes: a graphical aid to the interpretation and validation of cluster analysis,”Journal of computational and applied mathematics, vol. 20, pp. 53–65, 1987
work page 1987
-
[26]
A dendrite method for cluster analysis,
T. Cali ´nski and J. Harabasz, “A dendrite method for cluster analysis,” Communications in Statistics-theory and Methods, vol. 3, no. 1, pp. 1– 27, 1974
work page 1974
-
[27]
D. L. Davies and D. W. Bouldin, “A cluster separation measure,”IEEE transactions on pattern analysis and machine intelligence, no. 2, pp. 224–227, 2009
work page 2009
-
[28]
Nonlinear dimensionality reduction and mapping of compound libraries for drug discovery,
M. Reutlinger and G. Schneider, “Nonlinear dimensionality reduction and mapping of compound libraries for drug discovery,”Journal of Molecular Graphics and Modelling, vol. 34, pp. 108–117, 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.