Contribution of task-irrelevant stimuli to drift of neural representations
Pith reviewed 2026-05-18 05:12 UTC · model grok-4.3
The pith
Task-irrelevant stimuli that learners ignore still produce gradual long-term drift in representations of relevant stimuli.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In an online learning setup with a mixed stream of inputs, the component of the data that the agent learns to treat as irrelevant still injects persistent noise into synaptic updates, producing cumulative drift in the representation of the relevant component. This occurs under Oja's rule, similarity matching, autoencoder gradient descent, and supervised two-layer networks, with the drift rate scaling positively with the variance and dimensionality of the irrelevant subspace.
What carries the argument
Online weight updates on a continuous mixed stream of task-relevant and task-irrelevant vectors, where the irrelevant subspace contributes additive noise to the representation of the relevant subspace despite being ignored for the task objective.
If this is right
- Drift rate grows monotonically with the variance and dimension of the task-irrelevant data subspace.
- The effect appears consistently across Hebbian learning rules and stochastic gradient descent applied to autoencoders and supervised networks.
- Geometry and dimension scaling of drift differ qualitatively from those produced by additive Gaussian synaptic noise.
- Drift measurements could be used to infer which aspects of the input an agent is treating as irrelevant in a given context.
Where Pith is reading between the lines
- If the mechanism holds, artificial lifelong learners may need explicit input segregation rather than relying solely on learning to ignore irrelevant features.
- The same drift source could interact with other noise processes in real neural circuits, producing observable signatures that combine both.
- Experimental designs that control the statistics of distractor stimuli during learning could test whether drift rates match the predicted dependence on irrelevant variance.
Load-bearing premise
Learning proceeds by continuous weight updates on an unsegregated stream of relevant and irrelevant stimuli, with no separate gating or blocking mechanism that would stop irrelevant inputs from influencing the updates.
What would settle it
Record drift magnitude in a network or brain region while parametrically varying the variance or dimension of added task-irrelevant stimuli; if the observed drift rate fails to increase with that variance or dimension, the proposed mechanism is falsified.
Figures





read the original abstract
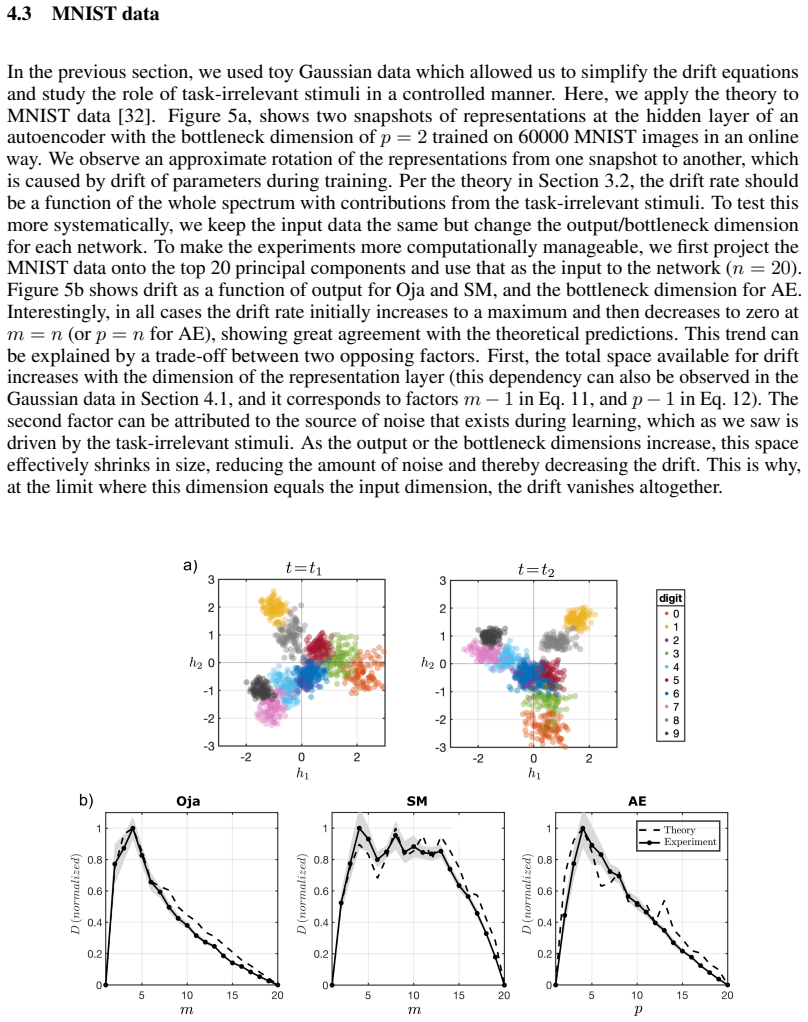
Biological and artificial learners are inherently exposed to a stream of data and experience throughout their lifetimes and must constantly adapt to, learn from, or selectively ignore the ongoing input. Recent findings reveal that, even when the performance remains stable, the underlying neural representations can change gradually over time, a phenomenon known as representational drift. Studying the different sources of data and noise that may contribute to drift is essential for understanding lifelong learning in neural systems. However, a systematic study of drift across architectures and learning rules, and the connection to task, are missing. Here, in an online learning setup, we characterize drift as a function of data distribution, and specifically show that the learning noise induced by task-irrelevant stimuli, which the agent learns to ignore in a given context, can create long-term drift in the representation of task-relevant stimuli. Using theory and simulations, we demonstrate this phenomenon both in Hebbian-based learning -- Oja's rule and Similarity Matching -- and in stochastic gradient descent applied to autoencoders and a supervised two-layer network. We consistently observe that the drift rate increases with the variance and the dimension of the data in the task-irrelevant subspace. We further show that this yields different qualitative predictions for the geometry and dimension-dependency of drift than those arising from Gaussian synaptic noise. Overall, our study links the structure of stimuli, task, and learning rule to representational drift and could pave the way for using drift as a signal for uncovering underlying computation in the brain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that in an online mixed-stream learning setup, task-irrelevant stimuli induce learning noise that produces long-term representational drift in task-relevant stimuli even after the system has learned to ignore the irrelevant inputs for task performance. This is demonstrated via theory and simulations across Hebbian rules (Oja's rule, similarity matching) and SGD on autoencoders plus a supervised two-layer network, with the drift rate increasing as a function of variance and dimension in the irrelevant subspace and yielding distinct geometric predictions from those of Gaussian synaptic noise.
Significance. If the central results hold, the work supplies a concrete, input-driven mechanism for representational drift under stable behavior, directly linking stimulus statistics, task structure, and learning rule. The cross-architecture simulations and explicit contrast with synaptic-noise predictions are strengths that could generate falsifiable experimental tests in neuroscience; the absence of free parameters in the core derivations further strengthens the contribution.
major comments (1)
- [Simulation results (supervised network and autoencoder)] Simulation results for the supervised two-layer network and autoencoder: the central claim requires that task performance remains high and flat after initial convergence while drift continues indefinitely in the relevant subspace. The manuscript provides no explicit numerical check (e.g., loss/accuracy trajectories or subspace projection metrics over long timescales) confirming that performance plateaus in the mixed-stream regime; without this, it is unclear whether the irrelevant inputs truly leave task performance unaffected while still driving ongoing weight updates.
minor comments (2)
- [Abstract] Abstract: the term 'learning noise' is used without an immediate operational definition; a brief parenthetical clarifying that it refers to the residual Hebbian/SGD updates from the irrelevant component would improve immediate readability.
- [Methods] Methods: data-generation and update-rule parameters (learning rates, subspace variances, input dimensions, number of trials) should be tabulated for each architecture to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for identifying an important point regarding the clarity of our simulation results. We address the major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Simulation results (supervised network and autoencoder)] Simulation results for the supervised two-layer network and autoencoder: the central claim requires that task performance remains high and flat after initial convergence while drift continues indefinitely in the relevant subspace. The manuscript provides no explicit numerical check (e.g., loss/accuracy trajectories or subspace projection metrics over long timescales) confirming that performance plateaus in the mixed-stream regime; without this, it is unclear whether the irrelevant inputs truly leave task performance unaffected while still driving ongoing weight updates.
Authors: We agree that explicit verification of stable task performance alongside ongoing drift is essential for supporting the central claim. In the simulations presented, task performance (measured via loss or accuracy) converges rapidly and remains high and flat in the mixed-stream regime, while drift in the task-relevant subspace persists due to the ongoing updates from irrelevant inputs. However, we acknowledge that the manuscript does not include dedicated long-timescale trajectories or subspace projection metrics to make this explicit. In the revised version, we will add figures showing performance metrics (e.g., loss/accuracy) and relevant subspace projections over extended training periods for both the supervised network and autoencoder. These will confirm that performance plateaus while drift continues, directly addressing the concern and clarifying that irrelevant inputs drive weight updates without degrading task performance. revision: yes
Circularity Check
No significant circularity; drift characterization follows directly from standard update rules on mixed data streams
full rationale
The paper derives representational drift by applying standard learning rules (Oja's rule, similarity matching, SGD on autoencoders and supervised networks) to an online stream containing both task-relevant and task-irrelevant stimuli. Drift rate is shown to increase with variance and dimension of the irrelevant subspace through explicit theory and simulations. No load-bearing step reduces by construction to a fitted parameter, self-defined quantity, or self-citation chain; the central claim is obtained by direct substitution of the mixed input distribution into the update equations without re-labeling inputs as predictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Continuous online exposure to a data stream containing both task-relevant and task-irrelevant stimuli
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
drift rate increases with the variance and the dimension of the data in the task-irrelevant subspace
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decompose the dynamics near a point θ̃ on the solution manifold into local normal (N) and tangential (T) spaces
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
work page 2019
-
[2]
Timo Flesch, Andrew Saxe, and Christopher Summerfield. Continual task learning in natural and artificial agents.Trends in neurosciences, 46(3):199–210, 2023
work page 2023
-
[3]
Representational drift in primary olfactory cortex.Nature, pages 1–6, 2021
Carl E Schoonover, Sarah N Ohashi, Richard Axel, and Andrew JP Fink. Representational drift in primary olfactory cortex.Nature, pages 1–6, 2021
work page 2021
-
[4]
Long-term dynamics of ca1 hippocampal place codes.Nature neuroscience, 16(3):264–266, 2013
Yaniv Ziv, Laurie D Burns, Eric D Cocker, Elizabeth O Hamel, Kunal K Ghosh, Lacey J Kitch, Ab- bas El Gamal, and Mark J Schnitzer. Long-term dynamics of ca1 hippocampal place codes.Nature neuroscience, 16(3):264–266, 2013
work page 2013
-
[5]
Causes and consequences of representational drift.Current opinion in neurobiology, 58:141–147, 2019
Michael E Rule, Timothy O’Leary, and Christopher D Harvey. Causes and consequences of representational drift.Current opinion in neurobiology, 58:141–147, 2019
work page 2019
-
[6]
Representational drift in the mouse visual cortex.Current Biology, 31(19):4327–4339, 2021
Daniel Deitch, Alon Rubin, and Yaniv Ziv. Representational drift in the mouse visual cortex.Current Biology, 31(19):4327–4339, 2021
work page 2021
-
[7]
Laura N Driscoll, Lea Duncker, and Christopher D Harvey. Representational drift: Emerging theories for continual learning and experimental future directions.Current Opinion in Neurobiology, 76:102609, 2022
work page 2022
-
[8]
Drifting neuronal representations: Bug or feature? Biological cybernetics, pages 1–14, 2022
Paul Masset, Shanshan Qin, and Jacob A Zavatone-Veth. Drifting neuronal representations: Bug or feature? Biological cybernetics, pages 1–14, 2022
work page 2022
-
[9]
Shanshan Qin, Shiva Farashahi, David Lipshutz, Anirvan M Sengupta, Dmitri B Chklovskii, and Cengiz Pehlevan. Coordinated drift of receptive fields in hebbian/anti-hebbian network models during noisy representation learning.Nature Neuroscience, pages 1–11, 2023
work page 2023
-
[10]
Kyle Aitken, Marina Garrett, Shawn Olsen, and Stefan Mihalas. The geometry of representational drift in natural and artificial neural networks.PLOS Computational Biology, 18(11):e1010716, 2022
work page 2022
-
[11]
Representational drift as a result of implicit regularization
Aviv Ratzon, Dori Derdikman, and Omri Barak. Representational drift as a result of implicit regularization. Elife, 12:RP90069, 2024
work page 2024
-
[12]
Maanasa Natrajan and James E Fitzgerald. Stability through plasticity: Finding robust memories through representational drift.bioRxiv, pages 2024–12, 2024
work page 2024
-
[13]
Jens-Bastian Eppler, Thomas Lai, Dominik Aschauer, Simon Rumpel, and Matthias Kaschube. Representa- tional drift reflects ongoing balancing of stochastic changes by hebbian learning.bioRxiv, pages 2025–01, 2025
work page 2025
-
[14]
Representational drift as the consequence of ongoing memory storage.bioRxiv, pages 2024–06, 2024
Federico Devalle, Licheng Zou, Gloria Cecchini, and Alex Roxin. Representational drift as the consequence of ongoing memory storage.bioRxiv, pages 2024–06, 2024
work page 2024
-
[15]
Network plasticity as bayesian inference.PLoS computational biology, 11(11):e1004485, 2015
David Kappel, Stefan Habenschuss, Robert Legenstein, and Wolfgang Maass. Network plasticity as bayesian inference.PLoS computational biology, 11(11):e1004485, 2015
work page 2015
-
[16]
Motor learning with unstable neural representations.Neuron, 54(4):653–666, 2007
Uri Rokni, Andrew G Richardson, Emilio Bizzi, and H Sebastian Seung. Motor learning with unstable neural representations.Neuron, 54(4):653–666, 2007. 11
work page 2007
-
[17]
Charles Micou and Timothy O’Leary. Representational drift as a window into neural and behavioural plasticity.Current opinion in neurobiology, 81:102746, 2023
work page 2023
-
[18]
Gianluigi Mongillo, Simon Rumpel, and Yonatan Loewenstein. Intrinsic volatility of synaptic connec- tions—a challenge to the synaptic trace theory of memory.Current opinion in neurobiology, 46:7–13, 2017
work page 2017
-
[19]
David Kappel, Robert Legenstein, Stefan Habenschuss, Michael Hsieh, and Wolfgang Maass. A dynamic connectome supports the emergence of stable computational function of neural circuits through reward- based learning.eneuro, 5(2), 2018
work page 2018
-
[20]
Three Factors Influencing Minima in SGD
Stanislaw Jastrzkebski, Zachary Kenton, Devansh Arpit, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amos Storkey. Three factors influencing minima in sgd.arXiv preprint arXiv:1711.04623, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects.arXiv preprint arXiv:1803.00195, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Pratik Chaudhari and Stefano Soatto. Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks. In2018 Information Theory and Applications Workshop (ITA), pages 1–10. IEEE, 2018
work page 2018
-
[23]
Fluctuation-dissipation relations for stochastic gradient descent
Sho Yaida. Fluctuation-dissipation relations for stochastic gradient descent.arXiv preprint arXiv:1810.00004, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
What happens after SGD reaches zero loss? –a mathemati- cal framework
Zhiyuan Li, Tianhao Wang, and Sanjeev Arora. What happens after SGD reaches zero loss? –a mathemati- cal framework. InInternational Conference on Learning Representations, 2022
work page 2022
-
[25]
Stochastic gradient descent-induced drift of representation in a two-layer neural network
Farhad Pashakhanloo and Alexei Koulakov. Stochastic gradient descent-induced drift of representation in a two-layer neural network. InInternational Conference on Machine Learning, pages 27401–27419. PMLR, 2023
work page 2023
-
[26]
Erkki Oja. Simplified neuron model as a principal component analyzer.Journal of mathematical biology, 15:267–273, 1982
work page 1982
-
[27]
Introduction to the theory of neural computation, 1991
John Hertz, Anders Krogh, Richard G Palmer, and Heinz Horner. Introduction to the theory of neural computation, 1991
work page 1991
-
[28]
Stochastic Gradient Descent as Approximate Bayesian Inference
Stephan Mandt, Matthew D Hoffman, and David M Blei. Stochastic gradient descent as approximate bayesian inference.arXiv preprint arXiv:1704.04289, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Alan Edelman, Tomás A Arias, and Steven T Smith. The geometry of algorithms with orthogonality constraints.SIAM journal on Matrix Analysis and Applications, 20(2):303–353, 1998
work page 1998
-
[30]
Cengiz Pehlevan, Anirvan M Sengupta, and Dmitri B Chklovskii. Why do similarity matching objectives lead to hebbian/anti-hebbian networks?Neural computation, 30(1):84–124, 2017
work page 2017
-
[31]
Pierre Baldi and Kurt Hornik. Neural networks and principal component analysis: Learning from examples without local minima.Neural networks, 2(1):53–58, 1989
work page 1989
-
[32]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
work page 1998
-
[33]
Luis M Franco and Michael J Goard. Differential stability of task variable representations in retrosplenial cortex.Nature Communications, 15(1):6872, 2024
work page 2024
-
[34]
Stimulus-dependent representational drift in primary visual cortex
Tyler D Marks and Michael J Goard. Stimulus-dependent representational drift in primary visual cortex. Nature communications, 12(1):1–16, 2021
work page 2021
-
[35]
Gal Elyasaf, Alon Rubin, and Yaniv Ziv. Novel off-context experience constrains hippocampal representa- tional drift.Current Biology, 34(24):5769–5773, 2024
work page 2024
-
[36]
Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks.arXiv preprint arXiv:1312.6120, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[37]
Daniel Kunin, Javier Sagastuy-Brena, Lauren Gillespie, Eshed Margalit, Hidenori Tanaka, Surya Ganguli, and Daniel LK Yamins. The limiting dynamics of sgd: Modified loss, phase-space oscillations, and anomalous diffusion.Neural Computation, 36(1):151–174, 2023. 12
work page 2023
-
[38]
Zico Kolter, and Ameet Talwalkar
Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability.arXiv preprint arXiv:2103.00065, 2021
-
[39]
Nitzan Geva, Daniel Deitch, Alon Rubin, and Yaniv Ziv. Time and experience differentially affect distinct aspects of hippocampal representational drift.Neuron, 111(15):2357–2366, 2023
work page 2023
-
[40]
Dan Rokni, Vivian Hemmelder, Vikrant Kapoor, and Venkatesh N Murthy. An olfactory cocktail party: figure-ground segregation of odorants in rodents.Nature neuroscience, 17(9):1225–1232, 2014
work page 2014
-
[41]
Crispin W Gardiner et al.Handbook of stochastic methods, volume 3. springer Berlin, 1985. 13 Appendix • A: Summary of Framework . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 • B: Oja Derivations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
work page 1985
-
[42]
Replacing the above and the corresponding λµ,ν H in Eq
Here, xµ =v T µ x is a component of stimulus in the principal subspace, and xν =v T m+νx a component in the task-irrelevant subspace. Replacing the above and the corresponding λµ,ν H in Eq. 20, we obtain the covariance of fluctuations associated with this subspace: ⟨ρ2 µ,ν⟩= η⟨x2 µx2 m+ν⟩ 2(λµ −λ m+ν) = ηλm+ν 2(1− λm+ν λµ ) µ∈[m], ν∈[n−m],(30) and the oth...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.