From Evidence to Verdict: An Agent-Based Forensic Framework for AI-Generated Image Detection
Pith reviewed 2026-05-18 02:01 UTC · model grok-4.3
The pith
A multi-agent forensic framework detects AI-generated images by debating evidence from multiple tools without any model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
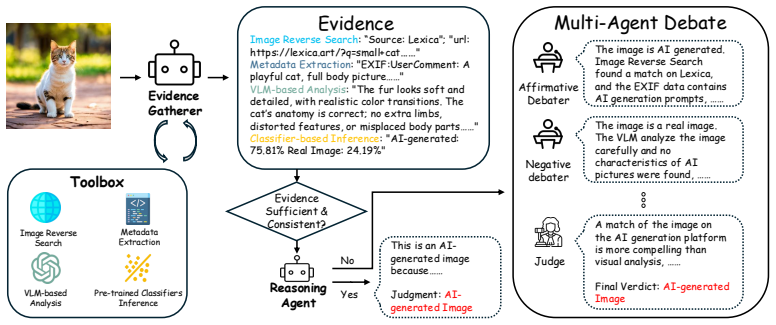
AIFo formulates AI-generated image detection as a multi-stage forensic analysis process through multi-agent collaboration that integrates reverse image search, metadata extraction, pre-trained classifiers, and vision-language model analysis, resolving insufficient or conflicting evidence through a structured multi-agent debate mechanism, achieving 97.05% accuracy on a 6,000-image benchmark spanning controlled and real-world scenarios.
What carries the argument
The multi-agent debate mechanism, which structures collaboration among agents to reconcile conflicting forensic evidence from diverse tools.
Load-bearing premise
That the structured debate among agents can consistently produce accurate verdicts even when the individual forensic tools provide insufficient or conflicting information.
What would settle it
Observing a set of AI-generated images where the agents reach an incorrect verdict due to unresolved conflicts in the evidence from the tools.
Figures





read the original abstract
The rapid evolution of AI-generated images poses growing challenges to information integrity and media authenticity. Existing detection approaches face limitations in robustness, interpretability, and generalization across diverse generative models, particularly when relying on a single source of visual evidence. We introduce AIFo (Agent-based Image Forensics), a training-free framework that formulates AI-generated image detection as a multi-stage forensic analysis process through multi-agent collaboration. The framework integrates a set of forensic tools, including reverse image search, metadata extraction, pre-trained classifiers, and vision-language model analysis, and resolves insufficient or conflicting evidence through a structured multi-agent debate mechanism. An optional memory-augmented module further enables the framework to incorporate information from historical cases. We evaluate AIFo on a benchmark of 6,000 images spanning controlled laboratory settings and challenging real-world scenarios, where it achieves 97.05% accuracy and consistently outperforms traditional classifiers and strong vision-language model baselines. These findings demonstrate the effectiveness of agent-based procedural reasoning for AI-generated image detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AIFo, a training-free agent-based framework for detecting AI-generated images. It integrates forensic tools including reverse image search, metadata extraction, pre-trained classifiers, and vision-language models, then employs a structured multi-agent debate to resolve insufficient or conflicting evidence, with an optional memory-augmented module for historical cases. The framework is evaluated on a 6,000-image benchmark spanning laboratory and real-world scenarios, reporting 97.05% accuracy and consistent outperformance over traditional classifiers and strong VLM baselines.
Significance. If the multi-agent debate reliably converts tool outputs into correct verdicts, the work offers a promising direction for interpretable, generalizable, and training-free detection methods that combine multiple evidence sources. The explicit avoidance of fitted parameters and reliance on external pre-trained tools is a clear strength that supports broader applicability across generative models.
major comments (2)
- [§5] §5 (Evaluation): The central claim of 97.05% accuracy and outperformance is reported without error bars, confidence intervals, or statistical significance tests against baselines. This omission makes it impossible to determine whether the gains are robust or could be explained by variance in the 6,000-image benchmark.
- [§3.2] §3.2 (Multi-agent Debate Mechanism): The robustness argument rests on the debate resolving conflicts among reverse search, metadata, classifiers, and VLMs, yet no ablation studies (e.g., replacing debate with majority vote or single-VLM decision) or quantitative metrics on conflict frequency and resolution success are provided. Without these, the contribution of the agent component remains unproven and is the weakest link in the generalization claim.
minor comments (2)
- [Abstract] Abstract and §4: The benchmark is described as covering 'controlled laboratory settings and challenging real-world scenarios' but lacks explicit enumeration of the generative models, image sources, or construction protocol, which would aid reproducibility.
- [Figure 1] Figure 1 (Framework Overview): The diagram would benefit from clearer labeling of the debate stages and information flow between agents to improve readability for readers unfamiliar with multi-agent systems.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments highlight important aspects regarding the statistical rigor of our evaluation and the validation of the multi-agent component. We provide detailed responses to each major comment and indicate the revisions planned for the next version of the paper.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The central claim of 97.05% accuracy and outperformance is reported without error bars, confidence intervals, or statistical significance tests against baselines. This omission makes it impossible to determine whether the gains are robust or could be explained by variance in the 6,000-image benchmark.
Authors: We agree that the current presentation lacks error bars, confidence intervals, and statistical significance tests, which weakens the ability to assess robustness. In the revised manuscript we will add 95% bootstrap confidence intervals for all reported accuracies on the 6,000-image benchmark and will include paired statistical tests (McNemar’s test) comparing AIFo to each baseline. These results will appear in Section 5 together with the existing accuracy figures. revision: yes
-
Referee: [§3.2] §3.2 (Multi-agent Debate Mechanism): The robustness argument rests on the debate resolving conflicts among reverse search, metadata, classifiers, and VLMs, yet no ablation studies (e.g., replacing debate with majority vote or single-VLM decision) or quantitative metrics on conflict frequency and resolution success are provided. Without these, the contribution of the agent component remains unproven and is the weakest link in the generalization claim.
Authors: We acknowledge the value of explicit ablations to isolate the contribution of the multi-agent debate. We will add experiments that replace the debate with majority voting and with single-VLM decisions, and we will report quantitative metrics on conflict frequency across evidence sources and on the fraction of conflicts successfully resolved by the debate. These new results and analysis will be placed in Section 3.2 and in an expanded evaluation subsection. revision: yes
Circularity Check
No significant circularity; framework relies on external tools and rules
full rationale
The paper presents AIFo as a training-free framework that integrates pre-existing forensic tools (reverse search, metadata, classifiers, VLMs) and applies a structured multi-agent debate to resolve conflicts. No equations, fitted parameters, or self-referential definitions appear in the description. Performance claims rest on evaluation against an external 6000-image benchmark rather than any internal reduction of outputs to inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked that would make the central claims tautological. The method is self-contained against external components and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forensic tools (reverse search, metadata, classifiers, VLMs) produce complementary or reconcilable evidence that multi-agent debate can integrate into reliable verdicts.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AIFo ... formulates AI-generated image detection as a multi-stage forensic analysis process through multi-agent collaboration ... resolves insufficient or conflicting evidence through a structured multi-agent debate mechanism.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrates ... reverse image search, metadata extraction, pre-trained classifiers, and vision-language model analysis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Authenticated Contradictions from Desynchronized Provenance and Watermarking
C2PA manifests and AI watermarks can independently validate contradictory claims on the same asset, and a cross-layer audit protocol resolves this with 100% accuracy on 3500 images.
-
HEDGE: Heterogeneous Ensemble for Detection of AI-GEnerated Images in the Wild
HEDGE is a heterogeneous ensemble using progressive DINOv3 training, multi-scale features, and MetaCLIP2 diversity with dual-gating fusion to achieve robust AI-generated image detection and 4th place in the NTIRE 2026...
Reference graph
Works this paper leans on
-
[1]
AI Image Detector.https://huggingface.co/ haywoodsloan/ai-image-detector-deploy. 5
-
[2]
Anime Image Detector.https://huggingface.co/ legekka/AI-Anime-Image-Detector-ViT. 6
- [3]
-
[4]
Flickr.https://flickr.com. 6, 7
-
[5]
Google CLoud Vision.https://cloud.google.com/ vision?hl=en. 5
- [6]
- [7]
- [8]
-
[9]
co/NYUAD-ComNets/NYUAD_AI-generated_images_ detector
NYUAD AI Image Detector.https://huggingface. co/NYUAD-ComNets/NYUAD_AI-generated_images_ detector. 6
-
[10]
SDXL-Detector.https://huggingface.co/Organika/ sdxl-detector. 6
-
[11]
SMOGY AI Image Detector.https://huggingface.co/ Smogy/SMOGY-Ai-images-detector. 6
-
[12]
Wikimedia Commons.https://commons.wikimedia.org. 6, 7
-
[13]
As Social Media Guardrails Fade and AI Deepfakes Go Mainstream, Experts Warn of Impact on Elec- tions.https://apnews.com/article/election- 2024-misinformation-ai-social-media-trump- 6119ee6f498db10603b3664e9ad3e87e, 2023. 1
work page 2024
-
[14]
NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study
Eirikur Agustsson and Radu Timofte. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In IEEE Conference on Computer Vision and Pattern Recogni- tion Workshops (CVPRW), pages 1122–1131. IEEE, 2017. 6, 7
work page 2017
- [15]
-
[16]
You-Ming Chang, Chen Yeh, Wei-Chen Chiu, and Ning Yu. AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors.CoRR abs/2310.17419, 2023. 13
-
[17]
Zero-Shot Detection of AI-Generated Im- ages
Davide Cozzolino, Giovanni Poggi, Matthias Nießner, and Luisa Verdoliva. Zero-Shot Detection of AI-Generated Im- ages. InEuropean Conference on Computer Vision (ECCV), pages 54–72. Springer, 2024. 1
work page 2024
-
[18]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. InIEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 248–255. IEEE, 2009. 6, 7
work page 2009
-
[19]
Tenen- baum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenen- baum, and Igor Mordatch. Improving Factuality and Reason- ing in Language Models through Multi-Agent Debate. InIn- ternational Conference on Machine Learning (ICML). JMLR,
-
[20]
Theory is All You Need: AI, Human Cognition, and Causal Reasoning.Strategy Sci- ence, 2024
Teppo Felin and Matthias Holweg. Theory is All You Need: AI, Human Cognition, and Causal Reasoning.Strategy Sci- ence, 2024. 3 14
work page 2024
-
[21]
Denoising Diffu- sion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffu- sion Probabilistic Models. InAnnual Conference on Neural Information Processing Systems (NeurIPS). NeurIPS, 2020. 1
work page 2020
-
[22]
MetaGPT: Meta Programming for A Multi-Agent Collabo- rative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta Programming for A Multi-Agent Collabo- rative Framework. InInternational Conference on Learning Representations (ICLR). JMLR, 2024. 13
work page 2024
-
[23]
Tanzib Hosain, Salman Rahman, Md
Md. Tanzib Hosain, Salman Rahman, Md. Kishor Morol, and Md. Rizwan Parvez. Xolver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team. CoRR abs/2506.14234, 2025. 11
-
[24]
Holopix50k: A Large-Scale In-the-wild Stereo Image Dataset
Yiwen Hua, Puneet Kohli, Pritish Uplavikar, Anand Ravi, Saravana Gunaseelan, Jason Orozco, and Edward Li. Holopix50k: A Large-Scale In-the-wild Stereo Image Dataset. CoRR abs/2003.11172, 2020. 6, 7
-
[25]
Tianyi Huang, Jingyuan Yi, Peiyang Yu, and Xiaochuan Xu. Unmasking Digital Falsehoods: A Comparative Analysis of LLM-Based Misinformation Detection Strategies.CoRR abs/2503.00724, 2025. 13
-
[26]
Yikun Ji, Yan Hong, Jiahui Zhan, Haoxing Chen, Jun Lan, Huijia Zhu, Weiqiang Wang, Liqing Zhang, and Jianfu Zhang. Towards Explainable Fake Image Detection with Multi-Modal Large Language Models.CoRR abs/2504.14245, 2025. 1, 13
-
[27]
Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics
Shan Jia, Reilin Lyu, Kangran Zhao, Yize Chen, Zhiyuan Yan, Yan Ju, Chuanbo Hu, Xin Li, Baoyuan Wu, and Siwei Lyu. Can ChatGPT Detect DeepFakes? A Study of Using Multimodal Large Language Models for Media Forensics. In IEEE Conference on Computer Vision and Pattern Recogni- tion Workshops (CVPRW), pages 4324–4333. IEEE, 2024. 13
work page 2024
-
[28]
Analyzing and Improving the Image Quality of StyleGAN
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and Improving the Image Quality of StyleGAN. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 8107–
- [29]
- [30]
-
[31]
Yixuan Li, Xuelin Liu, Xiaoyang Wang, Bu Sung Lee, Shiqi Wang, Anderson Rocha, and Weisi Lin. FakeBench: Prob- ing Explainable Fake Image Detection via Large Multimodal Models.CoRR abs/2404.13306, 2024. 1, 2, 6, 7, 13, 20
-
[32]
Improving Multi- Agent Debate with Sparse Communication Topology
Yunxuan Li, Yibing Du, Jiageng Zhang, Le Hou, Peter Grabowski, Yeqing Li, and Eugene Ie. Improving Multi- Agent Debate with Sparse Communication Topology. InCon- ference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 7281–7294. ACL, 2024. 2
work page 2024
-
[33]
Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate. InConference on Em- pirical Methods in Natural Language Processing (EMNLP), pages 17889–17904. ACL, 2024. 2
work page 2024
-
[34]
MIND: A Multi-agent Framework for Zero-shot Harmful Meme Detection
Ziyan Liu, Chunxiao Fan, Haoran Lou, Yuexin Wu, and Kai- wei Deng. MIND: A Multi-agent Framework for Zero-shot Harmful Meme Detection. InAnnual Meeting of the Asso- ciation for Computational Linguistics (ACL), pages 923–947. ACL, 2025. 2, 13
work page 2025
-
[35]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards Photorealistic Image Genera- tion and Editing with Text-Guided Diffusion Models.CoRR abs/2112.10741, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[36]
Qian Niu, Junyu Liu, Ziqian Bi, Pohsun Feng, Benji Peng, Keyu Chen, and Ming Li. Large Language Models and Cog- nitive Science: A Comprehensive Review of Similarities, Dif- ferences, and Challenges.CoRR abs/2409.02387, 2024. 3
-
[37]
GPT-4o.https://openai.com/index/hello- gpt-4o/
OpenAI. GPT-4o.https://openai.com/index/hello- gpt-4o/. 2, 8, 20
-
[38]
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Julia Hockenmaier, and Svetlana Lazeb- nik. Flickr30k Entities: Collecting Region-to-Phrase Corre- spondences for Richer Image-to-Sentence Models. InIEEE International Conference on Computer Vision (ICCV), pages 2641–2649. IEEE, 2015. 2, 6, 7
work page 2015
-
[39]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rom- bach. SDXL: Improving Latent Diffusion Models for High- Resolution Image Synthesis.CoRR abs/2307.01952, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763. PMLR, 2021. 11, 13
work page 2021
-
[41]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical Text-Conditional Image Gen- eration with CLIP Latents.CoRR abs/2204.06125, 2022. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
High-Resolution Image Syn- thesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Syn- thesis with Latent Diffusion Models. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695. IEEE, 2022. 1, 6, 7
work page 2022
-
[43]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding.CoRR abs/2205.11487, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Zeyang Sha, Zheng Li, Ning Yu, and Yang Zhang. DE-FAKE: Detection and Attribution of Fake Images Generated by Text- to-Image Diffusion Models.CoRR abs/2210.06998, 2022. 1, 2, 7, 8, 13, 20
-
[45]
ZeroFake: Zero-Shot Detection of Fake Images Generated and Edited by Text-to-Image Generation Models
Zeyang Sha, Yicong Tan, Mingjie Li, Michael Backes, and Yang Zhang. ZeroFake: Zero-Shot Detection of Fake Images Generated and Edited by Text-to-Image Generation Models. InACM SIGSAC Conference on Computer and Communica- tions Security (CCS), pages 4852–4866. ACM, 2024. 13
work page 2024
-
[46]
Shoaib, Zefan Wang, Milad Taleby Ahvanooey, and Jun Zhao
Mohamed R. Shoaib, Zefan Wang, Milad Taleby Ahvanooey, and Jun Zhao. Deepfakes, Misinformation, and Disinforma- tion in the Era of Frontier AI, Generative AI, and Large AI Models. InInternational Conference on Computer and Appli- cations (ICCA), pages 1–7. IEEE, 2023. 1 15
work page 2023
-
[47]
Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D
Andries P. Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D. Barrett, and Arnu Pretorius. Should we be going MAD? A Look at Multi-Agent Debate Strategies for LLMs. InInternational Conference on Machine Learning (ICML). JMLR, 2024. 2
work page 2024
-
[48]
Media Forensics and DeepFakes: An Overview.Journal of Selected Topics in Signal Processing,
Luisa Verdoliva. Media Forensics and DeepFakes: An Overview.Journal of Selected Topics in Signal Processing,
-
[49]
Jiarui Wang, Huiyu Duan, Juntong Wang, Ziheng Jia, Woo Yi Yang, Xiaorong Zhu, Yu Zhao, Jiaying Qian, Yuke Xing, Guangtao Zhai, and Xiongkuo Min. DFBench: Benchmarking Deepfake Image Detection Capability of Large Multimodal Models.CoRR abs/2506.03007, 2025. 1, 13
-
[50]
Meng, Zibin Zheng, Liang Chen, and Bingzhe Wu
Qichao Wang, Tian Bian, Yian Yin, Tingyang Xu, Hong Cheng, Helen M. Meng, Zibin Zheng, Liang Chen, and Bingzhe Wu. Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale.CoRR abs/2310.11778, 2023. 13
-
[51]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. CNN-Generated Images Are Surprisingly Easy to Spot... for Now. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 8692–8701. IEEE, 2020. 1, 2, 7, 8, 13, 20
work page 2020
-
[52]
DIRE for Diffusion-Generated Image Detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li. DIRE for Diffusion-Generated Image Detection. InIEEE International Conference on Computer Vision (ICCV), pages 22388–22398. IEEE, 2023. 1, 13
work page 2023
-
[53]
Reverse Im- age Retrieval Cues Parametric Memory in Multimodal LLMs
Jialiang Xu, Michael Moor, and Jure Leskovec. Reverse Im- age Retrieval Cues Parametric Memory in Multimodal LLMs. CoRR abs/2405.18740, 2024. 5
-
[54]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). ICLR, 2023. 13
work page 2023
-
[55]
Peipeng Yu, Jianwei Fei, Hui Gao, Xuan Feng, Zhihua Xia, and Chip-Hong Chang. Unlocking the Capabilities of Vision- Language Models for Generalizable and Explainable Deep- fake Detection.CoRR abs/2503.14853, 2025. 1, 13
-
[56]
Autodefense: Multi-agent LLM defense against jailbreak attacks,
Yifan Zeng, Yiran Wu, Xiao Zhang, Huazheng Wang, and Qingyun Wu. AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks.CoRR abs/2403.04783, 2024. 13
-
[57]
Nan Zhong, Yiran Xu, Sheng Li, Zhenxing Qian, and Xinpeng Zhang. PatchCraft: Exploring Texture Patch for Efficient AI- generated Image Detection.CoRR abs/2311.12397, 2024. 1, 7, 8, 13, 20
-
[58]
Ziyin Zhou, Yunpeng Luo, Yuanchen Wu, Ke Sun, Jiayi Ji, Ke Yan, Shouhong Ding, Xiaoshuai Sun, Yunsheng Wu, and Rongrong Ji. AIGI-Holmes: Towards Explainable and Gener- alizable AI-Generated Image Detection via Multimodal Large Language Models.CoRR abs/2507.02664, 2025. 1, 13
-
[59]
GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image
Mingjian Zhu, Hanting Chen, Qiangyu Yan, Xudong Huang, Guanyu Lin, Wei Li, Zhijun Tu, Hailin Hu, Jie Hu, and Yunhe Wang. GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image. InAnnual Conference on Neural Infor- mation Processing Systems (NeurIPS). NeurIPS, 2023. 2, 6, 7, 20 A Prompts Used in Our Framework This appendix documents the exact...
work page 2023
-
[61]
analysis_details: A detailed analysis explaining your decision Table 10: Second prompt template for the Reasoning Agent. evaluates the sufficiency of each debate round and can decide to terminate the debate early if the arguments are deemed suf- ficient. Table 13 and Table 14 are the prompt templates used to instruct the LLM: A.5 VLM Analysis Tool Prompt ...
-
[62]
If one side’s evidence is strong and the other’s is weak or has been effectively countered, the information is likely sufficient
-
[63]
If both sides have presented compelling but con- flicting evidence that has not yet been reconciled, more analysis is needed
-
[64]
If the discussion become repetitive, further rounds are unlikely to be productive. Based on these criteria, decide if you have enough information to make a high-confidence final judgment. Answer ’True’ if sufficient, ’False’ if more debate and analysis would be helpful. Table 13: First prompt template for the Judge Agent. 18 You are an AI Image Forensics ...
-
[65]
Weigh the Evidence: Identify the most compelling piece of evidence from EACH side
-
[66]
Resolve the Core Conflict: Directly address the central disagreement
-
[67]
State Your Final Conclusion: Based on your analysis, provide a clear final verdict. Required output format:
-
[68]
is_ai_generated: boolean (True if AI-generated, False if real image)
-
[69]
Table 14: Second prompt template for the Judge Agent
analysis_details: A detailed analysis explaining your decision Format the response as a structured object. Table 14: Second prompt template for the Judge Agent. As a professional AI image detector, please analyze this image carefully:
-
[70]
Determine if this is an AI-generated image or a real image. - Real images include images that are created by humans, including photographs captured by cameras, photos that have been edited with software such as Pho- toshop, or human artistic creations such as hand-drawn sketches and paintings. - AI-generated images include images that are fully or partial...
-
[71]
If you determine it’s an AI-generated image, please specifically identify and list the visual artifacts or characteristics that indicate AI generation, such as: - Unnatural textures or patterns - Inconsistent lighting or shadows - Anatomical errors in humans or animals - Unusual distortions or blending of elements - Text or writing abnormalities - Symmetr...
-
[72]
If you determine it’s a real image, explain what characteristics support this conclusion
-
[73]
Table 15: Prompt template for the VLM Analysis Tool
Provide your final classification with confidence level (high, medium, or low). Table 15: Prompt template for the VLM Analysis Tool. 19 Table 16: Metadata fields and prefixes considered in the analysis tool. Category Field / Prefix Description Exact Key Fields XMP:CreatorTool Creator tool Software used to generate or edit the image. EXIF:Software Software...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.