Online Continual Learning on Intel Loihi 2 via a Co-designed Spiking Neural Network
Pith reviewed 2026-05-18 01:06 UTC · model grok-4.3
The pith
CLP-SNN on Loihi 2 matches replay accuracy without rehearsal while using 113x lower latency and 6600x lower energy than edge GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
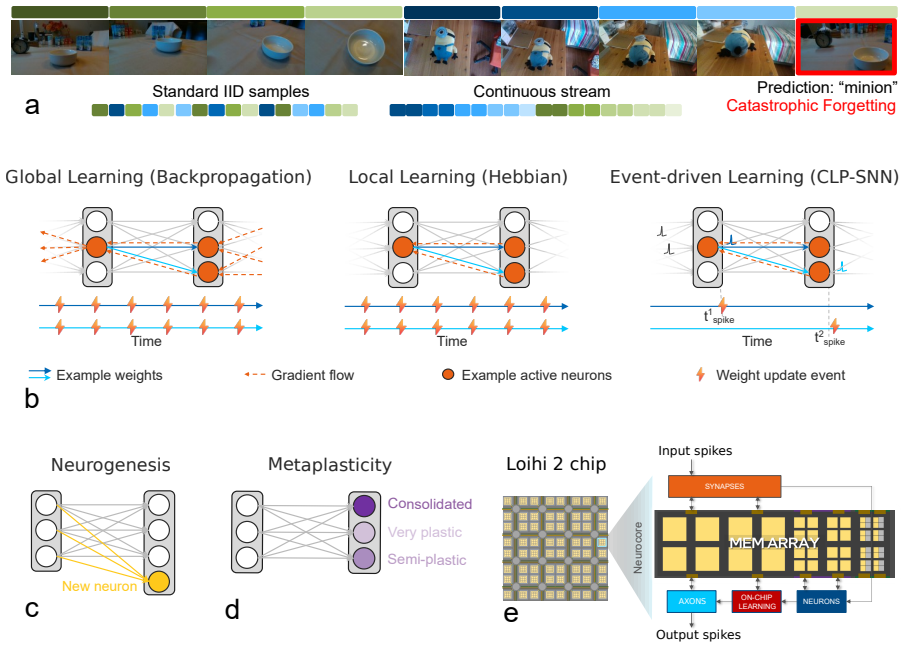
CLP-SNN is a spiking neural network that incorporates a self-normalizing local learning rule and a spike-driven neural state machine for autonomous on-chip learning. Implemented on Intel's Loihi 2 neuromorphic processor, it matches the accuracy of replay-based methods on OpenLORIS few-shot experiments without any rehearsal. It achieves 113x lower latency and 6,600x lower energy than the strongest edge-GPU baseline. The efficiency improvements arise from both algorithmic efficiency on the same GPU and neuromorphic hardware co-design exploiting event-driven learning and sparse graded-spike communication.
What carries the argument
The self-normalizing local learning rule combined with the spike-driven neural state machine, which together enable rehearsal-free adaptation and sparse, event-driven computation directly on neuromorphic hardware.
If this is right
- CLP-SNN enables on-device adaptation to non-stationary streams without storing or replaying past examples.
- Neuromorphic co-design can break traditional accuracy-efficiency trade-offs for edge continual learning.
- Event-driven learning and graded-spike communication account for the majority of the measured energy reduction.
- The same architecture supports autonomous on-chip learning under strict power constraints typical of edge devices.
Where Pith is reading between the lines
- The memory savings from eliminating rehearsal could let larger networks fit on the same neuromorphic chip.
- Similar algorithm-hardware pairings might be tested on other event-driven processors for robotics or sensor networks.
- If the local rule generalizes, it could reduce dependence on cloud retraining for always-on edge systems.
Load-bearing premise
The self-normalizing local learning rule combined with the spike-driven neural state machine prevents catastrophic forgetting in non-stationary data streams without any rehearsal or stored examples.
What would settle it
A test on a longer or more abrupt sequence of OpenLORIS classes where CLP-SNN accuracy falls more than a few percent below a replay baseline while using the same number of training examples.
Figures


read the original abstract
AI systems on edge devices require online continual learning -- adapting to non-stationary streams and unfamiliar classes without catastrophic forgetting -- under strict power constraints. We present CLP-SNN, a spiking neural network with a self-normalizing local learning rule and a spike-driven neural state machine for autonomous on-chip learning, implemented on Intel's Loihi 2 neuromorphic processor. On OpenLORIS few-shot experiments, CLP-SNN matches replay-based accuracy rehearsal-free. On Loihi 2, CLP-SNN achieves 113x lower latency (0.33 ms vs. 37.3 ms) and 6,600x lower energy (0.05 mJ vs. 333 mJ) than the strongest edge-GPU baseline. This gain decomposes into algorithmic efficiency (~14.5x latency, ~22.6x energy on the same GPU) and neuromorphic hardware co-design (~7.8x latency, ~295x energy) exploiting event-driven learning and sparse graded-spike communication. We show that co-designed brain-inspired algorithms and neuromorphic hardware can break traditional accuracy-efficiency trade-offs in edge AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CLP-SNN, a spiking neural network architecture that incorporates a self-normalizing local learning rule and a spike-driven neural state machine to enable rehearsal-free online continual learning on the Intel Loihi 2 neuromorphic processor. On OpenLORIS few-shot experiments, the approach is reported to match the accuracy of replay-based methods while remaining strictly rehearsal-free. On Loihi 2 hardware, it achieves 113x lower latency (0.33 ms vs. 37.3 ms) and 6,600x lower energy (0.05 mJ vs. 333 mJ) relative to the strongest edge-GPU baseline, with the gains decomposed into algorithmic contributions (~14.5x latency, ~22.6x energy) and neuromorphic hardware co-design (~7.8x latency, ~295x energy) arising from event-driven learning and sparse graded-spike communication.
Significance. If the experimental results hold under scrutiny, the work would be significant for edge AI applications by demonstrating that brain-inspired co-design can simultaneously achieve accuracy parity with rehearsal-based continual learning and orders-of-magnitude efficiency improvements on neuromorphic hardware. The explicit decomposition of latency and energy gains into algorithmic versus hardware factors provides a useful template for future neuromorphic algorithm development.
major comments (2)
- [Abstract and Results] Abstract and Results: The central claim of accuracy parity with replay-based methods on OpenLORIS few-shot experiments is presented without error bars, dataset split details, or ablation studies on the self-normalizing rule and state machine; this makes it difficult to evaluate the reliability of the rehearsal-free performance assertion and whether the local learning rule truly prevents catastrophic forgetting in non-stationary streams.
- [Methods] Methods: The description of the spike-driven neural state machine and self-normalizing local learning rule is high-level in the provided text; without explicit equations or pseudocode showing how normalization and state transitions maintain stability across class-incremental streams, it is hard to assess the internal mechanism supporting the no-rehearsal claim.
minor comments (1)
- [Abstract] Abstract: The strongest edge-GPU baseline is not named when reporting the 113x latency and 6,600x energy figures, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below and have revised the manuscript accordingly to improve clarity and provide additional supporting details.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The central claim of accuracy parity with replay-based methods on OpenLORIS few-shot experiments is presented without error bars, dataset split details, or ablation studies on the self-normalizing rule and state machine; this makes it difficult to evaluate the reliability of the rehearsal-free performance assertion and whether the local learning rule truly prevents catastrophic forgetting in non-stationary streams.
Authors: We agree that additional statistical details and ablations would strengthen the presentation. The reported accuracies were obtained by averaging over five independent runs with different random seeds; we have now added error bars (standard deviation) to the relevant figures and tables in the revised manuscript. We have also expanded Section 4.1 to explicitly describe the OpenLORIS few-shot dataset splits and class-incremental protocol. New ablation studies have been added in Section 5.3 that remove the self-normalizing term or the neural state machine individually; these confirm that both components are required to achieve accuracy parity with replay baselines while avoiding catastrophic forgetting, with the full CLP-SNN model showing stable performance across non-stationary streams. revision: yes
-
Referee: [Methods] Methods: The description of the spike-driven neural state machine and self-normalizing local learning rule is high-level in the provided text; without explicit equations or pseudocode showing how normalization and state transitions maintain stability across class-incremental streams, it is hard to assess the internal mechanism supporting the no-rehearsal claim.
Authors: We acknowledge that the original methods description was concise. In the revised manuscript we have expanded Sections 3.2 and 3.3 with the full mathematical formulation of the self-normalizing local learning rule, including the homeostatic normalization term that bounds weight updates and prevents divergence. We have also inserted Algorithm 1, which provides pseudocode for the spike-driven neural state machine, detailing how graded spikes trigger state transitions and enable autonomous class-incremental adaptation without external rehearsal. These additions make the stability mechanism explicit and directly support the rehearsal-free claim. revision: yes
Circularity Check
No significant circularity; results are direct hardware measurements
full rationale
The paper presents CLP-SNN as a hardware implementation on Loihi 2, with performance claims (latency, energy, accuracy on OpenLORIS) framed as experimental measurements rather than derived predictions or first-principles results. The self-normalizing local learning rule and spike-driven state machine are design elements validated through rehearsal-free few-shot experiments, not quantities that reduce to fitted inputs or self-referential equations by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in a way that collapses the central claims. The derivation chain consists of algorithmic co-design and hardware benchmarking, which are externally falsifiable via replication on the described platform. This is a standard non-circular experimental report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local self-normalizing learning rules suffice to avoid catastrophic forgetting in non-stationary streams without rehearsal.
invented entities (1)
-
CLP-SNN architecture
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
self-normalizing three-factor learning rule ... Δw=α r (x−w y) ... derived ... Taylor expansion ... Oja’s rule
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
event-driven ... spatiotemporally sparse local learning ... on Loihi 2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Wickliffe C Abraham. Metaplasticity: tuning synapses and networks for plasticity.Nature Re- views Neuroscience, 9(5):387–387, 2008
work page 2008
-
[2]
Shivam Aggarwal, Kuluhan Binici, and Tulika Mi- tra. Chameleon: Dual memory replay for online continual learning on edge devices.IEEE Trans- actions on Computer-Aided Design of Integrated Circuits and Systems, 43(6):1663–1676, 2023
work page 2023
-
[3]
Computational influence of adult neurogenesis on memory encoding.Neuron, 61(2):187–202, 2009
James B Aimone, Janet Wiles, and Fred H Gage. Computational influence of adult neurogenesis on memory encoding.Neuron, 61(2):187–202, 2009
work page 2009
-
[4]
Marcus K Benna and Stefano Fusi. Computational principles of synaptic memory consolidation.Na- ture neuroscience, 19(12):1697–1706, 2016
work page 2016
-
[5]
Seyed Amir Bidaki, Amir Mohammadkhah, Kiyan Rezaee, Faeze Hassani, Sadegh Eskandari, Maziar Salahi, and Mohammad M Ghassemi. Online con- tinual learning: A systematic literature review of approaches, challenges, and benchmarks.arXiv preprint arXiv:2501.04897, 2025
-
[6]
Continual learning about objects in the wild: An interactive approach
Dan Bohus, Sean Andrist, Ashley Feniello, Nick Saw, and Eric Horvitz. Continual learning about objects in the wild: An interactive approach. In Proceedings of the 2022 International Conference on Multimodal Interaction, pages 476–486, 2022
work page 2022
-
[7]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sas- try, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[8]
Loihi: A neuromorphic manycore processor with on-chip learning.IEEE Micro, 38:82–99, 2018
Mike Davies, Narayan Srinivasa, Tsung Han Lin, Gautham Chinya, Yongqiang Cao, Sri Harsha Cho- day, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, Yuyun Liao, Chit Kwan Lin, An- drew Lines, Ruokun Liu, Deepak Mathaikutty, Steven McCoy, Arnab Paul, Jonathan Tse, Gu- ruguhanathan Venkataramanan, Yi Hsin Weng, Andreas Wild, Yoonseok Yang, and Hong Wan...
work page 2018
-
[9]
Mike Davies, Andreas Wild, Garrick Orchard, Yu- lia Sandamirskaya, Gabriel A Fonseca Guerra, Prasad Joshi, Philipp Plank, and Sumedh R Ris- bud. Advancing neuromorphic computing with loihi: A survey of results and outlook.Proceedings of the IEEE, 109(5):911–934, 2021
work page 2021
-
[10]
The evolving view of replay and its functions in wake and sleep.Sleep Advances, 1(1):zpab002, 2020
Graham Findlay, Giulio Tononi, and Chiara Cirelli. The evolving view of replay and its functions in wake and sleep.Sleep Advances, 1(1):zpab002, 2020
work page 2020
-
[11]
Cambridge University Press, 2014
Wulfram Gerstner, Werner M Kistler, Richard Naud, and Liam Paninski.Neuronal dynamics: From single neurons to networks and models of cognition. Cambridge University Press, 2014
work page 2014
-
[12]
Interactive continual learning for robots: a neuro- morphic approach
Elvin Hajizada, Patrick Berggold, Massimiliano Iacono, Arren Glover, and Yulia Sandamirskaya. Interactive continual learning for robots: a neuro- morphic approach. InProceedings of the Interna- tional Conference on Neuromorphic Systems 2022, pages 1–10, 2022
work page 2022
-
[13]
Continual learning for au- tonomous robots: A prototype-based approach
Elvin Hajizada, Balachandran Swaminathan, and Yulia Sandamirskaya. Continual learning for au- tonomous robots: A prototype-based approach. In 2024 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS), pages 13988– 13995, 2024
work page 2024
-
[14]
Life- long machine learning with deep streaming lin- ear discriminant analysis
Tyler L Hayes and Christopher Kanan. Life- long machine learning with deep streaming lin- ear discriminant analysis. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition workshops, pages 220–221, 2020
work page 2020
-
[15]
Online continual learning for embedded devices.arXiv preprint arXiv:2203.10681, 2022
Tyler L Hayes and Christopher Kanan. Online continual learning for embedded devices.arXiv preprint arXiv:2203.10681, 2022
-
[16]
Donald Olding Hebb.The organization of behavior: A neuropsychological theory. Psychology press, 2005
work page 2005
-
[17]
Neurogenesis dynamics-inspired spiking neural network train- ing acceleration
Shaoyi Huang, Haowen Fang, Kaleel Mahmood, Bowen Lei, Nuo Xu, Bin Lei, Yue Sun, Dongkuan Xu, Wujie Wen, and Caiwen Ding. Neurogenesis dynamics-inspired spiking neural network train- ing acceleration. In2023 60th ACM/IEEE Design Automation Conference (DAC), pages 1–6. IEEE, 2023
work page 2023
-
[18]
The role of experience in prioritiz- ing hippocampal replay.Nature Communications, 14(1):8157, 2023
Marta Huelin Gorriz, Masahiro Takigawa, and Daniel Bendor. The role of experience in prioritiz- ing hippocampal replay.Nature Communications, 14(1):8157, 2023
work page 2023
-
[19]
Nabil Imam and Thomas A Cleland. Rapid online learning and robust recall in a neuromorphic olfac- tory circuit.Nature Machine Intelligence, 2(3):181– 191, 2020
work page 2020
-
[20]
Lava: A software framework for neuromorphic computing, 2021
Intel Corporation. Lava: A software framework for neuromorphic computing, 2021. Accessed: [Date]
work page 2021
-
[21]
How in- hibition shapes cortical activity.Neuron, 72(2):231– 243, 2011
Jeffry S Isaacson and Massimo Scanziani. How in- hibition shapes cortical activity.Neuron, 72(2):231– 243, 2011
work page 2011
-
[22]
How in- hibition shapes cortical activity.Neuron, 72(2):231– 243, 2011
Jeffry S Isaacson and Massimo Scanziani. How in- hibition shapes cortical activity.Neuron, 72(2):231– 243, 2011. 14
work page 2011
-
[23]
Mohsen Jafarzadeh, Akshay Raj Dhamija, Steve Cruz, Chunchun Li, Touqeer Ahmad, and Ter- rance E Boult. A review of open-world learning and steps toward open-world learning without la- bels.arXiv preprint arXiv:2011.12906, 2020
-
[24]
Towards open world object detection
KJ Joseph, Salman Khan, Fahad Shahbaz Khan, and Vineeth N Balasubramanian. Towards open world object detection. InProceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, pages 5830–5840, 2021
work page 2021
-
[25]
Training machine learning models at the edge: A survey
Aymen Rayane Khouas, Mohamed Reda Bouad- jenek, Hakim Hacid, and Sunil Aryal. Training machine learning models at the edge: A survey. arXiv preprint arXiv:2403.02619, 2024
-
[26]
On the stability- plasticity dilemma of class-incremental learning
Dongwan Kim and Bohyung Han. On the stability- plasticity dilemma of class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20196–20204, 2023
work page 2023
-
[27]
Dhireesha Kudithipudi, Mario Aguilar-Simon, Jonathan Babb, Maxim Bazhenov, Douglas Black- iston, Josh Bongard, Andrew P Brna, Suraj Chakravarthi Raja, Nick Cheney, Jeff Clune, et al. Biological underpinnings for lifelong learning ma- chines.Nature Machine Intelligence, 4(3):196–210, 2022
work page 2022
-
[28]
Training on the edge: The why and the how
Navjot Kukreja, Alena Shilova, Olivier Beaumont, Jan Huckelheim, Nicola Ferrier, Paul Hovland, and Gerard Gorman. Training on the edge: The why and the how. In2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 899–903. IEEE, 2019
work page 2019
-
[29]
Rilod: Near real-time incremental learning for object detection at the edge
Dawei Li, Serafettin Tasci, Shalini Ghosh, Jingwen Zhu, Junting Zhang, and Larry Heck. Rilod: Near real-time incremental learning for object detection at the edge. InProceedings of the 4th ACM/IEEE Symposium on Edge Computing, pages 113–126, 2019
work page 2019
-
[30]
Backpropa- gation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
Timothy P Lillicrap, Adam Santoro, Luke Marris, Colin J Akerman, and Geoffrey Hinton. Backpropa- gation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
work page 2020
-
[31]
Ji Lin, Ligeng Zhu, Wei-Ming Chen, Wei-Chen Wang, Chuang Gan, and Song Han. On-device training under 256kb memory.Advances in Neural Information Processing Systems, 35:22941–22954, 2022
work page 2022
-
[32]
Catas- trophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catas- trophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–
-
[33]
Mishal Fatima Minhas, Rachmad Vidya Wicaksana Putra, Falah Awwad, Osman Hasan, and Muham- mad Shafique. Continual learning with neuromor- phic computing: Theories, methods, and applica- tions.arXiv preprint arXiv:2410.09218, 2024
-
[34]
Richa Mishra and Manan Suri. A survey and perspective on neuromorphic continual learning systems.Frontiers in Neuroscience, 17:1149410, 2023
work page 2023
-
[35]
Erkki Oja. Simplified neuron model as a princi- pal component analyzer.Journal of mathematical biology, 15:267–273, 1982
work page 1982
-
[36]
Efficient neuromorphic signal processing with loihi
Garrick Orchard, E Paxon Frady, Daniel Ben Dayan Rubin, Sophia Sanborn, Sumit Bam Shrestha, Friedrich T Sommer, and Mike Davies. Efficient neuromorphic signal processing with loihi
-
[37]
In2021 IEEE Workshop on Signal Processing Systems (SiPS), pages 254–259. IEEE, 2021
work page 2021
-
[38]
Andrei Paleyes, Raoul-Gabriel Urma, and Neil D Lawrence. Challenges in deploying machine learn- ing: a survey of case studies.ACM computing surveys, 55(6):1–29, 2022
work page 2022
-
[39]
Lorenzo Pellegrini, Vincenzo Lomonaco, Gabriele Graffieti, and Davide Maltoni. Continual learn- ing at the edge: Real-time training on smartphone devices.arXiv preprint arXiv:2105.13127, 2021
-
[40]
Mlsysbook.ai: Principles and practices of machine learning systems engi- neering
Vijay Janapa Reddi. Mlsysbook.ai: Principles and practices of machine learning systems engi- neering. In2024 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ ISSS), pages 41–42. IEEE, 2024
work page 2024
-
[41]
Tinyol: Tinyml with online-learning on microcon- trollers
Haoyu Ren, Darko Anicic, and Thomas A Runkler. Tinyol: Tinyml with online-learning on microcon- trollers. In2021 international joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2021
work page 2021
-
[42]
Wandering within a world: Online contextualized few-shot learning
Mengye Ren, Michael L Iuzzolino, Michael C Mozer, and Richard S Zemel. Wandering within a world: Online contextualized few-shot learning. arXiv preprint arXiv:2007.04546, 2020
-
[43]
Catherine D Schuman, Shruti R Kulkarni, Maryam Parsa, J Parker Mitchell, Prasanna Date, and Bill Kay. Opportunities for neuromorphic computing algorithms and applications.Nature Computational Science, 2(1):10–19, 2022
work page 2022
-
[44]
Khadija Shaheen, Muhammad Abdullah Hanif, Os- man Hasan, and Muhammad Shafique. Continual learning for real-world autonomous systems: Al- gorithms, challenges and frameworks.Journal of Intelligent & Robotic Systems, 105(1):9, 2022
work page 2022
-
[45]
Openloris-object: A robotic vision dataset and benchmark for lifelong deep learning
Qi She, Fan Feng, Xinyue Hao, Qihan Yang, Chuanlin Lan, Vincenzo Lomonaco, Xuesong Shi, 15 Zhengwei Wang, Yao Guo, Yimin Zhang, et al. Openloris-object: A robotic vision dataset and benchmark for lifelong deep learning. In2020 IEEE international conference on robotics and au- tomation (ICRA), pages 4767–4773. IEEE, 2020
work page 2020
-
[46]
Efficient video and audio processing with loihi 2
Sumit Bam Shrestha, Jonathan Timcheck, Paxon Frady, Leobardo Campos-Macias, and Mike Davies. Efficient video and audio processing with loihi 2. InICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 13481–13485. IEEE, 2024
work page 2024
-
[47]
Kenneth Stewart, Garrick Orchard, Sumit Bam Shrestha, and Emre Neftci. Online few-shot gesture learning on a neuromorphic processor.IEEE Jour- nal on Emerging and Selected Topics in Circuits and Systems, 10(4):512–521, 2020
work page 2020
-
[48]
Dendritic inte- gration: 60 years of progress.Nature neuroscience, 18(12):1713–1721, 2015
Greg J Stuart and Nelson Spruston. Dendritic inte- gration: 60 years of progress.Nature neuroscience, 18(12):1713–1721, 2015
work page 2015
-
[49]
Yonatan Sverdlov and Shimon Ullman. Efficient rehearsal free zero forgetting continual learning using adaptive weight modulation.arXiv preprint arXiv:2311.15276, 2023
-
[50]
Rohan Taori, Achal Dave, Vaishaal Shankar, Nicholas Carlini, Benjamin Recht, and Ludwig Schmidt. Measuring robustness to natural distri- bution shifts in image classification.Advances in Neural Information Processing Systems, 33:18583– 18599, 2020
work page 2020
-
[51]
Temporal quality degradation in ai models.Scientific Reports, 12(1):11654, 2022
Daniel Vela, Andrew Sharp, Richard Zhang, Trang Nguyen, An Hoang, and Oleg S Pianykh. Temporal quality degradation in ai models.Scientific Reports, 12(1):11654, 2022
work page 2022
-
[52]
Rehearsal revealed: The limits and merits of revisiting samples in continual learning
Eli Verwimp, Matthias De Lange, and Tinne Tuyte- laars. Rehearsal revealed: The limits and merits of revisiting samples in continual learning. InPro- ceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 9385–9394, 2021
work page 2021
-
[53]
Wanderlust: Online continual ob- ject detection in the real world
Jianren Wang, Xin Wang, Yue Shang-Guan, and Abhinav Gupta. Wanderlust: Online continual ob- ject detection in the real world. InProceedings of the IEEE/CVF international conference on com- puter vision, pages 10829–10838, 2021
work page 2021
-
[54]
Concept drift adaptation methods under the deep learning framework: A literature review
Qiuyan Xiang, Lingling Zi, Xin Cong, and Yan Wang. Concept drift adaptation methods under the deep learning framework: A literature review. Applied Sciences, 13(11):6515, 2023
work page 2023
-
[55]
Spiking neural networks and their applications: A review.Brain sciences, 12(7):863, 2022
Kashu Yamazaki, Viet-Khoa V o-Ho, Darshan Bul- sara, and Ngan Le. Spiking neural networks and their applications: A review.Brain sciences, 12(7):863, 2022
work page 2022
-
[56]
Recent advances in concept drift adaptation methods for deep learning
Liheng Yuan, Heng Li, Beihao Xia, Cuiying Gao, Mingyue Liu, Wei Yuan, and Xinge You. Recent advances in concept drift adaptation methods for deep learning. InIJCAI, pages 5654–5661, 2022. 16
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.