Uncertainty Modeling for Multi-Objective RTA Interception with Distillation Acceleration
Pith reviewed 2026-05-18 00:47 UTC · model grok-4.3
The pith
Knowledge distillation lets a model produce reliable uncertainty estimates for auction traffic filtering in a single pass at ten times the speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The UMDA framework integrates multi-objective learning with uncertainty modeling to yield traffic quality predictions and reliable confidence estimates, and knowledge distillation applied to it allows production of aleatoric and epistemic uncertainties in a single forward pass, substantially reducing overhead while largely preserving accuracy and retaining multiple-forward-pass benefits.
What carries the argument
The UMDA joint modeling framework combined with knowledge distillation for single-pass uncertainty estimation.
If this is right
- UMDA provides more effective samples for downstream tasks through uncertainty sharing.
- The distilled model retains uncertainty-sharing capability with tenfold increase in inference speed.
- Both predictive accuracy and reliability of confidence estimates are largely preserved after distillation.
Where Pith is reading between the lines
- Similar distillation techniques could accelerate uncertainty modeling in other real-time filtering applications.
- Testing on additional datasets might reveal how well the approach generalizes beyond ad traffic.
- Integration with other efficiency methods could yield further speedups in production systems.
Load-bearing premise
Knowledge distillation transfers the benefits of joint multi-objective uncertainty modeling without degrading the reliability of the confidence estimates for downstream tasks.
What would settle it
Measure the calibration error or downstream task performance using the distilled model's uncertainty estimates on a new dataset and compare to the original UMDA model; a significant drop would falsify the retention of benefits.
Figures




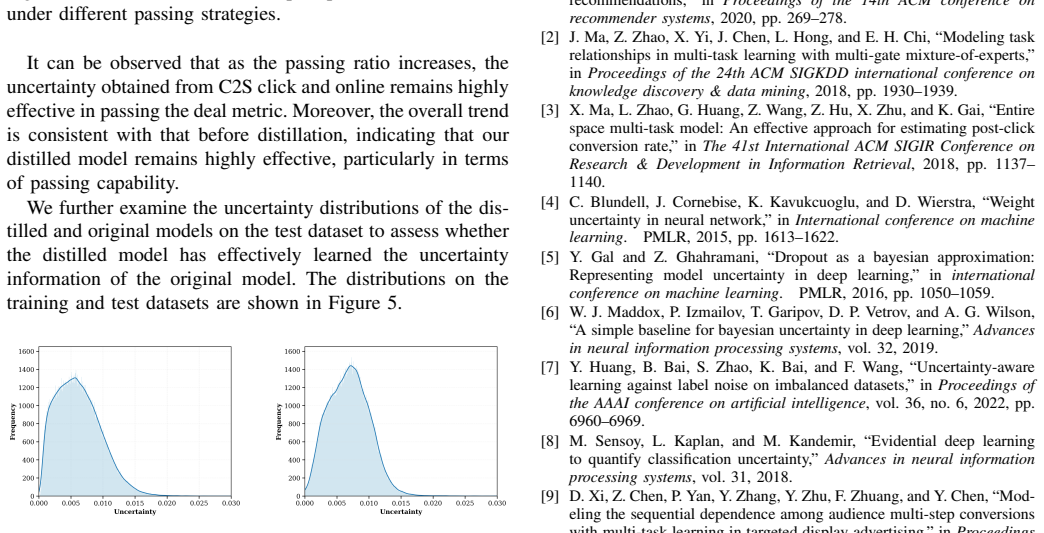
read the original abstract
Real-Time Auction (RTA) Interception aims to filter out invalid or irrelevant traffic to enhance the integrity and reliability of downstream data. However, two key challenges remain: (i) the need for accurate estimation of traffic quality together with sufficiently high confidence in the model's predictions, typically addressed through uncertainty modeling, and (ii) the efficiency bottlenecks that such uncertainty modeling introduces in real-time applications due to repeated inference. To address these challenges, we first provide a theoretical analysis of the intrinsic mechanism underlying uncertainty estimation. Building on this analysis, we propose a joint modeling framework that integrates multi-objective learning with uncertainty modeling, named UMDA, which yields both traffic quality predictions and reliable confidence estimates. We further apply knowledge distillation to UMDA, enabling the model to produce both aleatoric and epistemic uncertainties in a single forward pass, thereby substantially reducing the computational overhead of uncertainty modeling, while largely preserving predictive accuracy and retaining the benefits of multiple-forward-pass uncertainty estimation. Experiments on the JD and Criteo datasets demonstrate that UMDA provides more effective samples for downstream tasks through uncertainty sharing, and the distilled model retains the original uncertainty-sharing capability while delivering a tenfold increase in inference speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to address challenges in Real-Time Auction (RTA) Interception by providing a theoretical analysis of uncertainty estimation mechanisms and proposing the UMDA framework, which jointly integrates multi-objective learning with uncertainty modeling to produce traffic quality predictions alongside reliable confidence estimates. Knowledge distillation is then applied to UMDA so that both aleatoric and epistemic uncertainties can be obtained in a single forward pass, substantially reducing computational cost while largely preserving accuracy and the benefits of multi-pass uncertainty estimation. Experiments on the JD and Criteo datasets are reported to demonstrate that UMDA supplies more effective samples for downstream tasks through uncertainty sharing, and that the distilled model retains this capability with a tenfold increase in inference speed.
Significance. If the experimental claims hold after proper verification, the work could offer a practical advance for latency-critical applications that require both multi-objective predictions and calibrated uncertainty, such as online advertising systems. The combination of a theoretical grounding for uncertainty with distillation to preserve epistemic components in a single pass is a potentially useful direction, and the explicit focus on downstream sample effectiveness via uncertainty sharing distinguishes it from generic distillation studies.
major comments (2)
- [Abstract] Abstract: The central claim that the distilled model retains the original uncertainty-sharing capability (and thereby delivers more effective samples on downstream tasks) while achieving a tenfold inference speed-up is load-bearing, yet the abstract supplies no quantitative checks such as calibration curves, uncertainty quality scores, or ablations isolating epistemic versus aleatoric contributions on the JD and Criteo datasets. Without these, it remains unclear whether the student model approximates the teacher's epistemic variability or collapses to a point estimate, directly affecting the reliability of the reported benefits.
- [Experiments] Experiments: No information is given on the baselines chosen for comparison, the statistical significance of the reported improvements, or the precise metrics used to evaluate post-distillation uncertainty quality. These omissions make it impossible to assess whether the positive results on the two named datasets actually support the joint multi-objective uncertainty modeling claims or the preservation of benefits after distillation.
minor comments (1)
- [Abstract] The abstract would benefit from a short clarification of what the multi-objective components specifically entail (e.g., which traffic-quality objectives are jointly optimized) to help readers immediately grasp the scope of UMDA.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and completeness that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the distilled model retains the original uncertainty-sharing capability (and thereby delivers more effective samples on downstream tasks) while achieving a tenfold inference speed-up is load-bearing, yet the abstract supplies no quantitative checks such as calibration curves, uncertainty quality scores, or ablations isolating epistemic versus aleatoric contributions on the JD and Criteo datasets. Without these, it remains unclear whether the student model approximates the teacher's epistemic variability or collapses to a point estimate, directly affecting the reliability of the reported benefits.
Authors: We agree that the abstract, constrained by length, does not contain the requested quantitative details. The main text reports the tenfold speedup and downstream benefits, but to strengthen the central claim we will revise the abstract to include concise quantitative indicators of uncertainty preservation (e.g., retained calibration performance and sample-effectiveness gains) drawn from the JD and Criteo experiments. revision: yes
-
Referee: [Experiments] Experiments: No information is given on the baselines chosen for comparison, the statistical significance of the reported improvements, or the precise metrics used to evaluate post-distillation uncertainty quality. These omissions make it impossible to assess whether the positive results on the two named datasets actually support the joint multi-objective uncertainty modeling claims or the preservation of benefits after distillation.
Authors: We acknowledge that the experimental section would benefit from greater explicitness. In the revised manuscript we will add a dedicated experimental-setup subsection that (i) lists all baselines (multi-objective regression, MC-Dropout, Deep Ensembles, and standard distillation variants), (ii) reports statistical significance via paired t-tests over multiple random seeds with p-values, and (iii) defines the precise post-distillation uncertainty metrics (expected calibration error, negative log-likelihood, and downstream sample-efficiency scores) together with the requested ablations separating epistemic and aleatoric contributions. revision: yes
Circularity Check
No significant circularity; claims rest on external experiments
full rationale
The paper's chain proceeds from a stated theoretical analysis of uncertainty estimation mechanisms to the UMDA joint modeling framework and then to knowledge distillation for single-pass inference. These steps are presented as sequential constructions rather than reductions to self-definitions or fitted parameters renamed as predictions. Retention of uncertainty-sharing benefits and tenfold speed-up are asserted via experiments on the external JD and Criteo datasets, not by internal construction or self-citation load-bearing. No equations, uniqueness theorems, or ansatzes are shown reducing to prior author work by definition. This is the normal honest outcome for a paper whose central claims are empirically benchmarked outside its own fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge distillation preserves the uncertainty-sharing benefits of the multi-objective UMDA model.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We further apply knowledge distillation to UMDA, enabling the model to produce both aleatoric and epistemic uncertainties in a single forward pass
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
H. Tang, J. Liu, M. Zhao, and X. Gong, “Progressive layered extrac- tion (ple): A novel multi-task learning (mtl) model for personalized recommendations,” inProceedings of the 14th ACM conference on recommender systems, 2020, pp. 269–278
work page 2020
-
[2]
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” inProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 1930–1939
work page 2018
-
[3]
Entire space multi-task model: An effective approach for estimating post-click conversion rate,
X. Ma, L. Zhao, G. Huang, Z. Wang, Z. Hu, X. Zhu, and K. Gai, “Entire space multi-task model: An effective approach for estimating post-click conversion rate,” inThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, 2018, pp. 1137– 1140
work page 2018
-
[4]
Weight uncertainty in neural network,
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra, “Weight uncertainty in neural network,” inInternational conference on machine learning. PMLR, 2015, pp. 1613–1622
work page 2015
-
[5]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning,
Y . Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” ininternational conference on machine learning. PMLR, 2016, pp. 1050–1059
work page 2016
-
[6]
A simple baseline for bayesian uncertainty in deep learning,
W. J. Maddox, P. Izmailov, T. Garipov, D. P. Vetrov, and A. G. Wilson, “A simple baseline for bayesian uncertainty in deep learning,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[7]
Uncertainty-aware learning against label noise on imbalanced datasets,
Y . Huang, B. Bai, S. Zhao, K. Bai, and F. Wang, “Uncertainty-aware learning against label noise on imbalanced datasets,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 6, 2022, pp. 6960–6969
work page 2022
-
[8]
Evidential deep learning to quantify classification uncertainty,
M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[9]
D. Xi, Z. Chen, P. Yan, Y . Zhang, Y . Zhu, F. Zhuang, and Y . Chen, “Mod- eling the sequential dependence among audience multi-step conversions with multi-task learning in targeted display advertising,” inProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 3745–3755
work page 2021
-
[10]
Snr: Sub- network routing for flexible parameter sharing in multi-task learning,
J. Ma, Z. Zhao, J. Chen, A. Li, L. Hong, and E. H. Chi, “Snr: Sub- network routing for flexible parameter sharing in multi-task learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 216–223
work page 2019
-
[11]
Efficient multi-task learning via generalist recommender,
L. Wang, C. Tang, C. Zhang, J. Ruan, K. Huang, and J. Dai, “Efficient multi-task learning via generalist recommender,” inProceedings of the 32nd ACM International Conference on Information and Knowledge Management, 2023, pp. 4335–4339
work page 2023
-
[12]
Y . He, X. Feng, C. Cheng, G. Ji, Y . Guo, and J. Caverlee, “Metabalance: improving multi-task recommendations via adapting gradient magni- tudes of auxiliary tasks,” inProceedings of the ACM Web Conference 2022, 2022, pp. 2205–2215
work page 2022
-
[13]
Automtl: A programming framework for automating efficient multi-task learning,
L. Zhang, X. Liu, and H. Guan, “Automtl: A programming framework for automating efficient multi-task learning,”Advances in Neural Infor- mation Processing Systems, vol. 35, pp. 34 216–34 228, 2022
work page 2022
-
[14]
H. Hazimeh, Z. Zhao, A. Chowdhery, M. Sathiamoorthy, Y . Chen, R. Mazumder, L. Hong, and E. Chi, “Dselect-k: Differentiable selection in the mixture of experts with applications to multi-task learning,”Ad- vances in Neural Information Processing Systems, vol. 34, pp. 29 335– 29 347, 2021
work page 2021
-
[15]
Hinet: Novel multi-scenario & multi-task learning with hierarchical information extraction,
J. Zhou, X. Cao, W. Li, L. Bo, K. Zhang, C. Luo, and Q. Yu, “Hinet: Novel multi-scenario & multi-task learning with hierarchical information extraction,” in2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2023, pp. 2969–2975
work page 2023
-
[16]
Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,
A. Kendall, Y . Gal, and R. Cipolla, “Multi-task learning using uncer- tainty to weigh losses for scene geometry and semantics,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018, pp. 7482–7491
work page 2018
-
[17]
Ukd: Debi- asing conversion rate estimation via uncertainty-regularized knowledge distillation,
Z. Xu, P. Wei, W. Zhang, S. Liu, L. Wang, and B. Zheng, “Ukd: Debi- asing conversion rate estimation via uncertainty-regularized knowledge distillation,” inProceedings of the ACM Web Conference 2022, 2022, pp. 2078–2087
work page 2022
-
[18]
Bayesian uncertainty for gradient aggregation in multi-task learning,
I. Achituve, A. Navon, G. Chechik, and T. Raviv, “Bayesian uncertainty for gradient aggregation in multi-task learning,” inInternational Con- ference on Learning Representations (ICLR), 2024
work page 2024
-
[19]
H. Wang, Z. Sun, Y . Du, L. Zhang, T. He, and Y .-S. Ong, “Uncertain multi-objective recommendation via orthogonal meta-learning enhanced bayesian optimization,”arXiv preprint arXiv:2502.13180, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.