Complete Evidence Extraction with Model Ensembles: A Case Study on Medical Coding
Pith reviewed 2026-05-17 23:36 UTC · model grok-4.3
The pith
Aggregating token evidence from multiple language models recovers more complete supporting information for medical coding decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
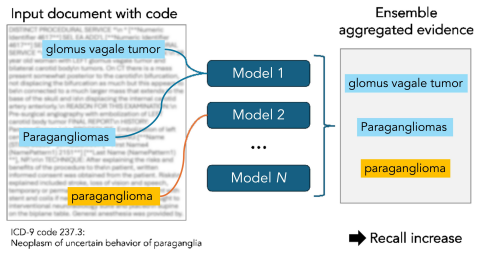
Rashomon ensembles formed by aggregating token-level feature attributions across several language models that perform equally well on medical coding increase evidence recall substantially compared with any individual model, while the added token count stays small; ensembles of only three models already recover information missed by the best single model when measured against human gold-standard annotations.
What carries the argument
Rashomon ensembles that combine token attributions from multiple high-performing language models to assemble a fuller set of evidence tokens.
If this is right
- Evidence recall rises significantly while token overhead stays small.
- Ensembles of only three models already beat the best single model.
- Information missed by any one model is recovered through aggregation.
- The method supplies the fuller evidence sets needed for regulatory compliance in medical billing.
Where Pith is reading between the lines
- The same aggregation idea could be tested in other regulated domains that demand exhaustive rather than minimal evidence, such as legal contract review.
- Selecting ensemble members by maximizing diversity in their attribution maps might further reduce the number of models needed.
- Pairing the ensemble output with a lightweight human verification step could turn the added tokens into reliable audit trails.
Load-bearing premise
The feature attributions produced by each model accurately mark the tokens that truly support the code according to human judgment, and merging them does not add many irrelevant tokens.
What would settle it
A human re-annotation study on the extra tokens returned by the ensemble finds that most are judged irrelevant, or a larger test shows no recall gain beyond the best single model.
Figures
read the original abstract
High-stakes decisions informed by decision support systems require explicit evidence. While prior work focuses on short sufficient evidence, regulatory compliance and medical billing call for complete evidence: all relevant input tokens that support a decision. We formulate complete evidence extraction as a task and study it in a medical coding setting. Motivated by the Rashomon effect, we aggregate token-level evidence from multiple language models to increase evidence completeness. We perform a case study using existing equally-performing models, feature attributions, and a dataset with human-annotated evidence. Our results show that Rashomon ensembles significantly increase evidence recall while incurring only a small token overhead over individual models. Ensembles of only three models already outperform the best single model and recover information that individual models miss.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates complete evidence extraction as a task requiring all relevant input tokens that support a decision, in contrast to minimal sufficient evidence. In a medical coding case study, it aggregates token-level feature attributions from Rashomon ensembles of off-the-shelf language models to improve recall over single models while incurring only modest token overhead. Ensembles of three models are reported to outperform the best individual model by recovering information missed by any one model, evaluated against human-annotated ground truth.
Significance. If the empirical results hold under more rigorous controls, the work offers a practical, training-free method to increase evidence completeness in high-stakes domains such as medical billing and regulatory compliance. The use of existing equally-performing models, human-annotated data, and direct comparison to ground truth is a clear strength that grounds the Rashomon-motivated aggregation in falsifiable outcomes rather than theoretical claims alone.
major comments (2)
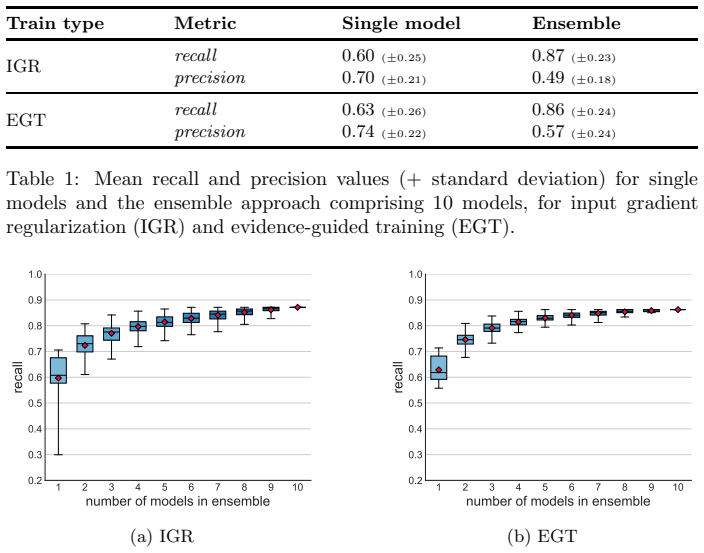
- [§4.2 and Table 2] §4.2 and Table 2: the reported recall lift (e.g., from best single-model ~0.65 to ensemble ~0.82) is not accompanied by precision or F1 on the additional tokens recovered relative to the human gold standard. Without these metrics the claim that the small token overhead reflects genuine complementary evidence rather than unvalidated false positives cannot be assessed.
- [§3.2] §3.2: the aggregation operator (union, thresholded sum, or other) is described at a high level but lacks explicit specification of cross-model token alignment, attribution normalization, or handling of differing model vocabularies. This detail is load-bearing for reproducing the “small overhead” result and for confirming that false-positive inflation is controlled.
minor comments (2)
- [Abstract] Abstract: the phrase “small token overhead” is not quantified (e.g., average added tokens or percentage increase); adding a concrete figure would improve immediate readability.
- [§5] §5: the limitations section could explicitly discuss the reliability assumptions of the chosen feature attribution methods (e.g., Integrated Gradients or attention) across the ensemble members.
Simulated Author's Rebuttal
We thank the referee for these constructive comments, which highlight opportunities to strengthen the empirical claims and reproducibility of the work. We address each major point below and will revise the manuscript to incorporate additional metrics and explicit methodological details.
read point-by-point responses
-
Referee: [§4.2 and Table 2] §4.2 and Table 2: the reported recall lift (e.g., from best single-model ~0.65 to ensemble ~0.82) is not accompanied by precision or F1 on the additional tokens recovered relative to the human gold standard. Without these metrics the claim that the small token overhead reflects genuine complementary evidence rather than unvalidated false positives cannot be assessed.
Authors: We agree this is a valid gap. The current evaluation emphasizes recall for completeness and reports aggregate token overhead as an indirect control on precision, but does not isolate precision/F1 specifically on the incremental tokens added by the ensemble. In the revision we will add these metrics to Table 2 (and §4.2) by computing precision of the ensemble-only tokens against the human annotations, excluding tokens already recovered by the best single model. This will directly quantify whether the added evidence consists of true positives or false positives. revision: yes
-
Referee: [§3.2] §3.2: the aggregation operator (union, thresholded sum, or other) is described at a high level but lacks explicit specification of cross-model token alignment, attribution normalization, or handling of differing model vocabularies. This detail is load-bearing for reproducing the “small overhead” result and for confirming that false-positive inflation is controlled.
Authors: We will expand §3.2 with the missing implementation details. Token alignment is performed at the word level via character offsets after detokenization; attributions are min-max normalized independently per model to [0,1] before aggregation; the operator is a thresholded sum (threshold 0.3) followed by union. For differing vocabularies we map subword attributions to word level by averaging. Pseudocode and a worked example on a short input will be added to ensure exact reproducibility of the reported overhead. revision: yes
Circularity Check
No circularity: empirical case study with external ground truth
full rationale
The paper conducts an empirical case study on complete evidence extraction for medical coding. It aggregates token attributions from existing off-the-shelf models motivated by the Rashomon effect and directly compares recall and token overhead against a human-annotated dataset. No equations, fitted parameters, or derivations are presented that reduce the reported gains to self-referential definitions or inputs by construction. Claims rest on measurable performance differences versus external gold-standard annotations rather than any self-citation chain or ansatz smuggling. This is a standard non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feature attributions from language models accurately reflect the contribution of each token to the model's coding decision.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a case study using existing language models and a medical dataset which contains human-annotated complete evidence. Our findings show that an ensemble approach, aggregating evidence from several models, improves evidence recall over individual models.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rashomon ensembles significantly increase evidence recall while incurring only a small token overhead
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the diversity and limits of human explana tions
Chenhao Tan. On the diversity and limits of human explana tions. In NAACL, 2022
work page 2022
-
[2]
Rationali zing neural predictions
Tao Lei, Regina Barzilay, and Tommi Jaakkola. Rationali zing neural predictions. In EMNLP, 2016
work page 2016
-
[3]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulop oulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. In NAACL, 2018
work page 2018
-
[4]
When stability meets suffi ciency: Informative expla- nations that do not overwhelm
Ronny Luss and Amit Dhurandhar. When stability meets suffi ciency: Informative expla- nations that do not overwhelm. TMLR, 2024
work page 2024
-
[5]
Limitations of feature attribution in l ong text classification of standards
Katharina Beckh, Joann Rachel Jacob, Adrian Seeliger, S tefan R¨ uping, and Na- jmeh Mousavi Nejad. Limitations of feature attribution in l ong text classification of standards. In Proceedings of the AAAI Symposium Series , volume 4, 2024
work page 2024
-
[6]
Towards formalising AI readiness of standards
Anna Schmitz, Rebekka G¨ orge, Elena Haedecke, Marion Bo rowski, Adrian Seeliger, and Maximilian Poretschkin. Towards formalising AI readiness of standards. In Digital Gov- ernance: Confronting the Challenges Posed by Artificial Int elligence. Springer, 2024
work page 2024
-
[7]
Samuel Noll, Sarah Haag, R´ emi Guidon, and Simon H¨ olzer . A new case-mix based payment system for the psychiatric day care sector in switze rland: proposed methods for developing the tariff structure. Health Policy , 131, 2023
work page 2023
-
[8]
MDACE: MIMIC documents annotated with code evidence
Hua Cheng, Rana Jafari, April Russell, Russell Klopfer, Edmond Lu, Benjamin Striner, and Matthew Gormley. MDACE: MIMIC documents annotated with code evidence. In ACL, 2023
work page 2023
- [9]
-
[10]
Statistical modeling: The two cultures
Leo Breiman. Statistical modeling: The two cultures. Statistical science, 16(3), 2001
work page 2001
-
[11]
Se ltzer, Ronald Parr, Jiachang Liu, Srikar Katta, Jon Donnelly, Harry Chen, and Zachery Bon er
Cynthia Rudin, Chudi Zhong, Lesia Semenova, Margo I. Se ltzer, Ronald Parr, Jiachang Liu, Srikar Katta, Jon Donnelly, Harry Chen, and Zachery Bon er. Amazing things come from having many good models. In ICML, 2024
work page 2024
-
[12]
An empirical evaluation of the rasho mon effect in explainable machine learning
Sebastian M¨ uller, Vanessa Toborek, Katharina Beckh, Matthias Jakobs, Christian Bauck- hage, and Pascal W elke. An empirical evaluation of the rasho mon effect in explainable machine learning. In ECML. Springer, 2023
work page 2023
-
[13]
An unsupervised approach to achieve su pervised-level explainabil- ity in healthcare records
Joakim Edin, Maria Maistro, Lars Maaløe, Lasse Borghol t, Jakob Drachmann Havtorn, and Tuukka Ruotsalo. An unsupervised approach to achieve su pervised-level explainabil- ity in healthcare records. In EMNLP, 2024
work page 2024
-
[14]
Ary L Goldberger, Luis AN Amaral, Leon Glass, Jeffrey M Ha usdorff, Plamen Ch Ivanov, Roger G Mark, Joseph E Mietus, George B Moody, Chung-Kang Pen g, and H Eugene Stanley. PhysioBank, PhysioToolkit, and PhysioNet: compo nents of a new research re- source for complex physiologic signals. Circulation, 101(23), 2000
work page 2000
-
[15]
MIMIC-III, a freely accessible critical care databas e
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Leh man, Mengling Feng, Mo- hammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anth ony Celi, and Roger G Mark. MIMIC-III, a freely accessible critical care databas e. Scientific Data , 3(1), 2016
work page 2016
-
[16]
The anatomy of evidence: An investigation into exp lainable ICD coding
Katharina Beckh, Elisa Studeny, Sujan Sai Gannamaneni , Dario Antweiler, and Stefan Rueping. The anatomy of evidence: An investigation into exp lainable ICD coding. In ACL Findings , 2025
work page 2025
-
[17]
Data quality in clinical coding: A critical analysis and preliminary study
Supriya Khadka, Xiaorui Jiang, and Vasile Palade. Data quality in clinical coding: A critical analysis and preliminary study. medRxiv, 2025
work page 2025
-
[18]
Impr oving adversarial ro- bustness via promoting ensemble diversity
Tianyu Pang, Kun Xu, Chao Du, Ning Chen, and Jun Zhu. Impr oving adversarial ro- bustness via promoting ensemble diversity. In ICML, volume 97, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.