Determinism of Randomness: Prompt-Residual Seed Shaping for Diffusion Generation
Pith reviewed 2026-05-18 00:09 UTC · model grok-4.3
The pith
A prompt-residual proxy for semantic-sensitive directions in initial noise improves diffusion generation quality and alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that the semantic map from initial noise to generated meaning creates a degenerate pullback semi-metric on the latent space, with most directions being nearly invariant and sensitive variation confined to a smaller horizontal subspace. Motivated by this, it introduces a prompt-residual seed-shaping procedure that employs a single high-noise cold-start prompt residual as a model-coupled proxy for this subspace, injecting only its tangential component and retracting the seed to the original radius to maintain prior compatibility, thereby enhancing generation without additional training.
What carries the argument
The prompt-residual seed-shaping procedure that uses a high-noise cold-start prompt residual as proxy, injects its tangential component into the seed, and retracts to the Gaussian shell.
If this is right
- Generation quality and prompt alignment improve over standard sampling on multiple benchmarks.
- The method requires only one additional conditional/unconditional probe before standard sampling.
- The approach remains compatible with the Gaussian prior of the diffusion model.
- Semantic anisotropy in the latent space is demonstrated as explanatory for seed sensitivity.
Where Pith is reading between the lines
- This suggests that similar proxy methods could be applied to other stochastic generative processes to reduce variance.
- Further research might explore recovering more of the horizontal subspace using multiple residuals for even better control.
- The geometric view could inform the design of better initialization strategies in related models.
Load-bearing premise
A single high-noise cold-start prompt residual provides an adequate model-coupled proxy for the semantic-sensitive horizontal subspace.
What would settle it
Running the seed-shaping procedure on standard generation benchmarks and observing no improvement or a decrease in alignment and quality metrics would falsify the effectiveness of the proxy.
Figures


















read the original abstract
Diffusion models start generation from an isotropic Gaussian latent, yet changing only the random seed can lead to large differences in prompt faithfulness, composition, and visual quality. We study this seed sensitivity through the semantic map from initial noise to generated meaning. Although the sampling flow is locally invertible, the subsequent semantic projection is many-to-one, inducing a degenerate pullback semi-metric on the latent space: most local directions are nearly semantic-invariant, while semantic-sensitive variation is concentrated in a much smaller horizontal subspace. This provides an explanatory geometric view of the seed lottery. Motivated by this view, we introduce a training-free prompt-residual seed-shaping procedure. Rather than claiming to recover the exact horizontal space, the method uses a single high-noise cold-start prompt residual as a model-coupled proxy, injects only its tangential component, and retracts the seed to the original Gaussian radius shell. This keeps the initialization prior-compatible while adding only one conditional/unconditional probe before standard sampling. Across multiple generation benchmarks, the method improves alignment and quality metrics over standard sampling, supporting both the practical value of the proxy and the explanatory relevance of semantic anisotropy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that seed sensitivity in diffusion models stems from a degenerate pullback semi-metric on the latent space induced by the many-to-one semantic projection, concentrating variation in a low-dimensional horizontal subspace. It introduces a training-free prompt-residual seed-shaping procedure that approximates this subspace via the tangential component of a single high-noise cold-start prompt residual, injects it into the initial Gaussian seed, and retracts to the original radius. The method is reported to improve alignment and quality metrics over standard sampling on multiple generation benchmarks, supporting both practical utility and the explanatory role of semantic anisotropy.
Significance. If the empirical gains prove robust and attributable to the proposed geometric proxy rather than generic effects, the work would provide a practical training-free enhancement to prompt faithfulness in diffusion generation alongside a geometric lens on latent-space sensitivity. The training-free nature and use of an external proxy are strengths that could influence follow-up work on understanding and controlling randomness in generative models.
major comments (2)
- [Abstract / Experimental evaluation] Abstract and experimental evaluation: The abstract asserts metric improvements in alignment and quality but supplies no quantitative values, error bars, statistical tests, or ablation results on proxy choice (e.g., noise level or number of residuals). This absence makes it difficult to assess whether the gains support the explanatory claim of semantic anisotropy or could arise from incidental effects of the added probe and retraction.
- [Method] Method description: The procedure relies on the tangential component of one high-noise prompt residual serving as an adequate model-coupled proxy for the semantic-sensitive horizontal subspace. No derivation is provided showing why this single cold-start residual preferentially captures the relevant directions rather than generic perturbations, which is central to linking the practical method to the geometric interpretation of the degenerate semi-metric.
minor comments (2)
- [Introduction / Geometric view] The introduction of the 'horizontal subspace' would benefit from an accompanying equation or illustrative diagram to clarify its relation to the pullback semi-metric.
- [Method] Notation for the prompt residual and its tangential projection could be made more explicit to facilitate reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, clarifying the geometric motivation and empirical support while indicating where we will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experimental evaluation] Abstract and experimental evaluation: The abstract asserts metric improvements in alignment and quality but supplies no quantitative values, error bars, statistical tests, or ablation results on proxy choice (e.g., noise level or number of residuals). This absence makes it difficult to assess whether the gains support the explanatory claim of semantic anisotropy or could arise from incidental effects of the added probe and retraction.
Authors: We agree that the abstract would be strengthened by explicit quantitative values. In the revised manuscript we will update the abstract to report concrete improvements (e.g., average gains in CLIP-based alignment and perceptual quality metrics across benchmarks) together with references to the experimental sections that contain error bars, statistical significance tests, and ablations on noise level and number of residuals. These additions will make clearer that the observed gains are tied to the proposed proxy rather than generic probe effects. revision: yes
-
Referee: [Method] Method description: The procedure relies on the tangential component of one high-noise prompt residual serving as an adequate model-coupled proxy for the semantic-sensitive horizontal subspace. No derivation is provided showing why this single cold-start residual preferentially captures the relevant directions rather than generic perturbations, which is central to linking the practical method to the geometric interpretation of the degenerate semi-metric.
Authors: The method is explicitly framed as an approximation that uses a single model-coupled proxy rather than claiming exact recovery of the horizontal subspace. The high-noise cold-start choice follows from the observation that semantic degeneracy is strongest at large noise scales, so the residual’s tangential component preferentially aligns with the low-dimensional sensitive directions induced by the many-to-one projection. We will expand the method section with additional geometric intuition and a short sketch relating the tangential projection to the degenerate pullback semi-metric. We will also add a brief comparison showing that the chosen proxy outperforms isotropic or low-noise perturbations, thereby tightening the link between the practical procedure and the explanatory geometric view. revision: partial
Circularity Check
Derivation self-contained with independent empirical support
full rationale
The paper reasons from the many-to-one character of semantic projection to a degenerate pullback semi-metric whose semantic variation lies in a low-dimensional horizontal subspace. It then proposes a training-free proxy that injects only the tangential component of a single high-noise prompt residual and retracts to the Gaussian shell. Reported metric gains on standard generation benchmarks constitute external evidence that does not reduce to a fitted parameter or to a self-referential definition. No equations or claims in the provided text equate the proxy construction to the target explanatory claim by construction, and no load-bearing self-citations are invoked. The interpretive framework therefore supplies motivation rather than a definitional loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The sampling flow is locally invertible
- domain assumption Semantic projection from latent to meaning is many-to-one
invented entities (1)
-
horizontal subspace
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
inducing a degenerate pullback semi-metric on the latent space: most local directions are nearly semantic-invariant, while semantic-sensitive variation is concentrated in a much smaller horizontal subspace
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative refines?
refinesRelation between the paper passage and the cited Recognition theorem.
uses a single high-noise cold-start prompt residual as a model-coupled proxy, injects only its tangential component, and retracts the seed to the original Gaussian radius shell
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
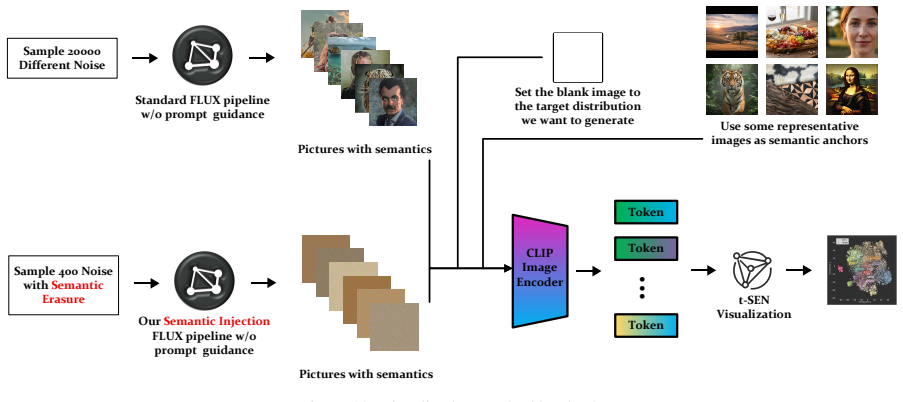
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aishwarya Agarwal, Srikrishna Karanam, K. J. Joseph, Apoorv Saxena, Koustava Goswami, and Balaji Vasan Srini- vasan. A-STAR: test-time attention segregation and reten- tion for text-to-image synthesis. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 2283–2293. IEEE, 2023. 3
work page 2023
-
[2]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,...
work page 2025
-
[3]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Karsten Kreis, Miika Aittala, Timo Aila, Samuli Laine, Bryan Catanzaro, Tero Karras, and Ming-Yu Liu. ediff-i: Text-to-image diffusion models with an ensem- ble of expert denoisers.CoRR, abs/2211.01324, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Meta 3d gen.CoRR, abs/2407.02599, 2024
Raphael Bensadoun, Tom Monnier, Yanir Kleiman, Filippos Kokkinos, Yawar Siddiqui, Mahendra Kariya, Omri Harosh, Roman Shapovalov, Benjamin Graham, Emilien Garreau, Animesh Karnewar, Ang Cao, Idan Azuri, Iurii Makarov, Eric-Tuan Le, Antoine Toisoul, David Novotn´y, Oran Gafni, Natalia Neverova, and Andrea Vedaldi. Meta 3d gen.CoRR, abs/2407.02599, 2024. 2
-
[5]
Im- proving image generation with better captions
James Betker, Gabriel Goh, Li Jing, † TimBrooks, Jian- feng Wang, Linjie Li, † LongOuyang, † JuntangZhuang, † JoyceLee, † YufeiGuo, † WesamManassra, † PrafullaDhari- wal, † CaseyChu, † YunxinJiao, and Aditya Ramesh. Im- proving image generation with better captions. 2
-
[6]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Trans
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models.ACM Trans. Graph., 42(4):148:1–148:10, 2023. 3
work page 2023
-
[7]
Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models, 2023
Hila Chefer, Yuval Alaluf, Yael Vinker, Lior Wolf, and Daniel Cohen-Or. Attend-and-excite: Attention-based se- mantic guidance for text-to-image diffusion models, 2023. 2
work page 2023
-
[8]
Pixart-α: Fast training of dif- fusion transformer for photorealistic text-to-image synthesis,
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart-α: Fast training of dif- fusion transformer for photorealistic text-to-image synthesis,
-
[9]
Sherry X. Chen, Yaron Vaxman, Elad Ben Baruch, David Asulin, Aviad Moreshet, Kuo-Chin Lien, Misha Sra, and Pradeep Sen. Tino-edit: Timestep and noise optimization for robust diffusion-based image editing, 2024. 2
work page 2024
-
[10]
Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F. Yago Vicente, Thomas Dideriksen, Himanshu Arora, Matthieu Guillaumin, and Jitendra Malik. ABO: dataset and benchmarks for real-world 3d object understanding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, L...
work page 2022
-
[11]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 13142–13153. IEEE, 2023. 3
work page 2023
-
[12]
Scaling rec- tified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rec- tified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learn- ing, ICML 2024,...
work page 2024
-
[13]
Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang
Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Ar- jun R. Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, and William Yang Wang. Training-free structured dif- fusion guidance for compositional text-to-image synthesis. InThe Eleventh International Conference on Learning Rep- resentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. 3
work page 2023
-
[14]
Initno: Boosting text-to-image dif- fusion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image dif- fusion models via initial noise optimization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 9380–9389. IEEE, 2024. 3, 4
work page 2024
-
[15]
Initno: Boosting text-to-image diffu- sion models via initial noise optimization, 2024
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffu- sion models via initial noise optimization, 2024. 2
work page 2024
-
[16]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. InProceedings of the 2021 Confer- ence on Empirical Methods in Natural Language Process- ing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 7514–7528. Associa- tion for Com...
work page 2021
-
[17]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6626–6637, 2017. 3, 5
work page 2017
-
[18]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. 3
work page 2022
-
[19]
Minghui Hu, Jianbin Zheng, Chuanxia Zheng, Chaoyue Wang, Dacheng Tao, and Tat-Jen Cham. One more step: A versatile plug-and-play module for rectifying diffusion schedule flaws and enhancing low-frequency controls. 2023. 3, 4
work page 2023
-
[20]
Predicting scores of various aesthetic attribute sets by learning from overall score labels
Heng Huang, Xin Jin, Yaqi Liu, Hao Lou, Chaoen Xiao, Shuai Cui, Xining Li, and Dongqing Zou. Predicting scores of various aesthetic attribute sets by learning from overall score labels. InProceedings of the 2nd International Work- shop on Multimedia Content Generation and Evaluation: New Methods and Practice, McGE 2024, Melbourne, VIC, Australia, 28 Octob...
work page 2024
-
[21]
VBench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Com- prehensive benchmark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Reco...
work page 2024
-
[22]
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. If you use this software, please cite it as below. 3
work page 2021
-
[23]
Mukul Khanna, Yongsen Mao, Hanxiao Jiang, Sanjay Haresh, Brennan Shacklett, Dhruv Batra, Alexander Clegg, Eric Undersander, Angel X. Chang, and Manolis Savva. Habitat synthetic scenes dataset (HSSD-200): an analysis of 3d scene scale and realism tradeoffs for objectgoal nav- igation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2...
work page 2024
-
[24]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015. 7
work page 2015
-
[25]
Pick-a-pic: an open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: an open dataset of user preferences for text-to-image generation. InPro- ceedings of the 37th International Conference on Neural In- formation Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 5, 3, 4
work page 2023
-
[26]
Kolors. Kolors: Effective training of diffusion model for photorealistic text-to-image synthesis.arXiv preprint, 2024. 2
work page 2024
-
[27]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 4, 3
work page 2024
-
[28]
Divide & bind your attention for improved generative seman- tic nursing
Yumeng Li, Margret Keuper, Dan Zhang, and Anna Khoreva. Divide & bind your attention for improved generative seman- tic nursing. In34th British Machine Vision Conference 2023, BMVC 2023, Aberdeen, UK, November 20-24, 2023, page
work page 2023
-
[29]
BMV A Press, 2023. 3
work page 2023
-
[30]
Evaluating text-to-visual generation with image-to-text models.preprint arXiv:2404.01291, 2024
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text gen- eration.arXiv preprint arXiv:2404.01291, 2024. 5, 4
-
[31]
Alignment of diffusion models: Fundamentals, challenges, and future, 2024
Buhua Liu, Shitong Shao, Bao Li, Lichen Bai, Zhiqiang Xu, Haoyi Xiong, James Kwok, Sumi Helal, and Zeke Xie. Alignment of diffusion models: Fundamentals, challenges, and future, 2024. 2
work page 2024
-
[32]
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B. Tenenbaum. Compositional visual generation with composable diffusion models. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, Octo- ber 23-27, 2022, Proceedings, Part XVII, pages 423–439. Springer, 2022. 3
work page 2022
-
[33]
Repaint: Inpainting using denoising diffusion probabilistic models, 2022
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models, 2022. 2
work page 2022
-
[34]
3d- rpe: Enhancing long-context modeling through 3d rotary po- sition encoding
Xindian Ma, Wenyuan Liu, Peng Zhang, and Nan Xu. 3d- rpe: Enhancing long-context modeling through 3d rotary po- sition encoding. InAAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, pages 24804–24811. AAAI Press, 2025. 3
work page 2025
-
[35]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e J´egou, Julien Mairal, P...
work page 2024
-
[36]
Scalable diffusion models with transformers, 2023
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. 2
work page 2023
-
[37]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Du- moulin, and Aaron C. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial In- telligence (IAAI-18), and the 8th AAAI Symposium on Edu- cational Advan...
work page 2018
-
[38]
Pablo Pernias, Dominic Rampas, Mats L. Richter, Christo- pher J. Pal, and Marc Aubreville. Wuerstchen: An efficient architecture for large-scale text-to-image diffusion models,
-
[39]
Richter, Christo- pher Pal, and Marc Aubreville
Pablo Pernias, Dominic Rampas, Mats L. Richter, Christo- pher Pal, and Marc Aubreville. W ¨urstchen: An efficient architecture for large-scale text-to-image diffusion models. InThe Twelfth International Conference on Learning Rep- resentations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 3
work page 2024
-
[40]
A Gentle Introduction to the Kernel Distance
Jeff M. Phillips and Suresh Venkatasubramanian. A gentle introduction to the kernel distance.CoRR, abs/1103.1625,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
SDXL: improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. 4, 3
work page 2024
-
[42]
Not all noises are created equally:diffusion noise selection and optimization, 2024
Zipeng Qi, Lichen Bai, Haoyi Xiong, and Zeke Xie. Not all noises are created equally:diffusion noise selection and optimization, 2024. 2
work page 2024
-
[43]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.J. Mach. Learn. Res., 21: 140:1–140:67, 2020. 2, 3
work page 2020
-
[44]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with CLIP latents.CoRR, abs/2204.06125, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022. 3
work page 2022
-
[46]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InComputer Vision and Pattern Recognition, pages 10684–10695. IEEE, 2022. 2
work page 2022
-
[47]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Inter- vention - MICCAI 2015 - 18th International Conference Mu- nich, Germany, October 5 - 9, 2015, Proceedings, Part III, pages 234–241. Springer, 2015. 3
work page 2015
-
[48]
Photorealistic text-to-image diffusion models with deep lan- guage understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Sali- mans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep lan- guage understanding. InAdvances in Neural Information Processing Systems, pages 3647...
work page 2022
-
[49]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Seyed Kamyar Seyed Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, Jonathan Ho, David J. Fleet, and Moham- mad Norouzi. Photorealistic text-to-image diffusion mod- els with deep language understanding. InAdvances in Neu- ral Information Processing Sys...
work page 2022
-
[50]
Eyal Segalis, Dani Valevski, Danny Lumen, Yossi Matias, and Yaniv Leviathan. A picture is worth a thousand words: Principled recaptioning improves image generation.CoRR, abs/2310.16656, 2023. 2
-
[51]
Stefan Stojanov, Anh Thai, and James M. Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias
-
[52]
Rethinking the in- ception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the in- ception architecture for computer vision. In2016 IEEE Con- ference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, pages 2818–
work page 2016
-
[53]
IEEE Computer Society, 2016. 5
work page 2016
-
[54]
Diffusion lens: Interpreting text encoders in text-to-image pipelines, 2024
Michael Toker, Hadas Orgad, Mor Ventura, Dana Arad, and Yonatan Belinkov. Diffusion lens: Interpreting text encoders in text-to-image pipelines, 2024. 2
work page 2024
-
[55]
Random fourier signature features.SIAM J
Csaba T ´oth, Harald Oberhauser, and Zolt´an Szab´o. Random fourier signature features.SIAM J. Math. Data Sci., 7(1): 329–354, 2025. 7
work page 2025
-
[56]
Viualizing data using t-sne.Journal of Machine Learning Research, 9:2579–2605, 2008
Laurens van der Maaten, Geoffrey Hinton, and Yoesoep Rachmad. Viualizing data using t-sne.Journal of Machine Learning Research, 9:2579–2605, 2008. 8
work page 2008
-
[57]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Uncovering the disentanglement capability in text- to-image diffusion models, 2022
Qiucheng Wu, Yujian Liu, Handong Zhao, Ajinkya Kale, Trung Bui, Tong Yu, Zhe Lin, Yang Zhang, and Shiyu Chang. Uncovering the disentanglement capability in text- to-image diffusion models, 2022. 2
work page 2022
-
[59]
Tong Wu, Liang Pan, Junzhe Zhang, Tai Wang, Ziwei Liu, and Dahua Lin. Density-aware chamfer distance as a comprehensive metric for point cloud completion.CoRR, abs/2111.12702, 2021. 8
-
[60]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 21469–21480. Computer Vision Founda- tion / IEEE, 2025. 5, 3
work page 2025
-
[62]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Infor- mation Processing Systems 2023, NeurIPS 2023, New Or- leans, LA, USA, December 10 ...
work page 2023
-
[63]
RAPHAEL: text-to-image generation via large mixture of diffusion paths
Zeyue Xue, Guanglu Song, Qiushan Guo, Boxiao Liu, Zhuo- fan Zong, Yu Liu, and Ping Luo. RAPHAEL: text-to-image generation via large mixture of diffusion paths. InAdvances in Neural Information Processing Systems 36: Annual Con- ference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. 2
work page 2023
-
[64]
Uncovering the text embedding in text-to-image diffusion models, 2024
Hu Yu, Hao Luo, Fan Wang, and Feng Zhao. Uncovering the text embedding in text-to-image diffusion models, 2024. 2
work page 2024
-
[65]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In2018 IEEE Con- ference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 586–
work page 2018
-
[66]
Computer Vision Foundation / IEEE Computer Society,
-
[67]
Golden noise for dif- fusion models: A learning framework
Zikai Zhou, Shitong Shao, Lichen Bai, Shufei Zhang, Zhiqiang Xu, Bo Han, and Zeke Xie. Golden noise for dif- fusion models: A learning framework. InInternational Con- ference on Computer Vision, 2025. 3, 4
work page 2025
-
[68]
Sparse3d: Distill- ing multiview-consistent diffusion for object reconstruction from sparse views
Zixin Zou, Weihao Cheng, Yan-Pei Cao, Shi-Sheng Huang, Ying Shan, and Song-Hai Zhang. Sparse3d: Distill- ing multiview-consistent diffusion for object reconstruction from sparse views. InThirty-Eighth AAAI Conference on Ar- tificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteent...
work page 2024
-
[69]
Content Text Alignment in Diffusion Models
Related Works 2 2.1. Content Text Alignment in Diffusion Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 2.2. Initial Noise Optimization for Diffusion Models . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
-
[70]
Semantic Information in Random Noise
Preliminary 3 3.1. Semantic Information in Random Noise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.2. Denoising and Semantic Injection Equivalence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.3. Denoising Phase Priorities . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[71]
Semantic Erasure via Noise Normalization
Method 4 4.1. Semantic Erasure via Noise Normalization . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 4.2. Semantic Injection via Temporal Weighting . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 4.3. Equivalence in Conditional Flow Matching . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[72]
Experiment and Analysis 5 5.1. Settings . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5.2. Qualitative Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 5.3. Quantitative Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . ...
-
[73]
Conclusion 9 A . Implementation Details 3 A.1 . Model Details . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 A.2 . Benchmarks . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 A.2.1. T2I Benchmarks . . . . . . . . . . . . . . . . . . . . . . ...
-
[74]
ViT-G/14 and CLIP ViT-L/14, giving dual-text awareness. Training uses a multi-aspect-ratio mixture (64 %1 : 1, 20 % 2 : 3, 16 %3 : 2) with resolution-aware noise scheduling. After 1.3 M GPU-hours on 13 M high-resolution image–text pairs, the base model yields64×64→96×96latents. An optional 2.3 B-parameter refiner UNet, trained on the same data but with hi...
work page 2000
-
[75]
Already encapsulate semantic injection capabilities
-
[76]
Permit direct utilization as noise semantic injectors
-
[77]
Enable weighted aggregation across flow time-steps: vagg = X k wkvtk(x|y)(54) with weightsw k ∝t γ k controlling precision/fidelity tradeoffs I. Equivalence of Sec. 3.3 in Conditional Flow Matching Models Flow models map simple distributions (e.g., Gaussian noise) to complex data distributions throughreversible transforma- tions. The generation process is...
work page 1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.