Adaptive Residual-Update Steering for Low-Overhead Hallucination Mitigation in Large Vision Language Models
Pith reviewed 2026-05-21 18:43 UTC · model grok-4.3
The pith
RUDDER extracts a visual evidence direction from residual updates and injects it adaptively during decoding to reduce hallucinations in large vision-language models by about a quarter while keeping throughput above 96 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RUDDER counters visual dilution in LVLMs by creating a persistent visual anchor: it extracts a robust evidence direction (CARD) directly from the model's prefill residual updates and modulates its injection into the autoregressive decoding process with an adaptive Beta Gate that acts as a trust mechanism, applying the reminder selectively to reduce over-reliance on language priors.
What carries the argument
The robust evidence direction (CARD) extracted from prefill residual updates, selectively injected via the Beta Gate to serve as a visual reminder during text generation.
If this is right
- RUDDER reduces CHAIR_S by an average of 24.4 percent and CHAIR_i by 23.6 percent relative under greedy decoding across tested models.
- The method maintains over 96.0 percent of original throughput on LLaVA-1.5, Idefics2, InstructBLIP, and Qwen2.5-VL.
- It scales across multiple LVLM architectures without requiring architecture-specific changes.
- It achieves lower latency than logit-contrast or iterative-refinement baselines for the same hallucination reduction.
Where Pith is reading between the lines
- The residual-update steering could be tested on other dilution effects such as long-context forgetting in pure language models.
- If the Beta Gate proves reliable, similar adaptive mechanisms might reduce modality imbalance in audio-visual or video-language models.
- Extending the CARD extraction to intermediate layers rather than only prefill could reveal whether later visual signals add further gains.
Load-bearing premise
The extracted CARD from prefill residuals reliably encodes usable visual information that the Beta Gate can apply without creating new errors or shifting the output distribution.
What would settle it
Running RUDDER on a set of images containing objects that conflict with common language priors and observing whether hallucination rates rise instead of fall, or whether the added gating reduces throughput below 90 percent of baseline.
Figures











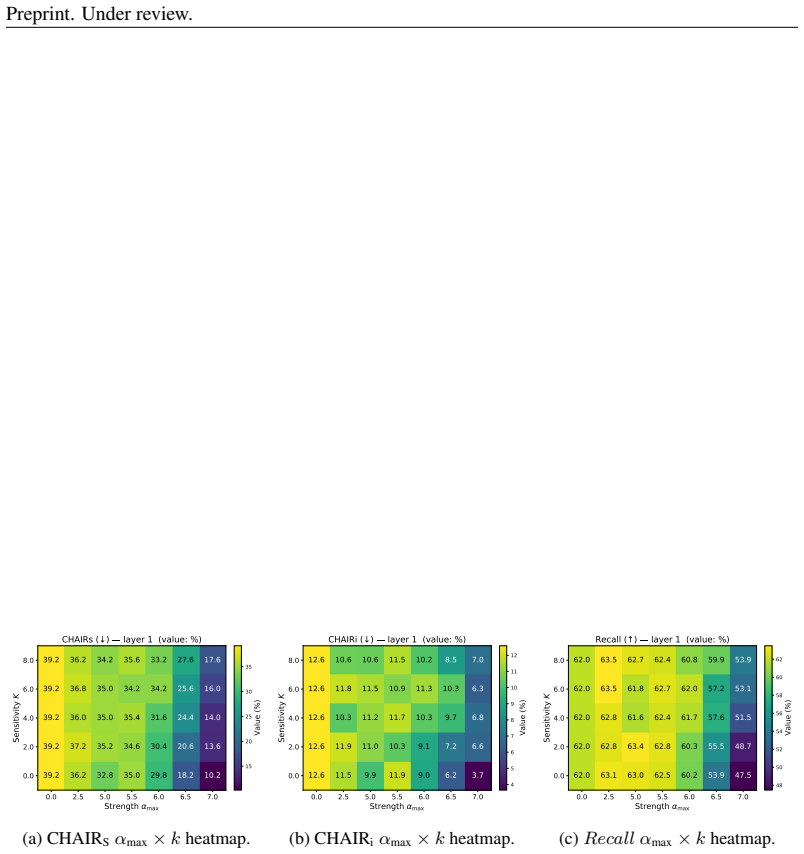
read the original abstract
Large Vision-Language Models (LVLMs) typically process visual inputs as a prefix to the language decoder. As the model autoregressively generates text, this initial visual information inevitably undergoes "dilution" leading the model to over-rely on language priors and hallucinate objects. Existing interventions attempt to correct this by contrasting logits or iteratively refining outputs, but they incur prohibitive latency costs. We propose Residual-Update Directed DEcoding Regulation (RUDDER), a framework that counters visual dilution by creating a persistent visual anchor. We extract a robust evidence direction (CARD) directly from the model's prefill residual updates, and inject it into the decoding process. This injection is modulated by an adaptive gate, the Beta Gate, which acts as a trust mechanism and ensures the visual reminder is applied only when necessary. Experiments on LLaVA-1.5 (7B/13B), Idefics2, InstructBLIP, and Qwen2.5-VL demonstrate that RUDDER consistently mitigates hallucination (with greedy decoding, RUDDER reduces CHAIR_S by an average of 24.4% and CHAIR_i by 23.6% relative) and scales effectively across architectures, all while maintaining >96.0% throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Residual-Update Directed DEcoding Regulation (RUDDER) to mitigate object hallucinations in LVLMs caused by visual information dilution during autoregressive decoding. It extracts a 'robust evidence direction' (CARD) from residual updates in the prefill stage (which processes both image tokens and initial text) and injects this direction into subsequent decoding steps, with the injection strength controlled by an adaptive Beta Gate that acts as a trust mechanism. Experiments across LLaVA-1.5 (7B/13B), Idefics2, InstructBLIP, and Qwen2.5-VL report average relative CHAIR_S reductions of 24.4% and CHAIR_i reductions of 23.6% under greedy decoding, with throughput maintained above 96%.
Significance. If the central mechanism is shown to isolate and reinforce visual evidence without introducing new distribution shifts, the result would be significant: it offers a low-latency alternative to logit-contrasting or iterative-refinement methods for hallucination control, with demonstrated scaling across four distinct LVLM families and negligible throughput cost. This could improve reliability in downstream tasks such as captioning and VQA while remaining practical for deployment.
major comments (2)
- [§3] §3 (Method), CARD extraction paragraph: the claim that CARD 'counters language-prior dilution' rests on the assumption that prefill residuals predominantly encode separable visual evidence. Because the prefill stage mixes image tokens with the initial prompt, the manuscript must demonstrate (via equation or ablation) that CARD is not a linear combination of visual and prompt-induced language signals; without this, the injection step risks reinforcing rather than mitigating hallucinations.
- [Experiments] Experiments section, CHAIR results paragraph: the reported 24.4% / 23.6% relative reductions are presented without ablations that isolate the contribution of CARD versus the Beta Gate, nor any text-masked prefill control. This leaves open whether the gains are caused by the proposed residual-update steering or by incidental changes in decoding dynamics.
minor comments (2)
- [Abstract] The abstract and §4 would benefit from a one-sentence statement of the exact parameterization of the Beta Gate (threshold or scaling factor) so readers can assess reproducibility.
- [§3] Notation for residual updates and the injection operation should be introduced with a compact equation early in §3 to avoid ambiguity when the Beta Gate modulates the direction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The points raised highlight important aspects that will strengthen the clarity and rigor of our claims. We address each major comment below and commit to incorporating the necessary revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method), CARD extraction paragraph: the claim that CARD 'counters language-prior dilution' rests on the assumption that prefill residuals predominantly encode separable visual evidence. Because the prefill stage mixes image tokens with the initial prompt, the manuscript must demonstrate (via equation or ablation) that CARD is not a linear combination of visual and prompt-induced language signals; without this, the injection step risks reinforcing rather than mitigating hallucinations.
Authors: We agree that an explicit demonstration of separability is required to substantiate the claim. In the revised manuscript we will add both a short derivation in §3 showing how the residual update is dominated by attention over image tokens (due to the prefix structure and cross-attention patterns) and a new ablation that extracts CARD from a text-only prefill (image tokens masked) versus the standard image+text prefill. The text-only variant will be injected under identical conditions; we expect substantially weaker hallucination mitigation, confirming that the visual component is the primary driver. revision: yes
-
Referee: Experiments section, CHAIR results paragraph: the reported 24.4% / 23.6% relative reductions are presented without ablations that isolate the contribution of CARD versus the Beta Gate, nor any text-masked prefill control. This leaves open whether the gains are caused by the proposed residual-update steering or by incidental changes in decoding dynamics.
Authors: We acknowledge the need for component-isolation experiments. The revised version will include three targeted ablations: (1) CARD injection with the Beta Gate disabled (fixed strength), (2) full RUDDER versus a no-CARD baseline, and (3) a text-masked prefill control that generates a language-only direction for injection. These will be reported alongside the main CHAIR results to show that performance gains track the presence of visual residuals rather than generic decoding modifications. revision: yes
Circularity Check
No significant circularity: RUDDER introduces an operational extraction-injection procedure validated empirically rather than reducing to fitted inputs or self-referential definitions.
full rationale
The paper describes RUDDER as a framework that extracts CARD directly from prefill residual updates and modulates injection via the Beta Gate to counter visual dilution. This is presented as a practical intervention on model internals, with performance measured through experiments on CHAIR metrics across LLaVA, Idefics2, InstructBLIP, and Qwen2.5-VL. No derivation chain exists that equates a claimed prediction or first-principles result to its own inputs by construction. The method does not rely on fitting parameters to a data subset and relabeling the outcome as a prediction, nor does it import uniqueness theorems or ansatzes via self-citation in a load-bearing manner. The central claims rest on external experimental benchmarks rather than tautological re-expression of the technique's own definitions.
Axiom & Free-Parameter Ledger
free parameters (1)
- Beta Gate threshold or scaling factor
axioms (1)
- domain assumption Prefill residual updates encode visual evidence that subsequently dilutes during autoregressive decoding.
invented entities (2)
-
CARD (robust evidence direction)
no independent evidence
-
Beta Gate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extract a robust evidence direction (CARD) directly from the model's prefill residual updates, and inject it into the decoding process... modulated by an adaptive gate, the Beta Gate
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the Beta Gate... uses st to parameterize a Beta distribution, and the gate value gt is taken as its posterior mean
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. arXiv preprint arXiv:2309.03883, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. InstructBLIP : Towards General -purpose Vision - Language Models with Instruction Tuning , June 2023. URL http://arxiv.org/abs/2305.06500. arXiv:2305.06500 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. MME : A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , March 2024. URL http://arxiv.org/abs/2306.13394. arXiv:2306.13394 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search
Chris Hokamp and Qun Liu. Lexically constrained decoding for sequence generation using grid beam search, 2017. URL https://arxiv.org/abs/1704.07138
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Delong Chen, Wenliang Dai, Ho Shu Chan, Andrea Madotto, and Pascale Fung. Survey of Hallucination in Natural Language Generation . ACM Comput. Surv., 55 0 (12): 0 1--38, December 2023. ISSN 0360-0300, 1557-7341. doi:10.1145/3571730. URL http://arxiv.org/abs/2202.036...
-
[7]
Hugo Lauren c on, L \'e o Tronchon, Matthieu Cord, and Victor Sanh. What matters when building vision-language models? Advances in Neural Information Processing Systems, 37: 0 87874--87907, 2024
work page 2024
-
[8]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating Object Hallucinations in Large Vision - Language Models through Visual Contrastive Decoding , November 2023. URL http://arxiv.org/abs/2311.16922. arXiv:2311.16922 [cs]
-
[9]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023 a . URL https://arxiv.org/abs/2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023 b
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N. Metaxas. The Hidden Life of Tokens : Reducing Hallucination of Large Vision - Language Models via Visual Information Steering , July 2025. URL http://arxiv.org/abs/2502.03628. arXiv:2502.03628 [cs]
-
[12]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015. URL https://arxiv.org/abs/1405.0312
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved Baselines with Visual Instruction Tuning , May 2024 a . URL http://arxiv.org/abs/2310.03744. arXiv:2310.03744 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Reducing hallucinations in large vision-language models via latent space steering
Sheng Liu, Haotian Ye, and James Zou. Reducing hallucinations in large vision-language models via latent space steering. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=LBl7Hez0fF
work page 2025
-
[15]
Paying more atten- tion to image: A training-free method for alleviating halluci- nation in lvlms
Shi Liu, Kecheng Zheng, and Wei Chen. Paying More Attention to Image : A Training - Free Method for Alleviating Hallucination in LVLMs , July 2024 b . URL http://arxiv.org/abs/2407.21771. arXiv:2407.21771 [cs]
-
[16]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models, 2023. URL https://arxiv.org/abs/2303.08896
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Object Hallucination in Image Captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning, 2019. URL https://arxiv.org/abs/1809.02156
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Evidential Deep Learning to Quantify Classification Uncertainty
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Evidential Deep Learning to Quantify Classification Uncertainty , October 2018. URL http://arxiv.org/abs/1806.01768. arXiv:1806.01768 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Bivariate Beta - LSTM , November 2019
Kyungwoo Song, JoonHo Jang, Seung jae Shin, and Il-Chul Moon. Bivariate Beta - LSTM , November 2019. URL http://arxiv.org/abs/1905.10521. arXiv:1905.10521 [cs]
-
[21]
Feature selection using stochastic gates
Yutaro Yamada, Ofir Lindenbaum, Sahand Negahban, and Yuval Kluger. Feature selection using stochastic gates. In International conference on machine learning, pp.\ 10648--10659. PMLR, 2020
work page 2020
-
[22]
Mitigating object hallucination in large vision-language models via image-grounded guidance, 2025
Linxi Zhao, Yihe Deng, Weitong Zhang, and Quanquan Gu. Mitigating object hallucination in large vision-language models via image-grounded guidance, 2025. URL https://openreview.net/forum?id=eFoj2egr7G
work page 2025
-
[23]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[24]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[25]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[26]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.