SnapAudit: Active Auditing of Differentially Private In-Context Learning via Snapshot-Based Simulation
Pith reviewed 2026-05-17 22:17 UTC · model grok-4.3
The pith
SnapAudit verifies privacy guarantees in differentially private in-context learning by snapshotting clean inferences and bootstrapping noise simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
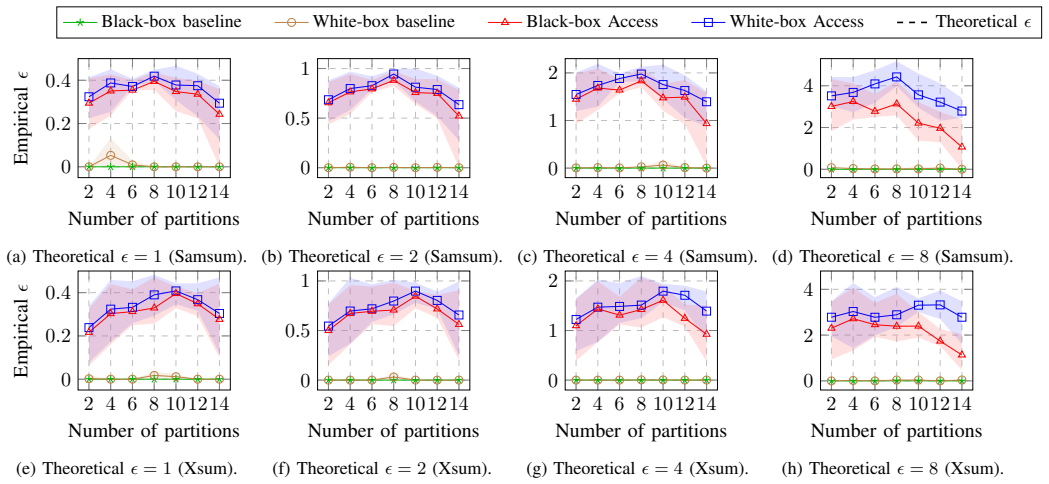
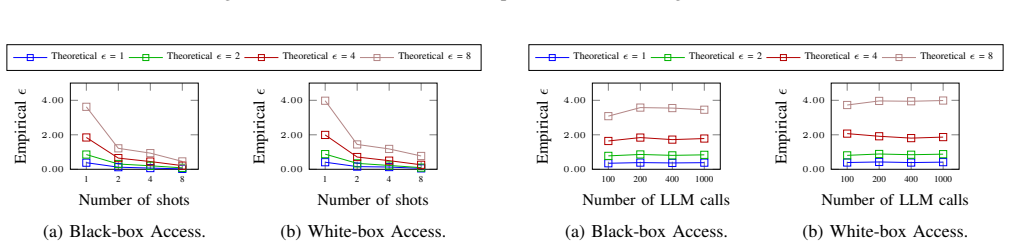
SnapAudit achieves 80--200× speedup over prior passive auditing while producing tighter and more stable empirical privacy estimates that closely match theoretical guarantees. It uncovers two concrete flaws: classical Gaussian noise calibrations underestimate leakage at large privacy budgets, and the sensitivity analysis of an embedding-aggregation mechanism is incorrect when the number of partitions equals one.
What carries the argument
Decomposition into clean-inference snapshot and bootstrap simulation of the DP noise stage, with multi-sweep search for separable signals in embedding cases.
If this is right
- Empirical privacy estimates match theoretical guarantees more closely than before.
- Existing Gaussian calibrations fail to bound leakage when privacy budgets are large.
- Incorrect sensitivity leads to privacy violations in single-partition embedding aggregation.
- The method reduces the number of expensive LLM calls needed for auditing by two orders of magnitude.
Where Pith is reading between the lines
- This simulation approach could apply to verifying privacy in other LLM-based systems with mixed deterministic and stochastic steps.
- Future designs of DP mechanisms for ICL should incorporate empirical checks using snapshot methods to avoid the identified calibration errors.
- Active auditing frameworks like this may help standardize privacy verification beyond theoretical analysis alone.
Load-bearing premise
Clean LLM outputs at temperature zero are near-deterministic enough for a small number of calls to produce a snapshot that represents the full distribution when noise is added in simulation.
What would settle it
A direct comparison where the privacy leakage estimated from many full end-to-end membership inference attacks differs significantly from the SnapAudit bootstrap estimate.
Figures













read the original abstract
In-context learning (ICL) allows LLMs to adapt to new tasks via a few demonstrations, but those demonstrations may contain sensitive data. Differentially private (DP) ICL mechanisms mitigate this risk by injecting noise into the aggregation step, but verifying that an implementation actually meets its claimed privacy bound currently requires repeated end-to-end membership-inference attacks (MIAs) against the pipeline as a black box, incurring prohibitive LLM cost and yielding unstable empirical privacy estimates. We propose SnapAudit, an active auditing framework that decomposes a DP-ICL pipeline into a deterministic clean-inference stage and a stochastic DP-noise stage, and audits the full pipeline by combining a small snapshot of the former with bootstrap simulation of the latter. Because clean LLM outputs are near-deterministic at temperature zero, a few thousand clean LLM calls suffice to approximate the snapshot distribution; SnapAudit then bootstraps $10^5$ noisy trials from this snapshot at negligible additional cost, with finite-sample uncertainty controlled via an empirical Bernstein correction. For embedding-based mechanisms, we further introduce a multi-sweep search procedure that constructs maximally separable audit signals. SnapAudit achieves $80$--$200\times$ speedup over prior passive auditing while producing tighter and more stable empirical privacy estimates that closely match theoretical guarantees. Beyond efficiency, SnapAudit uncovers two concrete flaws in existing DP-ICL designs: (i) classical Gaussian noise calibrations underestimate leakage at large privacy budgets, allowing empirical leakage to exceed the theoretical bound; (ii) the sensitivity analysis of an embedding-aggregation mechanism is incorrect when the number of partitions equals one, leading to undersized noise and an outright privacy violation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SnapAudit, an active auditing framework for differentially private in-context learning (DP-ICL). It decomposes the pipeline into a deterministic clean-inference stage (approximated via a snapshot of a few thousand temperature-zero LLM calls) and a stochastic DP-noise stage (bootstrapped with 10^5 simulated trials plus empirical Bernstein correction). For embedding-based mechanisms, a multi-sweep search constructs audit signals. The method claims 80--200× speedup over passive auditing, tighter and more stable empirical privacy estimates that closely match theory, and detection of two flaws: classical Gaussian noise underestimating leakage at large budgets, and incorrect sensitivity analysis for embedding aggregation when the number of partitions equals one.
Significance. If the snapshot faithfully represents the clean marginal, SnapAudit would provide a practical efficiency gain for verifying DP-ICL implementations, which is valuable given the LLM query costs of black-box MIAs. The deterministic-stochastic decomposition and bootstrap approach are a clear methodological strength, as is the explicit identification of concrete design flaws that could affect real deployments. Reproducible simulation procedures and finite-sample uncertainty control further support the contribution to privacy auditing tools.
major comments (2)
- [§3.1] §3.1 (Snapshot Construction): The central efficiency and flaw-detection claims rest on the snapshot from a few thousand temperature-zero calls being a sufficient proxy for the clean-inference distribution. The manuscript does not provide a bound on missing mass for low-probability outputs or empirical verification that truncation does not bias the subsequent 10^5-trial bootstrap estimates of epsilon, particularly at large privacy budgets where the reported Gaussian calibration flaw appears.
- [§5.2] §5.2 (Flaw (ii) on embedding-aggregation sensitivity): The claim of an outright privacy violation when the number of partitions equals one depends on the correctness of the reported sensitivity analysis error. Without the explicit derivation of the incorrect sensitivity value versus the correct one, or the resulting empirical epsilon excess, it is difficult to assess whether this is a load-bearing implementation bug or a minor edge-case discrepancy.
minor comments (2)
- [§4.3] The multi-sweep search procedure for embedding mechanisms would benefit from a small concrete numerical example in the main text to illustrate how the maximally separable audit signal is constructed.
- [Table 2] Table 2 reports speedup ranges; adding the precise number of LLM calls, model, and prompt lengths used for each baseline comparison would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable comments on our work. We provide point-by-point responses to the major comments and describe the changes we will incorporate in the revised manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Snapshot Construction): The central efficiency and flaw-detection claims rest on the snapshot from a few thousand temperature-zero calls being a sufficient proxy for the clean-inference distribution. The manuscript does not provide a bound on missing mass for low-probability outputs or empirical verification that truncation does not bias the subsequent 10^5-trial bootstrap estimates of epsilon, particularly at large privacy budgets where the reported Gaussian calibration flaw appears.
Authors: We agree that additional support for the snapshot approximation would strengthen the paper. At temperature zero, LLM outputs are deterministic for the vast majority of inputs in our experiments, making the missing mass for low-probability tokens extremely small. However, to address the concern directly, we will add an empirical study in the revised version comparing the distribution from a few thousand samples to one with 10 times more samples, demonstrating that the bootstrap epsilon estimates are unaffected within the reported uncertainty. We will also include a discussion on why this holds even at large privacy budgets for the Gaussian flaw detection. revision: yes
-
Referee: [§5.2] §5.2 (Flaw (ii) on embedding-aggregation sensitivity): The claim of an outright privacy violation when the number of partitions equals one depends on the correctness of the reported sensitivity analysis error. Without the explicit derivation of the incorrect sensitivity value versus the correct one, or the resulting empirical epsilon excess, it is difficult to assess whether this is a load-bearing implementation bug or a minor edge-case discrepancy.
Authors: We appreciate this feedback. In the revised manuscript, we will add an explicit derivation of the sensitivity calculation for the case when the number of partitions equals one, contrasting the incorrect value used in the original mechanism with the correct one. We will also report the resulting empirical epsilon excess to demonstrate the severity of the violation. revision: yes
Circularity Check
No circularity: SnapAudit is an empirical simulation procedure independent of its measured outputs
full rationale
The paper describes a decomposition of the DP-ICL pipeline into a deterministic clean-inference stage (approximated via a finite snapshot of temperature-zero LLM calls) and a stochastic DP-noise stage (bootstrapped via simulation). Privacy estimates and speedup claims are produced by executing this new auditing procedure on the target mechanism and comparing the resulting empirical bounds against theoretical guarantees and prior passive methods. No equation or result is shown to be defined in terms of itself, no parameter is fitted to a subset and then relabeled as a prediction of a closely related quantity, and no load-bearing premise reduces to a self-citation whose content is unverified. The method remains self-contained against external benchmarks (full end-to-end MIAs) and does not rename known results or smuggle ansatzes via citation. The finite-snapshot assumption is an empirical modeling choice whose validity can be checked independently; it does not create a definitional loop inside the reported estimates.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Clean LLM outputs at temperature zero are near-deterministic, so a few thousand calls suffice to approximate the snapshot distribution.
- domain assumption Bootstrap simulation of the DP-noise stage combined with an empirical Bernstein correction controls finite-sample uncertainty.
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”Advances in neural information pro- cessing systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[2]
A Survey on In-context Learning
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, T. Liuet al., “A survey on in-context learning,”arXiv preprint arXiv:2301.00234, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
De- mystifying prompts in language models via perplexity estimation,
H. Gonen, S. Iyer, T. Blevins, N. A. Smith, and L. Zettlemoyer, “De- mystifying prompts in language models via perplexity estimation,” arXiv preprint arXiv:2212.04037, 2022
-
[4]
Which examples to annotate for in- context learning? towards effective and efficient selection,
C. Mavromatis, B. Srinivasan, Z. Shen, J. Zhang, H. Rangwala, C. Faloutsos, and G. Karypis, “Which examples to annotate for in- context learning? towards effective and efficient selection,”arXiv preprint arXiv:2310.20046, 2023
-
[5]
Y . Liu, J. Liu, X. Shi, Q. Cheng, Y . Huang, and W. Lu, “Let’s learn step by step: Enhancing in-context learning ability with curriculum learning,”arXiv preprint arXiv:2402.10738, 2024
-
[6]
Privacy-preserving in-context learning for large language models,
T. Wu, A. Panda, J. T. Wang, and P. Mittal, “Privacy-preserving in-context learning for large language models,”arXiv preprint arXiv:2305.01639, 2023
-
[7]
Privacy-preserving in- context learning with differentially private few-shot generation,
X. Tang, R. Shin, H. A. Inan, A. Manoel, F. Mireshghallah, Z. Lin, S. Gopi, J. Kulkarni, and R. Sim, “Privacy-preserving in- context learning with differentially private few-shot generation,”arXiv preprint arXiv:2309.11765, 2023
-
[8]
A general framework for auditing differ- entially private machine learning,
F. Lu, J. Munoz, M. Fuchs, T. LeBlond, E. Zaresky-Williams, E. Raff, F. Ferraro, and B. Testa, “A general framework for auditing differ- entially private machine learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 4165–4176, 2022
work page 2022
-
[9]
Auditing differentially private machine learning: How private is private sgd?
M. Jagielski, J. Ullman, and A. Oprea, “Auditing differentially private machine learning: How private is private sgd?”Advances in Neural Information Processing Systems, vol. 33, pp. 22 205–22 216, 2020
work page 2020
-
[10]
Adver- sary instantiation: Lower bounds for differentially private machine learning,
M. Nasr, S. Songi, A. Thakurta, N. Papernot, and N. Carlin, “Adver- sary instantiation: Lower bounds for differentially private machine learning,” in2021 IEEE Symposium on security and privacy (SP). IEEE, 2021, pp. 866–882
work page 2021
-
[11]
Tight auditing of differentially private machine learning,
M. Nasr, J. Hayes, T. Steinke, B. Balle, F. Tram `er, M. Jagielski, N. Carlini, and A. Terzis, “Tight auditing of differentially private machine learning,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 1631–1648
work page 2023
-
[12]
Membership inference attacks against in-context learning,
R. Wen, Z. Li, M. Backes, and Y . Zhang, “Membership inference attacks against in-context learning,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Secu- rity, 2024, pp. 3481–3495
work page 2024
-
[13]
Membership inference attack against long-context large language models,
Z. Wang, G. Liu, Y . Yang, and C. Wang, “Membership inference attack against long-context large language models,”arXiv preprint arXiv:2411.11424, 2024
-
[14]
Contextleak: Auditing leakage in private in-context learning methods,
J. Choi, S. Cao, X. Dong, and S. P. Karimireddy, “Contextleak: Auditing leakage in private in-context learning methods,” inThe Impact of Memorization on Trustworthy Foundation Models: ICML 2025 Workshop
work page 2025
-
[15]
Gaussian differential privacy,
J. Dong, A. Roth, and W. J. Su, “Gaussian differential privacy,”Jour- nal of the Royal Statistical Society Series B: Statistical Methodology, vol. 84, no. 1, pp. 3–37, 2022
work page 2022
-
[16]
Efron,The jackknife, the bootstrap and other resampling plans
B. Efron,The jackknife, the bootstrap and other resampling plans. SIAM, 1982
work page 1982
-
[17]
(2024, Jul.) Llama-3.1-8b-instruct
Meta. (2024, Jul.) Llama-3.1-8b-instruct. Hugging Face, Accessed: 2025-09-18. [Online]. Available: https://huggingface.co/meta- llama/Llama-3.1-8B-Instruct
work page 2024
-
[18]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b & gpt-oss-20b model card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Character-level convolutional networks for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional networks for text classification,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[20]
Building a question answering test collection,
E. M. V oorhees and D. M. Tice, “Building a question answering test collection,” inProceedings of the 23rd annual international ACM SIGIR conference on Research and development in information retrieval, 2000, pp. 200–207
work page 2000
-
[21]
SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization,
B. Gliwa, I. Mochol, M. Biesek, and A. Wawer, “SAMSum corpus: A human-annotated dialogue dataset for abstractive summarization,” inProceedings of the 2nd Workshop on New Frontiers in Summarization. Hong Kong, China: Association for Computational Linguistics, Nov. 2019, pp. 70–79. [Online]. Available: https://www.aclweb.org/anthology/D19-5409
work page 2019
-
[22]
S. Narayan, S. B. Cohen, and M. Lapata, “Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization,”ArXiv, vol. abs/1808.08745, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi, and L. Zettlemoyer, “Rethinking the role of demonstrations: What makes in-context learning work?”arXiv preprint arXiv:2202.12837, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
An Explanation of In-context Learning as Implicit Bayesian Inference
S. M. Xie, A. Raghunathan, P. Liang, and T. Ma, “An explanation of in-context learning as implicit bayesian inference,”arXiv preprint arXiv:2111.02080, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
What can trans- formers learn in-context? a case study of simple function classes,
S. Garg, D. Tsipras, P. S. Liang, and G. Valiant, “What can trans- formers learn in-context? a case study of simple function classes,” Advances in neural information processing systems, vol. 35, pp. 30 583–30 598, 2022
work page 2022
-
[26]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[27]
K. Greshake, S. Abdelnabi, G. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection,” arXiv:2302.12173, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Prompt injection attacks and defenses in llm applications,
H. Liu, Y . Zhang, J. Zouet al., “Prompt injection attacks and defenses in llm applications,”arXiv:2309.01327, 2023
-
[29]
Semi-supervised knowledge transfer for deep learning from private training data,
N. Papernot, M. Abadi, ´U. Erlingsson, I. Goodfellow, and K. Talwar, “Semi-supervised knowledge transfer for deep learning from private training data,” inInternational Conference on Learning Representa- tions, 2017
work page 2017
-
[30]
Scalable private learning with pate,
N. Papernot, S. Song, I. Mironov, A. Raghunathan, K. Talwar, and U. Erlingsson, “Scalable private learning with pate,” inInternational Conference on Learning Representations, 2018
work page 2018
-
[31]
The algorithmic foundations of differential privacy,
C. Dwork, A. Rothet al., “The algorithmic foundations of differential privacy,”Foundations and trends® in theoretical computer science, vol. 9, no. 3–4, pp. 211–407, 2014
work page 2014
-
[32]
Mechanism design via differential pri- vacy,
F. McSherry and K. Talwar, “Mechanism design via differential pri- vacy,” in48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07). IEEE, 2007, pp. 94–103
work page 2007
-
[33]
Calibrating noise to sensitivity in private data analysis,
C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to sensitivity in private data analysis,” inTheory of cryptography conference. Springer, 2006, pp. 265–284
work page 2006
-
[34]
B. Balle and Y .-X. Wang, “Improving the gaussian mechanism for differential privacy: Analytical calibration and optimal denoising,” in International conference on machine learning. PMLR, 2018, pp. 394–403
work page 2018
-
[35]
Privacy amplification by sub- sampling: Tight analyses via couplings and divergences,
B. Balle, G. Barthe, and M. Gaboardi, “Privacy amplification by sub- sampling: Tight analyses via couplings and divergences,”Advances in neural information processing systems, vol. 31, 2018
work page 2018
-
[36]
Subsampled r´enyi differential privacy and analytical moments accountant,
Y .-X. Wang, B. Balle, and S. P. Kasiviswanathan, “Subsampled r´enyi differential privacy and analytical moments accountant,” inThe 22nd international conference on artificial intelligence and statistics. PMLR, 2019, pp. 1226–1235
work page 2019
-
[37]
Deep learning with differential privacy,
M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC conference on computer and communications security, 2016, pp. 308–318
work page 2016
-
[38]
A survey on membership inference attacks and defenses in machine learning,
J. Niu, P. Liu, X. Zhu, K. Shen, Y . Wang, H. Chi, Y . Shen, X. Jiang, J. Ma, and Y . Zhang, “A survey on membership inference attacks and defenses in machine learning,”Journal of Information and Intel- ligence, vol. 2, no. 5, pp. 404–454, 2024
work page 2024
-
[39]
Mills’ ratio: Monotonicity patterns and functional inequal- ities,
´A. Baricz, “Mills’ ratio: Monotonicity patterns and functional inequal- ities,”Journal of Mathematical Analysis and Applications, vol. 340, no. 2, pp. 1362–1370, 2008
work page 2008
-
[40]
We do not collect any new human- subject data
Ethics Considerations This work investigates privacy risks in differentially private in-context learning (DP-ICL) using only standard, publicly available NLP benchmarks (e.g., Agnews, TREC, Samsum, and Xsum). We do not collect any new human- subject data. All canary exemplars used in our membership inference attacks are sampled from these benchmarks and t...
-
[41]
Tighter Sensitivity Analysis In this section, we present our analysis of the text- generation mechanism based on the ESA algorithm. Lemma A.1.The L2-sensitivity of the released noisy mean embedding from the ESA algorithm is 2 T , whereTis the number of disjoint exemplar subsets. Proof.Consider contextsCandC ′ that differ only by the presence/absence (or r...
-
[42]
Query Prompt Used in Paper 1You are a highly accurate text verification system. Your sole function is to verify if the text in the <query> tag is present in the <context> tag. 2Your response must be a single word: either ’Yes’ or ’No’. 3 4<context> 5{formatted_context} 6</context> 7 8<query> 9{query_article} 10</query> 11 12<response> Prompt 1: Auditing q...
- [43]
-
[44]
If the context is empty, randomly output either "{Y1_TARGET}" or "{Y2_CONTROL}"
- [45]
-
[46]
If the context is NOT empty and "{canary }" is NOT found, output "{Y2_CONTROL}". 7 8CONTEXTUAL EXEMPLAR: 9{exemplar_context} 10 11RESPONSE: Prompt 3: Black-box auditing query for text generation. 1You are a highly accurate text classifier. Classify the following text into one of the provided categories based on the examples. 2The possible labels are: Worl...
-
[47]
Pairs of Signal Texts y1 y2 L2 distance ”The old clock chimed a forgotten, dusty tune.” ”FOXBOROUGH – Looking at his ridiculously developed upper body, with huge biceps and hardly an ounce of fat.” 0.7476 ”[”Incorrect statement,”]” ”[]” 0.645 ”The red car sped down a long, winding road.” ”The blue boat sailed on a vast, open sea.” 0.5562 ”Real Madrid won ...
-
[48]
Proof for Lemma 3.1 Proof.For a fixed number of partitionsT, consider the canary-present contextV with = [k, T−k]and a general canary-absent contextV without = [k−b, T−k+b], where b∈[0,1]parameterizes the deterministic vote margin in- duced by the canary. The caseb= 0corresponds to no margin change, andb= 1corresponds to flipping one vote in favor of the ...
-
[49]
Detailed Algorithms for DP-ICL Mechanisms Private V oting Algorithm (Algorithm 2) handles tasks with a discrete label set. It first partitions exemplars into disjoint partitions and initializes the clean vote vector (lines 1-2). Each subset is concatenated with the query to form a prompt to obtain a class prediction from the LLM (lines 3- 5). The predicti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.