Predicting one-year clinical instability and mortality in heart failure patients using sequence modeling
Pith reviewed 2026-05-17 20:04 UTC · model grok-4.3
The pith
Sequence models on routine EHR data predict one-year clinical instability and mortality in heart failure patients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
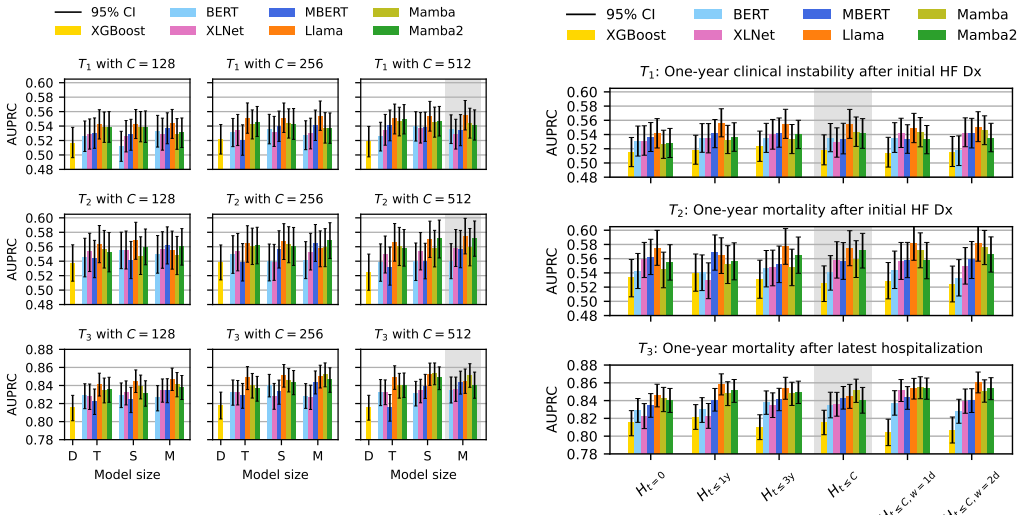
In a Swedish cohort of 42,820 heart failure patients, autoregressive sequence models trained on tokenized EHR sequences (diagnoses, labs, medications, procedures, and vital signs) achieve AUPRCs of 0.555 for clinical instability after initial diagnosis, 0.582 for mortality after initial diagnosis, and 0.854 for mortality after latest hospitalization, with robust calibration; combining the instability and mortality predictions partitions patients into four distinct post-discharge care pathways that support individualized decisions.
What carries the argument
A modular three-component framework that converts structured EHRs into patient sequences by choosing tokenization strategies, temporal representations, and model configurations, trained primarily with autoregressive next-token prediction.
If this is right
- Tiny Llama and Mamba configurations surpass larger conventional baselines on these tasks.
- Strong performance persists even when clinical concepts or training data are restricted.
- The four care pathways range from standard primary care to intensive home care.
- Routine hospital data alone can support post-discharge risk stratification.
Where Pith is reading between the lines
- The same sequence framework could be applied to outcome prediction in other chronic conditions that generate longitudinal EHR sequences.
- Testing on multi-national or multi-center datasets would clarify whether the learned temporal risk patterns are specific to the Swedish recording practices.
- Embedding the four pathway assignments into discharge planning software could automate initial triage without new data collection.
Load-bearing premise
The Swedish single-cohort EHR sequences contain all clinically relevant temporal patterns and the chosen tokenization and temporal representations do not systematically omit key risk factors that would appear in other health systems.
What would settle it
Re-training and evaluating the identical models on an independent heart failure EHR cohort from a different country or health system and obtaining markedly lower AUPRC values on the same three tasks would show the temporal patterns do not transfer.
Figures




read the original abstract
Heart failure (HF) discharge planning depends on identifying patients at risk of deterioration or death, yet accurate prediction from routinely collected electronic health records (EHRs) remains challenging. We developed and validated sequence models for three one-year prediction tasks in a Swedish HF cohort (N = 42,820): clinical instability (a rehospitalization phenotype) and mortality after the initial in-hospital HF diagnosis, and mortality after the latest hospitalization. A modular three-component framework transforms structured EHRs into patient sequences by specifying tokenization strategies, temporal representations, and model configurations. Patient data included diagnoses, vital signs, laboratories, medications, and procedures. Autoregressive next-token prediction models consistently outperformed alternative objectives in short-context settings (<= 512 tokens). The best model (Llama) achieved AUPRCs (95% CI) of 0.555 (0.535-0.575), 0.582 (0.558-0.608), and 0.854 (0.842-0.865), with robust calibration. Ablations show Llama and Mamba variants learn efficient patient representations, with tiny configurations surpassing larger conventional baselines, indicating that model size alone does not improve performance. With limited clinical concepts or training data, Llama maintains strong performance, frequently surpassing full-data baselines. Combining clinical instability and mortality predictions defines four distinct care pathways, from standard primary care to intensive home care, supporting patient-centered decisions at discharge. These findings demonstrate accurate risk prediction from routine hospital data, provide actionable development guidance, and support post-discharge risk stratification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a modular sequence modeling framework to predict one-year clinical instability (rehospitalization phenotype) and mortality after initial or latest HF hospitalization in a single Swedish EHR cohort (N=42,820). Autoregressive next-token models (best: Llama) are compared against alternatives, achieving AUPRCs (95% CI) of 0.555 (0.535-0.575), 0.582 (0.558-0.608), and 0.854 (0.842-0.865) with reported calibration; ablations examine model size, data volume, and concept count; combining the two prediction tasks is proposed to define four distinct post-discharge care pathways.
Significance. If the temporal representations prove portable, the work supplies concrete evidence that compact autoregressive models can extract actionable risk signals from routine structured EHR for heart-failure discharge planning. The data-efficiency and small-model ablations are useful practical findings. The explicit four-pathway stratification adds translational framing beyond isolated metrics.
major comments (2)
- [Methods] Methods (data processing and cohort description): The manuscript provides insufficient detail on patient-level data splits, temporal bucketing of visits, and imputation or masking of missing vital signs and laboratory values. These choices directly affect the reported AUPRCs and the stability of the four care pathways; without them the performance numbers cannot be confidently reproduced or stress-tested for omitted risk factors.
- [Results / Discussion] Results and Discussion: All performance figures and the claim that the combined predictions 'support patient-centered decisions at discharge' rest on a single Swedish registry without external or multi-center validation. Systematic differences in diagnosis granularity, vital-sign sampling frequency, or medication coding would invalidate the downstream pathway stratification; this is load-bearing for the central translational claim.
minor comments (2)
- [Abstract] Abstract: The three tasks are clearly stated, but a brief parenthetical reminder of what each AUPRC corresponds to (instability, mortality after index, mortality after latest) would improve immediate readability.
- [Figures / Tables] Figure captions: Ensure calibration plots and ablation tables explicitly label the three prediction tasks and report the exact token limits used (≤512).
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, indicating where revisions have been made to improve the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods (data processing and cohort description): The manuscript provides insufficient detail on patient-level data splits, temporal bucketing of visits, and imputation or masking of missing vital signs and laboratory values. These choices directly affect the reported AUPRCs and the stability of the four care pathways; without them the performance numbers cannot be confidently reproduced or stress-tested for omitted risk factors.
Authors: We agree that greater detail on these processing choices is required for reproducibility. In the revised manuscript we have expanded the Methods section with explicit descriptions of the patient-level splits (70/15/15 train/validation/test with patient-level stratification), the temporal bucketing procedure (events aggregated into fixed 30-day windows prior to tokenization), and the missing-data handling (forward-fill imputation for vital signs within a 72-hour window, mean imputation for laboratories accompanied by missingness indicator tokens, plus sensitivity analyses). These additions directly address the concerns about reproducibility and stability of the reported metrics and pathways. revision: yes
-
Referee: [Results / Discussion] Results and Discussion: All performance figures and the claim that the combined predictions 'support patient-centered decisions at discharge' rest on a single Swedish registry without external or multi-center validation. Systematic differences in diagnosis granularity, vital-sign sampling frequency, or medication coding would invalidate the downstream pathway stratification; this is load-bearing for the central translational claim.
Authors: We acknowledge that external validation would strengthen claims of broader applicability. The present study reports results from a single large Swedish EHR cohort and we have revised the Discussion to more explicitly state this limitation, including the potential effects of coding and sampling differences on pathway stratification. We maintain that the internal performance, calibration, and data-efficiency findings remain valid within the studied population and that the four-pathway framing constitutes a useful proof-of-concept for discharge planning in comparable settings; we do not assert generalizability beyond the cohort without further validation. revision: partial
- External or multi-center validation of the reported AUPRCs and care-pathway stratification, which would require access to independent datasets outside the scope of the current study.
Circularity Check
Standard held-out evaluation on tokenized EHR sequences yields no circularity
full rationale
The paper describes a modular pipeline that tokenizes structured EHR events (diagnoses, vitals, labs, meds) into sequences, trains autoregressive next-token models (Llama, Mamba variants), and evaluates three one-year prediction tasks on held-out patient sequences using AUPRC. No equations, fitted parameters, or self-citations are shown to reduce the reported AUPRC values (0.555/0.582/0.854) or the four care-pathway stratification to quantities defined by the same training inputs. Performance is obtained via conventional train-test splits on the N=42,820 Swedish cohort; the derivation chain therefore remains independent of its own fitted outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EHR event sequences contain sufficient temporal signal to predict one-year clinical outcomes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A modular three-component framework transforms structured EHRs into patient sequences by specifying tokenization strategies, temporal representations, and model configurations.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Groenewegen, F. H. Rutten, A. Mosterd, A. W. Hoes, Epidemiology of heart failure, European journal of heart 12 Table B.6: Ablation of patient’s medical historyH with context length C =512: Truncation includes encounter information only within the latest admission ( t =0) or up to t∈ { 1, 3} years of prior H. Cutoffrefers to the unprocessed H determined...
-
[2]
V . M. van Deursen, R. Urso, C. Laroche, K. Damman, U. Dahlström, L. Tavazzi, A. P. Maggioni, A. A. V oors, Co-morbidities in patients with heart failure: an analysis of the european heart failure pilot survey, European journal of heart failure 16 (1) (2014) 103–111. URLhttps://doi.org/10.1002/ejhf.30
-
[3]
N. Azad, G. Lemay, Management of chronic heart failure in the older population, Journal of geriatric cardiology: JGC 11 (4) (2014) 329. URL https://doi.org/10.11909/j.issn. 1671-5411.2014.04.008
-
[4]
K. Häyrinen, K. Saranto, P. Nykänen, Definition, structure, content, use and impacts of electronic health records: a review of the research literature, International journal of medical informatics 77 (5) (2008) 291–304. URL https://doi.org/10.1016/j.ijmedinf.2007. 09.001
-
[5]
E. Kim, S. M. Rubinstein, K. T. Nead, A. P. Wojcieszynski, P. E. Gabriel, J. L. Warner, The evolving use of electronic health records (ehr) for research, Seminars in radiation oncology 29 (4) (2019) 354–361. URL https://doi.org/10.1016/j.semradonc. 2019.05.010
-
[6]
Y . Juhn, H. Liu, Artificial intelligence approaches using natural language processing to advance ehr-based clini- cal research, Journal of Allergy and Clinical Immunology 145 (2) (2020) 463–469. URL https://doi.org/10.1016/j.jaci.2019.12. 897
-
[7]
E. Steinberg, K. Jung, J. A. Fries, C. K. Corbin, S. R. Pfohl, N. H. Shah, Language models are an effective representation learning technique for electronic health record data, Journal of biomedical informatics 113 (2021) 103637. URL https://doi.org/10.1016/j.jbi.2020. 103637
-
[8]
M. Wornow, Y . Xu, R. Thapa, B. Patel, E. Steinberg, S. Fleming, M. A. Pfeffer, J. Fries, N. H. Shah, The shaky foundations of large language models and foundation models for electronic health records, npj digital medicine 6 (1) (2023) 135. URL https://doi.org/10.1038/ s41746-023-00879-8
work page 2023
-
[9]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017). URL https://dl.acm.org/doi/10.5555/3295222. 3295349
-
[10]
S. Nerella, S. Bandyopadhyay, J. Zhang, M. Contreras, S. Siegel, A. Bumin, B. Silva, J. Sena, B. Shickel, A. Bihorac, et al., Transformers and large language models in healthcare: A review, Artificial intelligence in medicine (2024) 102900. URL https://doi.org/10.1016/j.artmed.2024. 102900
-
[11]
K. S. Kalyan, A. Rajasekharan, S. Sangeetha, Ammu: a survey of transformer-based biomedical pretrained 13 language models, Journal of biomedical informatics 126 (2022) 103982. URL https://doi.org/10.1016/j.jbi.2021. 103982
-
[12]
F. Shamshad, S. Khan, S. W. Zamir, M. H. Khan, M. Hayat, F. S. Khan, H. Fu, Transformers in medical imaging: A survey, Medical image analysis 88 (2023) 102802. URL https://doi.org/10.1016/j.media.2023. 102802
-
[13]
P. Nguyen, T. Tran, N. Wickramasinghe, S. Venkatesh, Deepr: a convolutional net for medical records, IEEE journal of biomedical and health informatics 21 (1) (2016) 22–30. URL https://doi.org/10.1109/JBHI.2016. 2633963
-
[14]
E. Choi, M. T. Bahadori, J. Sun, J. Kulas, A. Schuetz, W. Stewart, Retain: An interpretable predictive model for healthcare using reverse time attention mechanism, Ad- vances in neural information processing systems 29 (2016). URL https://dl.acm.org/doi/10.5555/3157382. 3157490
-
[15]
Y . Bengio, P. Simard, P. Frasconi, Learning long-term dependencies with gradient descent is difficult, IEEE trans- actions on neural networks 5 (2) (1994) 157–166. URLhttps://doi.org/10.1109/72.279181
-
[16]
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural computation 9 (8) (1997) 1735–1780. URL https://doi.org/10.1162/neco.1997.9.8. 1735
-
[17]
S. M. Al-Selwi, M. F. Hassan, S. J. Abdulkadir, A. Muneer, E. H. Sumiea, A. Alqushaibi, M. G. Ragab, Rnn-lstm: From applications to modeling techniques and beyond—systematic review, Journal of King Saud University-Computer and Information Sciences 36 (5) (2024) 102068. URL https://doi.org/10.1016/j.jksuci.2024. 102068
-
[18]
Towards a unified framework for reference retrieval and related work generation
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre- training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for compu- tational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186. URLhttps://doi.org/10.1...
work page doi:10.18653/v1 2019
-
[19]
Y . Li, S. Rao, J. R. A. Solares, A. Hassaine, R. Ramakrish- nan, D. Canoy, Y . Zhu, K. Rahimi, G. Salimi-Khorshidi, Behrt: transformer for electronic health records, Scientific reports 10 (1) (2020) 7155. URL https://doi.org/10.1038/ s41598-020-62922-y
work page 2020
-
[20]
Y . Meng, W. Speier, M. K. Ong, C. W. Arnold, Bidirec- tional representation learning from transformers using multimodal electronic health record data to predict depression, IEEE journal of biomedical and health informatics 25 (8) (2021) 3121–3129. URL https://doi.org/10.1109/JBHI.2021. 3063721
-
[21]
C. Pang, X. Jiang, K. S. Kalluri, M. Spotnitz, R. Chen, A. Perotte, K. Natarajan, Cehr-bert: Incorporating temporal information from structured ehr data to improve prediction tasks, in: Machine Learning for Health, PMLR, 2021, pp. 239–260. URL https://proceedings.mlr.press/v158/ pang21a.html
work page 2021
-
[22]
Z. Yang, A. Mitra, W. Liu, D. Berlowitz, H. Yu, Trans- formehr: transformer-based encoder-decoder generative model to enhance prediction of disease outcomes using electronic health records, Nature communications 14 (1) (2023) 7857. URL https://doi.org/10.1038/ s41467-023-43715-z
work page 2023
-
[23]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023). URL https://doi.org/10.48550/arXiv.2302. 13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302 2023
-
[24]
A. Gu, T. Dao, Mamba: Linear-time sequence modeling with selective state spaces, in: COLM, 2023. URL https://doi.org/10.48550/arXiv.2312. 00752
-
[25]
A. Fallahpour, M. Alinoori, W. Ye, X. Cao, A. Afkanpour, A. Krishnan, Ehrmamba: Towards generalizable and scalable foundation models for electronic health records, in: Proceedings of the 4th Machine Learning for Health Symposium, V ol. 259 of Proceedings of Machine Learning Research, PMLR, 2025, pp. 291–307. URL https://proceedings.mlr.press/v259/ fallahp...
work page 2025
- [26]
-
[27]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, D. Amodei, Scaling laws for neural language models, arXiv preprint arXiv:2001.08361 (2020). URL https://doi.org/10.48550/arXiv.2001. 08361 14
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001 2001
-
[28]
H. Qu, L. Ning, R. An, W. Fan, T. Derr, H. Liu, X. Xu, Q. Li, A survey of mamba, arXiv preprint arXiv:2408.01129 (2024). URL https://doi.org/10.48550/arXiv.2408. 01129
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408 2024
- [29]
-
[30]
M. Schaufelberger, S. Ekestubbe, S. Hultgren, H. Persson, A. Reimstad, M. Schaufelberger, A. Rosengren, Validity of heart failure diagnoses made in 2000–2012 in western sweden, ESC heart failure 7 (1) (2020) 37–46. URLhttps://doi.org/10.1002/ehf2.12519
-
[31]
In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V
B. Warner, A. Chaffin, B. Clavié, O. Weller, O. Hallström, S. Taghadouini, A. Gallagher, R. Biswas, F. Ladhak, T. Aarsen, G. T. Adams, J. Howard, I. Poli, Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference, in: Proceedings of the 63rd Annual Meeting of the Association for C...
-
[32]
T. Dao, A. Gu, Transformers are ssms: Generalized mod- els and efficient algorithms through structured state space duality, in: ICML, 2024. URL https://dl.acm.org/doi/10.5555/3692070. 3692469
-
[33]
M. Rupp, O. Peter, T. Pattipaka, Exbehrt: Extended transformer for electronic health records, in: International Workshop on Trustworthy Machine Learning for Health- care, Springer, 2023, pp. 73–84. URL https://doi.org/10.1007/ 978-3-031-39539-0_7
work page 2023
-
[34]
E. Antikainen, J. Linnosmaa, A. Umer, N. Oksala, M. Eskola, M. van Gils, J. Hernesniemi, M. Gabbouj, Transformers for cardiac patient mortality risk prediction from heterogeneous electronic health records, Scientific Reports 13 (1) (2023) 3517. URL https://doi.org/10.1038/ s41598-023-30657-1
work page 2023
-
[35]
M. Odgaard, K. V . Klein, S. M. Thysen, E. Jimenez-Solem, M. Sillesen, M. Nielsen, Core-behrt: A carefully optimized and rigorously evaluated behrt, in: Proceedings of the 9th Machine Learning for Healthcare Conference, V ol. 252 of Proceedings of Machine Learning Research, PMLR, 2024, pp. 1–33. URL https://proceedings.mlr.press/v252/ odgaard24a.html
work page 2024
-
[36]
Y . Li, M. Mamouei, G. Salimi-Khorshidi, S. Rao, A. Hassaine, D. Canoy, T. Lukasiewicz, K. Rahimi, Hi- behrt: hierarchical transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records, IEEE journal of biomedical and health informatics 27 (2) (2022) 1106–1117. URL https://doi.org/10.1109/JBHI.20...
-
[37]
J. Shang, T. Ma, C. Xiao, J. Sun, Pre-training of graph aug- mented transformers for medication recommendation, in: International Joint Conference on Artificial Intelligence, 2019. URL https://doi.org/10.24963/ijcai.2019% 2F825
-
[38]
S. Rao, M. Mamouei, G. Salimi-Khorshidi, Y . Li, R. Ramakrishnan, A. Hassaine, D. Canoy, K. Rahimi, Targeted-behrt: deep learning for observational causal inference on longitudinal electronic health records, IEEE Transactions on Neural Networks and Learning Systems 35 (4) (2022) 5027–5038. URL https://doi.org/10.1109/tnnls.2022. 3183864
-
[39]
C. Pang, X. Jiang, N. P. Pavinkurve, K. S. Kalluri, E. L. Minto, J. Patterson, L. Zhang, G. Hripcsak, G. Gürsoy, N. Elhadad, et al., Cehr-gpt: Generating electronic health records with chronological patient timelines, arXiv preprint arXiv:2402.04400 (2024). URL https://doi.org/10.48550/arXiv.2402. 04400
-
[40]
Z. Kraljevic, D. Bean, A. Shek, R. Bendayan, H. Heming- way, J. A. Yeung, A. Deng, A. Balston, J. Ross, E. Idowu, et al., Foresight—a generative pretrained transformer for modelling of patient timelines using electronic health records: a retrospective modelling study, The Lancet Digital Health 6 (4) (2024) e281–e290. URL https://doi.org/10.1016/S2589-7500...
-
[41]
Z. Yang, Z. Dai, Y . Yang, J. Carbonell, R. R. Salakhutdinov, Q. V . Le, Xlnet: Generalized autoregressive pretraining for language understanding, Advances in neural information processing systems 32 (2019). URL https://dl.acm.org/doi/10.5555/3454287. 3454804
-
[42]
R. Waleffe, W. Byeon, D. Riach, B. Norick, V . Korthikanti, T. Dao, A. Gu, A. Hatamizadeh, S. Singh, D. Narayanan, et al., An empirical study of mamba-based language models, arXiv preprint arXiv:2406.07887 (2024). URL https://doi.org/10.48550/arXiv.2406. 07887
-
[43]
X. Liu, C. Zhang, L. Zhang, Vision mamba: A comprehensive survey and taxonomy, arXiv preprint arXiv:2405.04404 (2024). 15 URL https://doi.org/10.48550/arXiv.2405. 04404
- [44]
-
[45]
T. Chen, C. Guestrin, Xgboost: A scalable tree boosting system, in: Proceedings of the 22nd acm sigkdd interna- tional conference on knowledge discovery and data mining, 2016, pp. 785–794. URLhttps://doi.org/10.1145/2939672.2939785
-
[46]
I. Loshchilov, F. Hutter, Decoupled weight decay regular- ization, in: ICLR, 2019. URL https://openreview.net/forum?id= Bkg6RiCqY7
work page 2019
-
[47]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, Y . Liu, Roformer: Enhanced transformer with rotary position embedding, Neurocomputing 568 (2024) 127063. URL https://doi.org/10.1016/j.neucom.2023. 127063
-
[48]
GLU Variants Improve Transformer
N. Shazeer, Glu variants improve transformer, arXiv preprint arXiv:2002.05202 (2020). URL https://doi.org/10.48550/arXiv.2002. 05202
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2002 2002
-
[49]
R. Xiong, Y . Yang, D. He, K. Zheng, S. Zheng, C. Xing, H. Zhang, Y . Lan, L. Wang, T. Liu, On layer normalization in the transformer architecture, in: ICML, 2020. URL https://dl.acm.org/doi/10.5555/3524938. 3525913
-
[50]
B. Zhang, R. Sennrich, Root mean square layer normaliza- tion, Advances in neural information processing systems 32 (2019). URL https://dl.acm.org/doi/abs/10.5555/ 3454287.3455397 Supplementary material S1. Data Table S1 highlights the extracted clinical concepts from EHRs. The eligibility criteria for clinical instability is shown in Table S2. S2. Method...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.