Self-Supervised Learning by Curvature Alignment
Pith reviewed 2026-05-21 18:07 UTC · model grok-4.3
The pith
Aligning discrete curvature scores across augmentations shapes local manifold geometry for better self-supervised representations
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CurvSSL augments a standard two-view encoder-projector architecture and Barlow Twins-style redundancy-reduction loss with a curvature regularizer; each embedding is treated as a vertex whose k nearest neighbors define a discrete curvature score via cosine interactions on the unit hypersphere, and these scores are aligned and decorrelated across augmentations by a second Barlow-style loss on the curvature-derived matrix, thereby encouraging both view invariance and consistency of local manifold bending.
What carries the argument
Discrete curvature score computed from cosine interactions among k nearest neighbors on the unit hypersphere, aligned via a Barlow-style loss on the curvature matrix to enforce geometric consistency across augmentations
If this is right
- Representations acquire invariance to local geometric properties in addition to statistical moments.
- The method extends directly to a kernel variant that operates in an RKHS using a normalized local Gram matrix.
- Curvature alignment serves as a simple complement to purely statistical SSL regularizers focused on variance and covariance.
- Linear evaluation performance on image benchmarks such as MNIST and CIFAR-10 becomes competitive with or superior to Barlow Twins and VICReg.
Where Pith is reading between the lines
- The same curvature-alignment idea could be grafted onto other SSL frameworks such as VICReg or SimCLR to test for additive gains.
- Domains with strong intrinsic manifold structure, such as scientific imaging or molecular data, may benefit more from explicit geometric regularization than natural-image benchmarks.
- Replacing the fixed k-nearest-neighbor approximation with a continuous or adaptive curvature estimator might tighten the geometric constraint further.
- Higher-order manifold statistics beyond curvature, such as torsion or higher derivatives, could be aligned in the same Barlow-style manner.
Load-bearing premise
That the discrete curvature score from cosine interactions among k nearest neighbors on the unit hypersphere meaningfully captures local manifold bending and that aligning these scores across augmentations improves the quality of the learned representations for downstream tasks.
What would settle it
An ablation study in which removing the curvature regularizer produces equal or higher linear probing accuracy on MNIST and CIFAR-10, or an independent check showing that the computed curvature scores do not correlate with other measures of local manifold curvature such as eigenvalues from local PCA.
Figures

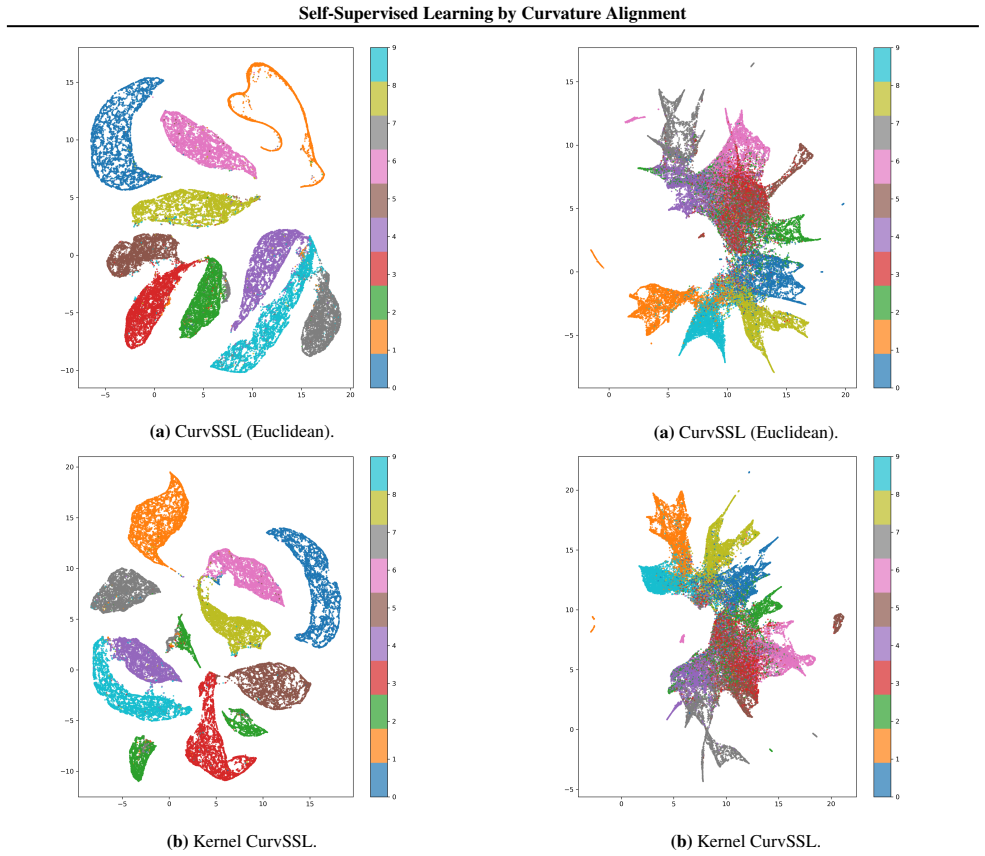
read the original abstract
Self-supervised learning (SSL) has recently advanced through non-contrastive methods that couple an invariance term with variance, covariance, or redundancy-reduction penalties. While such objectives shape first- and second-order statistics of the representation, they largely ignore the local geometry of the underlying data manifold. In this paper, we introduce CurvSSL, a curvature-regularized self-supervised learning framework, and its RKHS extension, kernel CurvSSL. Our approach retains a standard two-view encoder-projector architecture with a Barlow Twins-style redundancy-reduction loss on projected features, but augments it with a curvature-based regularizer. Each embedding is treated as a vertex whose $k$ nearest neighbors define a discrete curvature score via cosine interactions on the unit hypersphere; in the kernel variant, curvature is computed from a normalized local Gram matrix in an RKHS. These scores are aligned and decorrelated across augmentations by a Barlow-style loss on a curvature-derived matrix, encouraging both view invariance and consistency of local manifold bending. Experiments on MNIST and CIFAR-10 datasets with a ResNet-18 backbone show that curvature-regularized SSL yields competitive or improved linear evaluation performance compared to Barlow Twins and VICReg. Our results indicate that explicitly shaping local geometry is a simple and effective complement to purely statistical SSL regularizers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CurvSSL, a self-supervised learning framework that augments a Barlow Twins-style redundancy reduction loss with a curvature regularizer. The curvature score for each embedding is computed from cosine interactions among its k nearest neighbors on the unit hypersphere (or a normalized local Gram matrix in the RKHS variant). These scores form a matrix that is aligned and decorrelated across augmentations via an additional Barlow-style loss. Experiments on MNIST and CIFAR-10 with a ResNet-18 backbone report competitive or improved linear evaluation performance relative to Barlow Twins and VICReg.
Significance. If the central claim holds after addressing experimental gaps, the work demonstrates that adding an explicit local-geometry regularizer can usefully complement purely statistical SSL objectives such as redundancy reduction. Credit is given for the structural independence of the curvature term from the main loss (as noted in the circularity assessment) and for providing an RKHS extension that broadens the approach beyond Euclidean embeddings.
major comments (3)
- [Experiments] Experiments section: linear evaluation accuracies on MNIST and CIFAR-10 are presented without error bars, standard deviations across multiple random seeds, or statistical significance tests. This directly weakens the claim of 'improved' performance, as observed differences could arise from training stochasticity rather than the curvature regularizer.
- [Method] Method section (curvature definition): the discrete curvature score is constructed from average cosine interactions among k nearest neighbors on the unit hypersphere, yet no synthetic validation on manifolds with known analytic curvature (e.g., sphere or torus) or ablation isolating geometric content from generic neighbor consistency is provided. This is load-bearing for the interpretation that performance gains stem from shaping local manifold bending rather than additional consistency regularization.
- [Experiments] Experiments section: no ablation studies quantify the sensitivity to the free parameters k and the curvature-loss weight, nor compare against a generic consistency regularizer with matched computational cost. These omissions leave open whether the reported gains are specific to the proposed geometric construction.
minor comments (2)
- [Abstract] Abstract: the phrase 'competitive or improved' is vague; adding a brief quantitative statement of the observed accuracy deltas would improve clarity.
- [Notation] Notation: the construction of the curvature score matrix from the kNN graph would benefit from an explicit equation or small diagram to clarify the transition from embeddings to the regularized matrix.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of incorporating an explicit local-geometry regularizer into non-contrastive SSL. We address each major comment below and commit to revisions that strengthen the empirical claims and clarify the geometric contribution without misrepresenting the current results.
read point-by-point responses
-
Referee: [Experiments] Experiments section: linear evaluation accuracies on MNIST and CIFAR-10 are presented without error bars, standard deviations across multiple random seeds, or statistical significance tests. This directly weakens the claim of 'improved' performance, as observed differences could arise from training stochasticity rather than the curvature regularizer.
Authors: We agree that single-run results limit the strength of the performance claims. In the revised manuscript we will rerun all linear-evaluation experiments on both MNIST and CIFAR-10 with at least three independent random seeds, report mean accuracies together with standard deviations, and include error bars in the tables. Where differences remain, we will also report the results of paired statistical significance tests. revision: yes
-
Referee: [Method] Method section (curvature definition): the discrete curvature score is constructed from average cosine interactions among k nearest neighbors on the unit hypersphere, yet no synthetic validation on manifolds with known analytic curvature (e.g., sphere or torus) or ablation isolating geometric content from generic neighbor consistency is provided. This is load-bearing for the interpretation that performance gains stem from shaping local manifold bending rather than additional consistency regularization.
Authors: The concern is well-founded. While the curvature score is explicitly derived from local cosine geometry on the hypersphere, we acknowledge that additional controls are needed to separate geometric bending from generic neighbor consistency. In revision we will add (i) an ablation that replaces the curvature computation with a simple neighbor-consistency loss using the same k-NN structure and (ii) a synthetic experiment on points sampled from a sphere, where the discrete score can be compared against the known analytic curvature. Full validation on a torus would require further theoretical work that lies outside the present scope; we will therefore mark this as a limitation and focus the added experiment on the sphere case. revision: partial
-
Referee: [Experiments] Experiments section: no ablation studies quantify the sensitivity to the free parameters k and the curvature-loss weight, nor compare against a generic consistency regularizer with matched computational cost. These omissions leave open whether the reported gains are specific to the proposed geometric construction.
Authors: We accept that sensitivity and specificity analyses are required. The revised experiments section will include systematic ablations over k (values 5, 10, 20) and the curvature-loss weight (range 0.1–1.0), reporting linear-evaluation accuracy for each setting. We will also implement a matched-cost generic consistency baseline that enforces view-invariant neighbor relations without the curvature formulation, and we will compare both accuracy and wall-clock overhead. These results will be presented in a new table or figure. revision: yes
Circularity Check
No circularity in CurvSSL: curvature regularizer is explicitly defined and independent
full rationale
The paper defines a discrete curvature score directly from kNN cosine interactions on unit-hypersphere embeddings (or normalized local Gram matrix in the kernel case) and applies an additional Barlow-style alignment/decorrelation loss on the resulting curvature matrix. This regularizer is structurally separate from the core redundancy-reduction term, involves no fitted parameters renamed as predictions, and relies on no self-citations or imported uniqueness theorems for its justification. The claimed improvement is presented as an empirical outcome of the combined loss rather than a derivation that reduces to its own inputs by construction. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- k (nearest neighbors)
- curvature loss weight
axioms (2)
- domain assumption Embeddings are normalized to lie on the unit hypersphere
- ad hoc to paper Local manifold curvature can be approximated by average cosine interactions among k nearest neighbors
invented entities (1)
-
Curvature score matrix
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 from nontrivial linking on S^D) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
c(xi) := sum_{a=1}^{k-1} sum_{b=a+1}^k (z_a - z_i)^T (z_b - z_i) / (||...|| ||...||) after centering and unit-hypersphere normalization; analogous normalized Gram matrix in RKHS
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely satisfies the calibrated reciprocal functional equation) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lcurv on curvature-derived cross-matrix M plus Lemb redundancy reduction; total L = Lemb + α_curv Lcurv
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Normalized kernels as similarity indices
Ah-Pine, J. Normalized kernels as similarity indices. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp.\ 362--373. Springer, 2010
work page 2010
-
[3]
VICReg : Variance-invariance-covariance regularization for self-supervised learning
Bardes, A., Ponce, J., and LeCun, Y. VICReg : Variance-invariance-covariance regularization for self-supervised learning. In International Conference on Learning Representations, 2022
work page 2022
-
[4]
A simple framework for contrastive learning of visual representations
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pp.\ 1597--1607. PmLR, 2020
work page 2020
-
[5]
Coxeter, H. S. M. Regular polytopes. Courier Corporation, 1973
work page 1973
-
[6]
Progymnasmata de solidorum elementis
Descartes, R. Progymnasmata de solidorum elementis. Oeuvres de Descartes, X: 0 265--276, 1890
-
[7]
Anomaly detection and prototype selection using polyhedron curvature
Ghojogh, B., Karray, F., and Crowley, M. Anomaly detection and prototype selection using polyhedron curvature. In Canadian Conference on Artificial Intelligence, pp.\ 238--250. Springer, 2020
work page 2020
-
[8]
Ghojogh, B., Crowley, M., Karray, F., and Ghodsi, A. Background on kernels. Elements of Dimensionality Reduction and Manifold Learning, pp.\ 43--73, 2023
work page 2023
-
[9]
Introduction to RKHS , and some simple kernel algorithms
Gretton, A. Introduction to RKHS , and some simple kernel algorithms. Adv. Top. Mach. Learn. Lecture Conducted from University College London, 16 0 (5-3): 0 2, 2013
work page 2013
-
[10]
Bootstrap your own latent-a new approach to self-supervised learning
Grill, J.-B., Strub, F., Altch \'e , F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33: 0 21271--21284, 2020
work page 2020
-
[11]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
work page 2016
-
[12]
Hilton, P. and Pedersen, J. Descartes, Euler , Poincare , Polya and polyhedra. S \'e minaire de Philosophie et Math \'e matiques , 0 (8): 0 1--17, 1982
work page 1982
-
[13]
Hofmann, T., Sch \"o lkopf, B., and Smola, A. J. Kernel methods in machine learning. The annals of statistics, pp.\ 1171--1220, 2008
work page 2008
-
[14]
Kingma, D. P. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Krizhevsky, A. and Hinton, G. Learning multiple layers of features from tiny images. Technical report, University of Toronto, ON, Canada, 2009
work page 2009
-
[16]
Gradient-based learning applied to document recognition
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86 0 (11): 0 2278--2324, 1998
work page 1998
-
[17]
Markvorsen, S. Curvature and shape. In Yugoslav Geometrical Seminar, Fall School of Differential Geometry, Yugoslavia, pp.\ 55--75, 1996
work page 1996
-
[18]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., and Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
T., Kumar, M., Mittal, A., and Kumar, K
Rani, V., Nabi, S. T., Kumar, M., Mittal, A., and Kumar, K. Self-supervised learning: A succinct review. Archives of Computational Methods in Engineering, 30 0 (4): 0 2761--2775, 2023
work page 2023
-
[20]
Richeson, D. S. Euler's Gem: The Polyhedron Formula and the Birth of Topology, volume 64. Princeton University Press, 2019
work page 2019
-
[21]
The kernel trick for distances
Sch \"o lkopf, B. The kernel trick for distances. In Advances in neural information processing systems, pp.\ 301--307, 2001
work page 2001
-
[22]
Sepanj, H. and Fieguth, P. Aligning feature distributions in VICReg using maximum mean discrepancy for enhanced manifold awareness in self-supervised representation learning. Journal of Computational Vision and Imaging Systems, 10 0 (1): 0 13--18, 2024
work page 2024
- [23]
-
[24]
H., Ghojogh, B., and Fieguth, P
Sepanj, M. H., Ghojogh, B., and Fieguth, P. Self-supervised learning using nonlinear dependence. IEEE Access, 13: 0 190582--190589, 2025 a
work page 2025
-
[25]
H., Ghojogh, B., and Fieguth, P
Sepanj, M. H., Ghojogh, B., and Fieguth, P. Kernel VICReg for self-supervised learning in reproducing kernel Hilbert space. arXiv preprint arXiv:2509.07289, 2025 b
-
[26]
Barlow twins: Self-supervised learning via redundancy reduction
Zbontar, J., Jing, L., Misra, I., LeCun, Y., and Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In International conference on machine learning, pp.\ 12310--12320. PMLR, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.