CHiQPM: Calibrated Hierarchical Interpretable Image Classification
Pith reviewed 2026-05-17 04:21 UTC · model grok-4.3
The pith
CHiQPM keeps nearly full accuracy of black-box models while adding hierarchical global and local explanations plus interpretable conformal prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Calibrated Hierarchical QPM (CHiQPM) achieves state-of-the-art accuracy as a point predictor, maintaining 99% accuracy of non-interpretable models. It offers superior global interpretability by contrastively explaining the majority of classes and novel hierarchical explanations that are more similar to how humans reason and can be traversed to offer a built-in interpretable Conformal prediction method. Its calibrated set prediction is competitively efficient to other CP methods, while providing interpretable predictions of coherent sets along its hierarchical explanation.
What carries the argument
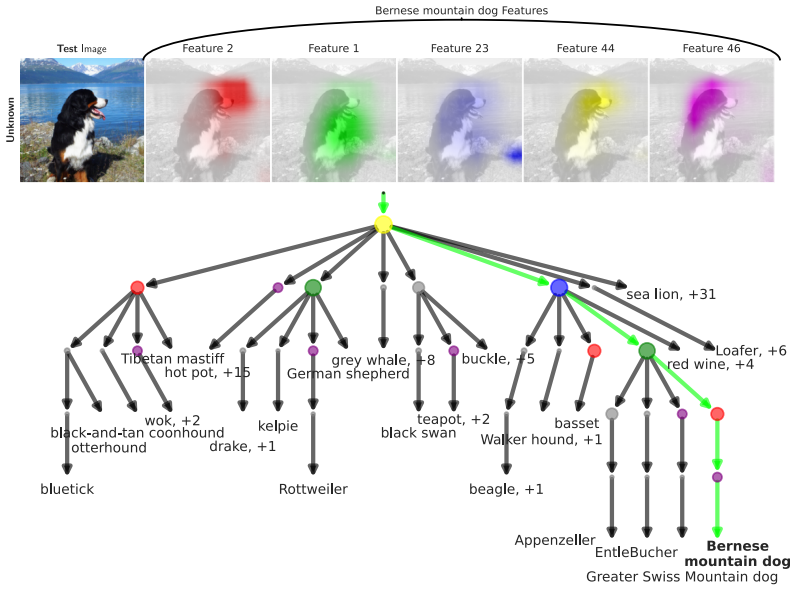
The calibrated hierarchical structure in CHiQPM that produces contrastive global explanations for most classes and supports traversal for local explanations and coherent prediction sets.
If this is right
- Maintains 99% accuracy of non-interpretable models as a point predictor.
- Supplies superior global interpretability by contrastively explaining the majority of classes.
- Enables traversal of hierarchical explanations for detailed local interpretability.
- Produces competitively efficient calibrated set predictions with coherent and interpretable sets.
Where Pith is reading between the lines
- Experts in safety-critical fields could follow the hierarchy to narrow down uncertain predictions and verify them step by step.
- The contrastive global explanations might make it easier to spot systematic errors across an entire class set than with per-class methods.
- The same hierarchical traversal could be tested as an add-on to improve the transparency of existing conformal prediction pipelines.
Load-bearing premise
The assumption that the novel hierarchical explanations are more similar to how humans reason than standard flat explanations.
What would settle it
A user study in which experts using CHiQPM hierarchies make measurably better or faster decisions than with non-hierarchical interpretable models on the same image tasks.
Figures

































read the original abstract
Globally interpretable models are a promising approach for trustworthy AI in safety-critical domains. Alongside global explanations, detailed local explanations are a crucial complement to effectively support human experts during inference. This work proposes the Calibrated Hierarchical QPM (CHiQPM) which offers uniquely comprehensive global and local interpretability, paving the way for human-AI complementarity. CHiQPM achieves superior global interpretability by contrastively explaining the majority of classes and offers novel hierarchical explanations that are more similar to how humans reason and can be traversed to offer a built-in interpretable Conformal prediction (CP) method. Our comprehensive evaluation shows that CHiQPM achieves state-of-the-art accuracy as a point predictor, maintaining 99% accuracy of non-interpretable models. This demonstrates a substantial improvement, where interpretability is incorporated without sacrificing overall accuracy. Furthermore, its calibrated set prediction is competitively efficient to other CP methods, while providing interpretable predictions of coherent sets along its hierarchical explanation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CHiQPM, a Calibrated Hierarchical QPM for image classification that supplies global contrastive explanations for the majority of classes together with novel hierarchical local explanations. These explanations are claimed to resemble human reasoning and to support a built-in interpretable conformal-prediction procedure. The central empirical claim is that CHiQPM attains state-of-the-art point-prediction accuracy while retaining 99 % of the accuracy of non-interpretable reference models and that its set predictions remain competitively efficient.
Significance. If the accuracy and calibration results hold under capacity-matched controls, the work would constitute a concrete demonstration that hierarchical interpretability can be added to image classifiers with negligible performance cost. The built-in conformal-prediction mechanism that traverses the hierarchy is a distinctive technical contribution that could facilitate human-AI complementarity in safety-critical settings.
major comments (1)
- [§4 and Table 2] §4 (Experimental evaluation) and Table 2: the claim that CHiQPM 'maintains 99 % accuracy of non-interpretable models' is load-bearing for the central thesis. The manuscript does not demonstrate that the non-interpretable baselines employ the identical backbone, feature extractor, training schedule, or regularization as CHiQPM. Without such capacity-matched ablations, any observed accuracy parity could be explained by differences in model capacity rather than by the compatibility of the hierarchical interpretability mechanism with high accuracy.
minor comments (2)
- [Abstract] The abstract states that the hierarchical explanations 'are more similar to how humans reason' without citing supporting cognitive-science references or user studies; a brief pointer to relevant literature would strengthen the claim.
- [§3] Notation for the hierarchical levels and the conformal-prediction sets is introduced without an explicit legend; adding a small diagram or table that maps symbols to concepts would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting the importance of capacity-matched controls to substantiate our central accuracy claim. We address the major comment below and will revise the manuscript to incorporate the requested experiments.
read point-by-point responses
-
Referee: [§4 and Table 2] §4 (Experimental evaluation) and Table 2: the claim that CHiQPM 'maintains 99 % accuracy of non-interpretable models' is load-bearing for the central thesis. The manuscript does not demonstrate that the non-interpretable baselines employ the identical backbone, feature extractor, training schedule, or regularization as CHiQPM. Without such capacity-matched ablations, any observed accuracy parity could be explained by differences in model capacity rather than by the compatibility of the hierarchical interpretability mechanism with high accuracy.
Authors: We agree that explicit capacity-matched ablations are necessary to isolate the effect of the hierarchical interpretability mechanism. In the current manuscript, non-interpretable baselines were selected from standard literature results using comparable architectures (e.g., ResNet-50/101), but we did not retrain them under identical conditions to CHiQPM. In the revised version, we will add new experiments that train a non-interpretable classifier using the exact same backbone, feature extractor, training schedule, optimizer, and regularization as CHiQPM (removing only the hierarchical QPM components). We will report these results in an updated Table 2 and expanded Section 4, confirming that CHiQPM retains ~99% of the matched baseline accuracy. This directly addresses the concern and strengthens the central thesis. revision: yes
Circularity Check
No circularity: empirical claims rest on independent evaluations
full rationale
The paper defines CHiQPM as a novel hierarchical model combining QPM with conformal prediction for interpretable image classification. All load-bearing claims (SOTA point-prediction accuracy at 99% of non-interpretable baselines, competitive calibrated set prediction, and human-like hierarchical explanations) are justified by direct experimental comparisons on standard benchmarks rather than by any derivation that reduces to fitted inputs, self-citations, or ansatzes imported from prior author work. No equations or uniqueness theorems are invoked that would make the reported performance equivalent to the model definition by construction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hierarchical explanations are more similar to how humans reason
invented entities (1)
-
CHiQPM
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CHiQPM consists of a deep feature extractor Φ ... and a sparse interpretable final assignment W* ... prediction y = W* f* with ReLU
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical local explanations ... traversing them to dynamically ... construct coherent prediction sets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ahsan, M. M., Luna, S. A., and Siddique, Z. Machine-learning-based disease diagnosis: A comprehensive review. InHealthcare, volume 10, pp. 541. MDPI, 2022
work page 2022
-
[2]
Alvarez Melis, D. and Jaakkola, T. Towards robust interpretability with self-explaining neural networks.Advances in neural information processing systems, 31, 2018
work page 2018
-
[3]
Position: Interpretability is a bidirectional communication problem
Ayonrinde, K. Position: Interpretability is a bidirectional communication problem. InICLR 2025 Workshop on Bidirectional Human-AI Alignment
work page 2025
-
[4]
Network dissection: Quantifying interpretability of deep visual representations
Bau, D., Zhou, B., Khosla, A., Oliva, A., and Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 6541–6549, 2017
work page 2017
-
[5]
B-cos networks: Alignment is all we need for interpretabil- ity
Böhle, M., Fritz, M., and Schiele, B. B-cos networks: Alignment is all we need for interpretabil- ity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10329–10338, 2022
work page 2022
-
[6]
Chen, C., Li, O., Tao, D., Barnett, A., Rudin, C., and Su, J. K. This looks like that: deep learning for interpretable image recognition.Advances in neural information processing systems, 32, 2019
work page 2019
-
[7]
V ., Louizos, C., and Behboodi, A
Correia, A., Massoli, F. V ., Louizos, C., and Behboodi, A. An information theoretic perspective on conformal prediction. InThe Thirty-eighth Annual Conference on Neural Information Pro- cessing Systems, 2024. URLhttps://openreview.net/forum?id=gKLgY3m9zj
work page 2024
-
[8]
M., Byun, Y ., Wu, S., Horvitz, E., and Wilder, B
Cortes-Gomez, S., Patiño, C. M., Byun, Y ., Wu, S., Horvitz, E., and Wilder, B. Utility-directed conformal prediction: A decision-aware framework for actionable uncertainty quantification. In The Thirteenth International Conference on Learning Representations, 2025. URL https: //openreview.net/forum?id=iOMnn1hSBO
work page 2025
-
[9]
Ding, T., Angelopoulos, A., Bates, S., Jordan, M., and Tibshirani, R. J. Class-conditional conformal prediction with many classes.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[10]
Coun- terfactual concept bottleneck models
Dominici, G., Barbiero, P., Giannini, F., Gjoreski, M., Marra, G., and Langheinrich, M. Coun- terfactual concept bottleneck models. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=w7pMjyjsKN
work page 2025
-
[11]
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Cub-200-2011 segmentations, Apr 2022
Farrell, R. Cub-200-2011 segmentations, Apr 2022
work page 2011
-
[13]
Craft: Concept recursive activation factorization for explainability
Fel, T., Picard, A., Béthune, L., Boissin, T., Vigouroux, D., Colin, J., Cadène, R., and Serre, T. Craft: Concept recursive activation factorization for explainability. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2711–2721, June 2023. 11
work page 2023
-
[14]
Gildenblat, J. and contributors. Pytorch library for cam methods. https://github.com/ jacobgil/pytorch-grad-cam, 2021
work page 2021
-
[15]
Glandorf, P. and Rosenhahn, B. Pruning by block benefit: Exploring the properties of vision transformer blocks during domain adaptation. InInternational Conference on Computer Vision Workshop, 2025
work page 2025
-
[16]
Hypersparse neural networks: Shifting exploration to exploitation through adaptive regularization
Glandorf, P., Kaiser, T., and Rosenhahn, B. Hypersparse neural networks: Shifting exploration to exploitation through adaptive regularization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1234–1243, 2023
work page 2023
-
[17]
Gurobi Optimizer Reference Manual, 2023
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2023. URL https://www. gurobi.com
work page 2023
-
[18]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[19]
We can’t understand ai using our existing vocabulary.arXiv preprint arXiv:2502.07586, 2025
Hewitt, J., Geirhos, R., and Kim, B. We can’t understand ai using our existing vocabulary.arXiv preprint arXiv:2502.07586, 2025
-
[20]
Hoffmann, A., Fanconi, C., Rade, R., and Kohler, J. This looks like that... does it? shortcomings of latent space prototype interpretability in deep networks, 2021
work page 2021
-
[21]
UncertainSAM: Fast and efficient uncertainty quantification of the segment anything model
Kaiser, T., Norrenbrock, T., and Rosenhahn, B. UncertainSAM: Fast and efficient uncertainty quantification of the segment anything model. InForty-second International Conference on Ma- chine Learning, 2025. URLhttps://openreview.net/forum?id=G3j3kq7rSC
work page 2025
-
[22]
B., Firooz, H., Sanjabi, M., and Feizi, S
Kalibhat, N., Bhardwaj, S., Bruss, C. B., Firooz, H., Sanjabi, M., and Feizi, S. Identify- ing interpretable subspaces in image representations. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),Proceedings of the 40th International Con- ference on Machine Learning, volume 202 ofProceedings of Machine Learning Rese...
work page 2023
-
[23]
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning, pp. 2668–2677. PMLR, 2018
work page 2018
-
[24]
Kim, S. S., Meister, N., Ramaswamy, V . V ., Fong, R., and Russakovsky, O. Hive: evaluating the human interpretability of visual explanations. InComputer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XII, pp. 280–298. Springer, 2022
work page 2022
-
[25]
Koh, P. W., Nguyen, T., Tang, Y . S., Mussmann, S., Pierson, E., Kim, B., and Liang, P. Concept bottleneck models. InInternational Conference on Machine Learning, pp. 5338–5348. PMLR, 2020
work page 2020
-
[26]
3d object representations for fine-grained categorization
Krause, J., Stark, M., Deng, J., and Fei-Fei, L. 3d object representations for fine-grained categorization. In4th International IEEE Workshop on 3D Representation and Recognition (3dRR-13), Sydney, Australia, 2013
work page 2013
-
[27]
Kuutti, S., Bowden, R., Jin, Y ., Barber, P., and Fallah, S. A survey of deep learning applications to autonomous vehicle control.IEEE Transactions on Intelligent Transportation Systems, 22(2): 712–733, 2020
work page 2020
-
[28]
Contrastive explanation.Royal Institute of Philosophy Supplements, 27:247–266, 1990
Lipton, P. Contrastive explanation.Royal Institute of Philosophy Supplements, 27:247–266, 1990
work page 1990
-
[29]
Swin transformer: Hierarchical vision transformer using shifted windows
Liu, Z., Lin, Y ., Cao, Y ., Hu, H., Wei, Y ., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022, 2021. 12
work page 2021
-
[30]
Accurate intelligible models with pairwise interactions
Lou, Y ., Caruana, R., Gehrke, J., and Hooker, G. Accurate intelligible models with pairwise interactions. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 623–631, 2013
work page 2013
-
[31]
Ma, C., Zhao, B., Chen, C., and Rudin, C. This looks like those: Illuminating prototypical concepts using multiple visualizations.Advances in Neural Information Processing Systems, 36:39212–39235, 2023
work page 2023
-
[32]
Glancenets: Interpretable, leak-proof concept-based models
Marconato, E., Passerini, A., and Teso, S. Glancenets: Interpretable, leak-proof concept-based models. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id= J7zY9j75GoG
work page 2022
-
[33]
Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289, 2021
Margeloiu, A., Ashman, M., Bhatt, U., Chen, Y ., Jamnik, M., and Weller, A. Do concept bottleneck models learn as intended?arXiv preprint arXiv:2105.04289, 2021
-
[34]
Miller, G. A. The magical number seven, plus or minus two: Some limits on our capacity for processing information.Psychological review, 63(2):81, 1956
work page 1956
-
[35]
Miller, T. Explanation in artificial intelligence: Insights from the social sciences.Artificial intelligence, 267:1–38, 2019
work page 2019
-
[36]
Molnar, C.Interpretable machine learning. Lulu. com, 2020
work page 2020
-
[37]
Neural prototype trees for interpretable fine-grained image recognition
Nauta, M., van Bree, R., and Seifert, C. Neural prototype trees for interpretable fine-grained image recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14933–14943, 2021
work page 2021
-
[38]
Nauta, M., Schlötterer, J., van Keulen, M., and Seifert, C. Pip-net: Patch-based intuitive prototypes for interpretable image classification.Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
work page 2023
-
[39]
Take 5: Interpretable image classification with a handful of features
Norrenbrock, T., Rudolph, M., and Rosenhahn, B. Take 5: Interpretable image classification with a handful of features. InProgress and Challenges in Building Trustworthy Embodied AI, 2022
work page 2022
-
[40]
Q-senn: Quantized self-explaining neural networks
Norrenbrock, T., Rudolph, M., and Rosenhahn, B. Q-senn: Quantized self-explaining neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp. 21482–21491, 2024
work page 2024
-
[41]
QPM: Discrete optimization for globally interpretable image classification
Norrenbrock, T., Kaiser, T., Biswas, S., Manuvinakurike, R., and Rosenhahn, B. QPM: Discrete optimization for globally interpretable image classification. InThe Thirteenth International Con- ference on Learning Representations, 2025. URL https://openreview.net/forum? id=GlAeL0I8LX
work page 2025
-
[42]
Oikarinen, T. and Weng, T.-W. CLIP-dissect: Automatic description of neuron representations in deep vision networks. InThe Eleventh International Conference on Learning Representations,
-
[43]
URLhttps://openreview.net/forum?id=iPWiwWHc1V
-
[44]
Inductive confidence machines for regression
Papadopoulos, H., Proedrou, K., V ovk, V ., and Gammerman, A. Inductive confidence machines for regression. InMachine learning: ECML 2002: 13th European conference on machine learning Helsinki, Finland, August 19–23, 2002 proceedings 13, pp. 345–356. Springer, 2002
work page 2002
-
[45]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chin- tala, S. Pytorch: An imperative style, high-performance deep learning library. In Wallach, H., Larochelle...
work page 2019
-
[46]
Read, S. J. and Marcus-Newhall, A. Explanatory coherence in social explanations: A parallel distributed processing account.Journal of Personality and Social Psychology, 65(3):429, 1993
work page 1993
-
[47]
Romano, Y ., Sesia, M., and Candes, E. Classification with valid and adaptive coverage.Advances in Neural Information Processing Systems, 33:3581–3591, 2020
work page 2020
-
[48]
Rosenhahn, B. Optimization of sparsity-constrained neural networks as a mixed integer linear program: Nn2milp.Journal of Optimization Theory and Applications, 199(3):931–954, 2023
work page 2023
-
[49]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 115(3):211–252,
-
[50]
doi: 10.1007/s11263-015-0816-y
-
[51]
Rymarczyk, D., Struski, Ł., Tabor, J., and Zieli´nski, B. Protopshare: Prototypical parts sharing for similarity discovery in interpretable image classification. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pp. 1420–1430, 2021
work page 2021
-
[52]
Sadinle, M., Lei, J., and Wasserman, L. Least ambiguous set-valued classifiers with bounded error levels.Journal of the American Statistical Association, 114(525):223–234, 2019
work page 2019
-
[53]
Sawada, Y . and Nakamura, K. Concept bottleneck model with additional unsupervised concepts. IEEE Access, 10:41758–41765, 2022
work page 2022
-
[54]
Polysemanticity and capacity in neural networks
Scherlis, A., Sachan, K., Jermyn, A. S., Benton, J., and Shlegeris, B. Polysemanticity and capacity in neural networks.arXiv preprint arXiv:2210.01892, 2022
-
[55]
Explainable reinforcement learning via dynamic mixture policies
Schier, M., Schubert, F., and Rosenhahn, B. Explainable reinforcement learning via dynamic mixture policies. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[56]
R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. InProceedings of the IEEE international conference on computer vision, pp. 618–626, 2017
work page 2017
-
[57]
R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. Grad-cam: visual explanations from deep networks via gradient-based localization.International journal of computer vision, 128:336–359, 2020
work page 2020
-
[58]
Straitouri, E. and Rodriguez, M. G. Designing decision support systems using counterfactual prediction sets. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2025
work page 2025
-
[59]
Straitouri, E., Wang, L., Okati, N., and Rodriguez, M. G. Improving expert predictions with conformal prediction. InInternational Conference on Machine Learning, pp. 32633–32653. PMLR, 2023
work page 2023
-
[60]
Stutz, D., Dvijotham, K. D., Cemgil, A. T., and Doucet, A. Learning optimal conformal classifiers. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=t8O-4LKFVx
work page 2022
-
[61]
Rethinking the inception architecture for computer vision
Szegedy, C., Vanhoucke, V ., Ioffe, S., Shlens, J., and Wojna, Z. Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 2818–2826, 2016
work page 2016
-
[62]
Templeton, A.Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Anthropic, 2024
work page 2024
-
[63]
Veale, M. and Zuiderveen Borgesius, F. Demystifying the draft eu artificial intelligence act—analysing the good, the bad, and the unclear elements of the proposed approach.Computer Law Review International, 22(4):97–112, 2021
work page 2021
-
[64]
V ovk, V ., Gammerman, A., and Shafer, G.Algorithmic learning in a random world, volume 29. Springer, 2005. 14
work page 2005
-
[65]
The caltech-ucsd birds-200-2011 dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The caltech-ucsd birds-200-2011 dataset. 2011
work page 2011
-
[66]
Wei, H. and Huang, J. Torchcp: A library for conformal prediction based on pytorch, 2024
work page 2024
-
[67]
Leveraging sparse linear layers for debuggable deep networks
Wong, E., Santurkar, S., and Madry, A. Leveraging sparse linear layers for debuggable deep networks. InInternational Conference on Machine Learning, pp. 11205–11216. PMLR, 2021
work page 2021
-
[68]
Zhang, J., Bargal, S. A., Lin, Z., Brandt, J., Shen, X., and Sclaroff, S. Top-down neural attention by excitation backprop.International Journal of Computer Vision, 126(10):1084–1102, 2018. 15 NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: ...
work page 2018
-
[69]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
work page 2025
-
[70]
As touched upon in Section 2.1, features can learn to detect multiple concepts, a phenomenon knows as polysemanticity. While the visualizations of features in Figures 31 to 34 indicate a consistent localization of the same feature across many classes on the same concept, proper metrics are missing to even measure that. However, we believe that a model lik...
-
[71]
While the activation maps of CHiQPM on CUB-2011 and Stanford Cars seem to localize very accurately,e.g. highlighting the red eye and not activating if it is not visible, the activation maps on ImageNet-1K seem to not always faithfully highlight the image region they respond to,e.g. Feature 23 in Figures 19, 29 and 30 consistently distributes a large porti...
work page 2011
-
[72]
CHiQPM learns general features that are well suited to classify the dataset given the training data. However, we do not restrict the features to be based on concepts that humans have noticed or named before. Therefore, there may exist a conceptual gap between the concepts learnt by CHiQPM and the ones known to humans. This Bi-directional Communication Pro...
work page 2080
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.