BRIDGE: Building Representations In Domain Guided Program Synthesis
Pith reviewed 2026-05-17 05:19 UTC · model grok-4.3
The pith
BRIDGE prompting connects generated code to formal specifications and proofs via domain-specific reasoning steps in Lean.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BRIDGE is a structured prompting framework that decomposes program synthesis into three interconnected domains of Code, Specification, and Theorem/Proof, inserting domain-specific intermediate reasoning steps to maintain consistency across the artifacts; in Lean it follows a code-first workflow that treats the generated implementation as a semantic anchor for producing the specification, theorem statement, and proof attempt.
What carries the argument
Domain-specific intermediate reasoning steps that link the Code, Specification, and Theorem/Proof domains while using the generated code as the central semantic reference.
If this is right
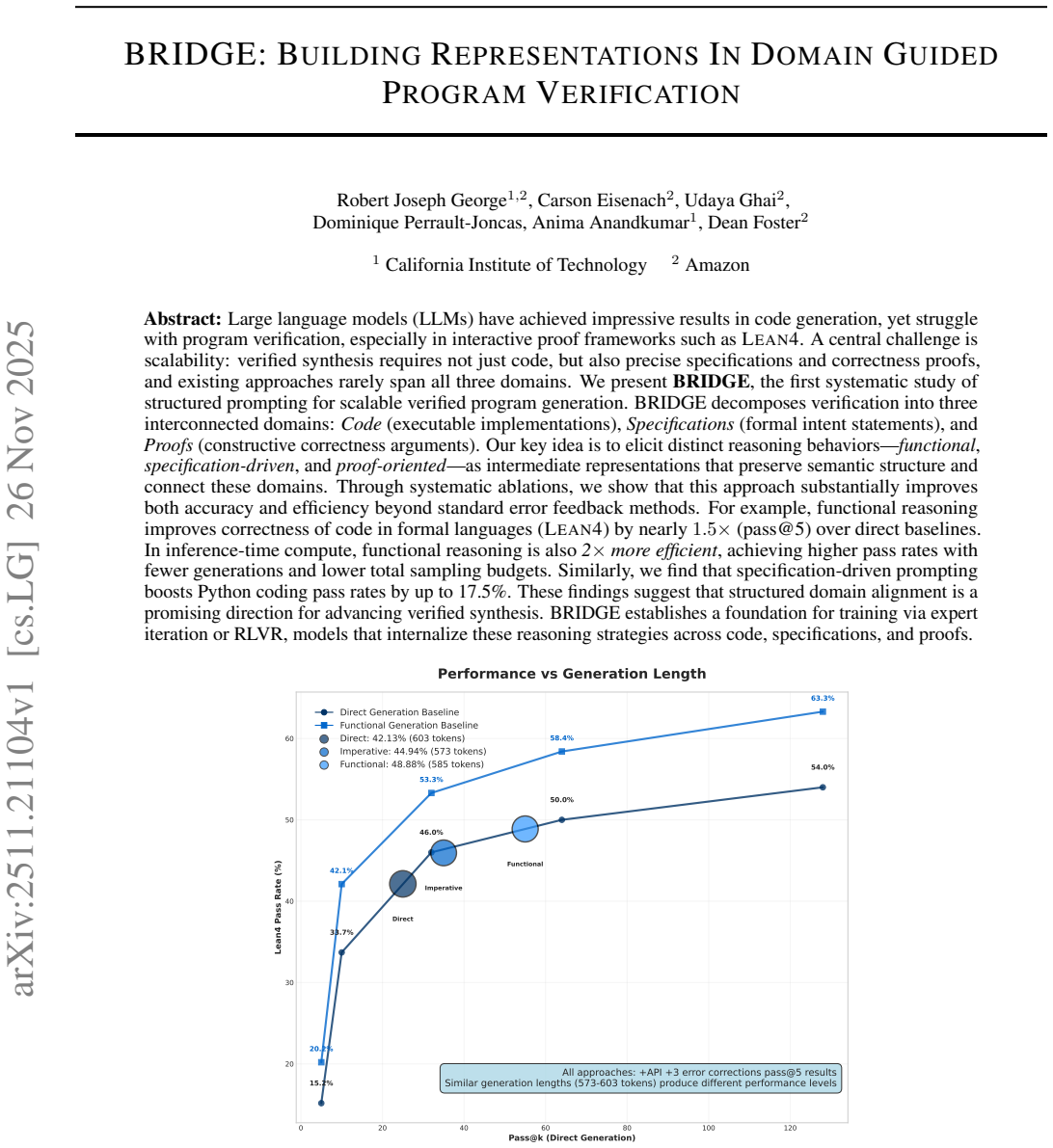
- Lean executable correctness rises by up to nearly 1.5 times relative to direct prompting on the same problems.
- Sample efficiency roughly doubles at comparable output lengths.
- Specification-focused prompting raises Python pass rates by as much as 17.5 percentage points.
- Supervised fine-tuning on BRIDGE reasoning traces produces nearly 1.5 times higher Lean pass rates than fine-tuning on code alone.
- A measurable gap remains between executable correctness and complete formal proof generation.
Where Pith is reading between the lines
- The same intermediate-reasoning pattern could be applied to other proof assistants such as Coq or Isabelle without changing the core structure.
- The generated reasoning traces offer a reusable source of training data that might improve models on related formal-synthesis benchmarks.
- Combining BRIDGE-style prompting with search or reinforcement learning over the intermediate steps could further close the gap to full proofs.
- The approach suggests that explicit cross-domain consistency checks are more important than raw model scale for verified code tasks.
Load-bearing premise
The intermediate reasoning steps produce specifications and proofs that remain semantically consistent with the generated code and do not introduce errors that break downstream Lean verification.
What would settle it
Run BRIDGE and direct prompting on the same 178 problems with a new LLM; if the Lean pass rate shows no consistent gain or if many generated proofs fail verification despite correct code execution, the central claim does not hold.
Figures











read the original abstract
Large language models can generate plausible code, but remain brittle for formal verification in proof assistants such as Lean. A central scalability challenge is that verified synthesis requires consistent artifacts across several coupled domains: executable code, formal specifications, theorem statements, and proof attempts. Existing approaches often treat these artifacts separately. We present BRIDGE, a structured prompting framework for multi-artifact program synthesis. BRIDGE decomposes generation into three interconnected domains: Code, Specification, and Theorem/Proof, and uses domain-specific intermediate reasoning to connect them. In Lean, BRIDGE often follows a code-first workflow, using the generated implementation as a semantic anchor for downstream specification, theorem statement, and proof-attempt generation. Across 178 algorithmic problems and five LLMs, BRIDGE improves Lean executable correctness by up to nearly 1.5x over direct prompting and can be roughly 2x more sample efficient at comparable generation lengths. We further find that specification-oriented prompting improves Python pass rates by up to 17.5 percentage points. Beyond inference-time prompting, supervised fine-tuning on BRIDGE-style reasoning traces yields nearly 1.5x higher Lean pass success than code-only fine-tuning, suggesting that these intermediate representations provide a learnable inductive bias. BRIDGE provides a practical framework for scaling verified synthesis while highlighting the remaining gap between executable correctness and full formal proof generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRIDGE, a structured prompting framework for multi-artifact program synthesis that decomposes generation into three interconnected domains (Code, Specification, and Theorem/Proof) using domain-specific intermediate reasoning steps. In a code-first workflow for Lean, the generated implementation serves as a semantic anchor for downstream artifacts. Across 178 algorithmic problems and five LLMs, it claims up to nearly 1.5x improvement in Lean executable correctness over direct prompting, roughly 2x better sample efficiency at comparable lengths, specification-oriented prompting gains of up to 17.5 percentage points in Python, and nearly 1.5x higher Lean pass rates from supervised fine-tuning on BRIDGE-style traces versus code-only fine-tuning.
Significance. If the results hold under scrutiny, the work is significant for scaling LLM-assisted verified synthesis. It provides a practical inference-time framework for handling coupled artifacts and demonstrates that the intermediate representations supply a learnable inductive bias, as evidenced by the SFT experiments. The evaluation scale (178 problems, multiple LLMs) and the distinction between executable correctness and full proof generation are useful contributions.
major comments (2)
- [§5] §5 (Experiments) and associated tables: The central claim that BRIDGE produces consistent multi-artifact outputs relies on the domain-specific intermediates reliably linking code semantics to specifications and theorems. However, the reported metrics are limited to aggregate Lean executable correctness and pass rates with no explicit measure, ablation, or consistency check quantifying semantic alignment (e.g., whether generated pre/post-conditions or theorem statements match the actual behavior of the code). This leaves open the possibility that gains are driven by improved code generation alone rather than verified multi-domain consistency.
- [§5.3] §5.3 (SFT experiments): The claim that BRIDGE-style reasoning traces provide a superior inductive bias for fine-tuning is load-bearing for the broader contribution, yet the comparison to code-only fine-tuning does not report controls for trace length, data quality filtering, or whether the traces were verified for internal consistency before use in SFT.
minor comments (2)
- [§4] The abstract and §4 could more explicitly define what constitutes a 'domain-specific intermediate reasoning step' with a short illustrative example from one of the 178 problems.
- Figure captions and axis labels in the efficiency plots would benefit from stating the exact generation length ranges used for the 'comparable generation lengths' comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments identify valuable opportunities to strengthen the presentation of our experimental results and the SFT analysis. We address each major comment below and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§5] §5 (Experiments) and associated tables: The central claim that BRIDGE produces consistent multi-artifact outputs relies on the domain-specific intermediates reliably linking code semantics to specifications and theorems. However, the reported metrics are limited to aggregate Lean executable correctness and pass rates with no explicit measure, ablation, or consistency check quantifying semantic alignment (e.g., whether generated pre/post-conditions or theorem statements match the actual behavior of the code). This leaves open the possibility that gains are driven by improved code generation alone rather than verified multi-domain consistency.
Authors: We agree that an explicit quantification of semantic alignment would provide stronger support for the multi-artifact consistency claim. Our evaluation centers on Lean executable correctness because it offers an objective, automated signal that the generated code satisfies test cases, and the code-first workflow is designed to use this implementation as a semantic anchor for subsequent specification and theorem generation. Nevertheless, we acknowledge that aggregate pass rates alone do not directly measure whether the generated pre/post-conditions or theorem statements are semantically faithful to the code. In the revised manuscript we will add a new subsection with an ablation that generates specifications and theorems both with and without the BRIDGE intermediate steps, then reports the fraction of generated specifications that are satisfied by the code on held-out test cases as well as a manual audit of theorem-statement alignment on a random sample of 30 problems. revision: yes
-
Referee: [§5.3] §5.3 (SFT experiments): The claim that BRIDGE-style reasoning traces provide a superior inductive bias for fine-tuning is load-bearing for the broader contribution, yet the comparison to code-only fine-tuning does not report controls for trace length, data quality filtering, or whether the traces were verified for internal consistency before use in SFT.
Authors: We appreciate the referee’s emphasis on rigorous controls for the SFT comparison. The BRIDGE traces used for fine-tuning were produced by the same prompting procedure and retained only those that yielded executable code; the code-only baseline was constructed from the same problems and filtered by the same execution criterion. We did not, however, explicitly match or report average trace lengths or perform additional automated consistency checks beyond execution success. In the revision we will add a table reporting average token lengths for the BRIDGE-style and code-only training sets, describe the exact filtering pipeline, and note that internal consistency was enforced via execution verification where feasible. Full manual verification of every trace was not performed due to dataset scale, but the observed performance gap remains informative given the matched problem set and execution filter. revision: partial
Circularity Check
No circularity: purely empirical claims with no derivations or self-referential reductions
full rationale
The paper describes an empirical prompting framework (BRIDGE) for generating code, specs, and proofs in Lean, evaluated on 178 problems across five LLMs with reported gains in executable correctness and sample efficiency versus direct prompting and code-only fine-tuning. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All central claims rest on experimental comparisons rather than any chain that reduces to its own inputs by construction, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can generate plausible code and intermediate reasoning traces when given structured prompts.
invented entities (1)
-
Domain-specific intermediate reasoning
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BRIDGE decomposes verification into three interconnected domains: Code, Specifications, and Proofs and provides a scalable way to generate and interconnect them.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Functional reasoning improves correctness of code in formal languages (LEAN4) by nearly 1.5×
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AUSTIN, J., ODENA, A., NYE, M., BOSMA, M., MICHALEWSKI, H., DOHAN, D., JIANG, E., CAI, C., TERRY, M., LE, Q.ET AL. (2021). Program synthesis with large language models.arXiv:2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
BARNETT, M., CHANG, B.-Y. E., DELINE, R., JACOBS, B. and LEINO, K. R. M. (2005). Boogie: A modular reusable verifier for object-oriented programs. InFormal Methods for Components and Objects. Springer, 364–387
work page 2005
-
[3]
BERTOT, Y. and CASTÉRAN, P. (2013).Interactive Theorem Proving and Program Development: Coq’Art: The Calculus of Inductive Constructions. Springer Science & Business Media
work page 2013
-
[4]
BOBOT, F., FILLIÂTRE, J.-C., MARCHÉ, C. and PASKEVICH, A. (2011). Why3: Shepherd your herd of provers. In Boogie 2011: First International Workshop on Intermediate Verification Languages
work page 2011
-
[5]
E., KUKOVEC, J., SINGH, A., BUTTERLEY, O., BIZID, A., DOUGHERTY, Q., ZHAO, M., TAN, M
BURSUC, S., EHRENBORG, T., LIN, S., ASTEFANOAEI, L., CHIOSA, I. E., KUKOVEC, J., SINGH, A., BUTTERLEY, O., BIZID, A., DOUGHERTY, Q., ZHAO, M., TAN, M. and TEGMARK, M. (2025). A benchmark for vericoding: Formally verified program synthesis.arXiv:2509.22908
-
[6]
CHEN, M., TWOREK, J., JUN, H., YUAN, Q.,DEOLIVEIRAPINTO, H. P., KAPLAN, J., EDWARDS, H., BURDA, Y., JOSEPH, N., BROCKMAN, G., RAY, A., PURI, N., KRUEGER, G., PETROV, M., KHLAAF, H., SASTRY, G., MISHKIN, P., CHAN, B., GRAY, S., RYDER, N., PAVLOV, M., POWER, B., KAISER, L., BAVARIAN, M., WINTER, C., TILLET, P., SUCH, F. P., CUMMINGS, A., PLAPPERT, M., CHANT...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
CLARKE, E. M. and WING, J. M. (1996). Formal methods: State of the art and future directions.ACM Computing Surveys 28626–643. 12 BRIDGE: Domain Guided Program VerificationA PREPRINT
work page 1996
-
[8]
DEMOURA, L., KONG, S., AVIGAD, J.,VANDOORN, F. andVONRAUMER, J. (2015). The lean theorem prover (system description). InAutomated Deduction - CADE-25: 25th International Conference on Automated Deduction. Springer
work page 2015
-
[9]
DIJKSTRA, E. W. (1976).A discipline of programming. Prentice Hall
work page 1976
-
[10]
FENG, Z., GUO, D., TANG, D., DUAN, N., FENG, X., GONG, M., SHOU, L., QIN, B., LIU, T., JIANG, D. and ZHOU, M. (2020). Codebert: A pre-trained model for programming and natural languages. InFindings of the Association for Computational Linguistics: EMNLP 2020
work page 2020
-
[11]
FLOYD, R. W. (1967). Assigning meanings to programs. InProceedings of the Symposium on Applied Mathematics, vol. 19. American Mathematical Society, 19–32
work page 1967
-
[12]
PAL: Program-aided Language Models
GAO, L., MADAAN, A., ZHOU, S., ALON, U., LIU, P., YANG, Y., CALLAN, J. and NEUBIG, G. (2022). Pal: Program- aided language models.arXiv:2211.10435
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
K., CLEMENT, C., DRAIN, D., SUNDARESAN, N., YIN, J., JIANG, D
GUO, D., REN, S., LU, S., FENG, Z., TANG, D., DUAN, N., SVYATKOVSKIY, A., FU, S., TUFANO, M., DENG, S. K., CLEMENT, C., DRAIN, D., SUNDARESAN, N., YIN, J., JIANG, D. and ZHOU, M. (2021). Graphcodebert: Pre-training code representations with data flow. InInternational Conference on Learning Representations (ICLR)
work page 2021
-
[14]
HOARE, C. A. R. (1969). An axiomatic basis for computer programming.Communications of the ACM12576–580
work page 1969
-
[15]
HOARE, C. A. R. (1971). Procedures and parameters: An axiomatic approach. InSymposium on Semantics of Algorithmic Languages
work page 1971
-
[16]
HUDAK, P. (1989). Conception, evolution, and application of functional programming languages.ACM Computing Surveys 21359–411
work page 1989
-
[17]
KLEIN, G., ELPHINSTONE, K., HEISER, G., ANDRONICK, J., COCK, D., DERRIN, P., ELKADUWE, D., ENGELHARDT, K., KOLANSKI, R., NORRISH, M.ET AL. (2009). sel4: Formal verification of an operating-system kernel. InProceedings of the ACM SIGOPS 22nd symposium on Operating systems principles. ACM
work page 2009
-
[18]
LATTUADA, A., HANCE, T., CHO, C., BRUN, M., SUBASINGHE, I., ZHOU, Y., HOWELL, J., PARNO, B. and HAW- BLITZEL, C. (2023). Verus: Verifying rust programs using linear ghost types.Proc. ACM Program. Lang.7
work page 2023
-
[19]
LEINO, K. R. M. (2010). Dafny: An automatic program verifier for functional correctness. InInternational Conference on Logic for Programming Artificial Intelligence and Reasoning. Springer
work page 2010
-
[20]
LEROY, X. (2009). Formal verification of a realistic compiler.Communications of the ACM52107–115
work page 2009
-
[21]
LOHN, E. and WELLECK, S. (2024). minicodeprops: a minimal benchmark for proving code properties. arXiv:2406.11915
- [22]
-
[23]
Self-Refine: Iterative Refinement with Self-Feedback
MADAAN, A., TANDON, N., GUPTA, P., HALLINAN, S., GAO, L., WIEGREFFE, S., ALON, U., DZIRI, N., PRABHUMOYE, S., YANG, Y., GUPTA, S., MAJUMDER, B. P., HERMANN, K., WELLECK, S. and CLARK, P. (2023). Self-refine: Iterative refinement with self-feedback.arXiv:2303.17651
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
MATHLIBCOMMUNITY, T. (2020). The lean mathematical library. InProceedings of the 9th ACM SIGPLAN International Conference on Certified Programs and Proofs. ACM, New Orleans, LA, USA
work page 2020
-
[25]
MIRANDA, B., ZHOU, Z., NIE, A., OBBAD, E., ANIVA, L., FRONSDAL, K., KIRK, W., SOYLU, D., YU, A., LI, Y. and KOYEJO, S. (2025). Veribench: End-to-end formal verification benchmark for ai code generation in lean 4. In AI4Math@ICML25
work page 2025
-
[26]
SHINN, N., CASSANO, F., BERMAN, E., GOPINATH, A., NARASIMHAN, K. and YAO, S. (2023). Reflexion: Language agents with verbal reinforcement learning. InNeurIPS
work page 2023
-
[27]
SUN, C., SHENG, Y., PADON, O. and BARRETT, C. (2024). Clover: Closed-loop verifiable code generation. arXiv:2310.17807
-
[28]
THAKUR, A., LEE, J., TSOUKALAS, G., SISTLA, M., ZHAO, M., ZETZSCHE, S., DURRETT, G., YUE, Y. and CHAUDHURI, S. (2025). Clever: A curated benchmark for formally verified code generation.arXiv:2505.13938
-
[29]
VIDELA, A. (2018). Are functional programs easier to verify? URLhttps://semantic-domain.blogspot.com/2018/04/are-functional-programs-easier-to.html
work page 2018
-
[30]
WANG, R., ZHANG, J., JIA, Y., PAN, R., DIAO, S., PI, R. and ZHANG, T. (2024). Theoremllama: Transforming general-purpose llms into lean4 experts. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA
work page 2024
-
[31]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
WANG, X., WEI, J., SCHUURMANS, D., LE, Q. V., CHI, E. H., NARANG, S., CHOWDHERY, A. and ZHOU, D. (2022). Self-consistency improves chain of thought reasoning in language models.arXiv:2203.11171. 13 BRIDGE: Domain Guided Program VerificationA PREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
WEI, J., WANG, X., SCHUURMANS, D., BOSMA, M., ICHTER, B., XIA, F., CHI, E. H., LE, Q. V. and ZHOU, D. (2022). Chain-of-thought prompting elicits reasoning in large language models.arXiv:2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
WEN, C., CAO, J., SU, J., XU, Z., QIN, S., HE, M., LI, H., CHEUNG, S.-C. and TIAN, C. (2024). Enchanting program specification synthesis by large language models using static analysis and program verification.arXiv:2404.00762
-
[34]
XU, X., LI, X., QU, X., FU, J. and YUAN, B. (2025). Local success does not compose: Benchmarking large language models for compositional formal verification.arXiv:2509.23061
-
[35]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
YAO, S., YU, D., ZHAO, J., SHAFRAN, I., GRIFFITHS, T. L., CAO, Y. and NARASIMHAN, K. (2023). Tree of thoughts: Deliberate problem solving with large language models.arXiv:2305.10601
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
YAO, S., ZHAO, J., YU, D., SHAFRAN, I., NARASIMHAN, K. and CAO, Y. (2023). React: Synergizing reasoning and acting in language models. InICLR
work page 2023
-
[37]
arXiv preprint arXiv:2505.23135 , year =
YE, Z., YAN, Z., HE, J., KASRIEL, T., YANG, K. and SONG, D. (2025). Verina: Benchmarking verifiable code generation. arXiv:2505.23135. A Extended Analysis A.1 Literate Programming for Formal Verification Literate programming presents programs as readable mathematical exposition with embedded, executable code. In this section we ask whether large language ...
-
[38]
Preprocessing: Input validation and data preparation
-
[39]
Core Algorithm: Optimized computation with memoization
-
[40]
Post-processing: Result validation and verification Complexity: O(n) time, O(1) space for this implementation """ # Step 1: Preprocessing if not data: return 0 # Step 2: Core algorithm with optimization result = sum(x for x in data if isinstance(x, int) and x > 0) # Step 3: Post-processing validation return max(0, result) 22 BRIDGE: Domain Guided Program ...
-
[41]
**Lean Implementation**: Complete solution to the problem
-
[42]
**Formal Theorems**: Mathematical properties discovered via [SWAP:PATHWAY] # Output Format import Std import Mathlib def solution (input : InputType) : OutputType := -- Implementation guided by [SWAP:PATHWAY] analysis sorry -- [SWAP:THEOREM_TYPE] theorem [SWAP:THEOREM_NAME] (input : InputType) : [SWAP:THEOREM_STATEMENT] := by sorry B.3.1 Concrete Pathway ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.