Recognition: 1 theorem link
· Lean TheoremBeyond Membership: Limitations of Add/Remove Adjacency in Differential Privacy
Pith reviewed 2026-05-17 04:38 UTC · model grok-4.3
The pith
Differential privacy accounting under add/remove adjacency overstates protection for individual record attributes relative to substitute adjacency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that privacy accounting performed under the add/remove adjacency relation overstates attribute privacy compared with accounting performed under the substitute adjacency relation. The authors demonstrate the gap by constructing novel attacks that audit differential privacy mechanisms when adjacency is defined by record substitution, and they show that the resulting empirical privacy loss is inconsistent with add/remove guarantees yet consistent with the budget computed under substitute adjacency.
What carries the argument
The substitute adjacency relation, under which two datasets are adjacent if one is obtained from the other by replacing a single record.
If this is right
- When the protection target is per-record attributes rather than membership, differential privacy guarantees should be computed and reported under substitute adjacency.
- Empirical audits under substitute adjacency can reveal privacy leakage that add/remove accounting does not capture.
- The choice of adjacency relation directly affects whether stated privacy budgets are conservative for attribute protection.
- Existing DP libraries that default to add/remove may need to expose substitute accounting for applications that protect labels or other record attributes.
Where Pith is reading between the lines
- Implementations could expose an option to select adjacency based on the threat model before training begins.
- The same auditing technique might be applied to other DP variants such as those used in federated learning.
- Misalignment between reported and actual attribute privacy could affect regulatory compliance when models are deployed on sensitive data.
- Hybrid accounting methods that adapt the adjacency relation during training could reduce the gap without increasing computation.
Load-bearing premise
The novel attacks correctly quantify the actual privacy leakage under substitute adjacency without introducing artifacts that exaggerate the observed gap.
What would settle it
Train a model with a fixed privacy budget computed under substitute adjacency and measure whether the success rate of the authors' attribute-inference attack exceeds the rate predicted by the add/remove accounting for the same mechanism.
Figures



read the original abstract
Training machine learning models with differential privacy (DP) limits an adversary's ability to infer sensitive information about the training data. It can be interpreted as a bound on adversary's capability to distinguish two adjacent datasets according to chosen adjacency relation. In practice, most DP implementations use the add/remove adjacency relation, where two datasets are adjacent if one can be obtained from the other by adding or removing a single record, thereby protecting membership. In many ML applications, however, the goal is to protect attributes of individual records (e.g., labels used in supervised fine-tuning). We show that privacy accounting under add/remove overstates attribute privacy compared to accounting under the substitute adjacency relation, which permits substituting one record. To demonstrate this gap, we develop novel attacks to audit DP under substitute adjacency, and show empirically that audit results are inconsistent with DP guarantees reported under add/remove, yet remain consistent with the budget accounted under the substitute adjacency relation. Our results highlight that the choice of adjacency when reporting DP guarantees is critical when the protection target is per-record attributes rather than membership.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that differential privacy accounting based on the add/remove adjacency relation overstates protection for per-record attributes (e.g., labels) in ML training compared to the substitute adjacency relation. It supports this by developing novel attacks that audit DP mechanisms under substitute adjacency, showing empirically that attack success is inconsistent with add/remove-reported budgets yet consistent with substitute-accounted budgets.
Significance. If the attacks correctly quantify leakage under the substitute relation without artifacts, the result would be significant for DP practice in machine learning: it would show that common add/remove accounting can give misleadingly strong guarantees when the goal is attribute rather than membership privacy. The work supplies concrete attacks and consistency checks that could guide more accurate reporting of DP guarantees in applications such as supervised fine-tuning.
major comments (2)
- [§4.2] §4.2 (Substitute-adjacency attack construction): the claim that the developed attacks are 'consistent with the budget accounted under the substitute adjacency relation' is load-bearing for the central comparison, yet the section provides no tightness argument, comparison to an optimal adversary, or formal bound showing that the observed success probability saturates the substitute DP guarantee. Without this, the reported gap could be an artifact of sub-optimal attack design rather than evidence that add/remove overstates attribute privacy.
- [§5.1, Table 2] §5.1 and Table 2 (empirical results): the inconsistency between attack success and add/remove epsilon is presented as the key evidence, but the experiments do not report whether the substitute attacks were run under identical dataset-size and query-adaptation assumptions as the add/remove baseline; differing implicit assumptions would undermine the direct comparison of the two accounting methods.
minor comments (2)
- [§2] Notation for the two adjacency relations is introduced in §2 but reused without reminder in later sections; a brief recap table would improve readability.
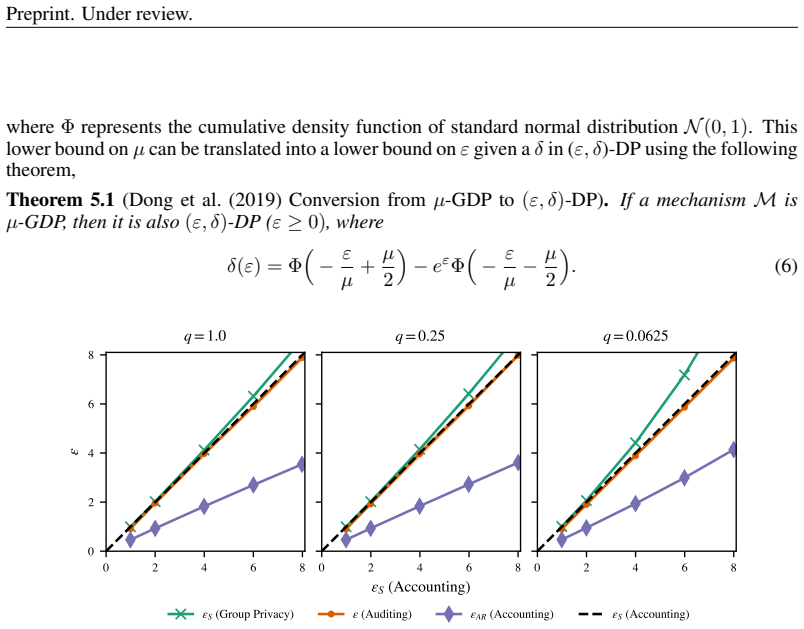
- [Figure 3] Figure 3 caption does not state the number of independent runs or confidence intervals shown in the plotted attack success rates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the attack construction and experimental reporting that we address point by point below. We have revised the manuscript to improve clarity and documentation while maintaining the core claims.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Substitute-adjacency attack construction): the claim that the developed attacks are 'consistent with the budget accounted under the substitute adjacency relation' is load-bearing for the central comparison, yet the section provides no tightness argument, comparison to an optimal adversary, or formal bound showing that the observed success probability saturates the substitute DP guarantee. Without this, the reported gap could be an artifact of sub-optimal attack design rather than evidence that add/remove overstates attribute privacy.
Authors: We agree that a formal tightness proof or direct comparison to an optimal adversary would provide stronger support. Our attack is constructed specifically around the substitute adjacency definition, enabling the adversary to query on datasets that differ by a single record substitution. Empirically, the observed success rates align with the success probability implied by the substitute DP guarantee (e.g., approaching 1 - e^{-ε} in the binary attribute inference setting), while exceeding the rates consistent with add/remove accounting. We have added a discussion paragraph in §4.2 explaining the attack rationale and its expected near-optimality for the substitute relation, along with an explicit acknowledgment that a general formal saturation bound is left for future work. This revision addresses the concern that the gap might stem solely from attack sub-optimality. revision: partial
-
Referee: [§5.1, Table 2] §5.1 and Table 2 (empirical results): the inconsistency between attack success and add/remove epsilon is presented as the key evidence, but the experiments do not report whether the substitute attacks were run under identical dataset-size and query-adaptation assumptions as the add/remove baseline; differing implicit assumptions would undermine the direct comparison of the two accounting methods.
Authors: The substitute-adjacency attacks were executed under precisely the same dataset sizes, query adaptation procedures, and other experimental parameters as the add/remove baselines to support a direct comparison. We have revised the text in §5.1 and the caption of Table 2 to explicitly document these identical assumptions and settings. revision: yes
Circularity Check
No circularity: empirical attacks provide independent evidence against add/remove accounting
full rationale
The paper's core argument rests on developing novel attacks to audit DP under the substitute adjacency relation and showing empirical inconsistency with add/remove guarantees while consistency with substitute accounting. No equation or claim reduces by construction to a fitted input, self-citation chain, or definitional equivalence. The attacks are presented as external validation against standard DP definitions rather than a renaming or ansatz smuggled from prior self-work. The derivation chain is self-contained and falsifiable via the reported audit results.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions of differential privacy under add/remove and substitute adjacency relations.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that privacy accounting under add/remove overstates attribute privacy compared to accounting under the substitute adjacency relation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
10 Preprint. Under review. R. Bassily, A. D. Smith, and A. Thakurta. Private Empirical Risk Minimization: Efficient Algo- rithms and Tight Error Bounds. In55th IEEE Annual Symposium on Foundations of Computer Science, FOCS 2014, pages 464–473,
work page 2014
- [4]
-
[5]
T. I. Cebere, A. Bellet, and N. Papernot. Tighter Privacy Auditing of DP-SGD in the Hidden State Threat Model. InThe Thirteenth International Conference on Learning Representations, ICLR 2025,
work page 2025
- [6]
-
[7]
J. Dong, A. Roth, and W. J. Su. Gaussian Differential Privacy.CoRR, abs/1905.02383,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[8]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In9th International Conference on Learn- ing Representations, ICLR 2021,
work page 2021
-
[9]
Concentrated Differential Privacy
C. Dwork and G. N. Rothblum. Concentrated Differential Privacy.CoRR, abs/1603.01887,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
- [11]
-
[12]
S. Gopi, Y . T. Lee, and L. Wutschitz. Numerical Composition of Differential Privacy. InAdvances in Neural Information Processing Systems 34: Annual Conference on Neural Information Pro- cessing Systems 2021, NeurIPS 2021, pages 11631–11642,
work page 2021
-
[13]
P. Kairouz, S. Oh, and P. Viswanath. The Composition Theorem for Differential Privacy. InPro- ceedings of the 32nd International Conference on Machine Learning, ICML 2015, volume 37 of JMLR Workshop and Conference Proceedings, pages 1376–1385,
work page 2015
-
[14]
P. Kairouz, B. McMahan, S. Song, O. Thakkar, A. Thakurta, and Z. Xu. Practical and Private (Deep) Learning Without Sampling or Shuffling. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, volume 139 ofProceedings of Machine Learning Research, pages 5213–5225,
work page 2021
-
[15]
D. P. Kingma and J. Ba. Adam: A Method for Stochastic Optimization. In3rd International Conference on Learning Representations, ICLR 2015, Conference Track Proceedings,
work page 2015
-
[16]
A. Koskela, J. J¨alk¨o, and A. Honkela. Computing Tight Differential Privacy Guarantees Using FFT. InThe 23rd International Conference on Artificial Intelligence and Statistics, AISTATS 2020, volume 108 ofProceedings of Machine Learning Research, pages 2560–2569,
work page 2020
-
[17]
A. Kulesza, A. T. Suresh, and Y . Wang. Mean Estimation in the Add-Remove Model of Differential Privacy. InForty-first International Conference on Machine Learning, ICML 2024,
work page 2024
-
[18]
11 Preprint. Under review. H. Mehta, A. G. Thakurta, A. Kurakin, and A. Cutkosky. Towards Large Scale Transfer Learning for Differentially Private Image Classification.Trans. Mach. Learn. Res., 2023,
work page 2023
-
[19]
S. Meiser and E. Mohammadi. Tight on Budget?: Tight Bounds for r-Fold Approximate Differential Privacy. InProceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS 2018, pages 247–264,
work page 2018
-
[20]
I. Mironov. R ´enyi differential privacy. In30th IEEE Computer Security Foundations Symposium, CSF 2017, pages 263–275,
work page 2017
-
[21]
M. Nasr, S. Song, A. Thakurta, N. Papernot, and N. Carlini. Adversary Instantiation: Lower Bounds for Differentially Private Machine Learning. In42nd IEEE Symposium on Security and Privacy, SP 2021, pages 866–882,
work page 2021
-
[22]
M. Nasr, J. Hayes, T. Steinke, B. Balle, F. Tram `er, M. Jagielski, N. Carlini, and A. Terzis. Tight Auditing of Differentially Private Machine Learning. In32nd USENIX Security Symposium, USENIX Security 2023, pages 1631–1648,
work page 2023
-
[23]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. K¨opf, E. Z. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala. PyTorch: An imperative style, high-performance deep learning library. InAdvances in Neural Information Processing ...
work page 2019
-
[24]
A. Rajkumar and S. Agarwal. A Differentially Private Stochastic Gradient Descent Algorithm for Multiparty Classification. InProceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2012, volume 22 ofJMLR Proceedings, pages 933–941,
work page 2012
-
[25]
N. Reimers and I. Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, pages 3980–3990. Association for Computational Linguistics,
work page 2019
- [26]
- [27]
-
[28]
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Con- ference on Empirical Methods in Natural Language Processing, pages 1631–1642. Association for Computational Linguistics,
work page 2013
-
[29]
S. Song, K. Chaudhuri, and A. D. Sarwate. Stochastic gradient descent with differentially private updates. InIEEE Global Conference on Signal and Information Processing, GlobalSIP 2013, pages 245–248,
work page 2013
-
[30]
T. Steinke, M. Nasr, and M. Jagielski. Privacy Auditing with One (1) Training Run. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Process- ing Systems 2023, NeurIPS 2023,
work page 2023
-
[31]
F. Tram`er and D. Boneh. Differentially Private Learning Needs Better Features (or Much More Data). In9th International Conference on Learning Representations, ICLR 2021,
work page 2021
-
[32]
12 Preprint. Under review. A. Yousefpour, I. Shilov, A. Sablayrolles, D. Testuggine, K. Prasad, M. Malek, J. Nguyen, S. Ghosh, A. Bharadwaj, J. Zhao, G. Cormode, and I. Mironov. Opacus: User-Friendly Differential Privacy Library in PyTorch.CoRR, abs/2109.12298,
-
[33]
to facilitate DP training of models with Pytorch (Paszke et al., 2019).In our experiments, we vary the seed per run, which ensures randomness in mini-batch sampling and, in the case of models trained from scratch, also ensures random initialization per run. We find that adding a canary to the gradients or datasets does not compromise the utility of the tr...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.