BINDER: Instantly Adaptive Mobile Manipulation with Open-Vocabulary Commands
Pith reviewed 2026-05-17 04:56 UTC · model grok-4.3
The pith
BINDER coordinates a planning LLM with a video-monitoring module to let robots adapt instantly to dynamic changes during open-vocabulary tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
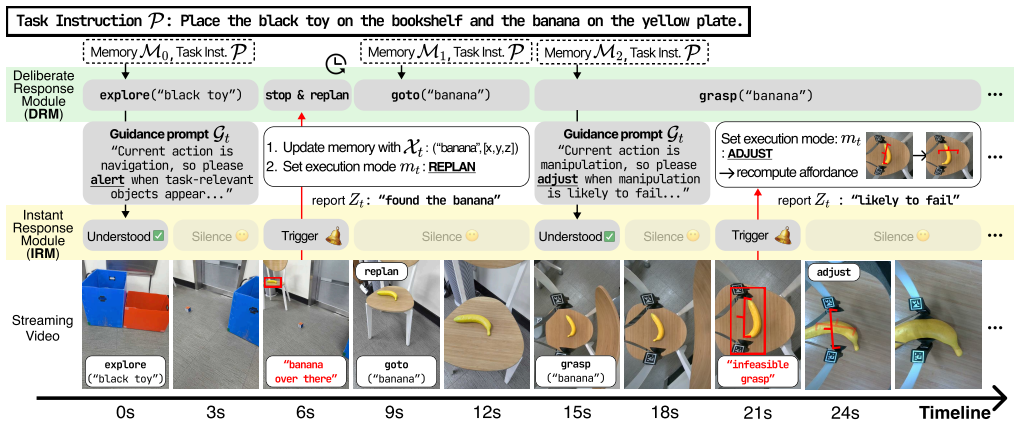
BINDER decouples strategic planning from continuous environment monitoring by combining a multimodal LLM for task planning with a VideoLLM for video analysis, using bidirectional coordination so the planner guides what to watch and the monitor updates memory, fixes ongoing actions, and triggers replanning when needed.
What carries the argument
Bidirectional coordination between the Deliberative Response Module for structured 3D scene planning and the Instant Response Module for continuous video-stream monitoring.
If this is right
- Robots catch and fix errors such as overlooked objects or changed positions without waiting until the end of a planned step.
- Fewer cascading failures occur because late detection is replaced by immediate correction from the monitoring module.
- Overall task completion rates and total time improve in settings where objects are placed or moved dynamically.
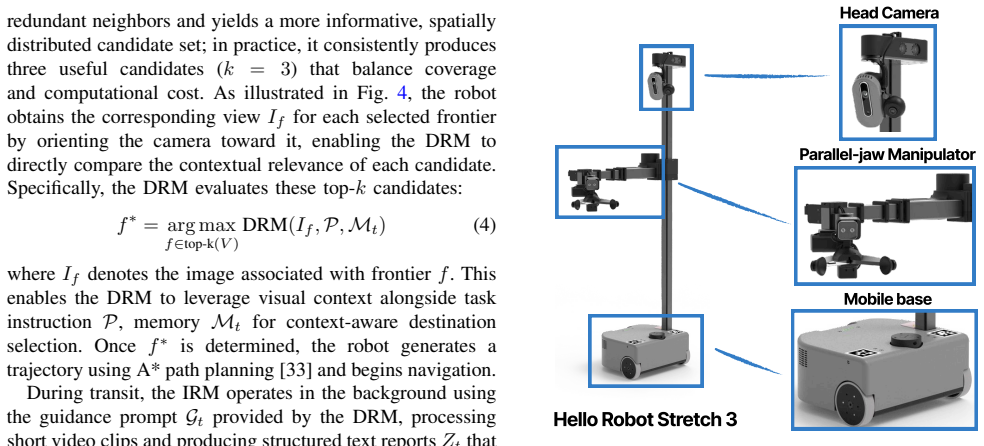
- The planner can direct the monitor's focus, avoiding the cost of full scene re-analysis at every moment.
Where Pith is reading between the lines
- The same split between slow strategic reasoning and fast perceptual monitoring could transfer to other domains that need both long-horizon plans and rapid reaction, such as warehouse logistics or search-and-rescue.
- Replacing the VideoLLM with lighter or distilled models would test whether the performance edge holds under tighter compute budgets.
Load-bearing premise
The two modules can exchange information fast enough in real time without adding latency or new failure modes that cancel out the adaptation gains.
What would settle it
Run a trial where an object is moved into the robot's workspace midway through an ongoing grasp or navigation step and check whether BINDER notices and corrects faster than a baseline that waits for the next waypoint update.
Figures





read the original abstract
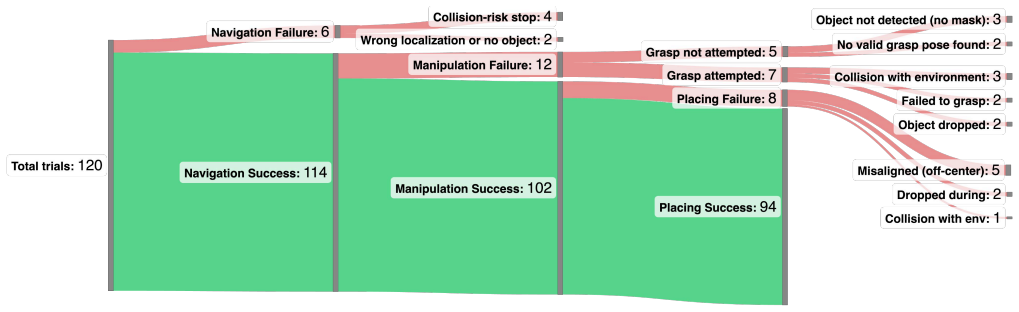
Open-vocabulary mobile manipulation (OVMM) requires robots to follow language instructions, navigate, and manipulate while updating their world representation under dynamic environmental changes. However, most prior approaches update their world representation only at discrete update points such as navigation targets, waypoints, or the end of an action step, leaving robots blind between updates and causing cascading failures: overlooked objects, late error detection, and delayed replanning. To address this limitation, we propose BINDER (Bridging INstant and DEliberative Reasoning), a dual process framework that decouples strategic planning from continuous environment monitoring. Specifically, BINDER integrates a Deliberative Response Module (DRM, a multimodal LLM for task planning) with an Instant Response Module (IRM, a VideoLLM for continuous monitoring). The two modules play complementary roles: the DRM performs strategic planning with structured 3D scene updates and guides what the IRM attends to, while the IRM analyzes video streams to update memory, correct ongoing actions, and trigger replanning when necessary. Through this bidirectional coordination, the modules address the trade off between maintaining awareness and avoiding costly updates, enabling robust adaptation under dynamic conditions. Evaluated in three real world environments with dynamic object placement, BINDER achieves substantially higher success and efficiency than SoTA baselines, demonstrating its effectiveness for real world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BINDER, a dual-process framework for open-vocabulary mobile manipulation (OVMM) that decouples strategic planning from continuous monitoring. It integrates a Deliberative Response Module (DRM, multimodal LLM for 3D scene planning) with an Instant Response Module (IRM, VideoLLM for video-stream analysis). The DRM guides attention and performs structured updates while the IRM updates memory, corrects actions, and triggers replanning via bidirectional coordination. The central claim is that this design overcomes limitations of discrete-update methods (overlooked objects, late detection) and yields substantially higher success and efficiency than SoTA baselines in three real-world environments with dynamic object placement.
Significance. If the performance claims are substantiated with quantitative data, the work could meaningfully advance real-world OVMM by showing how complementary LLM-based modules can maintain awareness without incurring prohibitive update costs. The architectural separation of deliberative and instant reasoning is a practical response to the trade-off between planning depth and responsiveness, and successful validation would provide a template for hybrid systems in dynamic robotics settings.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the claim that BINDER 'achieves substantially higher success and efficiency than SoTA baselines' is presented without any numerical success rates, efficiency metrics, error bars, or tabulated comparisons, which is load-bearing for the central empirical assertion and prevents verification of the magnitude of improvement.
- [Method / Framework Description] Bidirectional coordination mechanism: the description of information exchange between DRM and IRM (memory updates, attention guidance, replanning triggers) provides no protocol details, latency measurements, or ablation isolating coordination overhead, leaving open the risk that VideoLLM inference or synchronization delays could offset claimed efficiency gains on object-motion timescales.
minor comments (2)
- [Method] The abstract and method sections would benefit from an explicit diagram or pseudocode showing the exact data flow and triggering conditions between the two modules.
- [Introduction / Method] Terminology such as 'structured 3D scene updates' and 'continuous monitoring' could be defined more precisely with respect to the input/output interfaces of the underlying LLMs.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. We address each major comment point by point below, indicating the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the claim that BINDER 'achieves substantially higher success and efficiency than SoTA baselines' is presented without any numerical success rates, efficiency metrics, error bars, or tabulated comparisons, which is load-bearing for the central empirical assertion and prevents verification of the magnitude of improvement.
Authors: We agree that the abstract would benefit from concrete numerical support for the performance claims. In the revised version, we will incorporate key quantitative results from our experiments, including success rates with error bars and efficiency metrics such as task completion time, along with direct comparisons to the SoTA baselines. This will make the magnitude of improvement verifiable directly from the abstract while preserving its conciseness. revision: yes
-
Referee: [Method / Framework Description] Bidirectional coordination mechanism: the description of information exchange between DRM and IRM (memory updates, attention guidance, replanning triggers) provides no protocol details, latency measurements, or ablation isolating coordination overhead, leaving open the risk that VideoLLM inference or synchronization delays could offset claimed efficiency gains on object-motion timescales.
Authors: The current manuscript details the coordination protocol in Section 3, including how the DRM supplies structured 3D scene guidance to focus the IRM's video analysis and how the IRM returns memory updates and replanning triggers. We acknowledge that explicit latency benchmarks and an ablation isolating coordination overhead are not present. We will add these elements in the revision, reporting measured latencies for DRM-IRM exchanges and an ablation study to demonstrate that synchronization costs do not negate the efficiency advantages on relevant timescales. revision: yes
Circularity Check
No circularity: architectural framework with empirical evaluation
full rationale
The paper introduces BINDER as a dual-process architectural proposal (DRM for strategic planning and IRM for continuous VideoLLM monitoring with bidirectional coordination) rather than a mathematical derivation. No equations, fitted parameters, or self-referential reductions appear in the provided abstract or description. Claims rest on real-world experiments in three environments with dynamic objects, not on any step that reduces by construction to prior inputs, self-citations, or ansatzes. This is a standard system-design paper whose central content is independent of the circularity patterns listed.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Deliberative Response Module (DRM)
no independent evidence
-
Instant Response Module (IRM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BINDER integrates a Deliberative Response Module (DRM, a multimodal LLM for task planning) with an Instant Response Module (IRM, a VideoLLM for continuous monitoring).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Homerobot: Open-vocabulary mobile manipulation,
S. Yenamandra, A. Ramachandran, K. Yadav, A. S. Wang, M. Khanna, T. Gervet, T.-Y . Yang, V . Jain, A. Clegg, J. M. Turner, Z. Kira, M. Savva, A. X. Chang, D. S. Chaplot, D. Batra, R. Mottaghi, Y . Bisk, and C. Paxton, “Homerobot: Open-vocabulary mobile manipulation,” inCoRL, 2023
work page 2023
-
[2]
Ok- robot: What really matters in integrating open-knowledge models for robotics,
P. Liu, Y . Orru, C. Paxton, N. M. M. Shafiullah, and L. Pinto, “Ok- robot: What really matters in integrating open-knowledge models for robotics,” inRSS, 2024
work page 2024
-
[3]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inICRA Workshop, 2024
work page 2024
-
[4]
Clip-fields: Weakly supervised semantic fields for robotic memory,
N. M. M. Shafiullah, C. Paxton, L. Pinto, S. Chintala, and A. Szlam, “Clip-fields: Weakly supervised semantic fields for robotic memory,” arXiv, 2022
work page 2022
-
[5]
Dynamem: Online dynamic spatio-semantic memory for open world mobile manipulation,
P. Liu, Z. Guo, M. Warke, S. Chintala, C. Paxton, N. M. M. Shafiullah, and L. Pinto, “Dynamem: Online dynamic spatio-semantic memory for open world mobile manipulation,” inICRA, 2025
work page 2025
-
[6]
Dynamic open-vocabulary 3d scene graphs for long-term language- guided mobile manipulation,
Z. Yan, S. Li, Z. Wang, L. Wu, H. Wang, J. Zhu, L. Chen, and J. Liu, “Dynamic open-vocabulary 3d scene graphs for long-term language- guided mobile manipulation,”RA-L, vol. 10, no. 5, pp. 4252–4259, 2025
work page 2025
-
[7]
More: Mobile manipulation rearrangement through grounded language rea- soning,
M. Mohammadi, D. Honerkamp, M. B ¨uchner, M. Cassinelli, T. Welschehold, F. Despinoy, I. Gilitschenski, and A. Valada, “More: Mobile manipulation rearrangement through grounded language rea- soning,”arXiv, 2025
work page 2025
-
[8]
Closed-loop open-vocabulary mobile manipulation with gpt-4v,
P. Zhi, Z. Zhang, Y . Zhao, M. Han, Z. Zhang, Z. Li, Z. Jiao, B. Jia, and S. Huang, “Closed-loop open-vocabulary mobile manipulation with gpt-4v,”arXiv, 2024
work page 2024
-
[9]
R. Shah, A. Yu, Y . Zhu, Y . Zhu, and R. Mart´ın-Mart´ın, “Bumble: Uni- fying reasoning and acting with vision-language models for building- wide mobile manipulation,” inICRA, 2025
work page 2025
-
[10]
Open-vocabulary mo- bile manipulation in unseen dynamic environments with 3d semantic maps,
D. Qiu, W. Ma, Z. Pan, H. Xiong, and J. Liang, “Open-vocabulary mo- bile manipulation in unseen dynamic environments with 3d semantic maps,”arXiv, 2024
work page 2024
-
[11]
Language-grounded dynamic scene graphs for interactive object search with mobile manipulation,
D. Honerkamp, M. B ¨uchner, F. Despinoy, T. Welschehold, and A. Val- ada, “Language-grounded dynamic scene graphs for interactive object search with mobile manipulation,”RA-L, 2024
work page 2024
-
[12]
Kinect- fusion: Real-time dense surface mapping and tracking,
R. A. Newcombe, S. Izadi, O. Hilliges, D. Molyneaux, D. Kim, A. J. Davison, P. Kohi, J. Shotton, S. Hodges, and A. Fitzgibbon, “Kinect- fusion: Real-time dense surface mapping and tracking,”ISMAR, pp. 127–136, 2011
work page 2011
-
[13]
How nerfs and 3d gaussian splatting are reshaping slam: a survey,
F. Tosi, Y . Zhang, Z. Gong, E. Sandstr¨om, S. Mattoccia, M. R. Oswald, and M. Poggi, “How nerfs and 3d gaussian splatting are reshaping slam: a survey,”arXiv, 2024
work page 2024
-
[14]
Anticipating human activities using object affordances for reactive robotic response,
H. S. Koppula and A. Saxena, “Anticipating human activities using object affordances for reactive robotic response,”TPAMI, vol. 38, no. 1, pp. 14–29, 2016
work page 2016
-
[15]
P. C. Wason and J. S. B. T. Evans, “Dual processes in reasoning?” Cognition, vol. 3, no. 2, pp. 141–154, 1974
work page 1974
-
[16]
Kahneman,Thinking, Fast and Slow
D. Kahneman,Thinking, Fast and Slow. New York: Farrar, Straus and Giroux, 2011
work page 2011
-
[17]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,”arXiv, 2025
work page 2025
-
[18]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid,et al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL, 2023
work page 2023
-
[19]
Openvla: An open-source vision-language-action model,
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” inCoRL, 2024
work page 2024
-
[20]
π 0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,”arXiv, 2024
work page 2024
-
[21]
Hi robot: Open-ended instruction following with hierarchical vision-language-action models,
L. X. Shi, B. Ichter, M. Equi, L. Ke, K. Pertsch, Q. Vuong, J. Tanner, A. Walling, H. Wang, N. Fusai, A. Li-Bell, D. Driess, L. Groom, S. Levine, and C. Finn, “Hi robot: Open-ended instruction following with hierarchical vision-language-action models,” inICML, 2025
work page 2025
-
[22]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,”arXiv, 2022
work page 2022
-
[23]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,”arXiv, 2022
work page 2022
-
[24]
Open-vocabulary queryable scene representations for real world planning,
B. Chen, F. Xia, B. Ichter, K. Rao, K. Gopalakrishnan, M. S. Ryoo, A. Stone, and D. Kappler, “Open-vocabulary queryable scene representations for real world planning,”arXiv, 2022
work page 2022
-
[25]
Planning reactive manipulation in dynamic environments,
P. Schmitt, B. B ¨auml, J. Mages, and D. Lee, “Planning reactive manipulation in dynamic environments,” inIROS, 2019
work page 2019
-
[26]
X. Sui, D. Tian, Q. Sun, R. Chen, D. Choi, K. Kwok, and S. Poria, “From grounding to manipulation: Case studies of foundation model integration in embodied robotic systems,” inFindings of the Association for Computational Linguistics: EMNLP 2025. Suzhou, China: Association for Computational Linguistics, Nov. 2025. [Online]. Available: https://aclanthology...
work page 2025
-
[27]
Racer: Rich language-guided failure recovery policies for imitation learning,
Y . Dai, J. Lee, N. Fazeli, and J. Chai, “Racer: Rich language-guided failure recovery policies for imitation learning,” inICRA, 2025
work page 2025
-
[28]
Language-driven closed-loop grasping with model-predictive trajectory optimization,
H.-H. Nguyen, M. N. Vu, F. Beck, G. Ebmer, A. Nguyen, W. Kem- metm¨uller, and A. Kugi, “Language-driven closed-loop grasping with model-predictive trajectory optimization,”Mechatronics, vol. 109, p. 103335, 2025
work page 2025
-
[29]
E. Zhou, Q. Su, C. Chi, Z. Zhang, Z. Wang, T. Huang, L. Sheng, and H. Wang, “Code-as-monitor: Constraint-aware visual programming for reactive and proactive robotic failure detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 6919–6929
work page 2025
-
[30]
Closed-loop visuomotor control with generative expectation for robotic manipulation,
Q. Bu, J. Zeng, L. Chen, Y . Yang, G. Zhou, J. Yan, P. Luo, H. Cui, Y . Ma, and H. Li, “Closed-loop visuomotor control with generative expectation for robotic manipulation,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2024
work page 2024
-
[31]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa,et al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” inICRA, 2024
work page 2024
-
[32]
Open-vocabulary functional 3d scene graphs for real- world indoor spaces,
C. Zhang, A. Delitzas, F. Wang, R. Zhang, X. Ji, M. Pollefeys, and F. Engelmann, “Open-vocabulary functional 3d scene graphs for real- world indoor spaces,” inCVPR, 2025
work page 2025
-
[33]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, July 1968
work page 1968
-
[34]
Mpnet: Masked and permuted pre-training for language understanding,
K. Song, X. Tan, T. Qin, J. Lu, and T.-Y . Liu, “Mpnet: Masked and permuted pre-training for language understanding,” inNeurIPS, 2020
work page 2020
-
[35]
Simple open-vocabulary object detection,
M. Minderer, A. Gritsenko, A. Stone, M. Neumann, D. Weissenborn, A. Dosovitskiy, A. Mahendran, A. Arnab, M. Dehghani, Z. Shen,et al., “Simple open-vocabulary object detection,” inECCV, 2022
work page 2022
-
[36]
Back-tracing representative points for voting-based 3d object detection in point clouds,
B. Cheng, L. Sheng, S. Shi, M. Yang, and D. Xu, “Back-tracing representative points for voting-based 3d object detection in point clouds,” inCVPR, 2021
work page 2021
-
[37]
Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,
H.-S. Fang, C. Wang, H. Fang, M. Gou, J. Liu, H. Yan, W. Liu, Y . Xie, and C. Lu, “Anygrasp: Robust and efficient grasp perception in spatial and temporal domains,”T-RO, 2023
work page 2023
-
[38]
Lang-segment-anything: Sam with text prompt,
L. Medeiros, “Lang-segment-anything: Sam with text prompt,” https: //github.com/luca-medeiros/lang-segment-anything, 2023
work page 2023
-
[39]
Stretch se3 mobile manipulator robot,
Hello Robot Inc., “Stretch se3 mobile manipulator robot,” https: //hello-robot.com/product, 2023, accessed: 2024-01-01
work page 2023
-
[40]
OpenAI, “Gpt-5 system card,” OpenAI,” Technical Report, Aug. 2025, accessed: 2025-08-10. [Online]. Available: https://openai.com
work page 2025
-
[41]
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks,
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks,” inCVPR, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.