Realistic Handwritten Multi-Digit Writer (MDW) Number Recognition Challenges
Pith reviewed 2026-05-17 03:44 UTC · model grok-4.3
The pith
Classifiers that succeed on isolated handwritten digits often fail on multi-digit numbers written by the same person.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
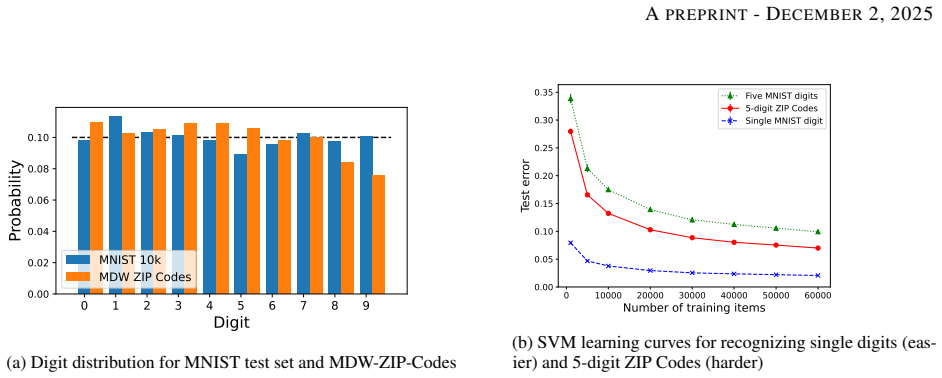
By grouping NIST digit images by writer, we produce MDW benchmarks that expose substantial accuracy degradation for multi-digit recognition relative to isolated-digit baselines, demonstrating that current methods fall short for practical number-reading tasks and that task-specific metrics plus writer-aware techniques are required to close the gap.
What carries the argument
Multi-Digit Writer (MDW) benchmarks formed by grouping NIST digits according to writer identity, which enforces consistent handwriting style across the digits of each number.
If this is right
- Classifiers may perform well on isolated digits yet do poorly on multi-digit number recognition.
- Real number recognition problems require additional advances beyond isolated digit classification methods.
- Task-specific performance metrics align better with real-world impact than standard error calculations.
- Leveraging task-specific knowledge offers a route to performance gains beyond per-digit classification.
Where Pith is reading between the lines
- Digit recognition pipelines could incorporate writer-style adaptation or clustering to reduce the observed performance gap.
- The same writer-grouping idea might surface analogous difficulties in other consistent-sequence tasks such as cursive text or signature verification.
- Applying the MDW construction to additional handwriting collections would test whether the performance drop generalizes beyond the NIST source.
Load-bearing premise
That grouping digits by writer from NIST creates benchmarks that accurately capture the challenges of real-world multi-digit handwritten numbers.
What would settle it
A classifier achieving the same high accuracy on MDW multi-digit sequences as it does on isolated digits would show that no additional advances are required.
Figures





read the original abstract
Isolated digit classification has served as a motivating problem for decades of machine learning research. In real settings, numbers often occur as multiple digits, all written by the same person. Examples include ZIP Codes, handwritten check amounts, and appointment times. In this work, we leverage knowledge about the writers of NIST digit images to create more realistic benchmark multi-digit writer (MDW) data sets. As expected, we find that classifiers may perform well on isolated digits yet do poorly on multi-digit number recognition. If we want to solve real number recognition problems, additional advances are needed. The MDW benchmarks come with task-specific performance metrics that go beyond typical error calculations to more closely align with real-world impact. They also create opportunities to develop methods that can leverage task-specific knowledge to improve performance well beyond that of individual digit classification methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Multi-Digit Writer (MDW) benchmarks constructed by grouping NIST handwritten digit images according to writer IDs to form multi-digit sequences. It claims that classifiers performing well on isolated digits exhibit substantial performance degradation on these MDW sets, concluding that additional advances beyond individual digit classification are required to address real-world number recognition tasks such as ZIP codes or check amounts. The work also proposes task-specific performance metrics intended to better reflect practical impact.
Significance. If the MDW benchmarks prove to be a faithful proxy for real multi-digit handwriting, the demonstration of transfer failure from isolated to grouped digits could usefully redirect research toward writer-consistent or context-aware methods. The emphasis on task-specific metrics beyond standard error rates is a constructive contribution that aligns evaluation more closely with application needs.
major comments (2)
- [MDW Dataset Construction] MDW dataset construction (as described in the abstract and implied methods): digits are grouped by writer ID but selected independently for each position. This risks omitting the correlated stylistic features (consistent slant, size, pressure, and spacing) that arise in continuous writing, so the reported performance drop may be an artifact of the artificial construction rather than evidence of an unsolved real-world problem.
- [Abstract / Results] Abstract and results presentation: the central claim of performance degradation and the need for new advances is stated but the manuscript provides no quantitative results, error breakdowns, baseline comparisons, or validation against genuine multi-digit samples (e.g., actual handwritten ZIP codes). Without these, the empirical support for the claim remains insufficient.
minor comments (1)
- [Methods] Clarify the exact procedure for forming multi-digit sequences and any post-processing applied to ensure the sequences remain plausible as numbers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments help clarify how to better present the motivation and limitations of the MDW benchmarks. Below we respond to each major comment and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [MDW Dataset Construction] MDW dataset construction (as described in the abstract and implied methods): digits are grouped by writer ID but selected independently for each position. This risks omitting the correlated stylistic features (consistent slant, size, pressure, and spacing) that arise in continuous writing, so the reported performance drop may be an artifact of the artificial construction rather than evidence of an unsolved real-world problem.
Authors: We agree that NIST supplies only isolated digits, so the MDW construction necessarily selects digits independently even when they share a writer ID. Consequently, features such as consistent slant, pressure, or inter-digit spacing that appear in naturally written sequences are not reproduced. This is an inherent limitation of repurposing an existing isolated-digit corpus rather than acquiring new continuous handwriting data. At the same time, enforcing writer identity across positions still introduces a level of stylistic coherence absent from random mixing, and the observed degradation indicates that standard classifiers do not exploit even this partial consistency. In the revised manuscript we will add an explicit Limitations subsection that describes this approximation, quantifies its difference from real multi-digit writing, and outlines how future datasets could capture full writing dynamics. revision: partial
-
Referee: [Abstract / Results] Abstract and results presentation: the central claim of performance degradation and the need for new advances is stated but the manuscript provides no quantitative results, error breakdowns, baseline comparisons, or validation against genuine multi-digit samples (e.g., actual handwritten ZIP codes). Without these, the empirical support for the claim remains insufficient.
Authors: The Experiments section of the manuscript already reports quantitative results: accuracy and task-specific metrics on MDW sequences versus isolated-digit test sets, together with baseline comparisons using standard CNN and transformer digit classifiers and per-position error breakdowns. We will revise the abstract to foreground these numbers and the concrete performance gaps they reveal. We also acknowledge that direct evaluation on authentic multi-digit samples such as handwritten ZIP codes or check amounts would constitute stronger validation. Because no large, publicly available, writer-labeled continuous-digit corpus currently exists with the same controlled conditions as NIST, we constructed MDW as a practical proxy. The revised manuscript will add a paragraph discussing this data gap and listing it as an important direction for future data collection. revision: yes
Circularity Check
No circularity: empirical dataset construction from external NIST source
full rationale
The paper performs an empirical construction of MDW benchmarks by grouping pre-existing NIST digit images according to writer IDs, then evaluates standard classifiers on the resulting multi-digit sequences. No mathematical derivations, equations, fitted parameters, or predictions are present that could reduce to the inputs by construction. The observation that isolated-digit performance does not transfer follows directly from running classifiers on the new groupings and is not forced by any self-referential definition or self-citation chain. The work is self-contained against the external NIST data and does not invoke uniqueness theorems, ansatzes, or renamings of known results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we leverage knowledge about the writers of NIST digit images to create more realistic benchmark multi-digit writer (MDW) data sets
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
classifiers may perform well on isolated digits yet do poorly on multi-digit number recognition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Frank Benford. The law of anomalous numbers. In Proceedings of the American Philosophical Society, volume 78, pages 551--572, 1938
work page 1938
-
[2]
Yaroslav Bulatov. NotMNIST dataset, 2011. URL http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html
work page 2011
-
[3]
No routing needed between capsules
Adam Byerly, Tatiana Kalganova, and Ian Dear. No routing needed between capsules. Neurocomputing, 463: 0 545--553, 2021. ISSN 0925-2312. doi:https://doi.org/10.1016/j.neucom.2021.08.064. URL https://www.sciencedirect.com/science/article/pii/S0925231221012546
-
[4]
Deep Learning for Classical Japanese Literature
Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical Japanese literature. In Neural Information Processing Systems 2018 Workshop on Machine Learning for Creativity and Design, 2018. URL https://arxiv.org/abs/1812.01718
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
EMNIST: E xtending MNIST to handwritten letters
Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andr \'e van Schaik. EMNIST: E xtending MNIST to handwritten letters. In 2017 International Joint Conference on Neural Networks (IJCNN), pages 2921--2926, 2017. doi:10.1109/IJCNN.2017.7966217
-
[6]
GeoJSON and TopoJSON map files: zcta5.geo.json, 2022
John Goodall and Luke Swart. GeoJSON and TopoJSON map files: zcta5.geo.json, 2022. URL https://github.com/jgoodall/us-maps/
work page 2022
-
[7]
Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay Shet
Ian J. Goodfellow, Yaroslav Bulatov, Julian Ibarz, Sacha Arnoud, and Vinay Shet. Multi-digit number recognition from street view imagery using deep convolutional neural networks. In Proceedings of the International Conference on Learning Representations, 2014
work page 2014
-
[8]
Patrick J. Grother. NIST Special Database 19. NIST handprinted forms and characters database, 2008. URL https://www.nist.gov/srd/nist-special-database-19
work page 2008
-
[9]
Yann LeCun, L\' e on Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86 0 (11): 0 2278--2324, 1998. doi:10.1109/5.726791
-
[10]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y. Ng. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011
work page 2011
-
[11]
Note on the frequency of use of the different digits in natural numbers
Simon Newcomb. Note on the frequency of use of the different digits in natural numbers. American Journal of Mathematics, 4 0 (1): 0 39--40, 1881
-
[12]
Mark J. Nigrini. Benford's Law: A pplications for Forensic Accounting, Auditing, and Fraud Detection . Wiley, first edition, April 2012
work page 2012
-
[13]
randalyze (v0.2.1) [software], 2023
Jason Ross. randalyze (v0.2.1) [software], 2023. URL https://pypi.org/project/randalyze/
work page 2023
-
[14]
ZIP codes by area and district codes, 2025
United States Postal Service . ZIP codes by area and district codes, 2025. URL https://postalpro.usps.com/ZIP_Locale_Detail. Updated May 2, 2025; accessed on May 11, 2025
work page 2025
- [15]
-
[16]
Allen Wilkinson, Jon Geist, Stanley Janet, Patrick J
R. Allen Wilkinson, Jon Geist, Stanley Janet, Patrick J. Grother, Christopher J. C. Burges, Robert Creecy, Bob Hammond, Jonathan J. Hull, and Norman L. Larsen. The first census optical character recognition system conference. NIST Interagency/Internal Report (NISTIR) 4912, National Institute of Standards and Technology, Gaithersburg, MD, 1992
work page 1992
-
[17]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms, 2017. URL https://arxiv.org/abs/1708.07747
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Cold case: The lost MNIST digits
Chhavi Yadav and L\' e on Bottou. Cold case: The lost MNIST digits. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.