Recognition: 2 theorem links
· Lean TheoremGraphFusion3D: Dynamic Graph Attention Convolution with Adaptive Cross-Modal Transformer for 3D Object Detection
Pith reviewed 2026-05-17 02:11 UTC · model grok-4.3
The pith
GraphFusion3D fuses image features into point clouds via an adaptive transformer and refines proposals with multi-scale graph attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GraphFusion3D is a unified framework that uses the Adaptive Cross-Modal Transformer to adaptively integrate image features into point cloud representations and the Graph Reasoning Module to model neighborhood relationships among proposals through multi-scale graph attention, together with a cascade decoder for progressive refinement, producing 70.6 percent AP25 and 51.2 percent AP50 on SUN RGB-D and 75.1 percent AP25 and 60.8 percent AP50 on ScanNetV2.
What carries the argument
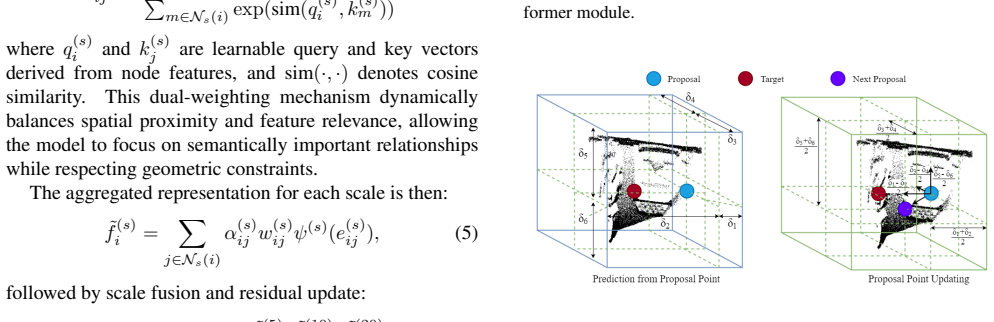
The Adaptive Cross-Modal Transformer that adaptively integrates image features into point representations together with the Graph Reasoning Module that applies multi-scale graph attention to weight spatial proximity and feature similarity between proposals.
If this is right
- Point representations gain both geometric detail and semantic context from selective image fusion.
- Proposal refinement improves by dynamically balancing local structure and broader semantic relationships in a graph.
- Multi-stage predictions from the cascade decoder allow successive correction of initial detections.
- Context between distant objects becomes easier to capture once proposals are connected through learned graph edges.
Where Pith is reading between the lines
- The same fusion and graph modules could be tested on outdoor LiDAR-camera datasets to check whether the indoor gains generalize.
- Replacing the separate proposal stage with an end-to-end graph formulation might simplify training while preserving the relational benefits.
- The attention weights learned inside the Graph Reasoning Module could be inspected to understand which spatial or feature cues matter most for different object categories.
Load-bearing premise
The reported accuracy gains arise primarily from the Adaptive Cross-Modal Transformer and Graph Reasoning Module rather than from dataset-specific tuning or training details not described in the paper.
What would settle it
An ablation experiment that removes the Adaptive Cross-Modal Transformer or the Graph Reasoning Module, retrains the model under identical conditions, and measures the resulting drop in AP25 and AP50 on SUN RGB-D would show whether those components drive the gains.
Figures




read the original abstract
Despite significant progress in 3D object detection, point clouds remain challenging due to sparse data, incomplete structures, and limited semantic information. Capturing contextual relationships between distant objects presents additional difficulties. To address these challenges, we propose GraphFusion3D, a unified framework combining multi-modal fusion with advanced feature learning. Our approach introduces the Adaptive Cross-Modal Transformer (ACMT), which adaptively integrates image features into point representations to enrich both geometric and semantic information. For proposal refinement, we introduce the Graph Reasoning Module (GRM), a novel mechanism that models neighborhood relationships to simultaneously capture local geometric structures and global semantic context. The module employs multi-scale graph attention to dynamically weight both spatial proximity and feature similarity between proposals. We further employ a cascade decoder that progressively refines detections through multi-stage predictions. Extensive experiments on SUN RGB-D (70.6% AP$_{25}$ and 51.2% AP$_{50}$) and ScanNetV2 (75.1% AP$_{25}$ and 60.8% AP$_{50}$) demonstrate a substantial performance improvement over existing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GraphFusion3D, a unified multi-modal framework for 3D object detection that fuses point clouds and images. It introduces the Adaptive Cross-Modal Transformer (ACMT) to adaptively integrate image features into point representations and the Graph Reasoning Module (GRM) that employs multi-scale graph attention to model neighborhood relationships among proposals, capturing both local geometry and global semantics. A cascade decoder progressively refines detections. The central experimental claim is substantial gains on SUN RGB-D (70.6% AP25, 51.2% AP50) and ScanNetV2 (75.1% AP25, 60.8% AP50) over prior methods.
Significance. If the performance deltas can be causally attributed to ACMT and GRM via controlled experiments, the work would offer a concrete advance in handling sparse, incomplete point clouds and inter-object context through adaptive cross-modal fusion and dynamic graph reasoning. The combination of transformer-based modality alignment with multi-scale graph attention is a plausible direction for improving proposal refinement in indoor 3D detection.
major comments (3)
- [§5 (Experiments)] §5 (Experiments) and associated tables: the reported AP25/AP50 numbers on SUN RGB-D and ScanNetV2 are presented without ablation studies that isolate ACMT or GRM. No results are shown for a controlled baseline that removes the adaptive cross-modal fusion or the multi-scale graph attention while freezing backbone, optimizer, data augmentation, and training schedule. This leaves the central claim that gains arise primarily from the proposed modules unsupported.
- [§4.2 (Graph Reasoning Module)] §4.2 (Graph Reasoning Module): the multi-scale graph attention mechanism is described at a high level but lacks explicit equations or pseudocode for computing the dynamic weights that combine spatial proximity and feature similarity. Without this, it is impossible to verify whether the module introduces new parameters or reduces to a standard attention variant.
- [Results tables and §5.3] Results tables and §5.3: no error bars, standard deviations across seeds, or hyperparameter sensitivity analysis accompany the quoted AP scores. The absence of these controls makes it difficult to assess whether the claimed improvements exceed typical variance from training stochasticity or tuning.
minor comments (2)
- [Abstract] Abstract: the phrase 'substantial performance improvement' is used without quantifying the delta relative to the strongest cited baseline or stating which prior methods were re-implemented under identical conditions.
- [Notation] Notation: AP$_{25}$ and AP$_{50}$ should be explicitly defined on first use as mean average precision at 3D IoU thresholds of 0.25 and 0.5, respectively, to align with standard 3D detection reporting conventions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating the revisions we will incorporate to strengthen the paper.
read point-by-point responses
-
Referee: §5 (Experiments) and associated tables: the reported AP25/AP50 numbers on SUN RGB-D and ScanNetV2 are presented without ablation studies that isolate ACMT or GRM. No results are shown for a controlled baseline that removes the adaptive cross-modal fusion or the multi-scale graph attention while freezing backbone, optimizer, data augmentation, and training schedule. This leaves the central claim that gains arise primarily from the proposed modules unsupported.
Authors: We agree that dedicated ablation studies isolating the contributions of ACMT and GRM are important for rigorously supporting our claims. In the revised manuscript, we will add controlled ablation experiments that remove either the adaptive cross-modal fusion or the multi-scale graph attention while keeping the backbone, optimizer, data augmentation, and training schedule fixed. These results will be presented in an expanded Section 5 to quantify the specific gains from each module. revision: yes
-
Referee: §4.2 (Graph Reasoning Module): the multi-scale graph attention mechanism is described at a high level but lacks explicit equations or pseudocode for computing the dynamic weights that combine spatial proximity and feature similarity. Without this, it is impossible to verify whether the module introduces new parameters or reduces to a standard attention variant.
Authors: We thank the referee for highlighting this clarity issue. In the revised manuscript, we will expand Section 4.2 to include explicit mathematical equations and pseudocode for the multi-scale graph attention. These will detail the computation of dynamic weights from spatial proximity and feature similarity, along with any introduced parameters, to facilitate verification and reproducibility. revision: yes
-
Referee: Results tables and §5.3: no error bars, standard deviations across seeds, or hyperparameter sensitivity analysis accompany the quoted AP scores. The absence of these controls makes it difficult to assess whether the claimed improvements exceed typical variance from training stochasticity or tuning.
Authors: We acknowledge the importance of statistical reporting for assessing result reliability. In the revised version, we will run experiments with multiple random seeds and report mean AP scores with standard deviations for SUN RGB-D and ScanNetV2. We will also include a hyperparameter sensitivity analysis in Section 5.3 to address potential variance from training stochasticity and tuning. revision: yes
Circularity Check
No circularity in derivation chain; claims rest on empirical architecture and benchmarks
full rationale
The paper presents GraphFusion3D as a new framework introducing the Adaptive Cross-Modal Transformer (ACMT) for multi-modal fusion and the Graph Reasoning Module (GRM) with multi-scale graph attention for proposal refinement, followed by a cascade decoder. Performance is reported via standard metrics on SUN RGB-D and ScanNetV2. No equations, first-principles derivations, or predictions that reduce by construction to fitted parameters or self-definitions appear in the abstract or described structure. Claims are grounded in experimental results on public benchmarks rather than self-referential math or load-bearing self-citations that would force equivalence to inputs. The derivation chain is therefore self-contained through novel components and external validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-scale attention weights
axioms (2)
- domain assumption Image features can be adaptively integrated into point representations to enrich both geometric and semantic information
- domain assumption Neighborhood relationships among proposals encode both local geometric structures and global semantic context
invented entities (2)
-
Adaptive Cross-Modal Transformer (ACMT)
no independent evidence
-
Graph Reasoning Module (GRM)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The module employs multi-scale graph attention to dynamically weight both spatial proximity and feature similarity between proposals.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an Adaptive Cross-Modal Transformer (ACMT), which dynamically aligns 2D image features and 3D point features
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A hierarchical graph network for 3d object detection on point clouds
Jintai Chen, Biwen Lei, Qingyu Song, Haochao Ying, Danny Z Chen, and Jian Wu. A hierarchical graph network for 3d object detection on point clouds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 392–401, 2020. 6
work page 2020
-
[2]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 7
work page 2019
-
[3]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017. 5
work page 2017
-
[4]
Kun Dai, Zhiqiang Jiang, Tao Xie, Ke Wang, Dedong Liu, Zhendong Fan, Ruifeng Li, Lijun Zhao, and Mohamed Omar. Sofw: A synergistic optimization framework for in- door 3d object detection.IEEE Transactions on Multimedia, pages 637–651, 2025. 3
work page 2025
-
[5]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 7
work page 2016
-
[6]
Unidet3d: Multi- dataset indoor 3d object detection
Maksim Kolodiazhnyi, Anna V orontsova, Matvey Skripkin, Danila Rukhovich, and Anton Konushin. Unidet3d: Multi- dataset indoor 3d object detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4365– 4373, 2025. 3
work page 2025
-
[7]
Zhe Liu, Tengteng Huang, Bingling Li, Xiwu Chen, Xi Wang, and Xiang Bai. Epnet++: Cascade bi-directional fusion for multi-modal 3d object detection.IEEE Trans- actions on Pattern Analysis and Machine Intelligence, 45: 8324–8341, 2021. 1, 3, 6
work page 2021
-
[8]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10012–10022, 2021. 7
work page 2021
-
[9]
Group-free 3d object detection via transformers
Ze Liu, Zheng Zhang, Yue Cao, Han Hu, and Xin Tong. Group-free 3d object detection via transformers. InProceed- ings of the IEEE International Conference on Computer Vi- sion, pages 2929–2938. Institute of Electrical and Electron- ics Engineers Inc., 2021. 3, 6
work page 2021
-
[10]
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection
Zongdai Liu, Dingfu Zhou, Feixiang Lu, Jin Fang, and Liangjun Zhang. AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection . In2021 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 15621–15630, Los Alamitos, CA, USA, 2021. 1
work page 2021
-
[11]
An end- to-end transformer model for 3d object detection
Ishan Misra, Rohit Girdhar, and Armand Joulin. An end- to-end transformer model for 3d object detection. InPro- ceedings of the IEEE International Conference on Computer Vision. Institute of Electrical and Electronics Engineers Inc.,
-
[12]
Multi-modality task cascade for 3d object detection
Jinhyung Park, Xinshuo Weng, Yunze Man, and Kris Kitani. Multi-modality task cascade for 3d object detection. InThe British Machine Vision Conference (BMVC), 2021. 3, 6
work page 2021
-
[13]
Qi, Hao Su, Kaichun Mo, and Leonidas J
Charles R. Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, pages 77–85. Institute of Electrical and Electronics Engi- neers Inc., 2016. 1, 2
work page 2017
-
[14]
PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Point- net++: Deep hierarchical feature learning on point sets in a metric space.arXiv preprint arXiv:1706.02413, 2017. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Frustum pointnets for 3d object detection from rgb- d data
Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb- d data. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 918–927, 2018. 1
work page 2018
-
[16]
Deep hough voting for 3d object detection in point clouds
Charles R Qi, Or Litany, Kaiming He, and Leonidas J Guibas. Deep hough voting for 3d object detection in point clouds. Inproceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 9277–9286, 2019. 1, 2, 6
work page 2019
-
[17]
Imvotenet: Boosting 3d object detection in point clouds with image votes
Charles R Qi, Xinlei Chen, Or Litany, and Leonidas J Guibas. Imvotenet: Boosting 3d object detection in point clouds with image votes. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 1, 3, 6
work page 2020
-
[18]
Fcaf3d: Fully convolutional anchor-free 3d object detection
Danila Rukhovich, Anna V orontsova, and Anton Konushin. Fcaf3d: Fully convolutional anchor-free 3d object detection. InEuropean Conference on Computer Vision, pages 477–
-
[19]
Springer, 2022. 3, 5, 6
work page 2022
-
[20]
Tr3d: Towards real-time indoor 3d object detection
Danila Rukhovich, Anna V orontsova, and Anton Konushin. Tr3d: Towards real-time indoor 3d object detection. InIEEE International Conference on Image Processing (ICIP), 2023. 3, 5, 6
work page 2023
-
[21]
Yichao Shen, Zigang Geng, Yuhui Yuan, Yutong Lin, Ze Liu, Chunyu Wang, Han Hu, Nanning Zheng, and Baining Guo. V-detr: Detr with vertex relative position encoding for 3d object detection.arXiv preprint arXiv:2308.04409, 2023. 3, 6
-
[22]
Geometry-based dis- tance decomposition for monocular 3d object detection
Xuepeng Shi, Qi Ye, Xiaozhi Chen, Chuangrong Chen, Zhixiang Chen, and Tae-Kyun Kim. Geometry-based dis- tance decomposition for monocular 3d object detection. In 2021 IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 15152–15161, 2021. 1
work page 2021
-
[23]
Deep sliding shapes for amodal 3d object detection in rgb-d images
Shuran Song and Jianxiong Xiao. Deep sliding shapes for amodal 3d object detection in rgb-d images. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 808–816, 2016. 3
work page 2016
-
[24]
Lichtenberg, and Jianxiong Xiao
Shuran Song, Samuel P. Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 567–576. IEEE Computer Society, 2015. 3, 5
work page 2015
-
[25]
CA- Group3d: Class-aware grouping for 3d object detection on point clouds
Haiyang Wang, Lihe Ding, Shaocong Dong, Shaoshuai Shi, Aoxue Li, Jianan Li, Zhenguo Li, and Liwei Wang. CA- Group3d: Class-aware grouping for 3d object detection on point clouds. InAdvances in Neural Information Processing Systems, 2022. 3, 6
work page 2022
-
[26]
Multimodal token fusion for vision transformers
Yikai Wang, Xinghao Chen, Lele Cao, Wenbing Huang, Fuchun Sun, and Yunhe Wang. Multimodal token fusion for vision transformers. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 3, 6 9
work page 2022
-
[27]
Uni3detr: Unified 3d detection transformer
Zhenyu Wang, Ya-Li Li, Xi Chen, Hengshuang Zhao, and Shengjin Wang. Uni3detr: Unified 3d detection transformer. Advances in Neural Information Processing Systems, 36: 39876–39896, 2023. 6
work page 2023
-
[28]
Boost- ing 3d object detection via object-focused image fusion
Hao Yang, Chen Shi, Yihong Chen, and Liwei Wang. Boost- ing 3d object detection via object-focused image fusion. arXiv preprint arXiv:2207.10589, 2022. 1, 3
-
[29]
Yu-Qi Yang, Yu-Xiao Guo, Jian-Yu Xiong, Yang Liu, Hao Pan, Peng-Shuai Wang, Xin Tong, and Baining Guo. Swin3d: A pretrained transformer backbone for 3d indoor scene understanding.Computational Visual Media, 11(1): 83–101, 2025. 7
work page 2025
-
[30]
Spgroup3d: Su- perpoint grouping network for indoor 3d object detection
Yun Zhu, Le Hui, Yaqi Shen, and Jin Xie. Spgroup3d: Su- perpoint grouping network for indoor 3d object detection. InProceedings of the AAAI Conference on Artificial Intelli- gence, pages 7811–7819, 2024. 3, 6 10
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.