Mechanistic Interpretability of Antibody Language Models Using SAEs
Pith reviewed 2026-05-17 00:23 UTC · model grok-4.3
The pith
Ordered SAEs reliably identify steerable features in antibody language models at the cost of more complex activation patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TopK SAEs can reveal biologically meaningful latent features in autoregressive antibody language models, but high feature-concept correlation does not guarantee causal control over generation. Ordered SAEs impose a hierarchical structure that reliably identifies steerable features, though this results in more complex and less interpretable activation patterns.
What carries the argument
TopK and Ordered sparse autoencoders (SAEs) applied to extract and steer latent features in antibody language models.
If this is right
- TopK SAEs suffice for mapping latent features to biological concepts.
- Ordered SAEs are better when precise generative steering is needed.
- Mechanistic interpretability advances for domain-specific protein language models.
- SAE choice depends on whether the goal is concept mapping or output control.
Where Pith is reading between the lines
- If the hierarchical structure in Ordered SAEs generalizes, it could help interpret other specialized language models beyond antibodies.
- Combining TopK for initial mapping with Ordered for steering might offer a hybrid approach to interpretability.
- Testing these methods on larger antibody datasets or different protein families would check broader applicability.
Load-bearing premise
Observed correlations between SAE features and biological concepts reflect causal mechanisms rather than spurious associations, and steering success generalizes to untested antibody sequences.
What would settle it
A test showing that steering using Ordered SAE features fails to alter generated antibodies in the expected biological way on a held-out set of sequences, or that TopK features do enable such control.
Figures
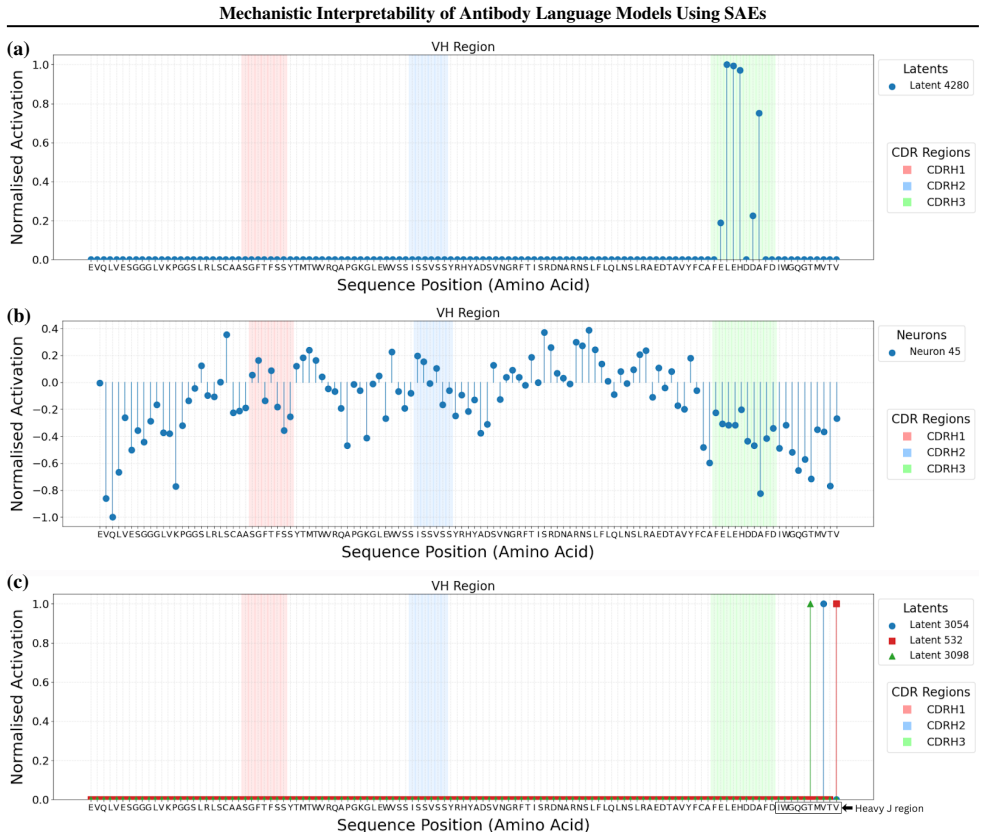
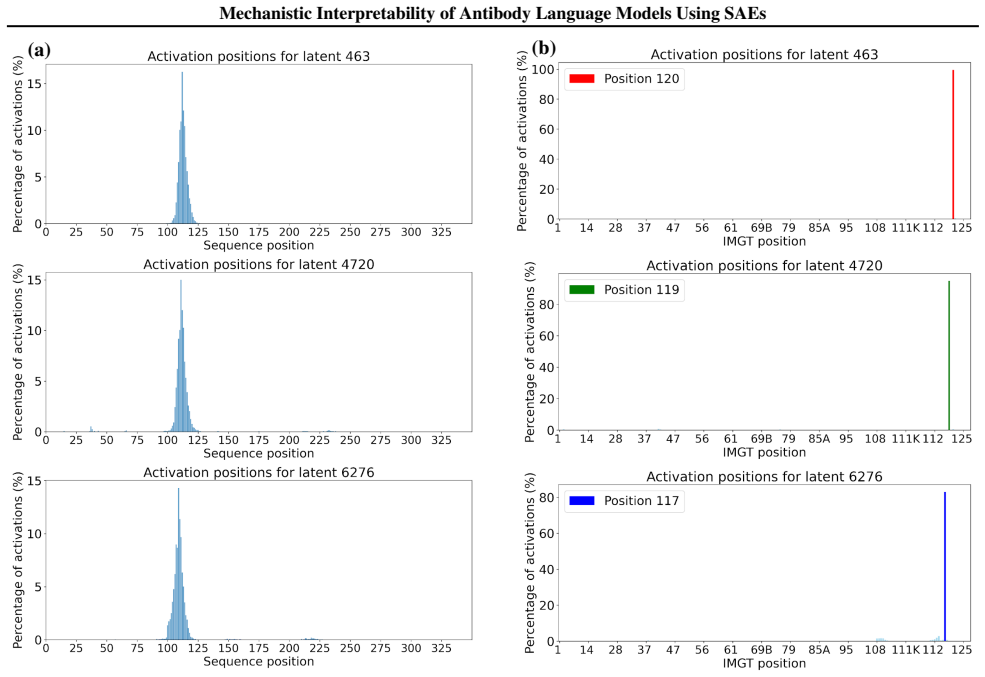
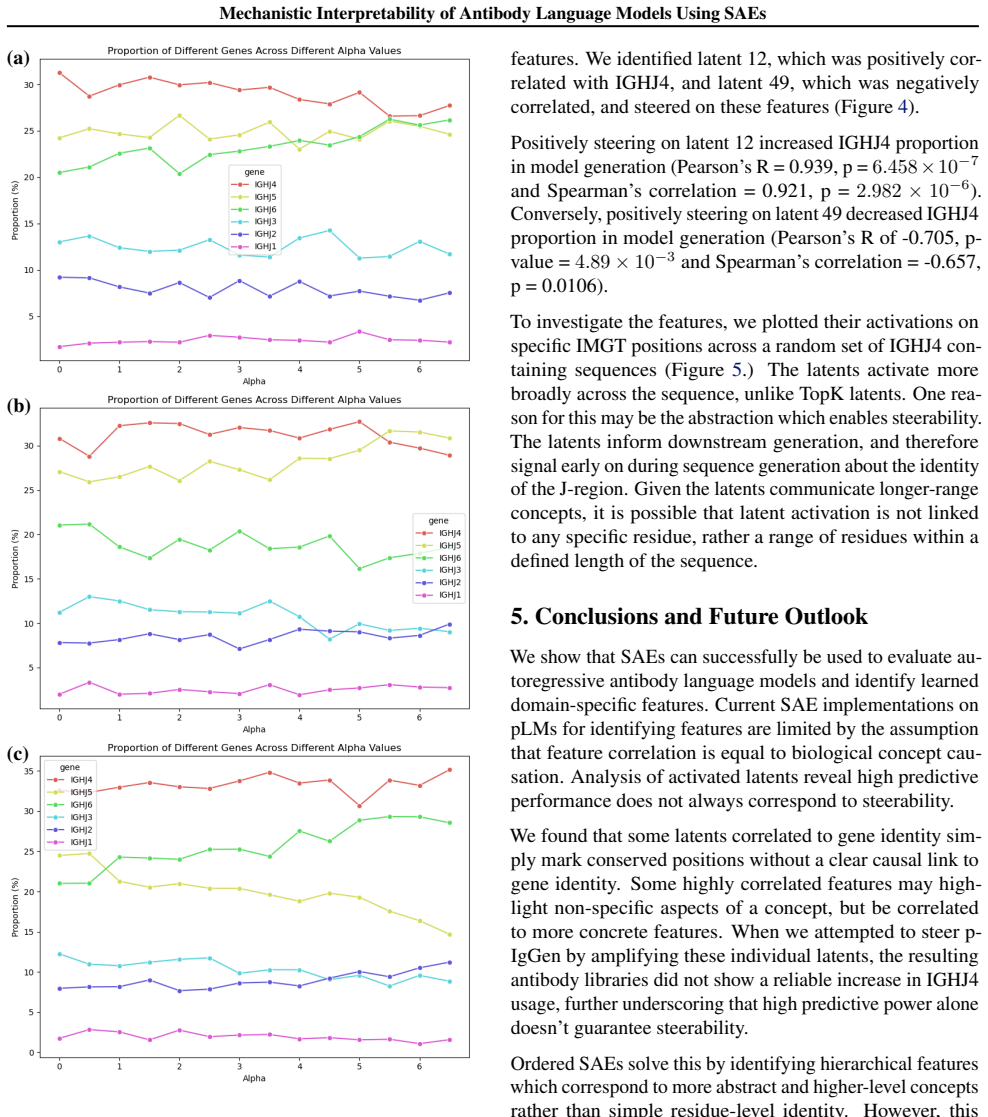
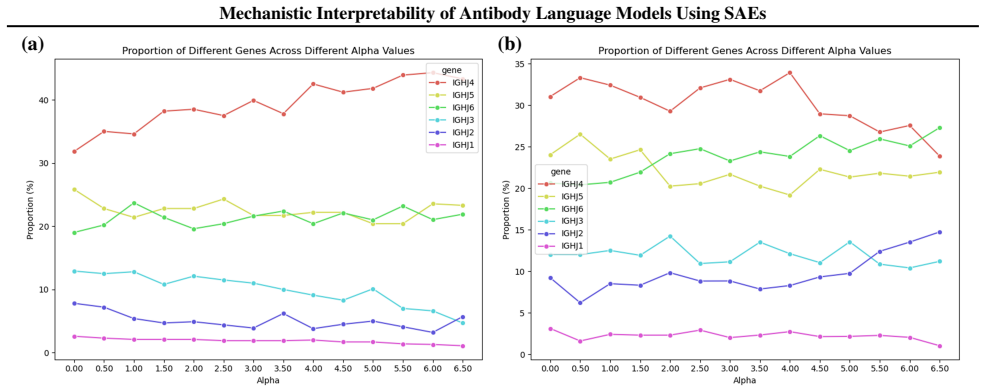
read the original abstract
Sparse autoencoders (SAEs) are a mechanistic interpretability technique that have been used to provide insight into learned concepts within large protein language models. Here, we employ TopK and Ordered SAEs to investigate autoregressive antibody language models, and steer their generation. We show that TopK SAEs can reveal biologically meaningful latent features, but high feature-concept correlation does not guarantee causal control over generation. In contrast, Ordered SAEs impose a hierarchical structure that reliably identifies steerable features, but at the expense of more complex and less interpretable activation patterns. These findings advance the mechanistic interpretability of domain-specific protein language models and suggest that, while TopK SAEs suffice for mapping latent features to concepts, Ordered SAEs are preferable when precise generative steering is required.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript applies TopK and Ordered Sparse Autoencoders (SAEs) to autoregressive antibody language models to extract latent features and enable generative steering. It reports that TopK SAEs identify biologically meaningful features but that high feature-concept correlation does not guarantee causal control over generation. Ordered SAEs impose a hierarchical structure that reliably surfaces steerable features, at the cost of more complex and less interpretable activation patterns. The work positions these distinctions as guidance for choosing SAE variants in domain-specific protein language models depending on whether the goal is concept mapping or precise steering.
Significance. If the empirical distinctions are substantiated, the paper would provide useful practical guidance on SAE selection for mechanistic interpretability in biological sequence models. It extends SAE techniques to antibody LMs and usefully separates correlation from causal control, which is relevant as these models see increasing use in design tasks. The trade-off between interpretability and steerability is a concrete contribution that could inform tool choice in the field.
major comments (3)
- [Abstract and §4] Abstract and §4 (Steering Experiments): The central claim that Ordered SAEs 'reliably identify steerable features' via imposed hierarchy lacks an ablation that removes the ordering constraint while holding sparsity and reconstruction loss fixed. Without this control it remains unclear whether the reported steering advantage reflects discovered model-internal causal directions or is an artifact of the ordering itself biasing controllable axes.
- [§3 and Results tables] §3 (Methods) and Results tables: No dataset sizes, number of antibody sequences, exact correlation or steering-success metrics, or statistical tests are described. This absence makes it impossible to assess whether the claimed distinctions between TopK and Ordered SAEs are robust or reproducible.
- [§5] §5 (Discussion): The assertion that high feature-concept correlation does not guarantee causal control for TopK SAEs is load-bearing for the recommendation to prefer Ordered SAEs for steering; the manuscript must show concrete counter-examples where high correlation fails to produce steering success, with quantitative effect sizes.
minor comments (2)
- [§2] §2 (Background): The precise definition and implementation details of the ordering constraint in Ordered SAEs versus standard TopK should be expanded for reproducibility.
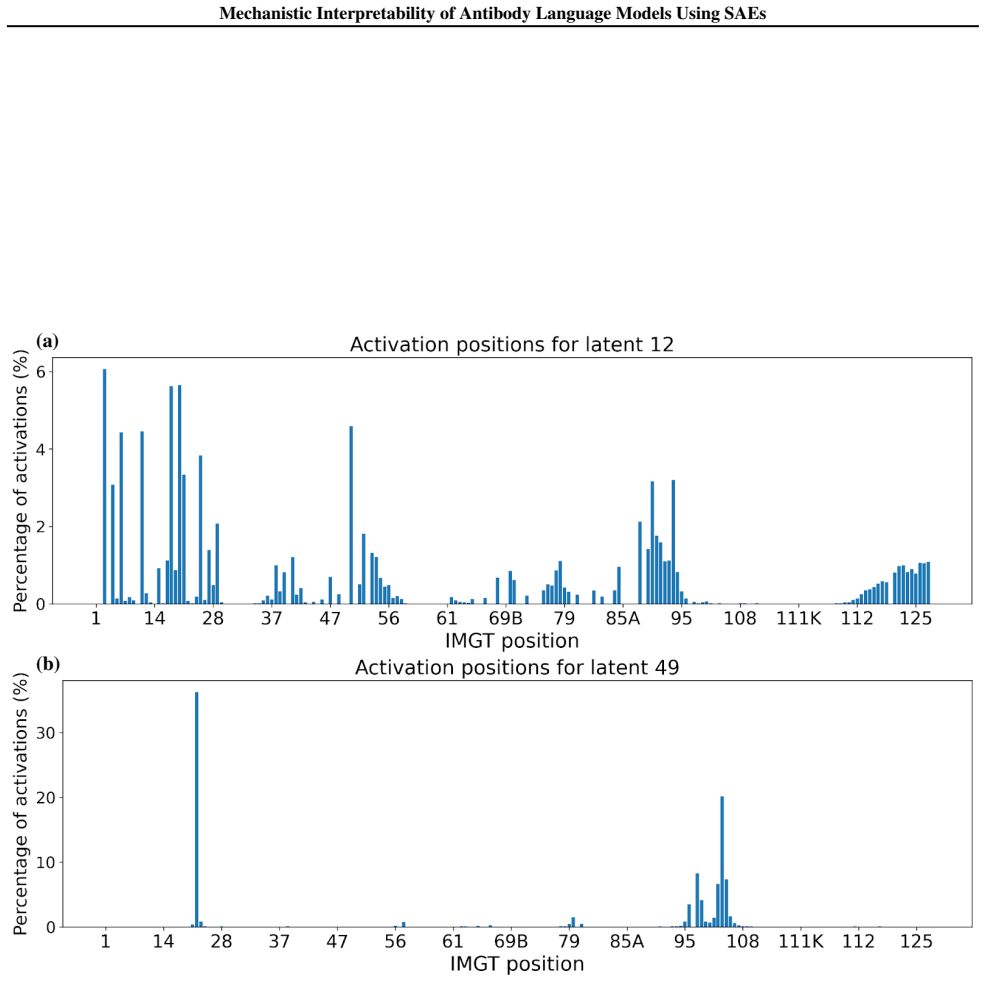
- [Figures] Figure captions: Activation-pattern visualizations should explicitly label which panels correspond to TopK versus Ordered SAEs and quantify the claimed increase in complexity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and rigor of our empirical claims. We address each of the major comments in detail below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Steering Experiments): The central claim that Ordered SAEs 'reliably identify steerable features' via imposed hierarchy lacks an ablation that removes the ordering constraint while holding sparsity and reconstruction loss fixed. Without this control it remains unclear whether the reported steering advantage reflects discovered model-internal causal directions or is an artifact of the ordering itself biasing controllable axes.
Authors: We agree that a controlled ablation isolating the ordering constraint while holding sparsity and reconstruction loss fixed would strengthen the evidence. The Ordered SAE is defined by its hierarchical ordering mechanism, which is the key distinction from TopK SAEs in our comparisons. In the revised manuscript, we will add a dedicated discussion of this architectural difference and include a sensitivity analysis or partial ablation where feasible to better isolate the contribution of the ordering. revision: partial
-
Referee: [§3 and Results tables] §3 (Methods) and Results tables: No dataset sizes, number of antibody sequences, exact correlation or steering-success metrics, or statistical tests are described. This absence makes it impossible to assess whether the claimed distinctions between TopK and Ordered SAEs are robust or reproducible.
Authors: We apologize for the omission of these critical details. In the revised manuscript, we will expand §3 and the results tables to report the exact number of antibody sequences used, dataset sizes for SAE training and evaluation, numerical values for all correlation and steering-success metrics, and appropriate statistical tests (including p-values) to demonstrate the robustness of the observed differences. revision: yes
-
Referee: [§5] §5 (Discussion): The assertion that high feature-concept correlation does not guarantee causal control for TopK SAEs is load-bearing for the recommendation to prefer Ordered SAEs for steering; the manuscript must show concrete counter-examples where high correlation fails to produce steering success, with quantitative effect sizes.
Authors: We will strengthen this section by adding explicit counter-examples drawn from our steering experiments. These will include specific TopK features with high concept correlations that nonetheless showed low steering success, accompanied by quantitative effect sizes such as changes in generation probabilities or success rates, to directly support the distinction from Ordered SAEs. revision: yes
Circularity Check
No load-bearing circularity; claims rest on direct experimental comparisons of SAE variants.
full rationale
The paper applies TopK and Ordered SAEs to antibody language models and reports empirical outcomes on feature-concept correlations and steering success. No derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present. The central claims compare observed performance differences between SAE architectures on biological data without reducing to self-definitional or ansatz-smuggled constructions. Any self-citations are peripheral and not required for the reported findings, which remain falsifiable via external replication on held-out sequences.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ordered SAEs impose a hierarchical structure that reliably identifies steerable features... per-index nested grouping and strictly decreasing truncation weights
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high feature–concept correlation does not guarantee causal control over generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.