Zero-Shot Textual Explanations via Translating Decision-Critical Features
Pith reviewed 2026-05-21 18:03 UTC · model grok-4.3
The pith
TEXTER generates textual explanations for image classifier decisions by isolating decision-critical features before aligning them with language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
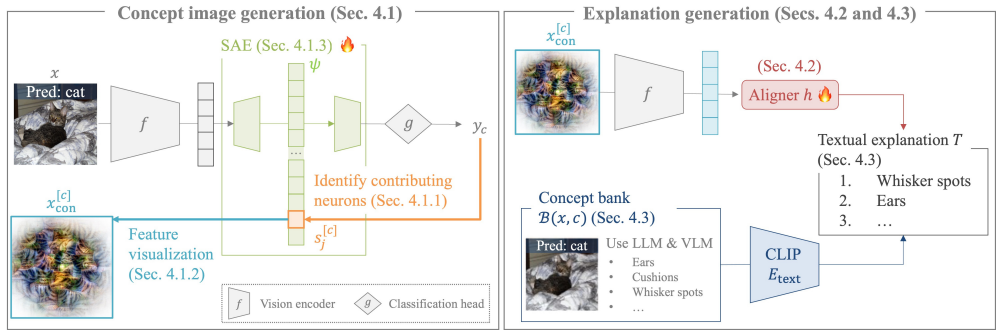
TEXTER identifies the neurons contributing to the prediction and emphasizes the features encoded in those neurons. It then maps these emphasized features into the CLIP feature space to retrieve textual explanations that reflect the model's reasoning. A sparse autoencoder further improves interpretability, particularly for Transformer architectures. Extensive experiments show that TEXTER provides more faithful and interpretable explanations than existing methods.
What carries the argument
Neuron-based isolation of decision-critical features before CLIP alignment, with sparse autoencoding for transformers.
If this is right
- Textual explanations will describe the specific elements that drove the classifier's output rather than general image content.
- Explanation faithfulness will increase because only prediction-relevant features are aligned with language.
- Sparse autoencoders will enhance human interpretability of the resulting descriptions, especially on transformer backbones.
- Zero-shot explanations become available for any pretrained classifier without additional labeled explanation data.
Where Pith is reading between the lines
- The neuron-isolation step could be adapted to other model types, such as those processing text or audio, by identifying analogous critical units.
- Selective feature emphasis before cross-modal mapping may prove useful for improving alignment quality in other vision-language tasks.
- One could test whether the same isolation principle improves post-hoc explanations for regression or detection models beyond simple classification.
- If the method scales, it suggests that interpretability gains can come from post-processing feature selection rather than model retraining.
Load-bearing premise
The neurons identified as contributing to the prediction encode precisely the decision-critical features whose mapping into CLIP space will faithfully reflect the classifier's internal reasoning.
What would settle it
If faithfulness metrics show that TEXTER explanations do not align better with the classifier's output changes under feature ablation than global-feature baselines, the advantage of isolating decision-critical features would not hold.
Figures




read the original abstract
Textual explanations make image classifier decisions transparent by describing the prediction rationale in natural language. Large vision-language models can generate captions but are designed for general visual understanding, not classifier-specific reasoning. Existing zero-shot explanation methods align global image features with language, producing descriptions of what is visible rather than what drives the prediction. We propose TEXTER, which overcomes this limitation by isolating decision-critical features before alignment. TEXTER identifies the neurons contributing to the prediction and emphasizes the features encoded in those neurons -- i.e., the decision-critical features. It then maps these emphasized features into the CLIP feature space to retrieve textual explanations that reflect the model's reasoning. A sparse autoencoder further improves interpretability, particularly for Transformer architectures. Extensive experiments show that TEXTER provides more faithful and interpretable explanations than existing methods. The code is available at \url{https://github.com/tttt-0814/TEXTER}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TEXTER, a zero-shot method for textual explanations of image classifier decisions. It first identifies neurons contributing to the prediction, emphasizes the features encoded by those neurons (termed decision-critical features), maps the resulting vector into CLIP space, and retrieves the nearest text descriptions. A sparse autoencoder is used to improve interpretability for Transformer architectures. The authors report that extensive experiments demonstrate superior faithfulness and interpretability relative to prior zero-shot alignment methods.
Significance. If the faithfulness claims are substantiated, the work would offer a practical route to classifier-specific explanations that avoid the generic visual descriptions produced by global feature alignment. The open release of code supports reproducibility and could facilitate follow-up studies in explainable computer vision.
major comments (1)
- [Method (central construction)] The faithfulness claim rests on the assumption that CLIP-space nearest-neighbor retrieval from neuron-emphasized features recovers language that describes the classifier's actual decision boundary. No controlled ablation is reported that isolates the projection step by comparing retrieval from raw image features versus neuron-emphasized features while holding the input image fixed; without this comparison the contribution of the decision-critical feature isolation cannot be separated from CLIP's general visual-textual correlations.
minor comments (1)
- [Abstract] The abstract states that 'extensive experiments' demonstrate superiority but does not name the datasets, quantitative metrics, or baseline methods; adding these details would clarify the evaluation scope.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The feedback highlights an important aspect of validating the core contribution of decision-critical feature isolation. We address the major comment below and will revise the manuscript to incorporate the suggested analysis.
read point-by-point responses
-
Referee: [Method (central construction)] The faithfulness claim rests on the assumption that CLIP-space nearest-neighbor retrieval from neuron-emphasized features recovers language that describes the classifier's actual decision boundary. No controlled ablation is reported that isolates the projection step by comparing retrieval from raw image features versus neuron-emphasized features while holding the input image fixed; without this comparison the contribution of the decision-critical feature isolation cannot be separated from CLIP's general visual-textual correlations.
Authors: We agree that a controlled ablation holding the input image fixed would more cleanly isolate the benefit of the neuron-emphasis step. While our current experiments already compare TEXTER against global-alignment baselines on the same images and report improved faithfulness metrics, they do not include the exact raw-versus-emphasized retrieval comparison on identical inputs. In the revised manuscript we will add this ablation: for a fixed set of images we will retrieve nearest-neighbor text using (i) raw CLIP image features and (ii) our neuron-emphasized features, then quantify the difference in explanation faithfulness and human interpretability. The new results will be presented in a dedicated table and discussed in the experimental section. revision: yes
Circularity Check
No circularity: method assembles external components without self-referential reduction
full rationale
The paper's core construction identifies neurons contributing to a classifier prediction, emphasizes the encoded features, projects the result into CLIP space, and retrieves nearest-neighbor text. This sequence is presented as a procedural pipeline using standard external tools (CLIP, sparse autoencoders) rather than any derivation that equates an output quantity to a fitted input or prior self-citation by construction. No equations are supplied that would make the faithfulness claim tautological, and the experimental comparisons are treated as independent validation. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TEXTER identifies the neurons contributing to the prediction using Integrated Gradients... maps these emphasized features into the CLIP feature space
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A sparse autoencoder further improves interpretability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam et al. Gpt-4 technical report. arXiv: 2303.08774, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023. 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Network Dissection: Quantifying Inter- pretability of Deep Visual Representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network Dissection: Quantifying Inter- pretability of Deep Visual Representations . In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3319–3327, 2017. 2
work page 2017
-
[4]
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Fl´ avio P . Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice). CoRR, abs/2402.10376, 2024. 4
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´ e J´ egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In Pro- ceedings of the IEEE International Conference on Computer Vision (ICCV), 2021. 5
work page 2021
-
[6]
Devil: Decoding vision features into language
Meghal Dani, Isabel Rio-Torto, Stephan Alaniz, and Zeyn ep Akata. Devil: Decoding vision features into language. CoRR, 2023. 2
work page 2023
-
[7]
Imagenet: A large-scale hierarchical im- age database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical im- age database. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 248–255, 2009. 5
work page 2009
-
[8]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov , Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In The International Conference on Learning Repre- sentations (ICLR), 2021. 5
work page 2021
-
[9]
Mark Everingham, Luc V an Gool, Christopher K. I. Williams, John M. Winn, and Andrew Zisserman. The pas- cal visual object classes (voc) challenge. Int. J. Comput. Vis., 88(2):303–338, 2010. 6
work page 2010
-
[10]
Unlocking feature visualiza- tion for deep network with MAgnitude constrained optimiza- tion
Thomas FEL, Thibaut Boissin, Victor Boutin, Agustin Ma r- tin Picard, Paul Novello, Julien Colin, Drew Linsley, Tom ROUSSEAU, Remi Cadene, Lore Goetschalckx, Laurent Gardes, and Thomas Serre. Unlocking feature visualiza- tion for deep network with MAgnitude constrained optimiza- tion. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 2, 3, 4
work page 2023
-
[11]
A holistic approach to unifying automatic concept extraction and concept importance estimation
Thomas FEL, Victor Boutin, Louis B´ ethune, Remi Ca- dene, Mazda Moayeri, L´ eo And´ eol, Mathieu Chalvidal, and Thomas Serre. A holistic approach to unifying automatic concept extraction and concept importance estimation. In Thirty-seventh Conference on Neural Information Process- ing Systems, 2023. 4
work page 2023
-
[12]
Craft: Concept recursive activation factori za- tion for explainability, 2023
Thomas Fel, Agustin Picard, Louis Bethune, Thibaut Boissin, David Vigouroux, Julien Colin, R´ emi Cad` ene, and Thomas Serre. Craft: Concept recursive activation factori za- tion for explainability, 2023. 2
work page 2023
-
[13]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. In The International Conference on Learning Representations (ICLR), 2025. 2, 4, 1
work page 2025
-
[14]
Ada Gorgun, Bernt Schiele, and Jonas Fischer. Vital: More understandable feature visualization through distri bu- tion alignment and relevant information flow, 2025. 4
work page 2025
-
[15]
Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. 5
work page 2016
-
[16]
Generating vi- sual explanations
Lisa Anne Hendricks, Zeynep Akata, Marcus Rohrbach, Je ff Donahue, Bernt Schiele, and Trevor Darrell. Generating vi- sual explanations. In Proceedings of the European Confer- ence on Computer Vision (ECCV) , pages 3–19, 2016. 2
work page 2016
-
[17]
Natural language descriptions of deep visual features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natural language descriptions of deep visual features. In The In- ternational Conference on Learning Representations (ICLR), 2022. 4
work page 2022
-
[18]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bra s, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Pro- cessing, pages 7514–7528, 2021. 6
work page 2021
-
[19]
Forrest N. Iandola, Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parame- ters and ¡0.5mb model size, 2016. 7
work page 2016
-
[20]
Comparing th e decision-making mechanisms by transformers and cnns via explanation methods
Mingqi Jiang, Saeed Khorram, and Li Fuxin. Comparing th e decision-making mechanisms by transformers and cnns via explanation methods. In Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR) , pages 9546–9555, 2024. 4, 6, 8
work page 2024
-
[21]
C ai, James Wexler, Fernanda B
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie J. C ai, James Wexler, Fernanda B. Vi´ egas, and Rory Sayres. In- terpretability beyond feature attribution: Quantitative test- ing with concept activation vectors (tcav). In Proceedings of the International Conference on Machine Learning (ICML) , pages 2673–2682, 2018. 2
work page 2018
-
[22]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In Proceedings of the Interna- tional Conference on Machine Learning (ICML) , 2020. 1, 2
work page 2020
-
[23]
Imagenet classification with deep convolutional neural net - works
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton . Imagenet classification with deep convolutional neural net - works. In Advances in Neural Information Processing Sys- tems (NeurIPS), 2012. 7 9
work page 2012
-
[24]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unifi ed vision-language understanding and generation. In Proceed- ings of the 39th International Conference on Machine Learn- ing, pages 12888–12900, 2022. 1, 2
work page 2022
-
[25]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Y ong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems, pages 34892–34916, 2023. 1, 2
work page 2023
-
[26]
Hybrid concept bot- tleneck models
Yang Liu, Tianwei Zhang, and Shi Gu. Hybrid concept bot- tleneck models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 20179–20189, 2025. 1, 2
work page 2025
-
[27]
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural In- formation Processing Systems (NeurIPS) , page 4768–4777,
-
[28]
Visual classification v ia description from large language models, 2023
Sachit Menon and Carl V ondrick. Visual classification v ia description from large language models, 2023. 2, 5
work page 2023
-
[29]
Text-to-concept (and back) via cross-model alignment
Mazda Moayeri, Keivan Rezaei, Maziar Sanjabi, and Sohe il Feizi. Text-to-concept (and back) via cross-model alignment. In Proceedings of the International Conference on Machine Learning (ICML), 2023. 1, 2, 3, 4, 5, 7
work page 2023
-
[30]
Synthesizing the preferred inputs for neurons in neural networks via deep generator net- works
Anh Nguyen, Alexey Dosovitskiy, Jason Y osinski, Thoma s Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator net- works. In Advances in Neural Information Processing Sys- tems (NeurIPS), page 3395–3403, 2016. 4
work page 2016
-
[31]
Bengio, Alexey Dosovitskiy,and Jason Y osinski
Anh Nguyen, Jeff Clune, Y . Bengio, Alexey Dosovitskiy,and Jason Y osinski. Plug & play generative networks: Condi- tional iterative generation of images in latent space. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3510–3520, 2017. 4
work page 2017
-
[32]
Tuomas Oikarinen, Subhro Das, Lam M. Nguyen, and Tsui- Wei Weng. Label-free concept bottleneck models. In The In- ternational Conference on Learning Representations (ICLR),
-
[33]
Tuomas P . Oikarinen and Tsui-Wei Weng. Clip-dissect: A u- tomatic description of neuron representations in deep visi on networks. In The International Conference on Learning Rep- resentations (ICLR), 2023. 4
work page 2023
-
[34]
Christopher Olah, Ludwig Schubert, and Alexander Mord v- intsev. Feature visualization. Distill, 2017. 4
work page 2017
-
[35]
OpenAI. Gpt-3.5 turbo models. https://platform.openai.com/docs/models/gpt-3-5 ,
-
[36]
Accessed 2025-10-13. 5
work page 2025
-
[37]
Multimodal explanations: Justifying deci- sions and pointing to the evidence
Dong Huk Park, Lisa Anne Hendricks, Zeynep Akata, Anna Rohrbach, Bernt Schiele, Trevor Darrell, and Mar- cus Rohrbach. Multimodal explanations: Justifying deci- sions and pointing to the evidence. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018. 2
work page 2018
-
[38]
Language models are unsuper- vised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dari o Amodei, and Ilya Sutskever. Language models are unsuper- vised multitask learners. OpenAI, 2019. 2
work page 2019
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML) , pages 8748–8763, 2021. 1, 2, 4
work page 2021
-
[40]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML) , pages 8748–8763, 2021. 4
work page 2021
-
[41]
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision trans- formers see like convolutional neural networks? In Advances in Neural Information Processing Systems (NeurIPS) , pages 12116–12128, 2021. 4, 6, 8
work page 2021
-
[42]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 7
work page 2022
-
[43]
Leonard Salewski, A. Sophia Koepke, Hendrik P . A. Lensc h, and Zeynep Akata. Zero-shot translation of attention patterns in vqa models to natural language. In Pattern Recognition, pages 378–393, Cham, 2024. 2
work page 2024
-
[44]
Uni-nlx: Unify- ing textual explanations for vision and vision-language tasks
Fawaz Sammani and Nikos Deligiannis. Uni-nlx: Unify- ing textual explanations for vision and vision-language tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) W orkshops , pages 4634–4639,
-
[45]
Zero-shot natura l language explanations
Fawaz Sammani and Nikos Deligiannis. Zero-shot natura l language explanations. In The International Conference on Learning Representations (ICLR), 2025. 1, 2, 3, 6
work page 2025
-
[46]
Nlx-gpt: A model for natural language explanations in vision and vision-language tasks
Fawaz Sammani, Tanmoy Mukherjee, and Nikos Deligian- nis. Nlx-gpt: A model for natural language explanations in vision and vision-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8322–8332, 2022. 1, 2
work page 2022
-
[47]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna V edantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna V edantam, Devi Parikh, and Dhruv Ba- tra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE In- ternational Conference on Computer Vision (ICCV) , pages 618–626, 2017. 5
work page 2017
-
[48]
Incremental residual con- cept bottleneck models
Chenming Shang, Shiji Zhou, Hengyuan Zhang, Xinzhe Ni, Y ujiu Yang, and Y uwang Wang. Incremental residual con- cept bottleneck models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11030–11040, 2024. 2
work page 2024
-
[49]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. In Pro- ceedings of the 56th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pages 2556–2565, 2018. 2
work page 2018
-
[50]
Rupprecht, and Andrea V eda ldi
Aleksandar Shtedritski, C. Rupprecht, and Andrea V eda ldi. What does clip know about a red circle? visual prompt engi- neering for vlms, 2023. 2 10
work page 2023
-
[51]
Axiomat ic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomat ic attribution for deep networks. In Proceedings of the In- ternational Conference on Machine Learning (ICML) , page 3319–3328, 2017. 1, 4
work page 2017
- [52]
- [53]
- [54]
-
[55]
Learning bottleneck concepts in image classifica- tion
Bowen Wang, Liangzhi Li, Y uta Nakashima, and Hajime Na- gahara. Learning bottleneck concepts in image classifica- tion. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 10962– 10971, 2023. 2
work page 2023
-
[56]
Score-cam: Score-weighted visual explanations for convolutional neu ral networks
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neu ral networks. In Proceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR) W orkshops , pages 111–119, 2020. 5
work page 2020
-
[57]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan , Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Y ue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19187–19197, 2023. 2, 5
work page 2023
-
[59]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shech t- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 586–595, 2018. 7
work page 2018
-
[60]
Ruihan Zhang, Prashan Madumal, Tim Miller, Krista A. Ehinger, and Benjamin I. P . Rubinstein. Invertible concept - based explanations for CNN models with non-negative con- cept activation vectors. In Proceedings of the AAAI Confer- ence on Artificial Intelligence , 2021. 2 11 Zero-Shot Textual Explanations via Translating Decision-Critical Features Supplem...
work page 2021
-
[61]
on the same dataset used to train each classifier (e.g., ImageNet) with batch size 1024, learning rate 5 × 10− 4, and the Adam optimizer for 10 epochs. A.2. Details of concept bank construction We use an LLM and a VLM to generate the concept bank B(x, c ). Below, we describe the prompts used for each model. The LLM is utilized to generate concepts that are...
-
[62]
Generate GENERAL concepts that can apply to many different photos of the same object type
-
[65]
DO NOT include class names or object names directly. Q: What are useful visual features for distinguishing a lemur in a photo? A: There are several useful visual features to tell there is a lemur in a photo: - long tail - large eyes - gray fur - trees - branches - forest Q: What are useful features for distinguishing a {class_name} in a photo? Already gen...
-
[66]
Generate DETAILED and SPECIFIC concepts that can apply to this image
-
[67]
Include both OBJECT features (e.g., shape, color, parts) AND CONTEXT features (e.g., background, environment, setting)
-
[68]
Keep concepts short and specific (1-3 words)
-
[69]
a photo of {class name} show- ing T ,
DO NOT include class names or object names directly. Examples: Q: Look at this image carefully. Based on what you can actually see in the image, identify useful visual features that help distinguish this as a koi fish. A: There are several useful visual features to tell there is a koi fish in a photo: - bright orange scales - curved tail fin - spotted pat...
-
[70]
As expected, Text-To-Concept achieves the best performance across all models, which is consistent with its design: it aligns global image features with text and is intended to describe the input image itself. These results therefore complement Tabs. 2 and 3: while Text-To-Concept is better aligned with the input images, the proposed method provides explan...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.