Recognition: 2 theorem links
· Lean TheoremPrismatic World Model: Learning Compositional Dynamics for Planning in Hybrid Systems
Pith reviewed 2026-05-17 00:32 UTC · model grok-4.3
The pith
A context-aware mixture of experts decomposes hybrid robot dynamics into distinct modes to reduce rollout drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PRISM-WM decomposes complex hybrid dynamics into composable primitives using a context-aware Mixture-of-Experts framework where a gating mechanism implicitly identifies the current physical mode and specialized experts predict the associated transition dynamics, with a latent orthogonalization objective ensuring expert diversity and thereby reducing rollout drift for trajectory optimization.
What carries the argument
Context-aware Mixture-of-Experts with implicit gating network and latent orthogonalization objective that routes predictions to mode-specific experts.
If this is right
- Trajectory optimization algorithms receive higher-fidelity long-horizon predictions at physical boundaries.
- High-dimensional humanoid control tasks exhibit lower compounding error during planning.
- Multi-task continuous-control settings benefit from reusable mode-specific dynamics without collapse.
- Model-based agents gain a more reliable substrate for search at contact-rich transitions.
Where Pith is reading between the lines
- The same gating-plus-orthogonalization pattern could extend to other piecewise-smooth physical systems such as fluid-structure interactions.
- Learned mode separation may increase interpretability of contact events compared with fully black-box predictors.
- Planners could jointly optimize discrete mode choice and continuous actions inside the same latent space.
Load-bearing premise
An implicit gating mechanism can reliably identify distinct physical modes from context alone and the latent orthogonalization objective will prevent mode collapse without explicit mode labels or additional regularization.
What would settle it
Ablating the orthogonalization objective and checking whether expert predictions converge to identical behavior while rollout error on the humanoid benchmarks rises to match a monolithic baseline.
Figures




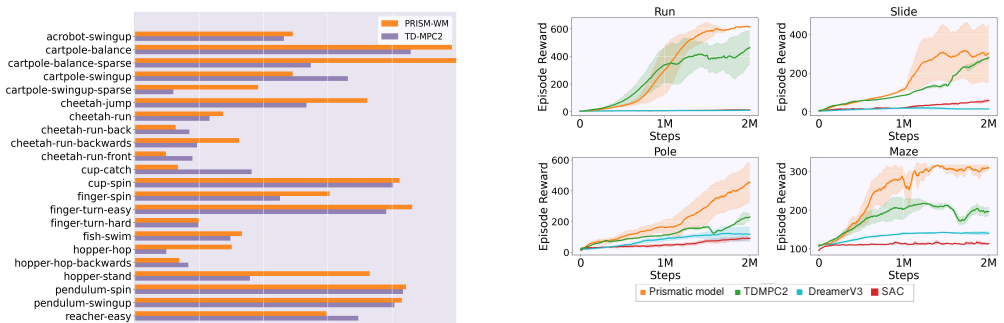





read the original abstract
Model-based planning in robotic domains is challenged by the hybrid nature of physical dynamics, where continuous motion is punctuated by discrete events such as contacts and impacts. Conventional latent world models typically employ monolithic neural networks that enforce global continuity, which over-smooths distinct dynamic modes (e.g., sticking vs. sliding, flight vs. stance). For a planner, this smoothing results in compounding errors during long-horizon lookaheads, rendering the search process unreliable at physical boundaries. To address this, we introduce the Prismatic World Model (PRISM-WM), a structured architecture designed to decompose complex hybrid dynamics into composable primitives. PRISM-WM uses a context-aware Mixture-of-Experts (MoE) framework where a gating mechanism implicitly identifies the current physical mode, and specialized experts predict the associated transition dynamics. We further introduce a latent orthogonalization objective to ensure expert diversity, preventing mode collapse. By modeling the mode transitions in system dynamics, PRISM-WM reduces rollout drift. Experiments on continuous control benchmarks, including high-dimensional humanoids and multi-task settings, demonstrate that PRISM-WM provides a high-fidelity substrate for trajectory optimization algorithms (e.g., TD-MPC), indicating its potential as a foundational model for model-based agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Prismatic World Model (PRISM-WM), a context-aware Mixture-of-Experts architecture for learning compositional dynamics in hybrid robotic systems. It uses an implicit gating mechanism to identify physical modes (e.g., contact vs. flight) and a latent orthogonalization objective to ensure expert diversity and prevent collapse, claiming that this reduces rollout drift and yields a higher-fidelity world model for trajectory optimization algorithms such as TD-MPC on continuous control benchmarks including high-dimensional humanoids and multi-task settings.
Significance. If the central claims hold with supporting evidence, the work would represent a meaningful step toward reliable long-horizon model-based planning in domains with discrete events, by explicitly addressing the limitations of monolithic latent dynamics models. The unsupervised decomposition of hybrid dynamics via MoE gating and orthogonalization, if shown to produce physically meaningful modes, could serve as a useful primitive for scalable robotics agents.
major comments (3)
- Abstract: the claims that PRISM-WM 'reduces rollout drift' and 'provides a high-fidelity substrate for trajectory optimization' are stated without any quantitative metrics, ablation results, error bars, or specific benchmark numbers, leaving the magnitude and reliability of the improvement unsupported in the provided text.
- Method section (description of context-aware MoE and latent orthogonalization): the manuscript does not provide evidence that the gating decisions align with ground-truth discrete events or that the orthogonalization objective enforces separation into physically distinct modes rather than arbitrary or collapsed partitions; without such verification the drift-reduction claim rests on an untested assumption about implicit mode discovery.
- Experiments section (humanoid and multi-task results): performance gains are attributed to mode modeling, yet no ablation isolating the gating/orthogonalization components from the simple increase in model capacity (number of experts) is reported, making it impossible to rule out that improvements arise from extra parameters rather than reduced compounding error at mode boundaries.
minor comments (2)
- Clarify the precise formulation of the latent orthogonalization loss (e.g., its mathematical definition and weighting relative to the dynamics prediction loss) to allow reproducibility.
- Add a figure or table showing example gating decisions overlaid on ground-truth mode switches for at least one benchmark environment.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of clarity and evidence that we will address in revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: Abstract: the claims that PRISM-WM 'reduces rollout drift' and 'provides a high-fidelity substrate for trajectory optimization' are stated without any quantitative metrics, ablation results, error bars, or specific benchmark numbers, leaving the magnitude and reliability of the improvement unsupported in the provided text.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. The full manuscript reports these results in Section 4 (e.g., rollout MSE reductions and TD-MPC success rates with standard errors across seeds). We will revise the abstract to include the key numerical improvements and error-bar information. revision: yes
-
Referee: Method section (description of context-aware MoE and latent orthogonalization): the manuscript does not provide evidence that the gating decisions align with ground-truth discrete events or that the orthogonalization objective enforces separation into physically distinct modes rather than arbitrary or collapsed partitions; without such verification the drift-reduction claim rests on an untested assumption about implicit mode discovery.
Authors: The experiments section already contains qualitative visualizations demonstrating that gating activations align with observable physical events (e.g., contact vs. flight phases). The orthogonalization loss is ablated and shown to reduce expert collapse while improving mode-specific prediction accuracy. Direct per-timestep ground-truth mode labels are not available for every benchmark; however, we will add quantitative correlation analysis between learned gates and known discrete events (such as foot-contact sensors) in the revised version. revision: partial
-
Referee: Experiments section (humanoid and multi-task results): performance gains are attributed to mode modeling, yet no ablation isolating the gating/orthogonalization components from the simple increase in model capacity (number of experts) is reported, making it impossible to rule out that improvements arise from extra parameters rather than reduced compounding error at mode boundaries.
Authors: This is a fair criticism. While we vary the number of experts and compare against monolithic baselines, we do not explicitly match total parameter count between PRISM-WM and a capacity-augmented single-expert model. We will add this controlled ablation in the revised experiments section to isolate the contribution of the compositional structure. revision: yes
Circularity Check
No circularity: architecture and loss are defined independently of claimed performance gains
full rationale
The paper defines PRISM-WM as a context-aware MoE with an added latent orthogonalization objective, then trains the full model end-to-end on observed trajectories. The central claim (reduced rollout drift from mode decomposition) is evaluated via downstream planning experiments rather than being recovered by construction from any fitted parameter or self-citation. No equation equates a prediction to an input by definition, and no uniqueness theorem or ansatz is smuggled via prior self-work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of experts
axioms (1)
- domain assumption Specialized sub-networks can capture distinct dynamic regimes when selected by context
invented entities (1)
-
latent orthogonalization objective
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we apply the Gram-Schmidt process to this set of vectors for each sample in the batch. Ideally U_s lies on the Stiefel manifold: U^T_s U_s = I_k
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
the gating network acts as a context-aware switching mechanism to identify the active physical regime
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Soft Actor-Critic Algorithms and Applications
Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905. Hafner, D.; Lillicrap, T.; Ba, J.; and Norouzi, M. 2019a. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603. Hafner, D.; Lillicrap, T.; Norouzi, M.; and Ba, J. 2019b. Learning Latent Dynamics for Planning from Pixels. InPro- ceedings of...
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[2]
InAdvances in Neural Information Pro- cessing Systems, volume 28, 2944–2952
Learning Continuous Control Policies by Stochastic Value Gradients. InAdvances in Neural Information Pro- cessing Systems, volume 28, 2944–2952. Hendawy, A.; Peters, J.; and D’Eramo, C. 2023. Multi-task reinforcement learning with mixture of orthogonal experts. arXiv preprint arXiv:2311.11385. Jacobs, R. A.; Jordan, M. I.; Nowlan, S. J.; and Hinton, G. E
-
[3]
Janner, M.; Fu, J.; Zhang, M.; and Levine, S
Adaptive mixtures of local experts.Neural computa- tion, 3(1): 79–87. Janner, M.; Fu, J.; Zhang, M.; and Levine, S. 2019. When to trust your model: Model-based policy optimization.Ad- vances in neural information processing systems, 32. Jim´enez, S.; De La Rosa, T.; Fern ´andez, S.; Fern ´andez, F.; and Borrajo, D. 2012. A review of machine learning for a...
-
[4]
Tassa, Y .; Doron, Y .; Muldal, A.; Erez, T.; Li, Y .; Casas, D
Humanoidbench: Simulated humanoid benchmark for whole-body locomotion and manipulation.arXiv preprint arXiv:2403.10506. Tassa, Y .; Doron, Y .; Muldal, A.; Erez, T.; Li, Y .; Casas, D. d. L.; Budden, D.; Abdolmaleki, A.; Merel, J.; Lefrancq, A.; et al. 2018. Deepmind control suite.arXiv preprint arXiv:1801.00690. Wang, H.; Li, X.; and Ma, L. 2022. Expert-...
-
[5]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
MoDem: Mixture-of-Dynamics Experts for Meta- Reinforcement Learning. InInternational Conference on Learning Representations. Zoph, B.; Shazeer, N.; Feder, A.; Ren, T.; and ... 2022. De- signing Effective Sparse Expert Models.arXiv preprint arXiv:2202.08906. A Expert Specialization Analysis To further analyze the composition of different experts across var...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.