Recognition: 1 theorem link
· Lean TheoremBenchmarking Real-World Medical Image Classification with Noisy Labels: Challenges, Practice, and Outlook
Pith reviewed 2026-05-16 23:53 UTC · model grok-4.3
The pith
Existing methods for learning from noisy labels lose much of their effectiveness on real medical images under high noise and domain shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
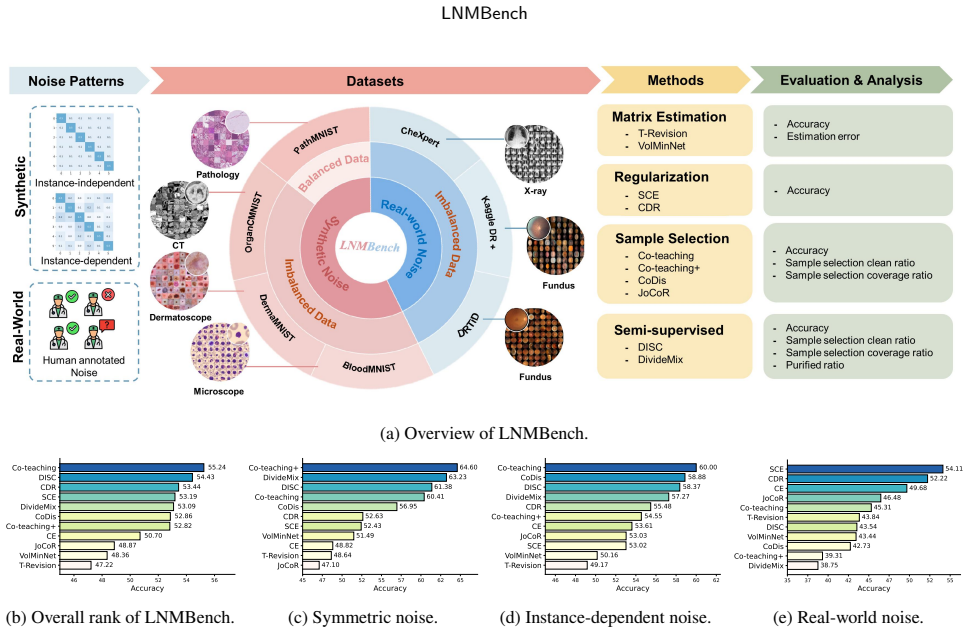
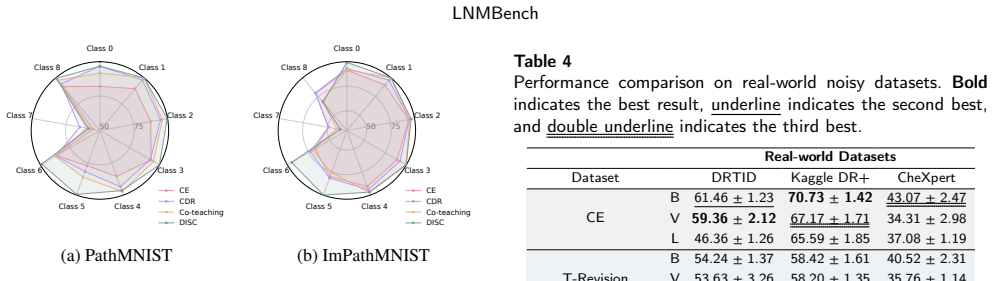
The paper establishes that existing learning with noisy labels methods degrade substantially under high and real-world noise in medical image classification, with class imbalance and domain variability posing persistent challenges. It introduces LNMBench as a unified framework evaluating ten representative methods across seven datasets, six modalities, and three noise patterns, and proposes a simple yet effective improvement to enhance model robustness under these conditions.
What carries the argument
LNMBench, a benchmark framework that applies ten LNL methods to seven medical datasets spanning six modalities with three noise patterns to assess robustness under realistic conditions.
If this is right
- Existing LNL methods show substantial performance degradation under high and real-world noise.
- Class imbalance and domain variability remain persistent challenges for noise-resilient algorithms in medical data.
- A simple yet effective improvement can enhance model robustness under high noise and domain variability.
- Public release of the LNMBench codebase supports standardized evaluation and reproducible research.
Where Pith is reading between the lines
- Future noisy label methods would likely benefit from built-in handling for medical domain shifts between equipment and sites.
- Extending the benchmark to cover real multi-expert annotation disagreements could provide a closer match to clinical label noise.
- Hybrid approaches that pair noise correction with domain adaptation techniques may offer a practical next step for medical applications.
Load-bearing premise
The seven datasets, six modalities, and three noise patterns chosen for the benchmark adequately represent the annotation inconsistencies and domain shifts encountered in real clinical practice.
What would settle it
Running the same ten methods plus the proposed improvement on a new medical dataset with independently measured high real-world noise from multiple observers and observing no substantial degradation would challenge the reported performance drops.
Figures








read the original abstract
Learning from noisy labels remains a major challenge in medical image analysis, where annotation demands expert knowledge and substantial inter-observer variability often leads to inconsistent or erroneous labels. Despite extensive research on learning with noisy labels (LNL), the robustness of existing methods in medical imaging has not been systematically assessed. To address this gap, we introduce LNMBench, a comprehensive benchmark for Label Noise in Medical imaging. LNMBench encompasses \textbf{10} representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns, establishing a unified and reproducible framework for robustness evaluation under realistic conditions. Comprehensive experiments reveal that the performance of existing LNL methods degrades substantially under high and real-world noise, highlighting the persistent challenges of class imbalance and domain variability in medical data. Motivated by these findings, we further propose a simple yet effective improvement to enhance model robustness under such conditions. The LNMBench codebase is publicly released to facilitate standardized evaluation, promote reproducible research, and provide practical insights for developing noise-resilient algorithms in both research and real-world medical applications.The codebase is publicly available on https://github.com/myyy777/LNMBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LNMBench, a benchmark for assessing the robustness of learning with noisy labels (LNL) methods in medical image classification. It evaluates 10 LNL methods on 7 datasets across 6 modalities using 3 noise patterns, reports substantial performance degradation under high and real-world noise levels, highlights challenges from class imbalance and domain variability, proposes a simple improvement, and releases the codebase publicly.
Significance. If the benchmark's noise patterns and dataset selection prove representative, the work offers a valuable standardized framework for evaluating LNL methods in medical imaging, where annotation noise is common. The public codebase release is a clear strength that supports reproducibility and future research. The findings on degradation could inform more resilient algorithm design, though their impact depends on how closely the evaluated conditions match clinical practice.
major comments (2)
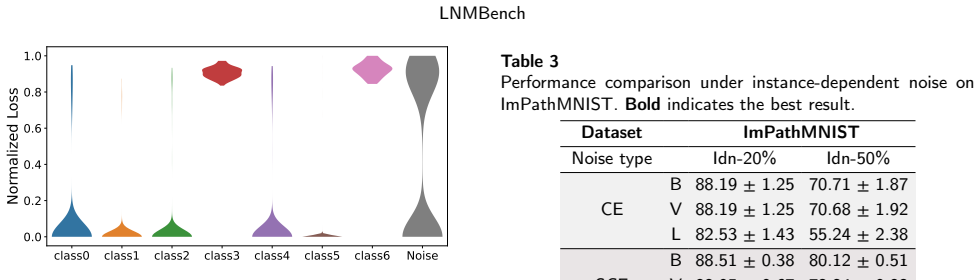
- [Section 4] Section 4 (Noise Patterns): The manuscript must explicitly state whether the 3 noise patterns are generated synthetically (e.g., symmetric/asymmetric/instance-dependent label flips) or derived from multi-rater annotations or observed inter-observer inconsistencies within the 7 datasets. This detail is load-bearing for the central claim of evaluating under 'real-world noise' in the title and abstract; without it, the observed degradation may not generalize to clinical annotation variability.
- [Results] Results section (implied by abstract claims): The comprehensive experiments are described as revealing 'substantial' degradation, yet the manuscript lacks specific quantitative tables, accuracy drops with standard deviations, or ablation isolating synthetic vs. observed noise. This weakens the ability to assess the magnitude and statistical reliability of the headline result on existing LNL methods.
minor comments (2)
- [Abstract] Abstract: The phrase 'simple yet effective improvement' is used without a brief derivation or pseudocode; adding one sentence on its core mechanism would improve clarity without altering scope.
- The claim of '6 imaging modalities' and '7 datasets' should include a short table or appendix listing the exact datasets, modalities, and class imbalance statistics to aid readers in assessing representativeness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the clarity and impact of our work on LNMBench. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Noise Patterns): The manuscript must explicitly state whether the 3 noise patterns are generated synthetically (e.g., symmetric/asymmetric/instance-dependent label flips) or derived from multi-rater annotations or observed inter-observer inconsistencies within the 7 datasets. This detail is load-bearing for the central claim of evaluating under 'real-world noise' in the title and abstract; without it, the observed degradation may not generalize to clinical annotation variability.
Authors: We appreciate this important clarification request. The three noise patterns described in Section 4 are synthetically generated using standard models (symmetric, asymmetric, and instance-dependent label noise) with parameters chosen to reflect typical annotation error patterns reported in medical imaging literature on inter-observer variability. They are not directly derived from multi-rater annotations or observed inconsistencies within the specific 7 datasets. We will revise Section 4 to explicitly detail the synthetic generation procedure, including exact flip probabilities and instance-dependent mechanisms, and add a discussion on how these patterns approximate real-world clinical noise while noting the limitations for direct generalization. This will better support the claims regarding real-world noise in the title and abstract. revision: yes
-
Referee: [Results] Results section (implied by abstract claims): The comprehensive experiments are described as revealing 'substantial' degradation, yet the manuscript lacks specific quantitative tables, accuracy drops with standard deviations, or ablation isolating synthetic vs. observed noise. This weakens the ability to assess the magnitude and statistical reliability of the headline result on existing LNL methods.
Authors: We agree that enhanced quantitative detail would improve interpretability. The Results section currently summarizes the degradation trends across the 10 methods, 7 datasets, and 3 noise patterns, but we will expand it with new tables reporting per-method accuracy drops (with standard deviations over multiple runs) under varying noise levels. For the requested ablation, we will add a comparison where feasible using any available multi-rater subsets in the datasets; in cases where observed noise data is unavailable, we will explicitly discuss this as a limitation and suggest it as future work. These additions will provide clearer evidence for the magnitude and reliability of the findings. revision: partial
- A full ablation isolating synthetic noise from observed multi-rater noise is not possible across all 7 datasets without new data collection, which exceeds the scope of this benchmarking study.
Circularity Check
No significant circularity in empirical benchmarking study
full rationale
The paper introduces LNMBench as an empirical evaluation framework and reports performance degradation of existing LNL methods based on new runs across 7 public datasets, 6 modalities, and 3 noise patterns. No mathematical derivation chain exists; claims rest on direct experimental observations rather than quantities defined from fitted parameters, self-referential definitions, or load-bearing self-citations. The proposed improvement is motivated by the benchmark results but does not reduce to a tautology by construction. This is a standard empirical benchmarking paper whose central results are independently falsifiable via the released codebase and public data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The chosen 7 datasets and 3 noise patterns capture realistic medical annotation variability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce LNMBench... 10 representative methods evaluated across 7 datasets, 6 imaging modalities, and 3 noise patterns... performance of existing LNL methods degrades substantially under high and real-world noise
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chen,M.,Cheng,H.,Du,Y.,Xu,M.,Jiang,W.,Wang,C.,2023. Two wrongs don’t make a right: Combating confirmation bias in learning withlabelnoise,in:ProceedingsoftheAAAIConferenceonArtificial Intelligence, pp. 14765–14773
work page 2023
-
[2]
Chen, P., Liao, B.B., Chen, G., Zhang, S., 2019. Understanding and utilizing deep neural networks trained with noisy labels, in: International conference on machine learning, PMLR. pp. 1062– 1070
work page 2019
-
[3]
Cordeiro, F.R., Carneiro, G., 2020. A survey on deep learning with noisy labels: How to train your model when you cannot trust on the annotations?, in: 2020 33rd SIBGRAPI conference on graphics, patterns and images (SIBGRAPI), IEEE. pp. 9–16
work page 2020
-
[4]
Dgani, Y., Greenspan, H., Goldberger, J., 2018. Training a neural network based on unreliable human annotation of medical images, in: 2018 IEEE 15th International symposium on biomedical imaging (ISBI 2018), IEEE. pp. 39–42
work page 2018
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy,A.,2020. Animageisworth16x16words:Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Gehlot, S., Gupta, A., Gupta, R., 2021. A cnn-based unified frame- work utilizing projection loss in unison with label noise handling for multiple myeloma cancer diagnosis. Medical Image Analysis 72, 102099
work page 2021
-
[7]
Ghesu, F.C., Georgescu, B., Gibson, E., Guendel, S., Kalra, M.K., Singh, R., Digumarthy, S.R., Grbic, S., Comaniciu, D., 2019. Quan- tifying and leveraging classification uncertainty for chest radiograph assessment,in:Internationalconferenceonmedicalimagecomputing and computer-assisted intervention, Springer. pp. 676–684
work page 2019
-
[8]
Gutbrod,M.,Rauber,D.,Nunes,D.W.,Palm,C.,2025. Openmibood: Open medical imaging benchmarks for out-of-distribution detection, in: Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 25874–25886
work page 2025
-
[9]
Co-teaching:Robusttrainingofdeepneuralnetworkswith extremely noisy labels
Han,B.,Yao,Q.,Yu,X.,Niu,G.,Xu,M.,Hu,W.,Tsang,I.,Sugiyama, M.,2018. Co-teaching:Robusttrainingofdeepneuralnetworkswith extremely noisy labels. Advances in neural information processing systems 31
work page 2018
-
[10]
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
work page 2016
-
[11]
Hendrycks, D., Lee, K., Mazeika, M., 2019. Using pre-training can improve model robustness and uncertainty, in: International confer- ence on machine learning, PMLR. pp. 2712–2721
work page 2019
-
[12]
Qmix: Quality-aware learning with mixed noise for robust retinal disease diagnosis
Hou, J., Xu, J., Feng, R., Chen, H., 2025. Qmix: Quality-aware learning with mixed noise for robust retinal disease diagnosis. IEEE Transactions on Medical Imaging
work page 2025
-
[13]
Hou,J.,Xu,J.,Xiao,F.,Zhao,R.W.,Zhang,Y.,Zou,H.,Lu,L.,Xue, W., Feng, R., 2022. Cross-field transformer for diabetic retinopathy gradingontwo-fieldfundusimages,in:2022IEEEInternationalCon- ferenceonBioinformaticsandBiomedicine(BIBM),IEEEComputer Society. pp. 985–990. Yuan Ma et al.:Preprint submitted to ElsevierPage 14 of 15 LNMBench
work page 2022
-
[14]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Johnson,A.E.,Pollard,T.J.,Greenbaum,N.R.,Lungren,M.P.,Deng, C.y., Peng, Y., Lu, Z., Mark, R.G., Berkowitz, S.J., Horng, S., 2019. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs. arXiv preprint arXiv:1901.07042
work page internal anchor Pith review arXiv 2019
-
[15]
Improving medical images classification with label noise using dual-uncertainty estimation
Ju, L., Wang, X., Wang, L., Mahapatra, D., Zhao, X., Zhou, Q., Liu, T., Ge, Z., 2022. Improving medical images classification with label noise using dual-uncertainty estimation. IEEE transactions on medical imaging 41, 1533–1546
work page 2022
-
[16]
Monica: Benchmarking on long-tailed medical image classification
Ju, L., Yan, S., Zhou, Y., Nan, Y., Xing, X., Duan, P., Ge, Z., 2024. Monica: Benchmarking on long-tailed medical image classification. arXiv preprint arXiv:2410.02010
-
[17]
Ju, L., Yu, Z., Wang, L., Zhao, X., Wang, X., Bonnington, P., Ge, Z.,
-
[18]
IEEETransactionsonMedicalImaging43,335– 350
Hierarchical knowledge guided learning for real-world retinal diseaserecognition. IEEETransactionsonMedicalImaging43,335– 350
-
[19]
Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis
Karimi, D., Dou, H., Warfield, S.K., Gholipour, A., 2020. Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis. Medical image analysis 65, 101759
work page 2020
-
[20]
Khanal, B., Bhattarai, B., Khanal, B., Linte, C.A., 2023. Improving medicalimageclassificationinnoisylabelsusingonlyself-supervised pretraining, in: MICCAI Workshop on Data Engineering in Medical Imaging, Springer. pp. 78–90
work page 2023
-
[21]
Ko, J., Yi, B., Yun, S.Y., 2023. A gift from label smoothing: robust training with adaptive label smoothing via auxiliary classifier under label noise, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 8325–8333
work page 2023
-
[22]
Li,J.,Cao,H.,Wang,J.,Liu,F.,Dou,Q.,Chen,G.,Heng,P.A.,2023a. Learning robust classifier for imbalanced medical image dataset with noisylabelsbyminimizinginvariantrisk,in:InternationalConference on Medical Image Computing and Computer-Assisted Intervention, Springer. pp. 306–316
-
[23]
Dividemix: Learning with noisy labelsassemi-supervisedlearning
Li, J., Socher, R., Hoi, S.C., 2020. Dividemix: Learning with noisy labelsassemi-supervisedlearning. arXivpreprintarXiv:2002.07394
-
[24]
Li, X., Liu, T., Han, B., Niu, G., Sugiyama, M., 2021. Provably end- to-end label-noise learning without anchor points, in: International conference on machine learning, PMLR. pp. 6403–6413
work page 2021
-
[25]
Li, Y., Han, H., Shan, S., Chen, X., 2023b. Disc: Learning from noisy labels via dynamic instance-specific selection and correction, in:ProceedingsoftheIEEE/CVFconferenceoncomputervisionand pattern recognition, pp. 24070–24079
-
[26]
Instance-dependent label distribution estimation for learning with label noise
Liao, Z., Hu, S., Xie, Y., Xia, Y., 2025a. Instance-dependent label distribution estimation for learning with label noise. International Journal of Computer Vision 133, 2568–2580
-
[27]
Liao, Z., Hu, S., Zhang, Y., Xia, Y., 2025b. Unleashing the potential of open-set noisy samples against label noise for medical image classification. Medical Image Analysis , 103702
-
[28]
Learning the latent causal structure formodelinglabelnoise
Lin, Y., Yao, Y., Liu, T., 2024. Learning the latent causal structure formodelinglabelnoise. AdvancesinNeuralInformationProcessing Systems 37, 120549–120577
work page 2024
-
[29]
Litjens, G., Kooi, T., Bejnordi, B.E., Setio, A.A.A., Ciompi, F., Ghafoorian,M.,VanDerLaak,J.A.,VanGinneken,B.,Sánchez,C.I.,
-
[30]
Medical image analysis 42, 60–88
A survey on deep learning in medical image analysis. Medical image analysis 42, 60–88
- [31]
-
[32]
Does label smoothing mitigate label noise?, in: International Conference on Machine Learning, PMLR
Lukasik, M., Bhojanapalli, S., Menon, A., Kumar, S., 2020. Does label smoothing mitigate label noise?, in: International Conference on Machine Learning, PMLR. pp. 6448–6458
work page 2020
-
[33]
Mehrtens, H.A., Kurz, A., Bucher, T.C., Brinker, T.J., 2023. Bench- marking common uncertainty estimation methods with histopatho- logical images under domain shift and label noise. Medical image analysis 89, 102914
work page 2023
-
[34]
The multimodal brain tumor image segmentation benchmark (brats)
Menze,B.H.,Jakab,A.,Bauer,S.,Kalpathy-Cramer,J.,Farahani,K., Kirby, J., Burren, Y., Porz, N., Slotboom, J., Wiest, R., et al., 2014. The multimodal brain tumor image segmentation benchmark (brats). IEEE transactions on medical imaging 34, 1993–2024
work page 2014
-
[35]
Self: Learning to filter noisy labels with self- ensembling
Nguyen,D.T.,Mummadi,C.K.,Ngo,T.P.N.,Nguyen,T.H.P.,Beggel, L., Brox, T., 2019. Self: Learning to filter noisy labels with self- ensembling. arXiv preprint arXiv:1910.01842
-
[36]
Pham, H.H., Le, T.T., Tran, D.Q., Ngo, D.T., Nguyen, H.Q., 2021. Interpreting chest x-rays via cnns that exploit hierarchical disease dependenciesanduncertaintylabels. Neurocomputing437,186–194
work page 2021
-
[37]
Asurveyof label-noise deep learning for medical image analysis
Shi,J.,Zhang,K.,Guo,C.,Yang,Y.,Xu,Y.,Wu,J.,2024. Asurveyof label-noise deep learning for medical image analysis. Medical image analysis 95, 103166
work page 2024
-
[38]
Shin, H.C., Roth, H.R., Gao, M., Lu, L., Xu, Z., Nogues, I., Yao, J., Mollura, D., Summers, R.M., 2016. Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning. IEEE transactions on medical imaging 35, 1285–1298
work page 2016
-
[39]
Training Convolutional Networks with Noisy Labels
Sukhbaatar, S., Bruna, J., Paluri, M., Bourdev, L., Fergus, R., 2014. Training convolutional networks with noisy labels. arXiv preprint arXiv:1406.2080
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
Tanno,R.,Saeedi,A.,Sankaranarayanan,S.,Alexander,D.C.,Silber- man, N., 2019. Learning from noisy labels by regularized estimation of annotator confusion, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11244–11253
work page 2019
-
[41]
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.,
- [42]
-
[43]
Wang,Y.,Ma,X.,Chen,Z.,Luo,Y.,Yi,J.,Bailey,J.,2019. Symmet- riccrossentropyforrobustlearningwithnoisylabels,in:Proceedings of the IEEE/CVF international conference on computer vision, pp. 322–330
work page 2019
-
[44]
Wei, H., Feng, L., Chen, X., An, B., 2020. Combating noisy labels by agreement: A joint training method with co-regularization, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13726–13735
work page 2020
-
[45]
Learning with noisy labels revisited: A study using real-world human annota- tions
Wei, J., Zhu, Z., Cheng, H., Liu, T., Niu, G., Liu, Y., 2021. Learning with noisy labels revisited: A study using real-world human annota- tions. arXiv preprint arXiv:2110.12088
-
[46]
Xia, X., Han, B., Zhan, Y., Yu, J., Gong, M., Gong, C., Liu, T.,
- [47]
-
[48]
Xia, X., Liu, T., Han, B., Gong, C., Wang, N., Ge, Z., Chang, Y., 2020a. Robust early-learning: Hindering the memorization of noisy labels, in: International conference on learning representations
-
[49]
Part-dependent label noise: Towards instance-dependent label noise
Xia, X., Liu, T., Han, B., Wang, N., Gong, M., Liu, H., Niu, G., Tao, D., Sugiyama, M., 2020b. Part-dependent label noise: Towards instance-dependent label noise. Advances in neural information processing systems 33, 7597–7610
-
[50]
Xia,X.,Liu,T.,Wang,N.,Han,B.,Gong,C.,Niu,G.,Sugiyama,M.,
-
[51]
Areanchorpointsreallyindispensableinlabel-noiselearning? Advances in neural information processing systems 32
-
[52]
Xue,C.,Dou,Q.,Shi,X.,Chen,H.,Heng,P.A.,2019.Robustlearning atnoisylabeledmedicalimages:Appliedtoskinlesionclassification, in: 2019 IEEE 16th International symposium on biomedical imaging (ISBI 2019), IEEE. pp. 1280–1283
work page 2019
-
[53]
Yang,J.,Shi,R.,Wei,D.,Liu,Z.,Zhao,L.,Ke,B.,Pfister,H.,Ni,B.,
-
[54]
Medmnist v2-a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data 10, 41
-
[55]
Yu, X., Han, B., Yao, J., Niu, G., Tsang, I., Sugiyama, M., 2019. Howdoesdisagreementhelpgeneralizationagainstlabelcorruption?, in: International conference on machine learning, PMLR. pp. 7164– 7173
work page 2019
-
[56]
Zhou, T., Wang, S., Bilmes, J., 2020. Robust curriculum learning: from clean label detection to noisy label self-correction, in: Interna- tional conference on learning representations. Yuan Ma et al.:Preprint submitted to ElsevierPage 15 of 15
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.