Recognition: 2 theorem links
· Lean TheoremSample-wise Adaptive Weighting for Transfer Consistency in Adversarial Distillation
Pith reviewed 2026-05-16 23:47 UTC · model grok-4.3
The pith
Reweighting distillation samples by adversarial transferability yields more robust student networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
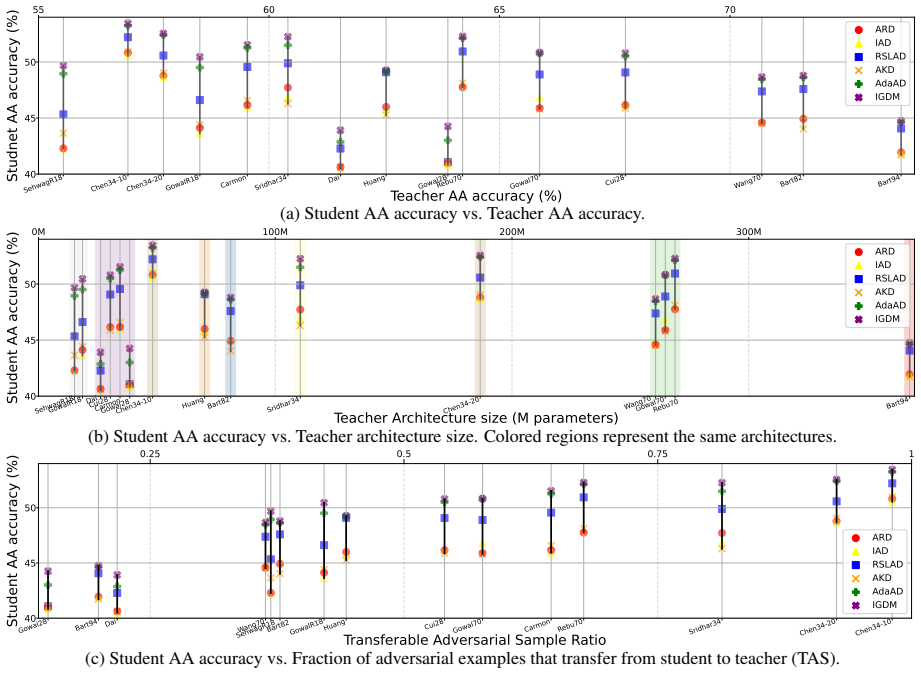
The central discovery is that adversarial transferability, defined as the fraction of student-generated adversarial examples that remain effective against the teacher, is a crucial factor for successful robustness transfer. Based on this, SAAD reweights training examples sample-wise by their transferability to enhance consistency in adversarial distillation.
What carries the argument
Sample-wise Adaptive Adversarial Distillation (SAAD), which measures and uses adversarial transferability to reweight training samples during distillation.
If this is right
- Stronger teachers can now be used more effectively in distillation without saturation limiting gains.
- Student robustness improves consistently across CIFAR-10, CIFAR-100, and Tiny-ImageNet under AutoAttack.
- Training can incorporate state-of-the-art robust teachers more reliably.
- The method adds no computational overhead beyond standard adversarial training.
Where Pith is reading between the lines
- Transferability could serve as a general signal for adjusting training dynamics in other robustness methods.
- If transferability varies during training, dynamically updating weights might further enhance results.
- Applying similar weighting in non-adversarial distillation might improve other transfer tasks.
Load-bearing premise
Adversarial transferability measured on the current student acts as a stable and causal driver of final robustness rather than merely correlating with other training factors.
What would settle it
An experiment where samples are reweighted by transferability but the resulting student shows no improvement or degradation in AutoAttack robustness compared to unweighted distillation would falsify the claim.
Figures



read the original abstract
Adversarial distillation in the standard min-max adversarial training framework aims to transfer adversarial robustness from a large, robust teacher network to a compact student. However, existing work often neglects to incorporate state-of-the-art robust teachers. Through extensive analysis, we find that stronger teachers do not necessarily yield more robust students-a phenomenon known as robust saturation. While typically attributed to capacity gaps, we show that such explanations are incomplete. Instead, we identify adversarial transferability-the fraction of student-crafted adversarial examples that remain effective against the teacher-as a key factor in successful robustness transfer. Based on this insight, we propose Sample-wise Adaptive Adversarial Distillation (SAAD), which reweights training examples by their measured transferability without incurring additional computational cost. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet show that SAAD consistently improves AutoAttack robustness over prior methods. Our code is available at https://github.com/HongsinLee/saad.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Sample-wise Adaptive Adversarial Distillation (SAAD) to address robust saturation in adversarial distillation, where stronger teachers do not always produce more robust students. It identifies adversarial transferability—the fraction of student-generated adversarial examples that fool the teacher—as a key factor beyond capacity mismatch, and introduces a reweighting scheme for the distillation loss based on this quantity computed on-the-fly from existing PGD attacks. Experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet are reported to show consistent AutoAttack robustness gains over prior methods at no extra cost.
Significance. If the gains are shown to arise specifically from transferability rather than correlated sample properties, the approach would provide a practical, zero-overhead improvement to adversarial distillation pipelines for compact robust models.
major comments (2)
- [§4] §4 (Experiments): The reported improvements over baselines lack an ablation that substitutes an equivalent non-transferability signal (e.g., reweighting by per-sample loss or gradient norm from the same PGD attacks) to test whether gains vanish, leaving open the possibility that SAAD is a proxy for known difficulty-based reweighting rather than a causal driver of transfer consistency.
- [§3.2] §3.2 (Method): The transferability definition is an observable computed directly from student-teacher agreement on adversarial examples; the manuscript provides no analysis (e.g., correlation tables or controlled substitution experiments) demonstrating that this quantity is not reducible to standard hardness metrics already known to affect robust training dynamics.
minor comments (2)
- [Abstract] Abstract: The claim of 'consistent improvements' is stated without any numerical deltas, baseline names, or statistical details, making it difficult to assess the practical magnitude of the contribution from the summary alone.
- [§4.1] §4.1: Robustness metrics are presented without reporting standard deviations across multiple random seeds or formal statistical tests, which is needed to support the 'consistently improves' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contribution of transferability in adversarial distillation. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported improvements over baselines lack an ablation that substitutes an equivalent non-transferability signal (e.g., reweighting by per-sample loss or gradient norm from the same PGD attacks) to test whether gains vanish, leaving open the possibility that SAAD is a proxy for known difficulty-based reweighting rather than a causal driver of transfer consistency.
Authors: We agree that an explicit ablation isolating transferability from standard difficulty signals would strengthen the causal claim. In the revised manuscript we will add this ablation: using the identical PGD attacks already computed for SAAD, we will reweight samples by (i) per-sample adversarial loss and (ii) gradient norm, then compare AutoAttack robustness against the original transferability weighting. This will directly test whether the observed gains persist only when the transferability signal is used. revision: yes
-
Referee: [§3.2] §3.2 (Method): The transferability definition is an observable computed directly from student-teacher agreement on adversarial examples; the manuscript provides no analysis (e.g., correlation tables or controlled substitution experiments) demonstrating that this quantity is not reducible to standard hardness metrics already known to affect robust training dynamics.
Authors: We acknowledge that the current manuscript does not include explicit correlation tables or substitution experiments. In the revision we will add (a) Pearson and Spearman correlations between transferability scores and per-sample loss / gradient norms across training epochs on CIFAR-10/100, and (b) a controlled substitution experiment that replaces the transferability weight with a hardness-based weight while keeping all other training elements fixed. These additions will quantify the degree of overlap and demonstrate that transferability captures teacher-specific alignment information beyond generic hardness. revision: yes
Circularity Check
No significant circularity: weighting defined from observable quantity with experimental support
full rationale
The paper identifies adversarial transferability via direct measurement (fraction of student adversarial examples effective against the teacher) and uses this to reweight the distillation loss on-the-fly. This is presented as an empirical design choice backed by experiments on CIFAR-10/100 and Tiny-ImageNet showing AutoAttack gains. No equations reduce the claimed improvement to a definitional identity, no fitted parameters are relabeled as predictions, and no self-citation chains or uniqueness theorems are invoked to force the result. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Adversarial transferability is a key causal factor in successful robustness transfer
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SAAD assigns sample-wise weights proportional to the entropy of fT(x+δS), effectively prioritizing transferable adversarial examples without incurring additional computational cost.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify adversarial transferability as a key factor for effective adversarial distillation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Towards understanding ensemble, knowledge distillation and self-distillation in deep learning
Zeyuan Allen-Zhu and Yuanzhi Li. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning. InThe Eleventh International Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=Uuf2q9TfXGA
work page 2023
-
[2]
Square attack: a query- efficient black-box adversarial attack via random search
Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias Hein. Square attack: a query- efficient black-box adversarial attack via random search. InEuropean conference on computer vision, pp. 484–501. Springer, 2020
work page 2020
-
[3]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. InInternational conference on machine learning, pp. 274–283. PMLR, 2018
work page 2018
-
[4]
Adversarial robustness for unsupervised domain adaptation
Muhammad Awais, Fengwei Zhou, Hang Xu, Lanqing Hong, Ping Luo, Sung-Ho Bae, and Zhenguo Li. Adversarial robustness for unsupervised domain adaptation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8568–8577, 2021
work page 2021
-
[5]
Yang Bai, Yuyuan Zeng, Yong Jiang, Shu-Tao Xia, Xingjun Ma, and Yisen Wang. Improving adversarial robustness via channel-wise activation suppressing.arXiv preprint arXiv:2103.08307, 2021
-
[6]
Brian R Bartoldson, James Diffenderfer, Konstantinos Parasyris, and Bhavya Kailkhura. Adversarial robustness limits via scaling-law and human-alignment studies.arXiv preprint arXiv:2404.09349, 2024
-
[7]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp), pp. 39–57. Ieee, 2017
work page 2017
-
[8]
Yair Carmon, Aditi Raghunathan, Ludwig Schmidt, John C Duchi, and Percy S Liang. Unlabeled data improves adversarial robustness.Advances in neural information processing systems, 32, 2019
work page 2019
-
[9]
What it thinks is important is important: Robustness transfers through input gradients
Alvin Chan, Yi Tay, and Yew-Soon Ong. What it thinks is important is important: Robustness transfers through input gradients. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 332–341, 2020
work page 2020
-
[10]
Cartl: Cooperative adversarially- robust transfer learning
Dian Chen, Hongxin Hu, Qian Wang, Li Yinli, Cong Wang, Chao Shen, and Qi Li. Cartl: Cooperative adversarially- robust transfer learning. InInternational Conference on Machine Learning, pp. 1640–1650. PMLR, 2021
work page 2021
-
[11]
Erh-Chung Chen and Che-Rung Lee. Ltd: Low temperature distillation for robust adversarial training.arXiv preprint arXiv:2111.02331, 2021
-
[12]
Hopskipjumpattack: A query-efficient decision-based attack
Jianbo Chen, Michael I Jordan, and Martin J Wainwright. Hopskipjumpattack: A query-efficient decision-based attack. In2020 ieee symposium on security and privacy (sp), pp. 1277–1294. IEEE, 2020
work page 2020
-
[13]
Rays: A ray searching method for hard-label adversarial attack
Jinghui Chen and Quanquan Gu. Rays: A ray searching method for hard-label adversarial attack. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 1739–1747, 2020
work page 2020
-
[14]
Dair: A query-efficient decision-based attack on image retrieval systems
Mingyang Chen, Junda Lu, Yi Wang, Jianbin Qin, and Wei Wang. Dair: A query-efficient decision-based attack on image retrieval systems. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1064–1073, 2021
work page 2021
-
[15]
Enhancing robustness in incremental learning with adversarial training
Seungju Cho, Hongsin Lee, and Changick Kim. Enhancing robustness in incremental learning with adversarial training. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp. 2518–2526, 2025
work page 2025
-
[16]
Long-tailed adversarial training with self-distillation
Seungju Cho, Hongsin Lee, and Changick Kim. Long-tailed adversarial training with self-distillation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/ forum?id=vM94dZiqx4
work page 2025
-
[17]
Certified adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. In international conference on machine learning, pp. 1310–1320. PMLR, 2019. 11
work page 2019
-
[18]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pp. 2206–2216. PMLR, 2020
work page 2020
-
[19]
Robustbench: a standardized adversarial robustness benchmark
Francesco Croce, Maksym Andriushchenko, Vikash Sehwag, Edoardo Debenedetti, Nicolas Flammarion, Mung Chiang, Prateek Mittal, and Matthias Hein. Robustbench: a standardized adversarial robustness benchmark. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021. URL https://openreview.net/forum?id=SSKZPJCt7B
work page 2021
-
[20]
Decoupled kullback- leibler divergence loss.arXiv preprint arXiv:2305.13948, 2023
Jiequan Cui, Zhuotao Tian, Zhisheng Zhong, Xiaojuan Qi, Bei Yu, and Hanwang Zhang. Decoupled kullback- leibler divergence loss.arXiv preprint arXiv:2305.13948, 2023
-
[21]
Parameterizing activation functions for adversarial robustness
Sihui Dai, Saeed Mahloujifar, and Prateek Mittal. Parameterizing activation functions for adversarial robustness. In2022 IEEE Security and Privacy Workshops (SPW), pp. 80–87. IEEE, 2022
work page 2022
-
[22]
Keeping the Bad Guys Out: Protecting and Vaccinating Deep Learning with JPEG Compression
Nilaksh Das, Madhuri Shanbhogue, Shang-Tse Chen, Fred Hohman, Li Chen, Michael E Kounavis, and Duen Horng Chau. Keeping the bad guys out: Protecting and vaccinating deep learning with jpeg compression. arXiv preprint arXiv:1705.02900, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Distilling adversarial robustness using heterogeneous teachers.arXiv preprint arXiv:2402.15586, 2024
Jieren Deng, Aaron Palmer, Rigel Mahmood, Ethan Rathbun, Jinbo Bi, Kaleel Mahmood, and Derek Aguiar. Distilling adversarial robustness using heterogeneous teachers.arXiv preprint arXiv:2402.15586, 2024
-
[24]
Fast and reliable evaluation of adversarial robustness with minimum-margin attack
Ruize Gao, Jiongxiao Wang, Kaiwen Zhou, Feng Liu, Binghui Xie, Gang Niu, Bo Han, and James Cheng. Fast and reliable evaluation of adversarial robustness with minimum-margin attack. InInternational Conference on Machine Learning, pp. 7144–7163. PMLR, 2022
work page 2022
-
[25]
Adversarially robust distillation
Micah Goldblum, Liam Fowl, Soheil Feizi, and Tom Goldstein. Adversarially robust distillation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 3996–4003, 2020
work page 2020
-
[26]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Sven Gowal, Chongli Qin, Jonathan Uesato, Timothy Mann, and Pushmeet Kohli. Uncovering the limits of adversarial training against norm-bounded adversarial examples.arXiv preprint arXiv:2010.03593, 2020
-
[28]
Sven Gowal, Sylvestre-Alvise Rebuffi, Olivia Wiles, Florian Stimberg, Dan Andrei Calian, and Timothy A Mann. Improving robustness using generated data.Advances in neural information processing systems, 34:4218–4233, 2021
work page 2021
-
[29]
Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. A survey of deep learning techniques for autonomous driving.Journal of Field Robotics, 37(3):362–386, 2020
work page 2020
-
[30]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[31]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pp. 630–645. Springer, 2016
work page 2016
-
[32]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Boosting accuracy and robustness of student models via adaptive adversarial distillation
Bo Huang, Mingyang Chen, Yi Wang, Junda Lu, Minhao Cheng, and Wei Wang. Boosting accuracy and robustness of student models via adaptive adversarial distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24668–24677, 2023
work page 2023
-
[34]
Hanxun Huang, Yisen Wang, Sarah Erfani, Quanquan Gu, James Bailey, and Xingjun Ma. Exploring architectural ingredients of adversarially robust deep neural networks.Advances in neural information processing systems, 34: 5545–5559, 2021. 12
work page 2021
-
[35]
Averaging Weights Leads to Wider Optima and Better Generalization
Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Enhancing adversarial training with second-order statistics of weights
Gaojie Jin, Xinping Yi, Wei Huang, Sven Schewe, and Xiaowei Huang. Enhancing adversarial training with second-order statistics of weights. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15273–15283, 2022
work page 2022
-
[37]
Randomized adversarial training via taylor expansion
Gaojie Jin, Xinping Yi, Dengyu Wu, Ronghui Mu, and Xiaowei Huang. Randomized adversarial training via taylor expansion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16447–16457, 2023
work page 2023
-
[38]
Peeraid: Improving adversarial distillation from a specialized peer tutor
Jaewon Jung, Hongsun Jang, Jaeyong Song, and Jinho Lee. Peeraid: Improving adversarial distillation from a specialized peer tutor. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24482–24491, 2024
work page 2024
-
[39]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[40]
Huafeng Kuang, Hong Liu, Yongjian Wu, Shin’ichi Satoh, and Rongrong Ji. Improving adversarial robustness via information bottleneck distillation.Advances in Neural Information Processing Systems, 36:10796–10813, 2023
work page 2023
-
[41]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Ya Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
work page 2015
-
[42]
Indirect gradient matching for adversarial robust distillation
Hongsin Lee, Seungju Cho, and Changick Kim. Indirect gradient matching for adversarial robust distillation. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=juKVq5dWTR
work page 2025
-
[43]
Binghui Li and Yuanzhi Li. Adversarial training can provably improve robustness: Theoretical analysis of feature learning process under structured data. InThe Thirteenth International Conference on Learning Representations,
-
[44]
URLhttps://openreview.net/forum?id=inLUnCpDIB
-
[45]
Binghui Li and Yuanzhi Li. On the clean generalization and robust overfitting in adversarial training from two theoretical views: Representation complexity and training dynamics. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=lvR39kEqpZ
work page 2025
-
[46]
Lin Li, Yifei Wang, Chawin Sitawarin, and Michael W. Spratling. OODRobustbench: a benchmark and large-scale analysis of adversarial robustness under distribution shift. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=kAFevjEYsz
work page 2024
-
[47]
Delving into Transferable Adversarial Examples and Black-box Attacks
Yanpei Liu, Xinyun Chen, Chang Liu, and Dawn Song. Delving into transferable adversarial examples and black-box attacks.arXiv preprint arXiv:1611.02770, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[48]
Xingjun Ma, Yuhao Niu, Lin Gu, Yisen Wang, Yitian Zhao, James Bailey, and Feng Lu. Understanding adversarial attacks on deep learning based medical image analysis systems.Pattern Recognition, 110:107332, 2021
work page 2021
-
[49]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[50]
On the robustness of vision transformers to adversarial examples
Kaleel Mahmood, Rigel Mahmood, and Marten van Dijk. On the robustness of vision transformers to adversarial examples. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 7838–7847, October 2021
work page 2021
-
[51]
Javier Maroto, Guillermo Ortiz-Jiménez, and Pascal Frossard. On the benefits of knowledge distillation for adversarial robustness.CoRR, abs/2203.07159, 2022. doi: 10.48550/ARXIV .2203.07159. URL https: //doi.org/10.48550/arXiv.2203.07159
work page internal anchor Pith review doi:10.48550/arxiv 2022
-
[52]
Awais Muhammad, Fengwei Zhou, Chuanlong Xie, Jiawei Li, Sung-Ho Bae, and Zhenguo Li. Mixacm: Mixup- based robustness transfer via distillation of activated channel maps.Advances in neural information processing systems, 34:4555–4569, 2021. 13
work page 2021
-
[53]
Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples
Nicolas Papernot, Patrick McDaniel, and Ian Goodfellow. Transferability in machine learning: from phenomena to black-box attacks using adversarial samples.arXiv preprint arXiv:1605.07277, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[54]
Practical black-box attacks against machine learning
Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay Celik, and Ananthram Swami. Practical black-box attacks against machine learning. InProceedings of the 2017 ACM on Asia conference on computer and communications security, pp. 506–519, 2017
work page 2017
-
[55]
Dynamic guidance adversarial distillation with enhanced teacher knowledge
Hyejin Park and Dongbo Min. Dynamic guidance adversarial distillation with enhanced teacher knowledge. In European Conference on Computer Vision, pp. 204–219. Springer, 2024
work page 2024
-
[56]
Chongli Qin, James Martens, Sven Gowal, Dilip Krishnan, Krishnamurthy Dvijotham, Alhussein Fawzi, Soham De, Robert Stanforth, and Pushmeet Kohli. Adversarial robustness through local linearization.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[57]
Fixing data augmentation to improve adversarial robustness.arXiv preprint arXiv:2103.01946, 2021
Sylvestre-Alvise Rebuffi, Sven Gowal, Dan A Calian, Florian Stimberg, Olivia Wiles, and Timothy Mann. Fixing data augmentation to improve adversarial robustness.arXiv preprint arXiv:2103.01946, 2021
-
[58]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510–4520, 2018
work page 2018
-
[59]
Ludwig Schmidt, Shibani Santurkar, Dimitris Tsipras, Kunal Talwar, and Aleksander Madry. Adversarially robust generalization requires more data.Advances in neural information processing systems, 31, 2018
work page 2018
-
[60]
Vikash Sehwag, Saeed Mahloujifar, Tinashe Handina, Sihui Dai, Chong Xiang, Mung Chiang, and Prateek Mittal. Robust learning meets generative models: Can proxy distributions improve adversarial robustness?arXiv preprint arXiv:2104.09425, 2021
-
[61]
Adversarially robust transfer learning.arXiv preprint arXiv:1905.08232, 2019
Ali Shafahi, Parsa Saadatpanah, Chen Zhu, Amin Ghiasi, Christoph Studer, David Jacobs, and Tom Goldstein. Adversarially robust transfer learning.arXiv preprint arXiv:1905.08232, 2019
-
[62]
Rulin Shao, Jinfeng Yi, Pin-Yu Chen, and Cho-Jui Hsieh. How and when adversarial robustness transfers in knowledge distillation?arXiv preprint arXiv:2110.12072, 2021
-
[63]
Improving neural network robustness via persistency of excitation
Kaustubh Sridhar, Oleg Sokolsky, Insup Lee, and James Weimer. Improving neural network robustness via persistency of excitation. In2022 American Control Conference (ACC), pp. 1521–1526. IEEE, 2022
work page 2022
-
[64]
Intriguing properties of neural networks
Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks.arXiv preprint arXiv:1312.6199, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[65]
Consistency regularization for adversarial robustness
Jihoon Tack, Sihyun Yu, Jongheon Jeong, Minseon Kim, Sung Ju Hwang, and Jinwoo Shin. Consistency regularization for adversarial robustness. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 8414–8422, 2022
work page 2022
-
[66]
The Space of Transferable Adversarial Examples
Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh, and Patrick McDaniel. The space of transferable adversarial examples.arXiv preprint arXiv:1704.03453, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
Adversarial risk and the dangers of evaluating against weak attacks
Jonathan Uesato, Brendan O’donoghue, Pushmeet Kohli, and Aaron Oord. Adversarial risk and the dangers of evaluating against weak attacks. InInternational conference on machine learning, pp. 5025–5034. PMLR, 2018
work page 2018
-
[68]
Transferring adversarial robustness through robust represen- tation matching
Pratik Vaishnavi, Kevin Eykholt, and Amir Rahmati. Transferring adversarial robustness through robust represen- tation matching. In31st USENIX security symposium (USENIX Security 22), pp. 2083–2098, 2022
work page 2083
-
[69]
Ningfei Wang, Yunpeng Luo, Takami Sato, Kaidi Xu, and Qi Alfred Chen. Does physical adversarial example really matter to autonomous driving? towards system-level effect of adversarial object evasion attack. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4412–4423, 2023
work page 2023
-
[70]
Yifei Wang, Liangchen Li, Jiansheng Yang, Zhouchen Lin, and Yisen Wang. Balance, imbalance, and rebalance: Understanding robust overfitting from a minimax game perspective.Advances in neural information processing systems, 36:15775–15798, 2023. 14
work page 2023
-
[71]
Improving adversarial robustness requires revisiting misclassified examples
Yisen Wang, Difan Zou, Jinfeng Yi, James Bailey, Xingjun Ma, and Quanquan Gu. Improving adversarial robustness requires revisiting misclassified examples. InInternational Conference on Learning Representations, 2020
work page 2020
-
[72]
Better diffusion models further improve adversarial training
Zekai Wang, Tianyu Pang, Chao Du, Min Lin, Weiwei Liu, and Shuicheng Yan. Better diffusion models further improve adversarial training. InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[73]
Cfa: Class-wise calibrated fair adversarial training
Zeming Wei, Yifei Wang, Yiwen Guo, and Yisen Wang. Cfa: Class-wise calibrated fair adversarial training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8193–8201, 2023
work page 2023
-
[74]
Adversarial weight perturbation helps robust generalization
Dongxian Wu, Shu-Tao Xia, and Yisen Wang. Adversarial weight perturbation helps robust generalization. Advances in Neural Information Processing Systems, 33:2958–2969, 2020
work page 2020
-
[75]
Feature denoising for improving adversarial robustness
Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan L Yuille, and Kaiming He. Feature denoising for improving adversarial robustness. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 501–509, 2019
work page 2019
-
[76]
Yaodong Yu, Zitong Yang, Edgar Dobriban, Jacob Steinhardt, and Yi Ma. Understanding generalization in adversarial training via the bias-variance decomposition.arXiv preprint arXiv:2103.09947, 2021
-
[77]
Xinli Yue, Mou Ningping, Qian Wang, and Lingchen Zhao. Revisiting adversarial robustness distillation from the perspective of robust fairness.Advances in Neural Information Processing Systems, 36:30390–30401, 2023
work page 2023
-
[78]
Theoretically principled trade-off between robustness and accuracy
Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and Michael Jordan. Theoretically principled trade-off between robustness and accuracy. InInternational conference on machine learning, pp. 7472–7482. PMLR, 2019
work page 2019
-
[79]
On adversarial robustness of trajectory prediction for autonomous vehicles
Qingzhao Zhang, Shengtuo Hu, Jiachen Sun, Qi Alfred Chen, and Z Morley Mao. On adversarial robustness of trajectory prediction for autonomous vehicles. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15159–15168, 2022
work page 2022
-
[80]
Enhanced accuracy and robustness via multi- teacher adversarial distillation
Shiji Zhao, Jie Yu, Zhenlong Sun, Bo Zhang, and Xingxing Wei. Enhanced accuracy and robustness via multi- teacher adversarial distillation. InEuropean Conference on Computer Vision, pp. 585–602. Springer, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.