MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Pith reviewed 2026-05-16 23:02 UTC · model grok-4.3
The pith
MoCapAnything reconstructs rotation-based animations for arbitrary rigged 3D assets directly from monocular video using the asset itself as a structural prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
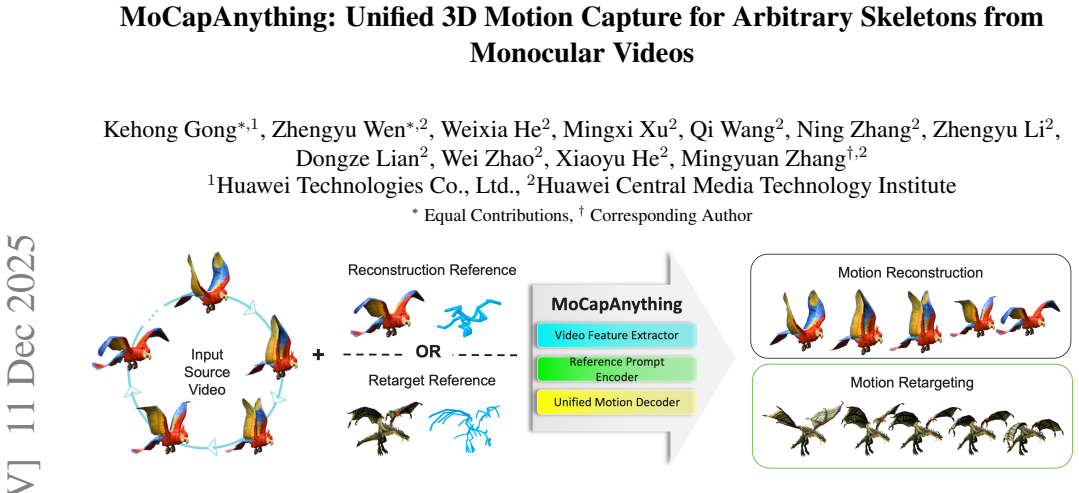
A reference-guided framework first extracts per-joint queries from an arbitrary asset's skeleton, mesh and rendered images, fuses them with dense video features and a reconstructed coarse 4D mesh, decodes temporally coherent 3D joint trajectories, and finally recovers asset-specific rotations via constraint-aware inverse kinematics, thereby producing driveable BVH-style animations for any rigged asset from a single monocular video.
What carries the argument
The Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh and rendered images to condition the entire motion prediction pipeline.
If this is right
- Prompt-driven capture becomes possible for any rigged asset without species- or template-specific retraining.
- Cross-species retargeting works across heterogeneous skeleton topologies while preserving motion semantics.
- Temporally coherent 3D trajectories can be produced directly from in-the-wild monocular footage.
- A standardized skeleton-mesh-render dataset of over one thousand clips can serve as a common benchmark for category-agnostic methods.
Where Pith is reading between the lines
- The same factorization could be tested on multi-view video inputs to reduce depth ambiguity in the trajectory prediction stage.
- Replacing the lightweight IK stage with a learned rotation predictor might allow end-to-end differentiability for further fine-tuning on custom rigs.
- Combining the prompt encoder with generative video models could enable creation of new motions that still respect the target asset's exact skeleton constraints.
Load-bearing premise
The rigged 3D asset supplies enough structural information through its skeleton, mesh and rendered images for the prompt encoder to produce accurate per-joint queries that generalize to unseen rigs and motions.
What would settle it
Running the system on videos of animals whose limb topology and joint count differ markedly from the Truebones Zoo training distribution and checking whether the output rotations visibly fail to reproduce the observed motion when applied to the input asset mesh.
Figures





read the original abstract
Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MoCapAnything, a reference-guided, factorized framework for Category-Agnostic Motion Capture (CAMoCap). Given a monocular video and an arbitrary rigged 3D asset as prompt, it predicts 3D joint trajectories via a Reference Prompt Encoder (extracting per-joint queries from skeleton/mesh/renders), Video Feature Extractor (dense descriptors plus coarse 4D mesh), and Unified Motion Decoder, then recovers asset-specific rotations through constraint-aware inverse kinematics. The method is trained on the curated Truebones Zoo dataset (1038 clips with standardized triads) and claims high-quality animations plus meaningful cross-species retargeting on in-domain benchmarks and in-the-wild videos.
Significance. If the generalization claims hold with supporting evidence, the work would be significant for enabling scalable, prompt-driven 3D motion capture beyond human- or template-specific pipelines, with potential impact on animation, gaming, and cross-species content creation. The factorized design and new dataset curation are positive elements that could support further research.
major comments (3)
- [Experiments] Experiments section: The abstract and results claim 'high-quality skeletal animations' and 'meaningful cross-species retargeting' on in-domain benchmarks and in-the-wild videos, yet no quantitative metrics (e.g., MPJPE, rotation error, or temporal consistency scores), ablation studies, or error analysis are reported. This leaves the central performance claims resting solely on qualitative description, which is insufficient to substantiate the generalization assertions.
- [§3.3] §3.3, Unified Motion Decoder: The decoder produces trajectories in a unified space before asset-specific IK. Because training relies on Truebones Zoo's standardized triads, it is unclear whether the learned trajectories encode purely geometric, topology-agnostic features or dataset-specific joint semantics. This assumption is load-bearing for the arbitrary-rig and cross-species claims (e.g., quadruped vs. avian hierarchies); without explicit tests on varying joint counts/connectivities, the subsequent IK stage may receive misaligned inputs.
- [§3.1] §3.1, Reference Prompt Encoder: The design assumes that the target asset's skeleton, mesh, and rendered images supply sufficient cues for accurate per-joint queries that generalize to unseen rigs. No analysis or ablation demonstrates robustness when these cues differ substantially from the training distribution, which directly affects the weakest assumption underlying the prompt-driven approach.
minor comments (2)
- [Abstract] Abstract: References to 'in-domain benchmarks' are made without naming the specific datasets or providing any numerical context, reducing clarity for readers.
- [§3] Notation and figures: The distinction between the unified trajectory space and asset-specific rotations could be clarified with an explicit diagram or equation in §3; some figure captions lack detail on which species/rigs are shown in cross-retargeting examples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications on our methodology and commit to revisions that provide stronger empirical support for the claims.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The abstract and results claim 'high-quality skeletal animations' and 'meaningful cross-species retargeting' on in-domain benchmarks and in-the-wild videos, yet no quantitative metrics (e.g., MPJPE, rotation error, or temporal consistency scores), ablation studies, or error analysis are reported. This leaves the central performance claims resting solely on qualitative description, which is insufficient to substantiate the generalization assertions.
Authors: We agree that quantitative metrics and ablations would strengthen the presentation. In the revised manuscript we will report MPJPE and per-joint rotation errors on the held-out portion of Truebones Zoo (where ground-truth 3D trajectories are available from the standardized triads), add temporal consistency scores, and include ablation studies on the Reference Prompt Encoder and Unified Motion Decoder. For in-the-wild results we will supplement the qualitative examples with a small-scale user study measuring perceived animation quality and retargeting fidelity. revision: yes
-
Referee: [§3.3] §3.3, Unified Motion Decoder: The decoder produces trajectories in a unified space before asset-specific IK. Because training relies on Truebones Zoo's standardized triads, it is unclear whether the learned trajectories encode purely geometric, topology-agnostic features or dataset-specific joint semantics. This assumption is load-bearing for the arbitrary-rig and cross-species claims (e.g., quadruped vs. avian hierarchies); without explicit tests on varying joint counts/connectivities, the subsequent IK stage may receive misaligned inputs.
Authors: The decoder is trained to regress 3D joint positions in a canonical coordinate frame; the per-joint queries supplied by the Reference Prompt Encoder are the only mechanism that injects rig-specific information, so the trajectory output itself is intended to be topology-agnostic. The subsequent constraint-aware IK stage then solves for asset-specific rotations given the target skeleton's joint limits and connectivity. To make this explicit, the revision will add a dedicated experiment that evaluates the decoder on rigs whose joint counts and connectivities differ from the training triads (e.g., by subsampling joints or introducing additional cross-species skeletons) and measures the quality of the IK-recovered animations. revision: partial
-
Referee: [§3.1] §3.1, Reference Prompt Encoder: The design assumes that the target asset's skeleton, mesh, and rendered images supply sufficient cues for accurate per-joint queries that generalize to unseen rigs. No analysis or ablation demonstrates robustness when these cues differ substantially from the training distribution, which directly affects the weakest assumption underlying the prompt-driven approach.
Authors: The encoder fuses three complementary signals (skeleton graph, mesh geometry, and rendered views) precisely to increase robustness to variations in any single cue. We will add an ablation that systematically removes or perturbs each cue and evaluates performance on rigs whose visual and structural statistics differ from the Truebones Zoo training distribution, thereby quantifying the contribution of each modality to generalization. revision: yes
Circularity Check
No circularity: empirical learned pipeline with independent training data
full rationale
The paper presents a factorized neural architecture (Reference Prompt Encoder, Video Feature Extractor, Unified Motion Decoder) trained end-to-end on the curated Truebones Zoo dataset of 1038 clips. No equations, fitted parameters, or self-citations are shown that reduce the output trajectories or retargeting results to definitional equivalence with the inputs. The central claims rest on empirical performance metrics for in-domain and in-the-wild videos rather than any self-referential construction. The IK stage is described as a lightweight post-process, not a fitted component. This is the expected non-circular outcome for a data-driven CV method.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A rigged 3D asset's skeleton, mesh, and rendered images contain sufficient information to generate per-joint queries that enable accurate motion retargeting.
- domain assumption Constraint-aware inverse kinematics can reliably convert predicted 3D joint trajectories into valid bone rotations for arbitrary rigs.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories... followed by an IK fitting stage
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
R-DMesh: Video-Guided 3D Animation via Rectified Dynamic Mesh Flow
R-DMesh generates high-fidelity 4D meshes aligned to video by disentangling base mesh, motion, and a learned rectification jump offset inside a VAE, then using Triflow Attention and rectified-flow diffusion.
-
R-DMesh: Video-Guided 3D Animation via Rectified Dynamic Mesh Flow
R-DMesh uses a VAE with a learned rectification jump offset and Triflow Attention inside a rectified-flow diffusion transformer to produce video-aligned 4D meshes despite initial pose misalignment.
Reference graph
Works this paper leans on
-
[1]
Multi-hmr: Multi-person whole-body human mesh recovery in a single shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Ro- main Br ´egier, Philippe Weinzaepfel, Gr ´egory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. InEuropean Conference on Computer Vision, pages 202–218. Springer, 2024. 3
work page 2024
-
[2]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 2
work page 2020
-
[3]
Cascaded pyramid net- work for multi-person pose estimation
Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid net- work for multi-person pose estimation. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 7103–7112, 2018. 2
work page 2018
-
[4]
Bowen Cheng, Bin Xiao, Jingdong Wang, Honghui Shi, Thomas S. Huang, and Lei Zhang. Higherhrnet: Scale-aware representation learning for bottom-up human pose estima- tion. InCVPR, 2020. 2
work page 2020
-
[5]
Beyond static features for temporally consis- tent 3d human pose and shape from a video
Hongsuk Choi, Gyeongsik Moon, Ju Yong Chang, and Ky- oung Mu Lee. Beyond static features for temporally consis- tent 3d human pose and shape from a video. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1964–1973, 2021. 3
work page 1964
- [6]
-
[7]
Objaverse-XL: A Universe of 10M+ 3D Objects
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Chris- tian Laforte, Vikram V oleti, Samir Yitzhak Gadre, Eli VanderBilt, Aniruddha Kembhavi, Carl V ondrick, Georgia Gkioxari, Kiana Ehsani, Ludwig Schmidt, and Ali Farhadi. Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023. 6
work page internal anchor Pith review arXiv 2023
-
[8]
Anytop: Character animation diffusion with any topology.arXiv preprint arXiv:2502.17327, 2025
Inbar Gat, Sigal Raab, Guy Tevet, Yuval Reshef, Amit H Bermano, and Daniel Cohen-Or. Anytop: Character animation diffusion with any topology.arXiv preprint arXiv:2502.17327, 2025. 4, 5
-
[9]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023. 3
work page 2023
-
[10]
A graph-based approach for category-agnostic pose estimation.arXiv preprint arXiv:2311.17891, 2023
Or Hirschorn and Shai Avidan. A graph-based approach for category-agnostic pose estimation.arXiv preprint arXiv:2311.17891, 2023. 2
-
[11]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7122–7131, 2018. 1, 3
work page 2018
-
[12]
Learning category-specific mesh reconstruc- tion from image collections
Angjoo Kanazawa, Shubham Tulsiani, Alexei A Efros, and Jitendra Malik. Learning category-specific mesh reconstruc- tion from image collections. InProceedings of the Euro- pean conference on computer vision (ECCV), pages 371– 386, 2018. 3
work page 2018
-
[13]
Vibe: Video inference for human body pose and shape estimation
Muhammed Kocabas, Nikos Athanasiou, and Michael J Black. Vibe: Video inference for human body pose and shape estimation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 5253–5263, 2020. 3
work page 2020
-
[14]
Pace: Human and camera motion estimation from in- the-wild videos
Muhammed Kocabas, Ye Yuan, Pavlo Molchanov, Yunrong Guo, Michael J Black, Otmar Hilliges, Jan Kautz, and Umar Iqbal. Pace: Human and camera motion estimation from in- the-wild videos. In2024 International Conference on 3D Vision (3DV), pages 397–408. IEEE, 2024. 3
work page 2024
-
[15]
Simple pose: Rethinking and improving a bottom-up approach for multi-person pose estimation
Jia Li, Wen Su, and Zengfu Wang. Simple pose: Rethinking and improving a bottom-up approach for multi-person pose estimation. InProceedings of the AAAI conference on artifi- cial intelligence, pages 11354–11361, 2020. 2
work page 2020
-
[16]
Human pose regression with residual log-likelihood estimation
Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 11025–11034, 2021. 2
work page 2021
-
[17]
Simcc: A simple coordinate classification perspective for hu- man pose estimation
Yanjie Li, Sen Yang, Peidong Liu, Shoukui Zhang, Yunx- iao Wang, Zhicheng Wang, Wankou Yang, and Shu-Tao Xia. Simcc: A simple coordinate classification perspective for hu- man pose estimation. InEuropean Conference on Computer Vision, pages 89–106. Springer, 2022. 2
work page 2022
-
[18]
Learning the 3d fauna of the web
Zizhang Li, Dor Litvak, Ruining Li, Yunzhi Zhang, Tomas Jakab, Christian Rupprecht, Shangzhe Wu, Andrea Vedaldi, and Jiajun Wu. Learning the 3d fauna of the web. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9752–9762, 2024. 3
work page 2024
-
[19]
One-stage 3d whole-body mesh recovery with component aware transformer
Jing Lin, Ailing Zeng, Haoqian Wang, Lei Zhang, and Yu Li. One-stage 3d whole-body mesh recovery with component aware transformer. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 21159–21168, 2023. 3
work page 2023
-
[20]
SMPL: A skinned multi- person linear model.ACM transactions on graphics (TOG), 34(6):1–16, 2015
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. SMPL: A skinned multi- person linear model.ACM transactions on graphics (TOG), 34(6):1–16, 2015. 1, 3 9
work page 2015
-
[21]
Stacked hour- glass networks for human pose estimation
Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hour- glass networks for human pose estimation. InEuropean con- ference on computer vision, pages 483–499. Springer, 2016. 2
work page 2016
-
[22]
Black, Sil- via Zuffi, and Peter Kulits
Tomasz Niewiadomski, Anastasios Yiannakidis, Hanz Cuevas-Velasquez, Soubhik Sanyal, Michael J. Black, Sil- via Zuffi, and Peter Kulits. Generative zoo.CoRR, abs/2412.08101, 2024. 3
-
[23]
Black, Silvia Zuffi, and Peter Kulits
Tomasz Niewiadomski, Anastasios Yiannakidis, Hanz Cuevas-Velasquez, Soubhik Sanyal, Michael J. Black, Silvia Zuffi, and Peter Kulits. Generative zoo. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 6
work page 2025
-
[24]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Rus- sell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael G. Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´e J´egou, Julien Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019. 1, 3
work page 2019
-
[26]
Matan Rusanovsky, Or Hirschorn, and Shai Avidan. Capex: Category-agnostic pose estimation from textual point expla- nation.arXiv preprint arXiv:2406.00384, 2024. 3
-
[27]
Capex: Category-agnostic pose estimation from textual point ex- planation
Matan Rusanovsky, Or Hirschorn, and Shai Avidan. Capex: Category-agnostic pose estimation from textual point ex- planation. InThe Thirteenth International Conference on Learning Representations, 2025. 1
work page 2025
-
[28]
End-to-end multi-person pose estimation with transformers
Dahu Shi, Xing Wei, Liangqi Li, Ye Ren, and Wenming Tan. End-to-end multi-person pose estimation with transformers. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 11069–11078, 2022. 2
work page 2022
-
[29]
Matching is not enough: A two-stage frame- work for category-agnostic pose estimation
Min Shi, Zihao Huang, Xianzheng Ma, Xiaowei Hu, and Zhiguo Cao. Matching is not enough: A two-stage frame- work for category-agnostic pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 7308–7317, 2023. 2
work page 2023
-
[30]
Wham: Reconstructing world-grounded humans with accu- rate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2070– 2080, 2024. 3
work page 2070
-
[31]
Deep high-resolution representation learning for human pose es- timation
Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose es- timation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5693–5703,
-
[32]
Aios: All-in-one-stage expres- sive human pose and shape estimation
Qingping Sun, Yanjun Wang, Ailing Zeng, Wanqi Yin, Chen Wei, Wenjia Wang, Haiyi Mei, Chi-Sing Leung, Zi- wei Liu, Lei Yang, et al. Aios: All-in-one-stage expres- sive human pose and shape estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1834–1843, 2024. 3
work page 2024
-
[33]
Deeppose: Hu- man pose estimation via deep neural networks
Alexander Toshev and Christian Szegedy. Deeppose: Hu- man pose estimation via deep neural networks. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014. 1
work page 2014
-
[34]
Deeppose: Human pose estimation via deep neural networks
Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1653–1660, 2014. 2
work page 2014
-
[35]
Truebones motion capture – mocap files, n.d
Truebones. Truebones motion capture – mocap files, n.d. Accessed: 2025-05-22. 1, 2, 6
work page 2025
-
[36]
Locllm: Exploiting generalizable human keypoint localization via large language model
Dongkai Wang, Shiyu Xuan, and Shiliang Zhang. Locllm: Exploiting generalizable human keypoint localization via large language model. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 614–623, 2024. 2
work page 2024
-
[37]
Tram: Global trajectory and motion of 3d humans from in- the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in- the-wild videos. InEuropean Conference on Computer Vi- sion, pages 467–487. Springer, 2024. 3
work page 2024
-
[38]
Magicpony: Learning ar- ticulated 3d animals in the wild
Shangzhe Wu, Ruining Li, Tomas Jakab, Christian Rup- precht, and Andrea Vedaldi. Magicpony: Learning ar- ticulated 3d animals in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8792–8802, 2023. 3
work page 2023
-
[39]
CASA: Category-agnostic skeletal an- imal reconstruction
Yuefan Wu*, Zeyuan Chen*, Shaowei Liu, Zhongzheng Ren, and Shenlong Wang. CASA: Category-agnostic skeletal an- imal reconstruction. InNeurIPS, 2022. 3
work page 2022
-
[40]
Simple baselines for human pose estimation and tracking
Bin Xiao, Haiping Wu, and Yichen Wei. Simple baselines for human pose estimation and tracking. InProceedings of the European conference on computer vision (ECCV), pages 466–481, 2018. 2
work page 2018
-
[41]
Querypose: Sparse multi- person pose regression via spatial-aware part-level query
Yabo Xiao, Kai Su, Xiaojuan Wang, Dongdong Yu, Lei Jin, Mingshu He, and Zehuan Yuan. Querypose: Sparse multi- person pose regression via spatial-aware part-level query. Advances in Neural Information Processing Systems, 35: 12464–12477, 2022. 2
work page 2022
-
[42]
Pose for everything: Towards category-agnostic pose estimation
Lumin Xu, Sheng Jin, Wang Zeng, Wentao Liu, Chen Qian, Wanli Ouyang, Ping Luo, and Xiaogang Wang. Pose for everything: Towards category-agnostic pose estimation. In European conference on computer vision, pages 398–416. Springer, 2022. 2
work page 2022
-
[43]
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vit- pose: Simple vision transformer baselines for human pose estimation.Advances in neural information processing sys- tems, 35:38571–38584, 2022. 2
work page 2022
-
[44]
Lasr: Learning articulated shape re- construction from a monocular video
Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Huiwen Chang, Deva Ramanan, William T Freeman, and Ce Liu. Lasr: Learning articulated shape re- construction from a monocular video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15980–15989, 2021. 3
work page 2021
-
[45]
Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Ce Liu, and Deva Ramanan. Viser: Video- 10 specific surface embeddings for articulated 3d shape recon- struction.Advances in Neural Information Processing Sys- tems, 34:19326–19338, 2021. 3
work page 2021
-
[46]
Banmo: Building animatable 3d neural models from many casual videos
Gengshan Yang, Minh V o, Natalia Neverova, Deva Ra- manan, Andrea Vedaldi, and Hanbyul Joo. Banmo: Building animatable 3d neural models from many casual videos. In CVPR, 2022. 3
work page 2022
-
[47]
Zhang, Zachary Manchester, and Deva Ramanan
Gengshan Yang, Shuo Yang, John Z. Zhang, Zachary Manchester, and Deva Ramanan. Physically plausible re- construction from monocular videos. InICCV, 2023. 3
work page 2023
-
[48]
Jie Yang, Ailing Zeng, Shilong Liu, Feng Li, Ruimao Zhang, and Lei Zhang. Explicit box detection unifies end-to-end multi-person pose estimation.arXiv preprint arXiv:2302.01593, 2023. 2
-
[49]
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Ru- binstein, Ming-Hsuan Yang, and Varun Jampani. Lassie: Learning articulated shapes from sparse image ensemble via 3d part discovery.Advances in Neural Information Process- ing Systems, 35:15296–15308, 2022. 3
work page 2022
-
[50]
Whac: World-grounded hu- mans and cameras
Wanqi Yin, Zhongang Cai, Ruisi Wang, Fanzhou Wang, Chen Wei, Haiyi Mei, Weiye Xiao, Zhitao Yang, Qingping Sun, Atsushi Yamashita, et al. Whac: World-grounded hu- mans and cameras. InEuropean Conference on Computer Vision, pages 20–37. Springer, 2024. 3
work page 2024
-
[51]
Glamr: Global occlusion-aware human mesh recov- ery with dynamic cameras
Ye Yuan, Umar Iqbal, Pavlo Molchanov, Kris Kitani, and Jan Kautz. Glamr: Global occlusion-aware human mesh recov- ery with dynamic cameras. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11038–11049, 2022. 3
work page 2022
-
[52]
Silvia Zuffi, Angjoo Kanazawa, David Jacobs, and Michael J. Black. 3D menagerie: Modeling the 3D shape and pose of animals. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. 1, 3 11 MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos Supplementary Material
work page 2017
-
[53]
More Visualization Results In this section, we summarize additional qualitative re- sults from our supplementary webpage. These visualiza- tions highlight the effectiveness of our approach across con- trolled multi-species datasets, in-the-wild videos, and cross- species retargeting scenarios, showing that our model pro- duces high-fidelity and temporally...
-
[54]
Implementation Details A. Dataset and Environment Details Dataset Processing.All meshes are first scaled by the bounding box of their rest pose, normalizing each mesh into a unit-volume space. For sequence data, we remove the global translation of every frame, compute a sequence- level super bounding box, and uniformly scale the entire se- quence into the...
-
[55]
Evaluation Metrics This section describes the computation of the proposed metric(CD-Skeleton) that evaluates the alignment between two articulated skeletons. Each skeleton is represented by a set of 3D joint positions and a kinematic hierarchy defined by a parent array. Notation Let Skeleton A and Skeleton B be defined as: • Joint positions: XA ={x A i ∈R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.