Recognition: 2 theorem links
· Lean TheoremMultiPath Memory Access: Breaking Host-GPU Bandwidth Bottlenecks in LLM Services
Pith reviewed 2026-05-16 21:54 UTC · model grok-4.3
The pith
Multipath Memory Access routes host-GPU copies over unused server links to raise bandwidth 4.6x.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MMA expands a single host-GPU copy across available direct and relay paths without hardware, driver, or application changes. It preserves CUDA stream semantics with a dependency-preserving Dummy Task, coordinates distributed micro-transfer completion through a lightweight synchronization mechanism, and uses queue backpressure to route traffic without explicit link-state feedback. On an 8-GPU NVIDIA H20 server, MMA achieves 245 GB/s peak host-to-GPU bandwidth, a 4.62x improvement over native CUDA copies, and reduces TTFT for KV cache fetching by 1.14-2.38x and model wake-up/switching latency by 1.12-2.48x.
What carries the argument
Multipath Memory Access (MMA), which splits transfers into micro-operations routed over direct PCIe links and relay paths through peer GPUs connected by high-bandwidth interconnects.
If this is right
- Effective host-GPU bandwidth increases without buying new hardware or changing drivers.
- KV cache offload and fetch operations complete faster, lowering time-to-first-token in LLM inference.
- Model loading and switching between different LLMs happens with less delay in shared servers.
- Existing LLM serving frameworks can adopt the gains immediately since no code changes are required.
- Server I/O capacity that was previously unused becomes available for data movement.
Where Pith is reading between the lines
- The same multipath idea could apply to other multi-device setups where data must cross host-device boundaries.
- If interconnect speeds increase in future hardware, the relative gain from MMA may grow because more relay capacity would be available.
- Workloads with very small transfers might see less benefit if the overhead of splitting and synchronizing exceeds the path gains.
- Testing on servers with different GPU counts or interconnect topologies would show how well the routing scales.
Load-bearing premise
The extra relay paths can be used without adding enough overhead to cancel out the bandwidth gains while still obeying all CUDA ordering rules.
What would settle it
Measure the sustained host-to-GPU copy bandwidth on the 8-GPU server with a single large transfer both with and without MMA enabled; if MMA does not exceed the native single-path limit by a large margin, the claim fails.
Figures












read the original abstract
Host-GPU data movement has become a latency-critical bottleneck in LLM serving, surfacing in common paths such as model-weight movement and KV cache offload/fetch. Today, each host-GPU copy is effectively confined to the PCIe path of the target GPU, even though modern multi-GPU servers contain additional PCIe links on peer GPUs and high bandwidth GPU interconnects. This leaves substantial intra-server I/O capacity unused. To address this issue, we present Multipath Memory Access (MMA), a software-defined multipath memory access system for host--GPU data transfer. To the best of our knowledge, MMA is the first software-defined system to enable efficient multipath host--GPU data transfer within a single multi-GPU server. MMA expands a single host--GPU copy across available direct and relay paths without hardware, driver, or application changes. It preserves CUDA stream semantics with a dependency-preserving Dummy Task, coordinates distributed micro-transfer completion through a lightweight synchronization mechanism, and uses queue backpressure to route traffic without explicit link-state feedback. On an 8-GPU NVIDIA H20 server, MMA achieves 245 GB/s peak host-to-GPU bandwidth, a 4.62x improvement over native CUDA copies, and reduces TTFT for KV cache fetching by 1.14-2.38x and model wake-up/switching latency by 1.12-2.48x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiPath Memory Access (MMA), a software-defined system that splits host-GPU transfers across direct PCIe paths and relay paths through peer GPUs and high-bandwidth interconnects. It uses a dependency-preserving Dummy Task, lightweight distributed synchronization for micro-transfer completion, and queue backpressure to preserve CUDA stream semantics without hardware, driver, or application changes. On an 8-GPU NVIDIA H20 server, MMA reports 245 GB/s peak host-to-GPU bandwidth (4.62x over native CUDA copies), 1.14-2.38x TTFT reduction for KV cache fetching, and 1.12-2.48x reduction in model wake-up/switching latency.
Significance. If the performance claims hold after overhead isolation, MMA would meaningfully improve LLM serving efficiency by utilizing otherwise-idle intra-server I/O capacity for latency-critical paths such as weight loading and KV cache movement, without requiring new hardware.
major comments (2)
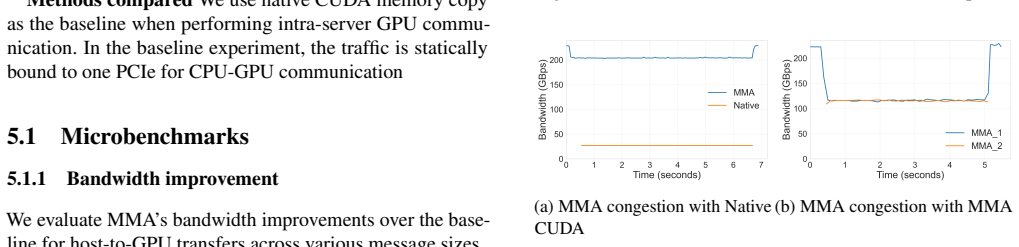
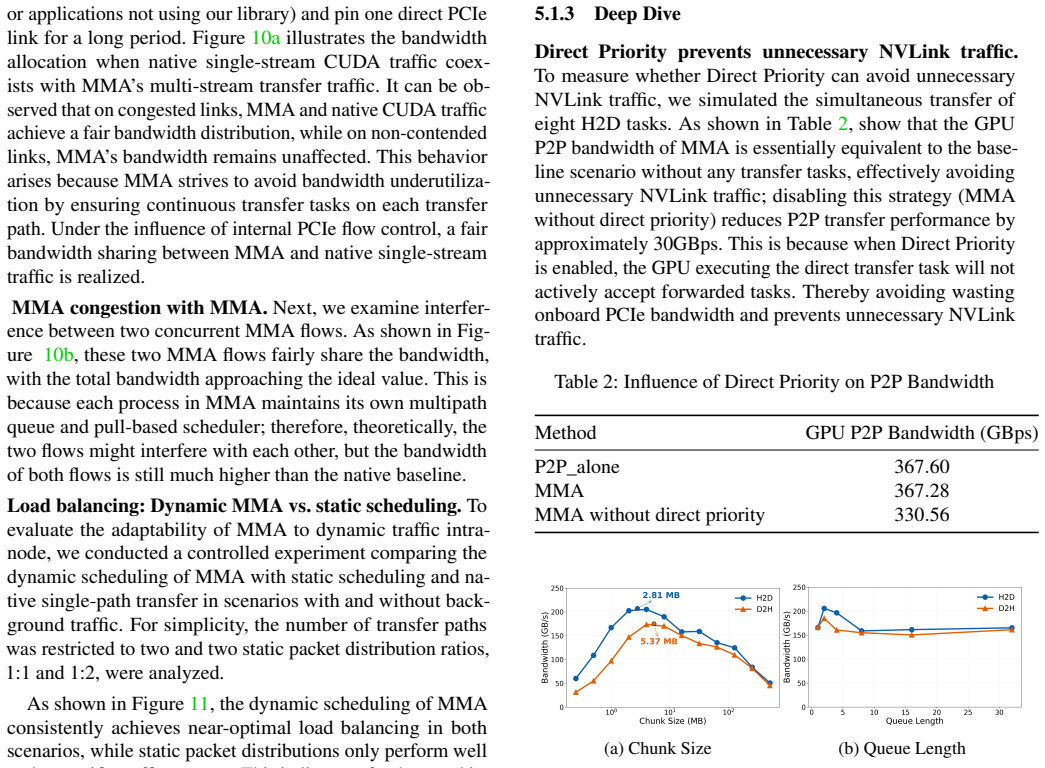
- [§5] §5 (Evaluation): the headline 4.62x bandwidth and 1.14-2.38x TTFT claims rest on the unverified assumption that Dummy Task insertion, distributed micro-transfer synchronization, and queue backpressure add negligible latency and resource usage. No single-stream microbenchmarks that subtract native copy time from multipath time, nor measurements under concurrent LLM-serving streams, are reported to isolate these costs.
- [§4 and §5] §4 (Design) and §5: the claim that queue backpressure routes traffic correctly without explicit link-state feedback while preserving full CUDA stream semantics is load-bearing for correctness under overlapping KV-cache and weight transfers, yet no evaluation of stream ordering or application-visible correctness under realistic multi-stream LLM workloads is provided.
minor comments (2)
- [Abstract and §5] Abstract and §5: results lack error bars, precise workload descriptions (e.g., model sizes, batch sizes, concurrency levels), and ablation tables separating bandwidth gains from coordination overhead.
- Figure clarity: diagrams of relay-path micro-transfers and Dummy Task insertion would benefit from explicit timing annotations to illustrate dependency preservation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing evaluation rigor. We address each major comment below and will revise the manuscript to include the requested microbenchmarks and correctness evaluations.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): the headline 4.62x bandwidth and 1.14-2.38x TTFT claims rest on the unverified assumption that Dummy Task insertion, distributed micro-transfer synchronization, and queue backpressure add negligible latency and resource usage. No single-stream microbenchmarks that subtract native copy time from multipath time, nor measurements under concurrent LLM-serving streams, are reported to isolate these costs.
Authors: We agree that dedicated isolation of overheads from Dummy Task insertion, micro-transfer synchronization, and queue backpressure would strengthen the claims. The reported 245 GB/s bandwidth and TTFT/latency speedups are end-to-end measurements that already incorporate any such costs. To directly address the concern, we will add single-stream microbenchmarks subtracting native copy time from MMA time and concurrent-stream measurements under realistic LLM workloads to quantify latency and resource overhead. These will appear in the revised §5. revision: yes
-
Referee: [§4 and §5] §4 (Design) and §5: the claim that queue backpressure routes traffic correctly without explicit link-state feedback while preserving full CUDA stream semantics is load-bearing for correctness under overlapping KV-cache and weight transfers, yet no evaluation of stream ordering or application-visible correctness under realistic multi-stream LLM workloads is provided.
Authors: Queue backpressure is intended to preserve CUDA stream semantics via dependency-preserving Dummy Tasks and lightweight synchronization without needing explicit link-state feedback. While the current evaluation does not include a dedicated stream-ordering test, the TTFT and wake-up latency results were obtained from realistic multi-stream LLM serving workloads involving overlapping KV-cache and weight transfers; any violation of ordering would have produced incorrect results or crashes. We will add explicit stream-ordering and application-correctness experiments under multi-stream workloads to the revised §5. revision: yes
Circularity Check
No significant circularity; results from direct hardware measurements
full rationale
The paper describes an implemented software system (MMA) whose performance claims rest on empirical measurements of bandwidth and latency on a physical 8-GPU NVIDIA H20 server. No equations, fitted parameters, predictions derived from prior results, or self-referential definitions appear in the provided text. The reported 4.62x bandwidth gain and latency reductions are presented as observed outcomes of the implementation rather than outputs of any derivation chain that reduces to its own inputs. The central mechanisms (Dummy Task, lightweight sync, queue backpressure) are engineering choices whose overhead is evaluated by direct timing, not by construction from the claimed gains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Modern multi-GPU servers contain additional PCIe links on peer GPUs and high-bandwidth interconnects that remain unused by native host-GPU copies.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MMA introduces a novel dummy task that retrieves control from asynchronous transfer tasks, along with a synchronization mechanism to maintain the original dependencies... congestion-aware routing strategy that achieves intra-server traffic load balancing even in the absence of path-aware information.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On an 8-GPU NVIDIA H20 server, MMA achieves 245 GB/s peak host-to-GPU bandwidth, a 4.62x improvement over native CUDA copies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MMA code base will be opensourced after paper ac- cepted
-
[2]
Inc. Advanced Micro Devices. AMD EPYC™ 9654. https://www.amd.com/ en/products/processors/server/epyc/ 4th-generation-9004-and-8004-series/ amd-epyc-9654.html, 2022
work page 2022
-
[3]
Inc. Advanced Micro Devices. AMD EPYC™ 9005 Series Processors Data Sheet. Data sheet, Advanced Micro Devices, Inc., 2024
work page 2024
-
[4]
Deepspeed-inference: enabling efficient in- ference of transformer models at unprecedented scale
Reza Yazdani Aminabadi, Samyam Rajbhandari, Am- mar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Olatunji Ruwase, Shaden Smith, Minjia Zhang, Jeff Rasley, et al. Deepspeed-inference: enabling efficient in- ference of transformer models at unprecedented scale. In SC22: International Conference for High Performance Computing, Networking, Storage and Analysis, ...
work page 2022
-
[5]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xi- aozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Long- bench v2: Towards deeper understanding and reason- ing on realistic long-context multitasks.arXiv preprint arXiv:2412.15204, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
{PipeSwitch}: Fast pipelined context switching for deep learning applications
Zhihao Bai, Zhen Zhang, Yibo Zhu, and Xin Jin. {PipeSwitch}: Fast pipelined context switching for deep learning applications. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 499–514, 2020
work page 2020
-
[8]
Overlapping data transfers with computation on gpu with tiles
Burak Bastem, Didem Unat, Weiqun Zhang, Ann Alm- gren, and John Shalf. Overlapping data transfers with computation on gpu with tiles. In2017 46th Interna- tional Conference on Parallel Processing (ICPP), pages 171–180. IEEE, 2017
work page 2017
-
[9]
BurnCloud. NVIDIA H20 GPU Specifications. https: //www.burncloud.com/gpu-catalog/H20.html, 2024
work page 2024
-
[10]
MP-RDMA: enabling RDMA with multi- path transport in datacenters.IEEE/ACM Trans
Guo Chen, Yuanwei Lu, Bojie Li, Kun Tan, Yongqiang Xiong, Peng Cheng, Jiansong Zhang, and Thomas Moscibroda. MP-RDMA: enabling RDMA with multi- path transport in datacenters.IEEE/ACM Trans. Netw., 27(6):2308–2323, 2019. 12
work page 2019
-
[11]
Yihua Cheng, Yuhan Liu, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaoting Feng, Yuyang Huang, Samuel Shen, Kuntai Du, and Junchen Jiang. Lmcache: An efficient kv cache layer for enterprise-scale llm inference.arXiv preprint arXiv:2510.09665, 2025
-
[12]
Michael Davies, Neal Crago, Karthikeyan Sankar- alingam, and Christos Kozyrakis. Efficient llm inference: Bandwidth, compute, synchronization, and capacity are all you need.arXiv preprint arXiv:2507.14397, 2025
-
[13]
Boosting large-scale parallel training efficiency with c4: A communication-driven approach
Jianbo Dong, Bin Luo, Jun Zhang, Pengcheng Zhang, Fei Feng, Yikai Zhu, Ang Liu, Zian Chen, Yi Shi, Hairong Jiao, et al. Boosting large-scale parallel training efficiency with c4: A communication-driven approach. arXiv preprint arXiv:2406.04594, 2024
-
[14]
{Cost-Efficient} large lan- guage model serving for multi-turn conversations with {CachedAttention}
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. {Cost-Efficient} large lan- guage model serving for multi-turn conversations with {CachedAttention}. In2024 USENIX Annual Technical Conference (USENIX ATC 24), pages 111–126, 2024
work page 2024
-
[15]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. Prompt cache: Modular attention reuse for low-latency inference.Pro- ceedings of Machine Learning and Systems, 6:325–338, 2024
work page 2024
-
[16]
Accelerate: Train- ing and inference at scale made simple, efficient and adaptable
Sylvain Gugger, Lysandre Debut, Thomas Wolf, Philipp Schmid, Zachary Mueller, Sourab Mangrulkar, Marc Sun, and Benjamin Bossan. Accelerate: Train- ing and inference at scale made simple, efficient and adaptable. https://github.com/huggingface/ accelerate, 2022
work page 2022
-
[17]
John L Hennessy and David A Patterson.Computer architecture: a quantitative approach. Elsevier, 2011
work page 2011
-
[18]
Changho Hwang, KyoungSoo Park, Ran Shu, Xinyuan Qu, Peng Cheng, and Yongqiang Xiong.{ARK}:{GPU- driven} code execution for distributed deep learning. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), pages 87–101, 2023
work page 2023
-
[19]
Ragcache: Efficient knowledge caching for retrieval-augmented generation
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shu- fan Liu, Xuanzhe Liu, and Xin Jin. Ragcache: Efficient knowledge caching for retrieval-augmented generation. ACM Transactions on Computer Systems, 2024
work page 2024
-
[20]
Andrew G Kegel, Ronald Perez, and Wei Huang. In- put/output memory management unit with protection mode for preventing memory access by i/o devices, Jan- uary 14 2014. US Patent 8,631,212
work page 2014
-
[21]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[22]
Ziming Li, Chenyang Hei, Fuliang Li, Tongrui Liu, Chengxi Gao, Xiuzhu Sha, and Xingwei Wang. Tuccl: Tailored and unified configuration optimizations for high-performance collective communication library. In 2025 IEEE 33rd International Conference on Network Protocols (ICNP), pages 1–11. IEEE, 2025
work page 2025
-
[23]
Reducing gpu offload latency via fine-grained cpu-gpu synchroniza- tion
Daniel Lustig and Margaret Martonosi. Reducing gpu offload latency via fine-grained cpu-gpu synchroniza- tion. In2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), pages 354–365. IEEE, 2013
work page 2013
-
[24]
Mlp-offload: Multi- level, multi-path offloading for llm pre-training to break the gpu memory wall
Avinash Kumar Maurya, M Mustafa Rafique, Franck Cappello, and Bogdan Nicolae. Mlp-offload: Multi- level, multi-path offloading for llm pre-training to break the gpu memory wall. InProceedings of the Interna- tional Conference for High Performance Computing, Networking, Storage and Analysis, pages 1381–1394, 2025
work page 2025
-
[25]
AzurePublicDataset: Azure LLM In- ference Dataset 2023
Microsoft. AzurePublicDataset: Azure LLM In- ference Dataset 2023. https://github.com/ Azure/AzurePublicDataset/blob/master/ AzureLLMInferenceDataset2023.md, 2023
work page 2023
-
[26]
John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. Scalable parallel programming with cuda: Is cuda the parallel programming model that application developers have been waiting for?Queue, 6(2):40–53, 2008
work page 2008
- [27]
-
[28]
NVIDIA. NVIDIA NVLink 4.0 Technology. https: //www.nvidia.com/en-us/data-center/nvlink/, 2025
work page 2025
-
[29]
Chatbot Arena Conversations Dataset
Large Model Systems Organization. Chatbot Arena Conversations Dataset. https://huggingface.co/ datasets/lmsys/chatbot_arena_conversations, 2023
work page 2023
-
[30]
Mar- coni: Prefix caching for the era of hybrid llms.arXiv preprint arXiv:2411.19379, 2024
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Mar- coni: Prefix caching for the era of hybrid llms.arXiv preprint arXiv:2411.19379, 2024
-
[31]
Pci express® base specification revision 5.0 version 1.0
PCI-SIG. Pci express® base specification revision 5.0 version 1.0. Technical report, PCI-SIG, 2019. 13
work page 2019
-
[32]
Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. In Proceedings of the international conference for high per- formance computing, networking, storage and analysis, pages 1–14, 2021
work page 2021
-
[33]
An i/o characterizing study of offloading llm models and kv caches to nvme ssd
Zebin Ren, Krijn Doekemeijer, Tiziano De Matteis, Christian Pinto, Radu Stoica, and Animesh Trivedi. An i/o characterizing study of offloading llm models and kv caches to nvme ssd. InProceedings of the 5th Work- shop on Challenges and Opportunities of Efficient and Performant Storage Systems, pages 23–33, 2025
work page 2025
-
[34]
Enabling efficient GPU communication over mul- tiple NICs with fuselink
Zhenghang Ren, Yuxuan Li, Zilong Wang, Xinyang Huang, Wenxue Li, Kaiqiang Xu, Xudong Liao, Yi- jun Sun, Bowen Liu, Han Tian, Junxue Zhang, Mingfei Wang, Zhizhen Zhong, Guyue Liu, Ying Zhang, and Kai Chen. Enabling efficient GPU communication over mul- tiple NICs with fuselink. InProceedings of the 19th USENIX Symposium on Operating Systems Design and Impl...
work page 2025
-
[35]
Sparq attention: Bandwidth-efficient llm inference.arXiv preprint arXiv:2312.04985, 2023
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. Sparq attention: Bandwidth-efficient llm inference.arXiv preprint arXiv:2312.04985, 2023
-
[36]
Flexgen: high-throughput generative inference of large language models with a single gpu
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. Flexgen: high-throughput generative inference of large language models with a single gpu. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
work page 2023
-
[37]
Dikshant Pratap Singh, Mathialakan Thavappiragasam, and Brice Videau. Efficient intra-node hierarchical par- allelisms and dynamic load balancing strategies on het- erogeneous systems. In2025 IEEE International Paral- lel and Distributed Processing Symposium Workshops (IPDPSW), pages 543–552. IEEE, 2025
work page 2025
-
[38]
Accelerating intra-node gpu communication: A perfor- mance model for multi-path transfers
Amirhossein Sojoodi, Mohammad Akbari, Hamed Shar- ifian, Ali Farazdaghi, Ryan E Grant, and Ahmad Afsahi. Accelerating intra-node gpu communication: A perfor- mance model for multi-path transfers. InProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 449–460, 2025
work page 2025
-
[39]
Collabora- tive bandwidth-efficient intra-node allreduce
Amirhossein Sojoodi, Ali Farazdaghi, Hamed Shari- fian, Ryan E Grant, and Ahmad Afsahi. Collabora- tive bandwidth-efficient intra-node allreduce. In2025 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), pages 63–67. IEEE, 2025
work page 2025
-
[40]
Enhancing intra-node GPU-to-GPU perfor- mance in MPI+UCX through multi-path communication
Amirhossein Sojoodi, Yıltan Hassan Temuçin, and Ah- mad Afsahi. Enhancing intra-node GPU-to-GPU perfor- mance in MPI+UCX through multi-path communication. InProceedings of the 3rd International Workshop on Extreme Heterogeneity Solutions (ExHET 2024). ACM,
work page 2024
-
[41]
Xiaoyong Song, Danyuan Zhou, Kai Li, Jiayuan Chen, Hao Zhang, Xiaoguang Zhang, and Xuxia Zhong. Sur- vey of intra-node gpu interconnection in scale-up net- work: Challenges, status, insights, and future directions. Future Internet, 17(12):537, 2025
work page 2025
-
[42]
Engine-agnostic model hot-swapping for cost-effective llm inference
Radostin Stoyanov, Viktória Spišaková, Adrian Reber, Wesley Armour, Marcin Copik, and Rodrigo Bruno. Engine-agnostic model hot-swapping for cost-effective llm inference. InProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, pages 114–125, 2025
work page 2025
-
[43]
Joaquin Tarraga-Moreno, Daniel Barley, Francisco J An- dujar Munoz, Jesus Escudero-Sahuquillo, Holger Fron- ing, Pedro Javier Garcia, Francisco J Quiles, and Jose Duato. Scalable and efficient intra-and inter-node in- terconnection networks for post-exascale supercomput- ers and data centers.arXiv preprint arXiv:2511.04677, 2025
-
[44]
Joaquin Tarraga-Moreno, Jesus Escudero-Sahuquillo, Pedro Javier Garcia, and Francisco J Quiles. Under- standing intra-node communication in hpc systems and datacenters.arXiv preprint arXiv:2502.20965, 2025
-
[45]
Efficient multi-path NVLink/PCIe-aware UCX-based collective communi- cation for deep learning
Yıltan Hassan Temuçin, Amirhossein Sojoodi, Pedram Alizadeh, and Ahmad Afsahi. Efficient multi-path NVLink/PCIe-aware UCX-based collective communi- cation for deep learning. In2021 IEEE Symposium on High-Performance Interconnects (HOTI), pages 25–34. IEEE, 2021
work page 2021
-
[46]
Performance models for cpu-gpu data transfers
Ben Van Werkhoven, Jason Maassen, Frank J Seinstra, and Henri E Bal. Performance models for cpu-gpu data transfers. In2014 14th IEEE/ACM International Sym- posium on Cluster, Cloud and Grid Computing, pages 11–20. IEEE, 2014
work page 2014
- [47]
-
[48]
Design, implementation and evalua- tion of congestion control for multipath {TCP}
Damon Wischik, Costin Raiciu, Adam Greenhalgh, and Mark Handley. Design, implementation and evalua- tion of congestion control for multipath {TCP}. In8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11), 2011. 14
work page 2011
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Learned prefix caching for efficient llm inference
Dongsheng Yang, Austin Li, Kai Li, and Wyatt Lloyd. Learned prefix caching for efficient llm inference. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[51]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information pro- cessing systems, 37:62557–62583, 2024
work page 2024
-
[52]
{DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 193–210, 2024. 15
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.