Recognition: 2 theorem links
· Lean TheoremSelective LoRA for Visual Tokens and Attention Heads
Pith reviewed 2026-05-16 20:14 UTC · model grok-4.3
The pith
Image-LoRA matches standard LoRA by adapting only visual tokens and a small set of attention heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
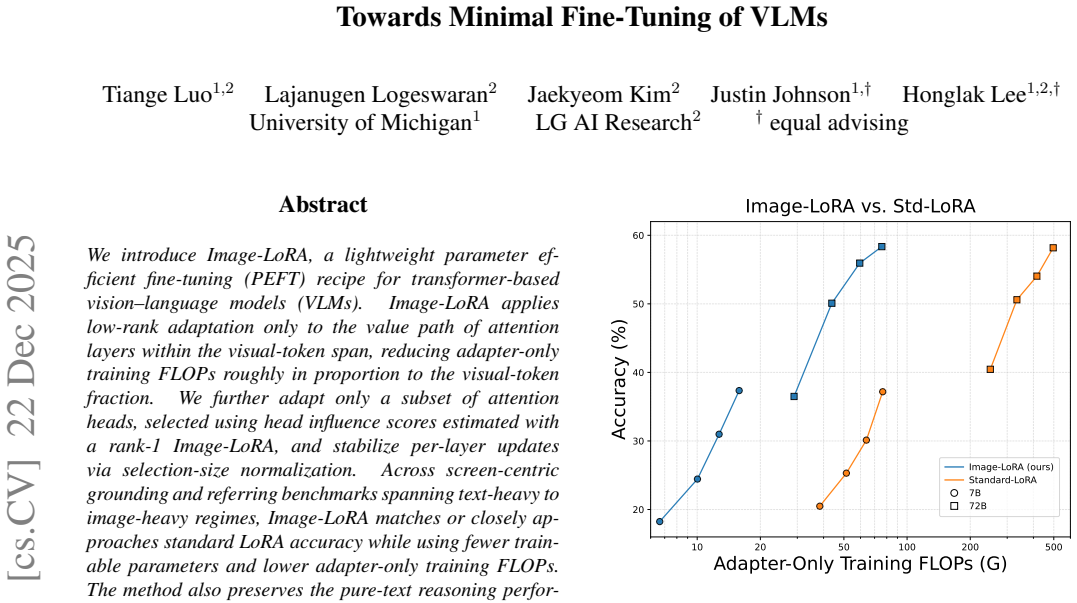
Image-LoRA treats LoRA as a token-level residual update applied exclusively to visual tokens and further restricts it to the value projection of a compact subset of attention heads identified by a single-pass rank-1 influence probe on visual tokens alone. This design achieves performance comparable to standard LoRA across visual localization tasks, with better efficiency in image-heavy settings, while leaving the pure-text forward pass of the frozen model unchanged.
What carries the argument
A one-pass rank-1 influence probe on visual tokens alone that selects a compact subset of attention heads whose value paths then receive the token-selective LoRA update.
If this is right
- Trainable parameters and adapter-only training FLOPs drop relative to standard LoRA.
- Performance matches or closely approaches standard LoRA on visual localization benchmarks, especially when image tokens are numerous.
- The pure-text forward pass of the frozen backbone remains exactly as before when no visual tokens are present.
- The same recipe generalizes to TextVQA and VideoQA while preserving accuracy on GSM8K.
- A stronger information bottleneck on ViLP can produce gains over standard LoRA.
Where Pith is reading between the lines
- The same one-pass probe idea could be tested on other parameter-efficient methods such as prefix tuning or adapters to see if similar head selectivity appears.
- Because the text-only path is untouched, the approach may suit pipelines that alternate between vision-language and pure-text queries without retraining.
- The favorable scaling in image-token-heavy regimes suggests the method could be combined with token-compression techniques to handle even longer visual inputs.
- Re-running the probe at different training checkpoints might reveal whether the selected heads stay stable or shift as fine-tuning progresses.
Load-bearing premise
The one-pass influence estimate from a rank-1 visual-token-only probe accurately identifies the compact subset of attention heads worth adapting.
What would settle it
If the probe-selected heads, when adapted with Image-LoRA, produce accuracy more than a few points below standard LoRA on the controlled visual-localization benchmarks while random heads of the same count do not, the value of the probe-based selection would be falsified.
Figures









read the original abstract
Low-rank adaptation (LoRA) is widely used for parameter-efficient fine-tuning, but its standard all-token, all-head design ignores the heterogeneous structure of vision language model (VLM) inputs. We introduce \emph{Image-LoRA}, a vision-oriented PEFT recipe that views LoRA as a token-level residual update and applies this update only to visual tokens. Image-LoRA further restricts adaptation to the value path of a compact subset of attention heads, selected using a one-pass influence estimate from a rank-1 visual-token-only probe. This token-, head-, and value-selective design reduces trainable parameters and adapter-only training FLOPs while leaving the pure-text forward pass of the frozen backbone unchanged when no visual tokens are present. Across visual localization benchmarks with controlled text:image token ratios, Image-LoRA matches or closely approaches standard LoRA, while showing especially favorable trade-offs in image-token-heavy regimes. We further validate its generality on TextVQA and VideoQA, verify pure-text preservation on GSM8K, and show on ViLP that a stronger information bottleneck can yield gains over standard LoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Image-LoRA, a selective PEFT method for VLMs that applies LoRA updates exclusively to visual tokens and restricts them to the value projections of a compact subset of attention heads. Head selection uses a one-pass rank-1 influence estimate from a visual-token-only probe. The approach reduces trainable parameters and adapter training FLOPs relative to standard LoRA, leaves the frozen backbone's pure-text forward pass unchanged, and is evaluated on visual localization benchmarks with controlled text:image token ratios plus TextVQA, VideoQA, and GSM8K. The central claim is that Image-LoRA matches or closely approaches standard LoRA performance while offering better efficiency trade-offs in image-token-heavy regimes, with additional validation that stronger bottlenecks can improve over standard LoRA on ViLP.
Significance. If the quantitative claims hold, the work would be a useful contribution to efficient adaptation of VLMs by exploiting input heterogeneity. The token-level residual view, value-only restriction, and one-pass selection heuristic could reduce compute without sacrificing accuracy, and the pure-text preservation property is a practical strength. The observation that stronger bottlenecks can outperform standard LoRA on ViLP suggests a broader design principle worth exploring.
major comments (2)
- [§3] §3 (Method): The one-pass rank-1 visual-token-only probe is presented as sufficient to identify the compact head subset whose value-path updates suffice under full LoRA training. However, this selection ignores query/key paths and cross-head interactions that arise during joint adapter training. The manuscript must supply an ablation (e.g., correlation between probe ranks and full-training head importance, or performance of probe-selected vs. random/full-training-selected heads) to show the heuristic is not an artifact of the reported benchmarks.
- [§4] §4 (Experiments): The headline claim that Image-LoRA 'matches or closely approaches standard LoRA' is unsupported by any numerical results, deltas, standard deviations, or ablation tables. The abstract and text supply no accuracies, parameter counts, or FLOPs for the controlled token-ratio regimes, making it impossible to evaluate the 'especially favorable trade-offs' or the ViLP bottleneck gains. Full result tables with error bars and statistical tests are required.
minor comments (1)
- [Abstract] Abstract: The phrase 'visual localization benchmarks with controlled text:image token ratios' is used without naming the datasets or reporting any concrete metrics, which reduces the immediate informativeness of the summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing Image-LoRA. The comments highlight important aspects of methodological validation and experimental reporting that we will address in the revision. We respond point-by-point below.
read point-by-point responses
-
Referee: [§3] §3 (Method): The one-pass rank-1 visual-token-only probe is presented as sufficient to identify the compact head subset whose value-path updates suffice under full LoRA training. However, this selection ignores query/key paths and cross-head interactions that arise during joint adapter training. The manuscript must supply an ablation (e.g., correlation between probe ranks and full-training head importance, or performance of probe-selected vs. random/full-training-selected heads) to show the heuristic is not an artifact of the reported benchmarks.
Authors: We agree that the one-pass rank-1 probe is a heuristic that does not explicitly capture query/key paths or cross-head interactions during joint training. To substantiate the selection procedure, we will add a dedicated ablation subsection in the revised §3. This will include: (i) Spearman rank correlation between the probe-derived head scores and head importance measured from full LoRA training runs, and (ii) performance tables comparing probe-selected heads against random subsets and against heads chosen by exhaustive full-training importance. These results will be reported on the same visual localization benchmarks used in the main experiments. revision: yes
-
Referee: [§4] §4 (Experiments): The headline claim that Image-LoRA 'matches or closely approaches standard LoRA' is unsupported by any numerical results, deltas, standard deviations, or ablation tables. The abstract and text supply no accuracies, parameter counts, or FLOPs for the controlled token-ratio regimes, making it impossible to evaluate the 'especially favorable trade-offs' or the ViLP bottleneck gains. Full result tables with error bars and statistical tests are required.
Authors: We acknowledge that the initial submission omitted explicit numerical values, deltas, and error statistics in the abstract and main experimental narrative. In the revision we will: (i) expand all tables in §4 with means ± standard deviations over at least three random seeds, (ii) add columns for trainable parameter counts and adapter-only FLOPs under each token-ratio regime, (iii) include paired statistical tests (e.g., t-tests with p-values) between Image-LoRA and standard LoRA, and (iv) update the abstract and §4 text with the key accuracy deltas and efficiency numbers. The ViLP bottleneck comparison will likewise be augmented with these statistics. revision: yes
Circularity Check
No significant circularity; selection heuristic and performance claims remain independent of fitted parameters
full rationale
The paper describes Image-LoRA as a heuristic that applies LoRA updates selectively to visual tokens and a compact subset of attention heads chosen via a one-pass rank-1 probe. No equations, derivations, or self-citations are presented that reduce the claimed parity with standard LoRA to quantities defined by the same fitted values or by construction. The probe is treated as an independent preprocessing step whose output is not re-used to define the final training objective or evaluation metric. Results are reported on external benchmarks (visual localization, TextVQA, VideoQA, GSM8K) without any reduction of the headline gains to the probe's own outputs. This is a standard empirical PEFT design whose central claims rest on experimental comparison rather than definitional or self-referential closure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ingeol Baek, Hwan Chang, Sunghyun Ryu, and Hwanhee Lee. How do large vision-language models see text in image? unveiling the distinctive role of ocr heads.arXiv preprint arXiv:2505.15865, 2025. 1
-
[2]
Qingqing Cao, Bhargavi Paranjape, and Hannaneh Ha- jishirzi. Pumer: Pruning and merging tokens for efficient vision language models.arXiv preprint arXiv:2305.17530,
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024. 3
work page 2024
-
[4]
Glyph: Scaling context windows via visual-text com- pression.arXiv e-prints, pages arXiv–2510, 2025
Jiale Cheng, Yusen Liu, Xinyu Zhang, Yulin Fei, Wenyi Hong, Ruiliang Lyu, Weihan Wang, Zhe Su, Xiaotao Gu, et al. Glyph: Scaling context windows via visual-text com- pression.arXiv e-prints, pages arXiv–2510, 2025. 1
work page 2025
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 1, 2, 5, 7 9
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
On the effectiveness of parameter-efficient fine-tuning
Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. InProceedings of the AAAI conference on artificial intelligence, pages 12799–12807,
-
[7]
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
Peng Gao, Jiaming Han, Renrui Zhang, Ziyi Lin, Shijie Geng, Aojun Zhou, Wei Zhang, Pan Lu, Conghui He, Xi- angyu Yue, et al. Llama-adapter v2: Parameter-efficient vi- sual instruction model.arXiv preprint arXiv:2304.15010,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Parameter- efficient transfer learning with diff pruning.arXiv preprint arXiv:2012.07463, 2020
Demi Guo, Alexander M Rush, and Yoon Kim. Parameter- efficient transfer learning with diff pruning.arXiv preprint arXiv:2012.07463, 2020. 3
-
[9]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations, 2022. 1, 3
work page 2022
-
[10]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Your large vision-language model only needs a few attention heads for visual grounding
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9339–9350, 2025. 1, 3
work page 2025
-
[12]
ReferItGame: Referring to objects in pho- tographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to objects in pho- tographs of natural scenes. InProceedings of the 2014 Con- ference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 787–798, Doha, Qatar, 2014. Associa- tion for Computational Linguistics. 2, 5, 6
work page 2014
-
[13]
Samir Khaki, Xiuyu Li, Junxian Guo, Ligeng Zhu, Chenfeng Xu, Konstantinos N Plataniotis, Amir Yazdanbakhsh, Kurt Keutzer, Song Han, and Zhijian Liu. Sparselora: Accelerat- ing llm fine-tuning with contextual sparsity.arXiv preprint arXiv:2506.16500, 2025. 3
-
[14]
Screenspot-pro: Gui grounding for professional high-resolution computer use,
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: Gui grounding for professional high- resolution computer use.arXiv preprint arXiv:2504.07981,
-
[15]
Probing visual language priors in VLMs
Tiange Luo, Ang Cao, Gunhee Lee, Justin Johnson, and Honglak Lee. Probing visual language priors in VLMs. In Forty-second International Conference on Machine Learn- ing, 2025. 1, 2, 5, 7
work page 2025
-
[16]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog
AI Meta. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog. Retrieved December, 20:2024, 2024. 9
work page 2024
-
[17]
Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019. 3
work page 2019
-
[18]
Lora with- out regret.Thinking Machines Lab: Connectionism, 2025
John Schulman and Thinking Machines Lab. Lora with- out regret.Thinking Machines Lab: Connectionism, 2025. https://thinkingmachines.ai/blog/lora/. 1, 3, 9
work page 2025
-
[19]
Lora vs full fine-tuning: An illusion of equivalence.arXiv preprint arXiv:2410.21228, 2024
Reece Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. Lora vs full fine-tuning: An illusion of equivalence.arXiv preprint arXiv:2410.21228, 2024. 3
-
[20]
Yi-Lin Sung, Varun Nair, and Colin A Raffel. Training neu- ral networks with fixed sparse masks.Advances in Neural Information Processing Systems, 34:24193–24205, 2021. 3
work page 2021
-
[21]
Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks
Yi-Lin Sung, Jaemin Cho, and Mohit Bansal. Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5227–5237,
-
[22]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Spe- cialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418, 2019. 3
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[23]
Han Wang, Yongjie Ye, Bingru Li, Yuxiang Nie, Jinghui Lu, Jingqun Tang, Yanjie Wang, and Can Huang. Vision as lora. arXiv preprint arXiv:2503.20680, 2025. 3
-
[24]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek- ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19792–19802, 2025. 3
work page 2025
-
[26]
Bitfit: Simple parameter- efficient fine-tuning for transformer-based masked language-models,
Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.arXiv preprint arXiv:2106.10199,
-
[27]
Low-rank few-shot adaptation of vision-language models
Maxime Zanella and Ismail Ben Ayed. Low-rank few-shot adaptation of vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1593–1603, 2024. 3
work page 2024
-
[28]
Jiarui Zhang, Mahyar Khayatkhoei, Prateek Chhikara, and Filip Ilievski. Mllms know where to look: Training-free per- ception of small visual details with multimodal llms.arXiv preprint arXiv:2502.17422, 2025. 3
-
[29]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget alloca- tion for parameter-efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Mengjie Zhao, Tao Lin, Fei Mi, Martin Jaggi, and Hin- rich Sch ¨utze. Masking as an efficient alternative to fine- tuning for pretrained language models.arXiv preprint arXiv:2004.12406, 2020. 3
-
[32]
Mova: Adapting mixture of vision experts to multimodal context
Zhuofan Zong, Bingqi Ma, Dazhong Shen, Guanglu Song, Hao Shao, Dongzhi Jiang, Hongsheng Li, and Yu Liu. Mova: Adapting mixture of vision experts to multimodal context. Advances in Neural Information Processing Systems, 37: 103305–103333, 2024. 3 10 A. Method Details A.1. Head Selection Procedure (details) Visual-only gradients & Different ratiosFor our he...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.