Recognition: 2 theorem links
· Lean TheoremIterative Inference-time Scaling with Adaptive Frequency Steering for Image Super-Resolution
Pith reviewed 2026-05-16 19:27 UTC · model grok-4.3
The pith
A training-free iterative method uses adaptive frequency steering to resolve the perception-fidelity conflict in diffusion image super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that Iterative Diffusion Inference-Time Scaling with Adaptive Frequency Steering (IAFS) overcomes the limitations of reward-driven particle optimization and optimal-path search by jointly using iterative refinement and frequency-aware particle fusion, resulting in balanced reconstruction that improves both perceptual quality and structural fidelity.
What carries the argument
Adaptive frequency-aware particle fusion performed iteratively to integrate high-frequency details with low-frequency structures during refinement.
If this is right
- Improved balance between perceptual detail and structural accuracy in generated super-resolution images
- Outperformance over existing inference-time scaling methods across various diffusion SR models
- Training-free application that can be added to existing pipelines
- More accurate reconstruction of different image details through adaptive integration
Where Pith is reading between the lines
- This approach implies that frequency-based steering could help in other areas of generative modeling where quality and fidelity conflict, such as text-to-image synthesis.
- Future work might test if the iterative process can be accelerated or combined with other optimization techniques for efficiency gains.
- The method highlights the potential of adaptive mechanisms in inference scaling to avoid common pitfalls like over-smoothing or inconsistency.
Load-bearing premise
The iterative application of adaptive frequency-aware particle fusion does not introduce new artifacts or accumulate errors over multiple refinement steps.
What would settle it
A direct comparison on standard benchmarks showing whether IAFS iterations improve or degrade metrics like LPIPS for perception and PSNR/SSIM for fidelity, or if visual artifacts emerge in later steps.
Figures






read the original abstract
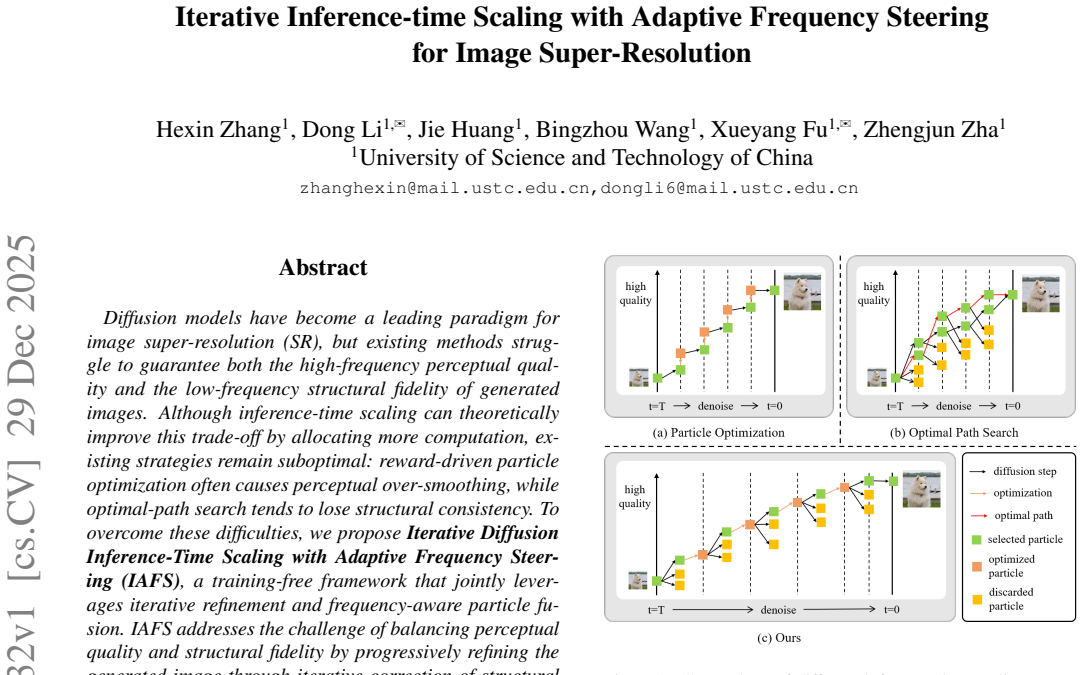
Diffusion models have become a leading paradigm for image super-resolution (SR), but existing methods struggle to guarantee both the high-frequency perceptual quality and the low-frequency structural fidelity of generated images. Although inference-time scaling can theoretically improve this trade-off by allocating more computation, existing strategies remain suboptimal: reward-driven particle optimization often causes perceptual over-smoothing, while optimal-path search tends to lose structural consistency. To overcome these difficulties, we propose Iterative Diffusion Inference-Time Scaling with Adaptive Frequency Steering (IAFS), a training-free framework that jointly leverages iterative refinement and frequency-aware particle fusion. IAFS addresses the challenge of balancing perceptual quality and structural fidelity by progressively refining the generated image through iterative correction of structural deviations. Simultaneously, it ensures effective frequency fusion by adaptively integrating high-frequency perceptual cues with low-frequency structural information, allowing for a more accurate and balanced reconstruction across different image details. Extensive experiments across multiple diffusion-based SR models show that IAFS effectively resolves the perception-fidelity conflict, yielding consistently improved perceptual detail and structural accuracy, and outperforming existing inference-time scaling methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Iterative Diffusion Inference-Time Scaling with Adaptive Frequency Steering (IAFS), a training-free framework for diffusion-based image super-resolution. It claims to resolve the perception-fidelity trade-off through iterative refinement that corrects structural deviations combined with adaptive fusion of high-frequency perceptual cues and low-frequency structural information, outperforming existing inference-time scaling methods such as reward-driven particle optimization and optimal-path search across multiple diffusion SR models.
Significance. If the iterative correction mechanism proves stable, IAFS would offer a practical, training-free way to improve the balance between perceptual detail and structural accuracy in existing diffusion SR pipelines. This could be broadly useful given the prevalence of diffusion models in SR, provided the frequency-steering steps demonstrably avoid introducing new artifacts or accumulating drift.
major comments (2)
- [Abstract] Abstract: the central claim that IAFS 'progressively refin[es] … through iterative correction of structural deviations' rests on an unspecified reference-free proxy for measuring those deviations. Without an explicit metric (e.g., particle variance, frequency-band consistency, or reconstruction consistency), it is impossible to verify that successive fusion steps suppress rather than amplify low-frequency drift, directly undermining the resolution of the perception-fidelity conflict.
- [Method] Method description (inferred from abstract): the adaptive frequency-aware particle fusion is presented at a high level without equations or pseudocode specifying how high- and low-frequency components are weighted, selected, or fused at each iteration. This omission is load-bearing because the claimed superiority over reward-driven and optimal-path baselines depends on the precise fusion rule.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have revised the manuscript to improve clarity and reproducibility while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that IAFS 'progressively refin[es] … through iterative correction of structural deviations' rests on an unspecified reference-free proxy for measuring those deviations. Without an explicit metric (e.g., particle variance, frequency-band consistency, or reconstruction consistency), it is impossible to verify that successive fusion steps suppress rather than amplify low-frequency drift, directly undermining the resolution of the perception-fidelity conflict.
Authors: We thank the referee for this important clarification request. The iterative correction mechanism uses a reference-free low-frequency consistency proxy defined as the L2 distance between low-pass filtered versions of particles across consecutive iterations (detailed in Section 3.2 of the full manuscript). This measure directly detects and corrects structural drift by prioritizing fusion steps that reduce band-specific variance. We will explicitly name and briefly describe this proxy in the revised abstract to make the claim verifiable without altering the reported results. revision: yes
-
Referee: [Method] Method description (inferred from abstract): the adaptive frequency-aware particle fusion is presented at a high level without equations or pseudocode specifying how high- and low-frequency components are weighted, selected, or fused at each iteration. This omission is load-bearing because the claimed superiority over reward-driven and optimal-path baselines depends on the precise fusion rule.
Authors: We agree that the fusion rule requires more explicit specification for full reproducibility. The adaptive weighting is governed by an energy-ratio-based steering function that computes per-band weights from the ratio of high-frequency perceptual energy to low-frequency structural consistency (see Equation 4 and the surrounding derivation in Section 3.3). We will add the complete mathematical formulation together with pseudocode for the iterative fusion loop in the revised method section. revision: yes
Circularity Check
No significant circularity; method is procedurally defined without self-referential reduction
full rationale
The paper introduces IAFS as a training-free inference-time framework that performs iterative refinement via frequency-aware particle fusion. No equations, fitted parameters, or self-citations are shown that reduce the claimed perceptual-structural improvements to redefinitions of inputs or prior results by construction. The central procedure is described as a new algorithmic combination (iterative correction of structural deviations plus adaptive high/low-frequency fusion) rather than a renaming or statistical forcing of existing quantities. The derivation chain remains self-contained against external benchmarks and does not rely on load-bearing self-citations or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative correction of structural deviations can be performed without destabilizing the diffusion trajectory
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IAFS addresses the challenge of balancing perceptual quality and structural fidelity by progressively refining the generated image through iterative correction of structural deviations... adaptively integrating high-frequency perceptual cues with low-frequency structural information
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we adopt an iterative strategy that uses the output of each round as pseudo-GT to guide subsequent sampling, and introduce frequency-domain fusion at each timestep
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition workshops, pages 126–135, 2017
work page 2017
-
[2]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6228–6237, 2018
work page 2018
-
[3]
Toward real-world single image super-resolution: A new benchmark and a new model
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. InProceedings of the IEEE/CVF international conference on computer vision, pages 3086–3095, 2019
work page 2019
-
[4]
D. Comaniciu and P. Meer. Mean shift: a robust approach toward feature space analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(5):603–619, 2002
work page 2002
-
[5]
Inference-Time Scaling of Diffusion Language Models via Trajectory Refinement
Meihua Dang, Jiaqi Han, Minkai Xu, Kai Xu, Akash Sri- vastava, and Stefano Ermon. Inference-time scaling of dif- fusion language models with particle gibbs sampling.arXiv preprint arXiv:2507.08390, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Re- marks on some nonparametric estimates of a density func- tion
Richard A Davis, Keh-Shin Lii, and Dimitris N Politis. Re- marks on some nonparametric estimates of a density func- tion. InSelected Works of Murray Rosenblatt, pages 95–100. Springer, 2011
work page 2011
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[8]
Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional net- works.IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015
work page 2015
-
[9]
Mahdi Farahbakhsh, Vishnu Teja Kunde, Dileep Kalathil, Krishna Narayanan, and Jean-Francois Chamber- land. Inference-time search using side information for diffusion-based image reconstruction.arXiv preprint arXiv:2510.03352, 2025
-
[10]
Super- resolution from a single image
Daniel Glasner, Shai Bagon, and Michal Irani. Super- resolution from a single image. In2009 IEEE 12th interna- tional conference on computer vision, pages 349–356. IEEE, 2009
work page 2009
-
[11]
Yingqing Guo, Yukang Yang, Hui Yuan, and Mengdi Wang. Training-free guidance beyond differentiability: Scalable path steering with tree search in diffusion and flow models. arXiv preprint arXiv:2502.11420, 2025
-
[12]
Yuyang Hu, Kangfu Mei, Mojtaba Sahraee-Ardakan, Ulug- bek S Kamilov, Peyman Milanfar, and Mauricio Del- bracio. Kernel density steering: Inference-time scaling via mode seeking for image restoration.arXiv preprint arXiv:2507.05604, 2025
-
[13]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. InProceed- ings of the IEEE international conference on computer vi- sion, pages 1501–1510, 2017
work page 2017
-
[14]
Purvish Jajal, Nick John Eliopoulos, Benjamin Shiue- Hal Chou, George K Thiruvathukal, James C Davis, and Yung-Hsiang Lu. Inference-time alignment of diffusion models with evolutionary algorithms.arXiv preprint arXiv:2506.00299, 2025
-
[15]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
work page 2021
-
[16]
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models.Advances in neural infor- mation processing systems, 34:21696–21707, 2021
work page 2021
-
[17]
Photo- realistic single image super-resolution using a generative ad- versarial network
Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo- realistic single image super-resolution using a generative ad- versarial network. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690, 2017
work page 2017
-
[18]
Srdiff: Single image super-resolution with diffusion probabilistic models
Haoying Li, Yifan Yang, Meng Chang, Shiqi Chen, Huajun Feng, Zhihai Xu, Qi Li, and Yueting Chen. Srdiff: Single image super-resolution with diffusion probabilistic models. Neurocomputing, 479:47–59, 2022
work page 2022
-
[19]
Xiner Li, Masatoshi Uehara, Xingyu Su, Gabriele Scalia, Tommaso Biancalani, Aviv Regev, Sergey Levine, and Shui- wang Ji. Dynamic search for inference-time alignment in diffusion models.arXiv preprint arXiv:2503.02039, 2025
-
[20]
Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184, 2024
Zhengyang Liang, Hao He, Ceyuan Yang, and Bo Dai. Scaling laws for diffusion transformers.arXiv preprint arXiv:2410.08184, 2024
-
[21]
Deepwsd: Projecting degradations in perceptual space to wasserstein distance in deep feature space
Xingran Liao, Baoliang Chen, Hanwei Zhu, Shiqi Wang, Mingliang Zhou, and Sam Kwong. Deepwsd: Projecting degradations in perceptual space to wasserstein distance in deep feature space. InProceedings of the 30th ACM Inter- national Conference on Multimedia, pages 970–978, 2022
work page 2022
-
[22]
Diff- bir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diff- bir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024
work page 2024
-
[23]
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu- Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffu- sion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732, 2025
-
[24]
Shunqi Mao, Wei Guo, Chaoyi Zhang, Jieting Long, Ke Xie, and Weidong Cai. Ctrl-z sampling: Diffusion sampling with controlled random zigzag explorations.arXiv preprint arXiv:2506.20294, 2025
-
[25]
Yuta Oshima, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Inference-time text-to-video alignment with diffu- sion latent beam search.arXiv preprint arXiv:2501.19252, 2025
-
[26]
Emanuel Parzen. On estimation of a probability density func- tion and mode.The annals of mathematical statistics, 33(3): 1065–1076, 1962
work page 1962
-
[27]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[28]
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement.IEEE transactions on pattern analysis and machine intelligence, 45(4):4713–4726, 2022
work page 2022
-
[29]
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025
-
[30]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[31]
Yang Song and Stefano Ermon. Generative modeling by esti- mating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
work page 2019
-
[32]
V olker Steinbiss, Bach-Hiep Tran, and Hermann Ney. Im- provements in beam search. InICSLP, pages 2143–2146, 1994
work page 1994
-
[33]
Xun Su, Jianming Huang, Yang Yusen, Zhongxi Fang, and Hiroyuki Kasai. Navigating the exploration-exploitation tradeoff in inference-time scaling of diffusion models.arXiv preprint arXiv:2508.12361, 2025
-
[34]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tommaso Biancalani. Inference-time alignment in diffusion models with reward- guided generation: Tutorial and review.arXiv preprint arXiv:2501.09685, 2025
-
[35]
Gabriele Valentini, Eliseo Ferrante, and Marco Dorigo. The best-of-n problem in robot swarms: Formalization, state of the art, and novel perspectives.Frontiers in Robotics and AI, 4:9, 2017
work page 2017
-
[36]
Ex- ploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Ex- ploring clip for assessing the look and feel of images. InPro- ceedings of the AAAI conference on artificial intelligence, pages 2555–2563, 2023
work page 2023
-
[37]
Component divide-and-conquer for real-world image super-resolution
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qix- iang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and-conquer for real-world image super-resolution. In European conference on computer vision, pages 101–117. Springer, 2020
work page 2020
-
[38]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution.Advances in Neural Information Process- ing Systems, 37:92529–92553, 2024
work page 2024
-
[39]
Seesr: Towards semantics- aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics- aware real-world image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25456–25467, 2024
work page 2024
-
[40]
One-step diffusion-based real-world image super-resolution with visual perception distillation
Xue Wu, Jingwei Xin, Zhijun Tu, Jie Hu, Jie Li, Nannan Wang, and Xinbo Gao. One-step diffusion-based real-world image super-resolution with visual perception distillation. arXiv preprint arXiv:2506.02605, 2025
-
[41]
Learning similarity with cosine similarity ensemble.Information sciences, 307: 39–52, 2015
Peipei Xia, Li Zhang, and Fanzhang Li. Learning similarity with cosine similarity ensemble.Information sciences, 307: 39–52, 2015
work page 2015
-
[42]
Jianchao Yang, John Wright, Thomas S Huang, and Yi Ma. Image super-resolution via sparse representation.IEEE transactions on image processing, 19(11):2861–2873, 2010
work page 2010
-
[43]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022
work page 2022
-
[44]
Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization
Tao Yang, Rongyuan Wu, Peiran Ren, Xuansong Xie, and Lei Zhang. Pixel-aware stable diffusion for realistic image super-resolution and personalized stylization. InEuropean conference on computer vision, pages 74–91. Springer, 2024
work page 2024
-
[45]
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. Resshift: Efficient diffusion model for image super- resolution by residual shifting.Advances in Neural Infor- mation Processing Systems, 36:13294–13307, 2023
work page 2023
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018
work page 2018
-
[47]
Xiangcheng Zhang, Haowei Lin, Haotian Ye, James Zou, Jianzhu Ma, Yitao Liang, and Yilun Du. Inference-time scaling of diffusion models through classical search.arXiv preprint arXiv:2505.23614, 2025. Iterative Inference-time Scaling with Adaptive Frequency Steering for Image Super-Resolution Supplementary Material
-
[48]
Theoretical Analysis In this section, we present a rigorous derivation of Eq. 4 and Eq. 5 from the main text, providing detailed mathematical steps that were omitted for brevity. We also visualize the spectral evolution of the intermediate latent variables across the reverse diffusion process, as shown in Fig. 5. These curves reveal how frequency componen...
-
[49]
We first provide additional details on the fre- quency decoupling mechanism within the AFS framework
Implementation Details In this section, we present supplementary derivations and clarifications that support the formulations introduced in the main paper. We first provide additional details on the fre- quency decoupling mechanism within the AFS framework. In addition, we supplement and compare different reward scheduling strategies in the particle optim...
-
[50]
Additional Ablation Studies In this section, we provide a comprehensive analysis of the core design choices within our IAFS framework. We first investigate the impact of different perceptual metrics when serving as the guidance reward during the initial iteration. Subsequently, we conduct a fine-grained search to identify the optimal temporal thresholds f...
-
[51]
Runtime & Computational Complexity To assess the feasibility of IAFS in practical deployment scenarios, we conducted a systematic computational cost analysis, benchmarking our proposed method against ex- isting inference-time scaling techniques. This section first outlines the experimental setup and testing protocols, fol- lowed by a quantitative comparis...
-
[52]
More Qualitative Results To further substantiate the robustness of our proposed IAFS framework, we provide an extended qualitative comparison on real-world images. We integrate various inference-time scaling strategies—specifically Best-of-N(BON), Beam Search (BS), FK-Steering (FK), and Kernel Density Steer- ing (KDS)—into the ResShift backbone and evalua...
-
[53]
The primary bot- tleneck originates from the computational overhead intro- duced during inference
Potential Limitations While the proposed Iterative Diffusion Inference-Time Scaling with Adaptive Frequency Steering (IAFS) effec- tively mitigates the inherent conflict between perceptual en- hancement and structural fidelity in super-resolution, the method still presents notable limitations. The primary bot- tleneck originates from the computational ove...
work page 2056
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.