Improved Evidence Extraction and Metrics for Document Inconsistency Detection with LLMs
Pith reviewed 2026-05-16 18:05 UTC · model grok-4.3
The pith
A redact-and-retry framework with constrained filtering improves LLM evidence extraction for detecting document inconsistencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that their redact-and-retry framework with constrained filtering substantially improves evidence extraction performance over other prompting methods for document inconsistency detection, supported by new comprehensive evidence-extraction metrics and validated on a released semi-synthetic dataset.
What carries the argument
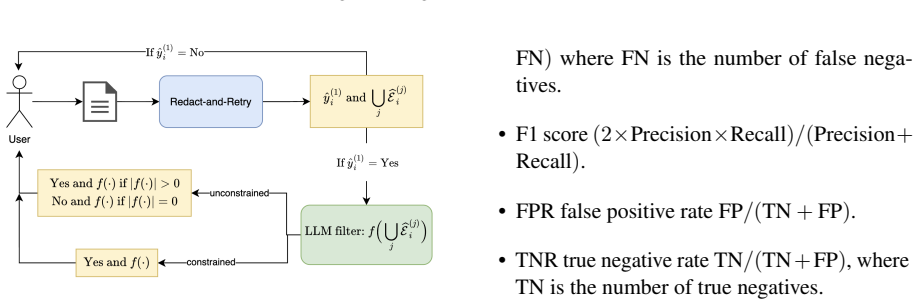
The redact-and-retry framework with constrained filtering, which iteratively removes inconsistent parts and retries with constraints to refine evidence extraction.
Load-bearing premise
The new evidence-extraction metrics accurately reflect true extraction quality and the gains seen on the semi-synthetic dataset will hold for actual real-world documents.
What would settle it
A direct comparison on a collection of real-world inconsistent documents where human experts rate the extracted evidence quality, checking if the framework still outperforms baselines and if metric scores match the ratings.
Figures
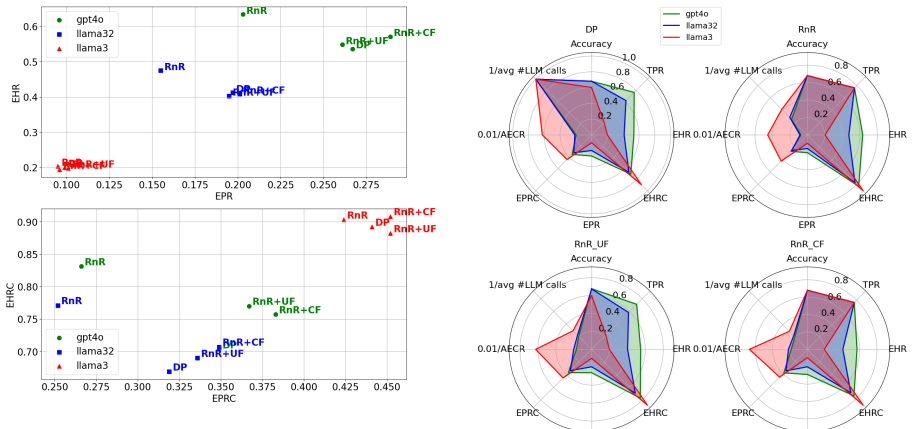



read the original abstract
Large language models (LLMs) are becoming useful in many domains due to their impressive abilities that arise from large training datasets and large model sizes. However, research on LLM-based approaches to document inconsistency detection is relatively limited. We address this gap by investigating evidence extraction capabilties of LLMs for document inconsistency detection. To this end, we introduce new comprehensive evidence-extraction metrics and a redact-and-retry framework with constrained filtering that substantially improves evidence extraction performance over other prompting methods. We support our approach with strong experimental results and release a new semi-synthetic dataset for evaluating evidence extraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces new evidence-extraction metrics for LLM-based document inconsistency detection and proposes a redact-and-retry framework with constrained filtering. It claims this framework substantially improves evidence extraction performance over standard prompting methods, supported by experimental results on a new semi-synthetic dataset that is released with the work.
Significance. If the central improvements hold under proper validation, the work could provide practical prompting techniques and evaluation tools for inconsistency detection tasks. However, the absence of human correlation studies for the new metrics and reliance on semi-synthetic data limit the assessed significance, as gains may not transfer to real documents.
major comments (3)
- [Metrics definition and validation section] The new evidence-extraction metrics are introduced without any reported correlation to human judgments or established extraction measures (e.g., no inter-annotator agreement or comparison to ROUGE/BLEU variants on held-out annotations). This directly undermines the claim that reported improvements reflect genuine extraction quality rather than metric artifacts.
- [Dataset and experimental setup] The semi-synthetic dataset construction is not shown to approximate real-world inconsistency distributions; no ablation or transfer experiments on authentic documents are reported. This makes the generalization claim in the abstract load-bearing but unsupported.
- [Experiments and results] Experimental results lack statistical details such as variance across runs, significance tests, or full baseline comparisons (including parameter counts and prompt lengths). The abstract's assertion of 'strong experimental results' cannot be assessed without these.
minor comments (2)
- [Framework description] Notation for the constrained filtering step is introduced without a formal definition or pseudocode, making the framework hard to reproduce from the text alone.
- [Abstract and results] The abstract claims 'substantial improvements' but the results section should include effect sizes or relative gains with confidence intervals for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Metrics definition and validation section] The new evidence-extraction metrics are introduced without any reported correlation to human judgments or established extraction measures (e.g., no inter-annotator agreement or comparison to ROUGE/BLEU variants on held-out annotations). This directly undermines the claim that reported improvements reflect genuine extraction quality rather than metric artifacts.
Authors: We agree that direct validation against human judgments would strengthen the metrics. In the revised manuscript we will add a human annotation study on a held-out subset of the dataset, report inter-annotator agreement, and compute correlations (Pearson and Spearman) between our metrics and human scores. We will also include comparisons against ROUGE and BLEU variants. These results will be presented in an expanded Metrics section. revision: yes
-
Referee: [Dataset and experimental setup] The semi-synthetic dataset construction is not shown to approximate real-world inconsistency distributions; no ablation or transfer experiments on authentic documents are reported. This makes the generalization claim in the abstract load-bearing but unsupported.
Authors: We acknowledge that explicit validation against real-world distributions is desirable. In revision we will expand the dataset section with a detailed mapping of our synthetic inconsistency types to patterns documented in prior literature on real documents. We will also add a small-scale transfer experiment on publicly available authentic documents where feasible and will moderate the generalization language in the abstract. revision: partial
-
Referee: [Experiments and results] Experimental results lack statistical details such as variance across runs, significance tests, or full baseline comparisons (including parameter counts and prompt lengths). The abstract's assertion of 'strong experimental results' cannot be assessed without these.
Authors: We agree that additional statistical rigor is needed. The revised version will report standard deviations across five independent runs, include statistical significance tests (paired t-tests and Wilcoxon signed-rank), and provide complete baseline specifications including model parameter counts and prompt token lengths. These details will appear in the Experiments and Results section. revision: yes
Circularity Check
No circularity: purely empirical prompting study with no derivations or fitted predictions
full rationale
The paper presents an empirical investigation of LLM prompting strategies for evidence extraction in document inconsistency detection. It introduces new metrics and a redact-and-retry framework, evaluates them on a semi-synthetic dataset, and reports experimental improvements. No equations, mathematical derivations, or parameter-fitting steps are described that could reduce a claimed prediction to its own inputs by construction. The work contains no self-citation chains used to justify uniqueness theorems or ansatzes, and the central claims rest on experimental results rather than definitional equivalence. This is a standard empirical contribution whose validity can be assessed against external benchmarks or human judgments without internal circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce new comprehensive evidence-extraction metrics and a redact-and-retry framework with constrained filtering that substantially improves evidence extraction performance over other prompting methods.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Language Bias under Conflicting Information in Multilingual LLMs
Multilingual LLMs ignore conflicts in information presented across languages and exhibit consistent biases favoring certain languages like Chinese over Russian.
Reference graph
Works this paper leans on
-
[1]
The pascal recognising textual entailment chal- lenge.Machine learning challenges workshop, pages 177–190. Tobias Deußer, Maren Pielka, Lisa Pucknat, Basil Jacob, Tim Dilmaghani, Mahdis Nourimand, Bernd Kliem, Rüdiger Loitz, Christian Bauckhage, and Rafet Sifa
-
[2]
Proceedings of the Northern Lights Deep Learning Workshop, 4
Contradiction detection in financial reports. Proceedings of the Northern Lights Deep Learning Workshop, 4. Arthur C Graesser and Cathy L McMahen. 1993. Anomalous information triggers questions when adults solve quantitative problems and comprehend stories.Journal of Educational Psychology, 85:136. Sanda Harabagiu, Andrew Hickl, and Finley Lacatusu
work page 1993
-
[3]
Textbooks Are All You Need II: phi-1.5 technical report
Negation, contrast and contradiction in text processing.Proceedings of the AAAI Conference on Artificial Intelligence, 6:755–762. Chuqin Li, Xi Niu, Ahmad Al-Doulat, and Noseong Park. 2018. A computational approach to finding contradictions in user opinionated text.IEEE/ACM International Conference on Advances in Social Net- works Analysis and Mining (ASO...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
A Comprehensive Overview of Large Language Models
DocInfer: Document-level natural language inference using optimal evidence selection.Proceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 809–824. Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. 2023. A comprehensive overview of larg...
work page internal anchor Pith review arXiv 2022
-
[5]
DocNLI: A large-scale dataset for document- level natural language inference.Findings of the Association for Computational Linguistics: ACL- IJCNLP 2021, pages 4913–4922. 5 Yusen Zhang, Ruoxi Sun, Yanfei Chen, Tomas Pfister, Rui Zhang, and Sercan Arik. 2024. Chain of agents: Large language models collaborating on long-context tasks.Advances in Neural Info...
work page 2021
-
[6]
Example: ‘Zully donated her kidney.’ vs
Negation.There exists one sentence which is a negation of another sentence. Example: ‘Zully donated her kidney.’ vs. ‘Zully never donated her kidney.’
-
[7]
Example: ‘All the donors are between 20 to 45 years old.’ vs
Numeric.There exists a numerical mismatch between sentences. Example: ‘All the donors are between 20 to 45 years old.’ vs. ‘Lisa, who donates her kidney, she is 70 years old.’
-
[8]
Example: ‘Zully Broussard donated her kidney to a stranger.’ vs
Content.There exists one sentence chang- ing one or multiple attributes of an event or entity that was previously stated in another sentence. Example: ‘Zully Broussard donated her kidney to a stranger.’ vs. ‘Zully Broussard donated her kidney to her close friend.’
-
[9]
Example: ‘The doctor spoke highly of the project and called it a breakthrough’ vs
Perspective/View/Opinion.Inconsistency in perspective/view/opinion between sentences. Example: ‘The doctor spoke highly of the project and called it a breakthrough’ vs. ‘The doctor disliked the project, saying it had no impact at all.’
-
[10]
Ex- ample: ‘The rescue team searched for the boy worriedly.’ vs
Emotion/Mood/Feeling.Inconsistency in emotion/mood/feeling between sentences. Ex- ample: ‘The rescue team searched for the boy worriedly.’ vs. ‘The rescue team searched for the boy happily.’
-
[11]
Example: ‘Jane and Tom are a married couple.’ vs
Relation.Presence of two mutually exclusive relations between entities. Example: ‘Jane and Tom are a married couple.’ vs. ‘Jane is Tom’s sister.’ 8 Figure 6: Boxplot for number of sentences. ‘pos’ refers to datapointsi such that yi =Yes , ‘neg’ refers to datapoints isuch thaty i =No, and ‘all’ refers to all datapoints
-
[12]
Example: ‘The road T51 was located in New York.’ vs
Factual.There exist sentence(s) in disagree- ment with external world knowledge/facts. Example: ‘The road T51 was located in New York.’ vs. ‘The road T51 was located in Cali- fornia.’
-
[13]
Example: ‘I slam the door.’ vs
Causal.There exist sentences where the ef- fect does not match the cause. Example: ‘I slam the door.’ vs. ‘After I do that, the door opens.’ 9 G4o L3.2 L3 accuracy 0.680 0.681 0.601 precision 0.642 0.704 0.869 F1 score 0.697 0.657 0.357 TPR/recall 0.763 0.616 0.225 FPR 0.399 0.254 0.033 TNR 0.601 0.746 0.967 FNR 0.237 0.384 0.775 EHR (DP) 0.536 0.412 0.20...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.