ReaMIL: Reasoning- and Evidence-Aware Multiple Instance Learning for Whole-Slide Histopathology
Pith reviewed 2026-05-16 13:38 UTC · model grok-4.3
The pith
ReaMIL adds a selection head to MIL models so that only a small number of tiles suffice for accurate whole-slide cancer subtyping while keeping baseline AUC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
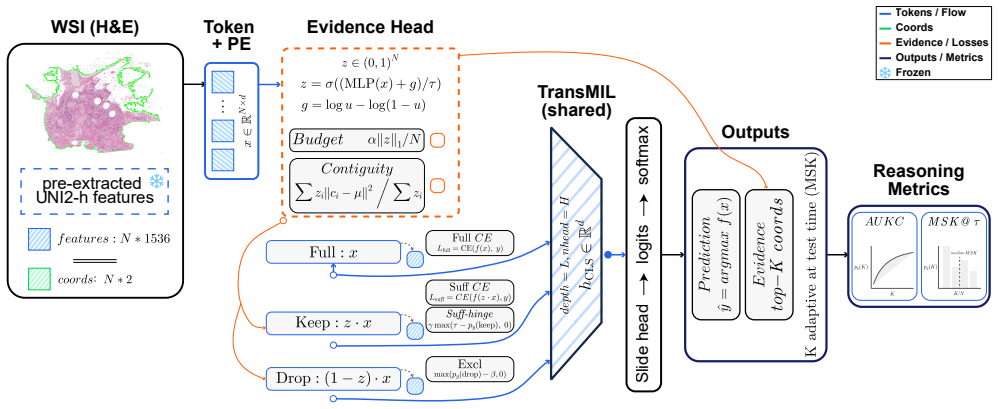
ReaMIL trains a soft selection head on top of a MIL backbone with a budgeted-sufficiency hinge loss that enforces the true-class probability to be at least τ when only the selected tiles are used, subject to a sparsity budget on the number of tiles; this produces small, spatially compact evidence sets that preserve baseline AUC and yield slide-level overlays without additional supervision.
What carries the argument
Budgeted-sufficiency hinge loss with a sparsity constraint on the number of selected tiles, which enforces class-probability sufficiency while promoting compactness and spatial coherence.
If this is right
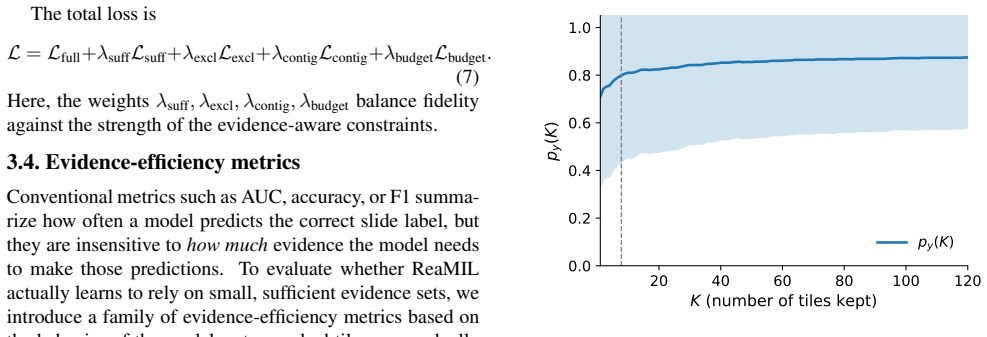
- Matches or slightly improves AUC across TCGA-NSCLC, TCGA-BRCA, and PANDA while returning mean minimal sufficient K of about 8 tiles at τ = 0.90 on NSCLC.
- Produces quantitative diagnostics (MSK, AUKC, contiguity) that measure how quickly class rises with added tiles.
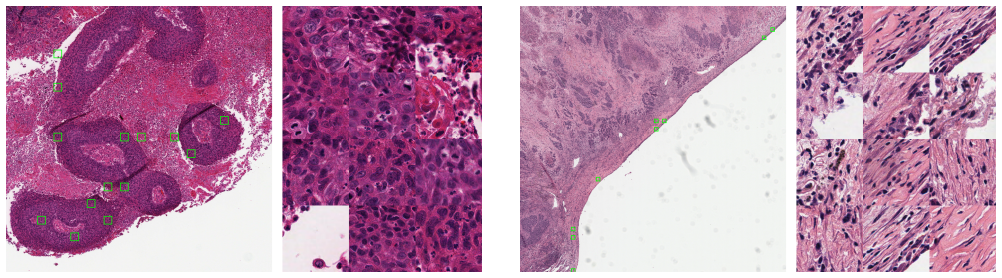
- Yields slide-level overlays of the selected tiles without requiring extra labels.
- Integrates directly into existing MIL training pipelines with no change to the backbone architecture.
Where Pith is reading between the lines
- The same selection mechanism could be applied to other large-image domains where only a few patches carry the decisive signal.
- Compact evidence sets may lower the cost of human review in clinical workflows by directing attention to a handful of regions.
- The AUKC metric offers a way to compare evidence efficiency across different MIL variants on the same data.
- Spatially compact selections might reduce the need for post-hoc explanation methods in digital pathology.
Load-bearing premise
Enforcing class probability above a threshold with a limited number of tiles under a sparsity budget will automatically select diagnostically meaningful and spatially compact tiles without degrading overall accuracy.
What would settle it
A controlled experiment in which enforcing the small selection budget on a held-out WSI cohort causes AUC to fall below the baseline MIL model, or in which selected tiles are judged non-diagnostic by blinded pathologists.
Figures
read the original abstract
We introduce ReaMIL (Reasoning- and Evidence-Aware MIL), a multiple instance learning approach for whole-slide histopathology that adds a light selection head to a strong MIL backbone. The head produces soft per-tile gates and is trained with a budgeted-sufficiency objective: a hinge loss that enforces the true-class probability to be $\geq \tau$ using only the kept evidence, under a sparsity budget on the number of selected tiles. The budgeted-sufficiency objective yields small, spatially compact evidence sets without sacrificing baseline performance. Across TCGA-NSCLC (LUAD vs. LUSC), TCGA-BRCA (IDC vs. Others), and PANDA, ReaMIL matches or slightly improves baseline AUC and provides quantitative evidence-efficiency diagnostics. On NSCLC, it attains AUC 0.983 with a mean minimal sufficient K (MSK) $\approx 8.2$ tiles at $\tau = 0.90$ and AUKC $\approx 0.864$, showing that class confidence rises sharply and stabilizes once a small set of tiles is kept. The method requires no extra supervision, integrates seamlessly with standard MIL training, and naturally yields slide-level overlays. We report accuracy alongside MSK, AUKC, and contiguity for rigorous evaluation of model behavior on WSIs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReaMIL, a multiple instance learning framework for whole-slide histopathology images that incorporates a selection head producing soft per-tile gates. These gates are optimized via a budgeted-sufficiency hinge loss to maintain a true-class probability of at least τ while respecting a sparsity budget on selected tiles. The method is evaluated on TCGA-NSCLC, TCGA-BRCA, and PANDA datasets, claiming to match or exceed baseline AUC while providing compact evidence sets, with specific metrics such as AUC 0.983, mean MSK of approximately 8.2 tiles at τ=0.90, and AUKC of 0.864 on NSCLC.
Significance. If the selected evidence sets prove clinically relevant, ReaMIL offers a practical advance in interpretable MIL for computational pathology by quantifying evidence efficiency via MSK, AUKC, and contiguity without requiring tile-level labels or extra supervision. The seamless integration with existing MIL backbones and the production of slide-level overlays are notable strengths that could support more trustworthy model deployment in diagnostic workflows.
major comments (3)
- [§4] §4 (Experiments): The reported AUC values and slight improvements over baselines are presented without details on baseline re-implementations, hyperparameter search protocols, or statistical significance testing (e.g., DeLong tests or bootstrap confidence intervals for AUC differences), which undermines verification of the central performance claims given the dependence on user-chosen τ and sparsity budget.
- [§3.2] §3.2 (Budgeted-sufficiency objective): The hinge loss enforces P(y|kept tiles) ≥ τ under the sparsity constraint but supplies no signal ensuring the kept tiles align with histopathologically diagnostic regions; without tile-level annotations or post-hoc expert review, high AUC + low MSK can arise from any small correlating set, including non-causal or artifactual tiles.
- [§4.3] §4.3 (Ablations and diagnostics): Sensitivity of MSK, AUKC, and contiguity to the free parameters τ and sparsity budget is only partially explored; a fuller ablation table showing performance degradation or evidence quality changes across a range of these values is needed to support the claim of robust evidence-aware behavior.
minor comments (3)
- [Abstract] Abstract: The phrase 'rigorous evaluation of model behavior' should explicitly name the baselines (e.g., standard attention-based MIL) and the exact statistical measures used.
- [Figure 3] Figure 3 (slide overlays): The caption should clarify how contiguity is quantitatively defined and computed from the soft gates.
- [§3] Notation: The definition of the soft per-tile gates and their relation to the final slide-level prediction should be stated more explicitly in the method section to avoid ambiguity with standard MIL pooling.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported AUC values and slight improvements over baselines are presented without details on baseline re-implementations, hyperparameter search protocols, or statistical significance testing (e.g., DeLong tests or bootstrap confidence intervals for AUC differences), which undermines verification of the central performance claims given the dependence on user-chosen τ and sparsity budget.
Authors: We agree that additional details are necessary to allow full verification of the results. In the revised manuscript, we will include a dedicated subsection describing the re-implementation of baselines, the hyperparameter search procedure (including ranges and selection criteria on a validation split), and statistical comparisons using bootstrap resampling to compute confidence intervals for AUC differences. revision: yes
-
Referee: [§3.2] §3.2 (Budgeted-sufficiency objective): The hinge loss enforces P(y|kept tiles) ≥ τ under the sparsity constraint but supplies no signal ensuring the kept tiles align with histopathologically diagnostic regions; without tile-level annotations or post-hoc expert review, high AUC + low MSK can arise from any small correlating set, including non-causal or artifactual tiles.
Authors: The budgeted-sufficiency loss is intentionally formulated to identify minimal sets sufficient for the model's prediction rather than to enforce alignment with expert-defined diagnostic regions, as the latter would require additional supervision which the method aims to avoid. We acknowledge this as a limitation and will expand the discussion section to clarify that the selected tiles are sufficient for high-confidence predictions but may not correspond to causal histopathological features. We will also include more qualitative visualizations to allow readers to assess relevance. revision: partial
-
Referee: [§4.3] §4.3 (Ablations and diagnostics): Sensitivity of MSK, AUKC, and contiguity to the free parameters τ and sparsity budget is only partially explored; a fuller ablation table showing performance degradation or evidence quality changes across a range of these values is needed to support the claim of robust evidence-aware behavior.
Authors: We will extend the ablation experiments to cover a broader range of τ values (e.g., 0.75 to 0.95) and sparsity budgets, presenting a comprehensive table that reports AUC, MSK, AUKC, and contiguity metrics for each combination to demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical results follow from defined objective on held-out data
full rationale
The paper defines a budgeted-sufficiency hinge loss that enforces true-class probability >= τ using selected tiles under a sparsity budget. Reported metrics (AUC 0.983, MSK ≈8.2 at τ=0.90, AUKC≈0.864) are computed on held-out TCGA and PANDA test sets after standard training. These quantities are not algebraically equivalent to the chosen hyperparameters τ and sparsity budget by construction; they are independent empirical outcomes. No self-citations, uniqueness theorems, or ansatzes are load-bearing in the core claims. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- tau =
0.90
- sparsity budget
axioms (1)
- domain assumption A lightweight selection head can be trained jointly with any strong MIL backbone without architectural conflict.
invented entities (1)
-
soft per-tile gates
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Str ¨om, Hans Pinckaers, Kunal Nagpal, Yuannan Cai, David F Steiner, Hester Van Boven, Robert Vink, et al. Artifi- cial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature Medicine, 28(1):154– 163, 2022. 2
work page 2022
-
[2]
Hanna, Luke Geneslaw, Andrew Miraflor, Vitor Werneck Krauss Silva, Klaus J
Gabriele Campanella, Matthew G. Hanna, Luke Geneslaw, Andrew Miraflor, Vitor Werneck Krauss Silva, Klaus J. Busam, Edi Brogi, Victor E. Reuter, David S. Klimstra, and Thomas J. Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide im- ages.Nature Medicine, 25(8):1301–1309, 2019. 1
work page 2019
-
[3]
Supriyo Chakraborty, Richard J. Tomsett, R. Raghaven- dra, Daniel Harborne, M. Alzantot, F. Cerutti, M. Sri- vastava, A. Preece, S. Julier, R. Rao, T. Kelley, Dave Braines, M. Sensoy, C. Willis, and Prudhvi K. Gurram. Interpretability of deep learning models: A survey of re- sults.2017 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trust...
work page 2017
-
[4]
Richard J Chen, Tong Ding, Ming Y Lu, Drew F K Williamson, Guillaume Jaume, Bowen Chen, Andrew Zhang, Daniel Shao, Andrew H Song, Muhammad Shaban, et al. Towards a general-purpose foundation model for com- putational pathology.Nature Medicine, 30:154–165, 2024. 1, 2
work page 2024
-
[5]
Scaling vision transform- ers to 22 billion parameters.arXiv preprint, 2022
Zhengying Chen, Xiao Wang, Alexander Kolesnikov, Dirk Weissenborn, Xiaojuan Qi, Jakob Verbeek, Neil Houlsby, Xiaohua Zhai, and Lucas Beyer. Scaling vision transform- ers to 22 billion parameters.arXiv preprint, 2022. 2
work page 2022
-
[6]
Overcoming data scarcity in biomedical imaging with a foundational multi-task model
Ozan Ciga and Anne L Martel. Overcoming data scarcity in biomedical imaging with a foundational multi-task model. arXiv preprint arXiv:2010.07964, 2022. 1
-
[7]
Neofytos Dimitriou, Ognjen Arandjelovic, and P. Caie. Deep learning for whole slide image analysis: An overview.Fron- tiers in Medicine, 2019. 1
work page 2019
-
[8]
Edwards, Mauricio Oberti, Ratna R
Nathan J. Edwards, Mauricio Oberti, Ratna R. Thangudu, Shuang Cai, Peter B. McGarvey, Shine Jacob, Subha Mad- havan, and Karen A. Ketchum. The CPTAC Data Portal: A Resource for Cancer Proteomics Research.Journal of Pro- teome Research, 14(6):2707–2713, 2015. 2
work page 2015
-
[9]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems, 2017. 2
work page 2017
-
[10]
Maximilian Ilse, Jakub M. Tomczak, and Max Welling. Attention-based deep multiple instance learning. InProceed- ings of the 35th International Conference on Machine Learn- ing, pages 2127–2136. PMLR, 2018. 1, 2
work page 2018
-
[11]
Categorical repa- rameterization with Gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical repa- rameterization with Gumbel-softmax. InInternational Con- ference on Learning Representations, 2017. 3
work page 2017
-
[12]
Litjens, P ´eter B ´andi, Babak Ehteshami Bejnordi, Oscar G
G. Litjens, P ´eter B ´andi, Babak Ehteshami Bejnordi, Oscar G. F. Geessink, M. Balkenhol, P. Bult, A. Halilovic, M. Hermsen, Rob van de Loo, R. V ogels, Quirine F. Manson, N. Stathonikos, A. Baidoshvili, Paul van Diest, C. Wauters, Marcory van Dijk, and Jeroen van der Laak. 1399 h&e- stained sentinel lymph node sections of breast cancer pa- tients: the c...
work page 2018
-
[13]
Ming Y . Lu, Drew F. K. Williamson, Tiffany Y . Liu, Richard J. Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathol- ogy on whole-slide images.Nature Biomedical Engineering, 5(6):555–570, 2021. 1, 2
work page 2021
-
[14]
The concrete distribution: A continuous relaxation of discrete random variables
Chris J Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representations, 2017. 3
work page 2017
-
[15]
Learning to deceive with attention-based explanations
Danish Pruthi, Mansi Gupta, Bhuwan Dhingra, Graham Neubig, and Zachary Chase Lipton. Learning to deceive with attention-based explanations. InProceedings of the 58th An- nual Meeting of the Association for Computational Linguis- tics, pages 4782–4793, Online, 2020. 1
work page 2020
-
[16]
Sofia Serrano and Noah A Smith. Is attention interpretable? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2931–2951, 2019. 1, 2
work page 2019
-
[17]
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, and Yongbing Zhang. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. InAdvances in Neural In- formation Processing Systems, pages 2136–2147, 2021. 1, 2
work page 2021
-
[18]
The cancer genome atlas pan-cancer analysis project.Nature Genetics, 45(10):1113–1120, 2013
John N Weinstein, Eric A Collisson, Gordon B Mills, Kenna R Shaw, Brad A Ozenberger, Kyle Ellrott, Ilya Shmulevich, Chris Sander, and Joshua M Stuart. The cancer genome atlas pan-cancer analysis project.Nature Genetics, 45(10):1113–1120, 2013. 2
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.