SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips
Pith reviewed 2026-05-21 15:21 UTC · model grok-4.3
The pith
SuperInfer uses SLO-aware rotary scheduling and duplex memory transfers to improve TTFT SLO attainment by up to 74.7% on GH200 superchips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
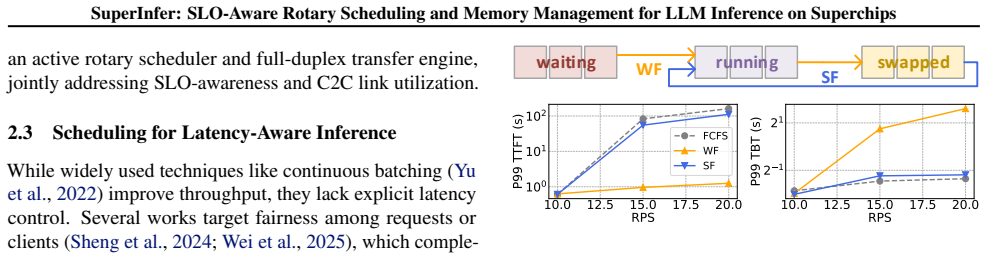
SuperInfer demonstrates that a proactive SLO-aware rotary scheduler together with a full-duplex KV-cache rotation engine on tightly coupled GPU-CPU superchips raises time-to-first-token SLO attainment rates by up to 74.7 percent while keeping time-between-tokens and throughput comparable to state-of-the-art LLM inference systems.
What carries the argument
RotaSched is the proactive SLO-aware rotary scheduler that rotates requests to preserve responsiveness, paired with DuplexKV, the rotation engine that performs full-duplex transfers over NVLink-C2C.
If this is right
- High request rates no longer produce severe head-of-line blocking once KV cache space runs out.
- Requests can be moved to CPU memory and back without violating tight TTFT or TBT targets.
- Memory capacity on the superchip is used more effectively through coordinated rotation rather than static allocation.
- Throughput stays comparable to existing systems while a much higher share of requests meet their latency SLOs.
Where Pith is reading between the lines
- The same rotation idea may apply to other platforms that provide fast CPU-GPU memory links.
- Proactive rather than reactive offloading could be combined with existing batching or quantization methods.
- Hardware designers might prioritize even lower-latency interconnects to support higher rotation rates.
Load-bearing premise
The NVLink-C2C link between GPU and CPU on superchips supplies low-overhead full-duplex transfers that keep the system responsive at high request rates without creating new bottlenecks.
What would settle it
Running the same workload on hardware without a fast GPU-CPU interconnect or at request rates where transfer latency exceeds the SLO budget would show whether the reported gains remain.
Figures














read the original abstract
Large Language Model (LLM) serving faces a fundamental tension between stringent latency Service Level Objectives (SLOs) and limited GPU memory capacity. When high request rates exhaust the KV cache budget, existing LLM inference systems often suffer severe head-of-line (HOL) blocking. While prior work explored PCIe-based offloading, these approaches cannot sustain responsiveness under high request rates, often failing to meet tight Time-To-First-Token (TTFT) and Time-Between-Tokens (TBT) SLOs. We present SuperInfer, a high-performance LLM inference system designed for emerging Superchips (e.g., NVIDIA GH200) with tightly coupled GPU-CPU architecture via NVLink-C2C. SuperInfer introduces RotaSched, the first proactive, SLO-aware rotary scheduler that rotates requests to maintain responsiveness on Superchips, and DuplexKV, an optimized rotation engine that enables full-duplex transfer over NVLink-C2C. Evaluations on GH200 using various models and datasets show that SuperInfer improves TTFT SLO attainment rates by up to 74.7% while maintaining comparable TBT and throughput compared to state-of-the-art systems, demonstrating that SLO-aware scheduling and memory co-design unlocks the full potential of Superchips for responsive LLM serving. Code is available in https://github.com/Supercomputing-System-AI-Lab/SuperInfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SuperInfer, an LLM inference system for NVIDIA GH200 Superchips that combines RotaSched—a proactive, SLO-aware rotary scheduler—with DuplexKV, an engine for full-duplex KV-cache transfers over NVLink-C2C. The central claim is that this co-design improves TTFT SLO attainment rates by up to 74.7% relative to state-of-the-art systems while preserving comparable TBT and throughput, by mitigating head-of-line blocking when KV-cache capacity is exhausted.
Significance. If the empirical results hold, the work demonstrates that tightly coupled GPU-CPU architectures can materially improve responsiveness for LLM serving under high load, where prior PCIe-based offloading approaches have failed. The public release of code is a clear strength that supports reproducibility and follow-on research.
major comments (1)
- Evaluation section: the reported TTFT SLO gains (up to 74.7%) are presented as aggregate outcomes of RotaSched + DuplexKV, yet the manuscript provides no direct instrumentation or ablation of NVLink-C2C transfer latency, bandwidth utilization, or queuing delays during rotations at peak request rates. This measurement gap is load-bearing for the hardware co-design claim, because the skeptic concern—that unmeasured transfer overheads could re-introduce HOL blocking—cannot be ruled out from the existing TTFT/TBT/throughput numbers alone.
minor comments (1)
- The abstract and evaluation description refer to “various models and datasets” without enumerating them or reporting per-model variance; adding a table or explicit list would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation methodology. The concern about direct instrumentation of NVLink-C2C transfers is well-taken, and we address it point-by-point below while committing to targeted revisions.
read point-by-point responses
-
Referee: Evaluation section: the reported TTFT SLO gains (up to 74.7%) are presented as aggregate outcomes of RotaSched + DuplexKV, yet the manuscript provides no direct instrumentation or ablation of NVLink-C2C transfer latency, bandwidth utilization, or queuing delays during rotations at peak request rates. This measurement gap is load-bearing for the hardware co-design claim, because the skeptic concern—that unmeasured transfer overheads could re-introduce HOL blocking—cannot be ruled out from the existing TTFT/TBT/throughput numbers alone.
Authors: We agree that isolating the NVLink-C2C transfer characteristics would strengthen the hardware co-design argument. Although the end-to-end TTFT improvements under high load already indicate that DuplexKV rotations do not reintroduce HOL blocking (as TBT and throughput remain comparable to baselines), we will add direct measurements in the revised evaluation section. Specifically, we will instrument and report: (1) per-rotation NVLink-C2C latency and achieved bandwidth at peak request rates, (2) queuing delays observed during full-duplex transfers, and (3) an ablation that disables DuplexKV optimizations while keeping RotaSched fixed. These additions will allow readers to directly assess whether transfer overheads remain negligible relative to the observed SLO gains. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivation chain
full rationale
The paper describes a systems artifact (RotaSched scheduler and DuplexKV engine) for GH200 Superchips and reports measured improvements in TTFT SLO attainment (up to 74.7%) from hardware experiments. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. All central claims rest on direct empirical benchmarks rather than any reduction to inputs by construction, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
GoodServe: Towards High-Goodput Serving of Agentic LLM Inferences over Heterogeneous Resources
GoodServe proposes a predict-and-rectify routing system for agentic LLM inferences on heterogeneous GPUs that improves goodput by up to 27.4%.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Optimizing LLM Inference: Fluid-Guided Online Scheduling with Memory Constraints
Ao, R., Luo, G., Simchi-Levi, D., and Wang, X. Optimiz- ing llm inference: Fluid-guided online scheduling with memory constraints.arXiv preprint arXiv:2504.11320,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Efficient llm serving on hybrid real-time and best-effort requests.arXiv preprint arXiv:2504.09590,
Borui, W., Juntao, Z., Chenyu, J., Chuanxiong, G., and Chuan, W. Efficient llm serving on hybrid real-time and best-effort requests.arXiv preprint arXiv:2504.09590,
-
[5]
Chen, J., Du, C., Liu, R., Yao, S., Yan, D., Liao, J., Liu, S., Wu, F., and Chen, G. Tokenflow: Responsive llm text streaming serving under request burst via preemptive scheduling.arXiv preprint arXiv:2510.02758, 2025a. Chen, W., He, S., Qu, H., Zhang, R., Yang, S., Chen, P., Zheng, Y ., Huai, B., and Chen, G. {IMPRESS}: An {Importance-Informed}{Multi-Tie...
-
[6]
Fusco, L., Khalilov, M., Chrapek, M., Chukkapalli, G., Schulthess, T., and Hoefler, T. Understanding data move- ment in tightly coupled heterogeneous systems: A case study with the grace hopper superchip.arXiv preprint arXiv:2408.11556,
-
[7]
He, J. and Zhai, J. Fastdecode: High-throughput gpu- efficient llm serving using heterogeneous pipelines.arXiv preprint arXiv:2403.11421,
-
[8]
Hu, C., Huang, H., Hu, J., Xu, J., Chen, X., Xie, T., Wang, C., Wang, S., Bao, Y ., Sun, N., et al. Memserve: Con- text caching for disaggregated llm serving with elastic memory pool.arXiv preprint arXiv:2406.17565,
-
[9]
Slo-aware scheduling for large language model inferences.arXiv preprint arXiv:2504.14966,
Huang, J., Xiong, Y ., Yu, X., Huang, W., Li, E., Zeng, L., and Chen, X. Slo-aware scheduling for large language model inferences.arXiv preprint arXiv:2504.14966,
-
[10]
SuperInfer: SLO-Aware Rotary Scheduling and Memory Management for LLM Inference on Superchips Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024a. Jiang, C., Gao, L., Zarch, H. E., and Annavaram, M. Kvpr:...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Li, Z., Chen, Z., Delacourt, R., Oliaro, G., Wang, Z., Chen, Q., Lin, S., Yang, A., Zhang, Z., Chen, Z., et al. Adaserve: Accelerating multi-slo llm serving with slo-customized speculative decoding.arXiv preprint arXiv:2501.12162,
-
[12]
Lian, X., Tanaka, M., Ruwase, O., and Zhang, M. Superof- fload: Unleashing the power of large-scale llm training on superchips.arXiv preprint arXiv:2509.21271,
-
[13]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437, 2024a. Liu, Y ., Li, H., Cheng, Y ., Ray, S., Huang, Y ., Zhang, Q., Du, K., Yao, J., Lu, S., Ananthanarayanan, G., et al. Cachegen: Kv cache compression and streaming for fast large language ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Ma, C., Ye, Z., Zhao, H., Yang, Z., Fu, T., Han, J., Zhang, J., Luo, Y ., Wang, X., Wang, Z., et al. Memory offload- ing for large language model inference with latency slo guarantees.arXiv preprint arXiv:2502.08182,
-
[15]
[On- line; accessed 2025-10-26]
URL https:// resources.nvidia.com/en-us-grace-cpu/ nvidia-grace-hopper?ncid=no-ncid . [On- line; accessed 2025-10-26]. Patke, A., Reddy, D., Jha, S., Qiu, H., Pinto, C., Narayanaswami, C., Kalbarczyk, Z., and Iyer, R. Queue management for slo-oriented large language model serv- ing. InProceedings of the 2024 ACM Symposium on Cloud Computing, pp. 18–35,
work page 2025
-
[16]
Qiu, H., Mao, W., Patke, A., Cui, S., Jha, S., Wang, C., Franke, H., Kalbarczyk, Z. T., Ba s ¸ar, T., and Iyer, R. K. Efficient interactive llm serving with proxy model-based sequence length prediction.arXiv preprint arXiv:2404.08509,
-
[17]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
- [18]
-
[19]
URL https://docs.vllm.ai/en/latest/usage/ v1_guide.html. [Online; accessed 2025-10-27]. Wei, Z., Yen, J., Chen, J., Zhang, Z., Huang, Z., Chen, C., Yu, X., Gu, Y ., Wu, C., Wang, Y ., et al. Equinox: Holistic fair scheduling in serving large language models.arXiv preprint arXiv:2508.16646,
-
[20]
Fast Distributed Inference Serving for Large Language Models
Wu, B., Zhong, Y ., Zhang, Z., Liu, S., Liu, F., Sun, Y ., Huang, G., Liu, X., and Jin, X. Fast distributed infer- ence serving for large language models.arXiv preprint arXiv:2305.05920,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Pie: Pooling cpu memory for llm inference.arXiv preprint arXiv:2411.09317,
Xu, Y ., Mao, Z., Mo, X., Liu, S., and Stoica, I. Pie: Pooling cpu memory for llm inference.arXiv preprint arXiv:2411.09317,
-
[22]
Yang, A., Yu, B., Li, C., Liu, D., Huang, F., Huang, H., Jiang, J., Tu, J., Zhang, J., Zhou, J., et al. Qwen2. 5-1m technical report.arXiv preprint arXiv:2501.15383,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Yu, J., Taneja, A., Lin, J., and Zhang, M. V oltanallm: Feedback-driven frequency control and state-space rout- ing for energy-efficient llm serving.arXiv preprint arXiv:2509.04827,
-
[24]
Tempo: Application-aware llm serving with mixed slo requirements.arXiv preprint arXiv:2504.20068,
Zhang, W., Wu, Z., Mu, Y ., Liu, B., Lee, M., and Lai, F. Tempo: Application-aware llm serving with mixed slo requirements.arXiv preprint arXiv:2504.20068,
-
[25]
Zhao, X., Jia, B., Zhou, H., Liu, Z., Cheng, S., and You, Y . Hetegen: Heterogeneous parallel inference for large language models on resource-constrained devices.arXiv preprint arXiv:2403.01164,
-
[26]
Zheng, L., Chiang, W.-L., Sheng, Y ., Li, T., Zhuang, S., Wu, Z., Zhuang, Y ., Li, Z., Lin, Z., Xing, E. P., et al. Lmsys-chat-1m: A large-scale real-world llm conversa- tion dataset.arXiv preprint arXiv:2309.11998,
-
[27]
model and ShareGPT dataset (ShareGPT Team, 2023). We compare theFirst- Come-First-Serve(FCFS) andShortest-Job-Firstwith ora- cle generation length information (SJF-Oracle) policy. As shown in Fig. 23, both FCFS and SJF-Oracle fail to pre- vent TTFT SLO violations under memory pressure. Once KV cache storage is exhausted, the length of waiting queue spikes...
work page 2023
-
[28]
Comparing the vLLM and that with KV cache storage in GH200’s Unified Memory (UM). vLLM on UM shows significant TBT degradation. 2024). This allows the Hopper GPU to directly access the Grace CPU’s DRAM without incurring any page faults. GH200 does support page migration, but instead of being page-fault driven, it useshardware access countersto track the a...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.