ZipMoE: Efficient On-Device MoE Serving via Lossless Compression and Cache-Affinity Scheduling
Pith reviewed 2026-05-25 07:41 UTC · model grok-4.3
The pith
ZipMoE reduces on-device MoE inference latency by up to 72.77% using lossless compression and cache-affinity scheduling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
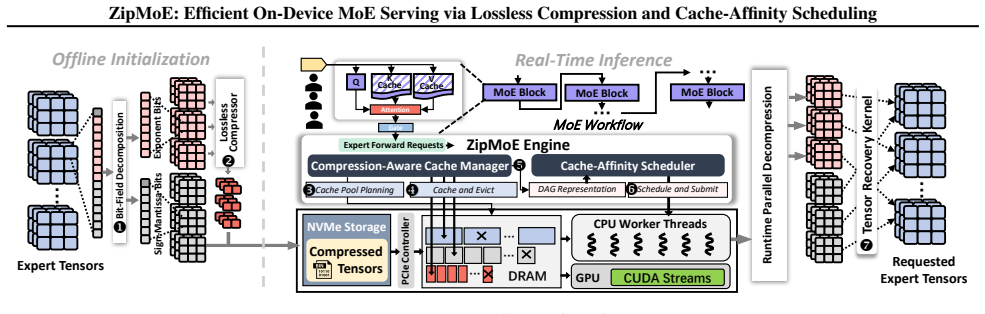
ZipMoE exploits the synergy between the hardware properties of edge devices and the statistical redundancy inherent to MoE parameters via a caching-scheduling co-design with provable performance guarantee. The design shifts on-device MoE inference from an I/O-bound bottleneck to a compute-centric workflow that enables efficient parallelization.
What carries the argument
The caching-scheduling co-design that pairs semantically lossless compression of MoE parameters with cache-affinity scheduling to minimize data movement.
If this is right
- Inference latency drops by as much as 72.77 percent on representative edge platforms.
- Throughput rises by as much as 6.76 times compared with current state-of-the-art on-device systems.
- MoE models can run without lossy quantization while fitting within edge memory limits.
- The scheduling component supplies a formal performance guarantee for the combined system.
- Inference workload moves from memory-bound transfers to parallel compute on the device.
Where Pith is reading between the lines
- The same redundancy-plus-affinity pattern may extend to other sparse architectures beyond MoE.
- Edge hardware vendors could add explicit cache-affinity primitives to further amplify the gains.
- Wider testing across additional MoE variants would show whether the compression remains lossless under distribution shift.
Load-bearing premise
The statistical redundancy present in MoE parameters permits a semantically lossless compression scheme that preserves model behavior across real-world workloads on edge hardware.
What would settle it
Running the compressed MoE model on a held-out real-world workload and observing any change in output distributions or task accuracy relative to the uncompressed model.
Figures







read the original abstract
While Mixture-of-Experts (MoE) architectures substantially bolster the expressive power of large-language models, their prohibitive memory footprint severely impedes the practical deployment on resource-constrained edge devices, especially when model behavior must be preserved without relying on lossy quantization. In this paper, we present ZipMoE, an efficient and semantically lossless on-device MoE serving system. ZipMoE exploits the synergy between the hardware properties of edge devices and the statistical redundancy inherent to MoE parameters via a caching-scheduling co-design with provable performance guarantee. Fundamentally, our design shifts the paradigm of on-device MoE inference from an I/O-bound bottleneck to a compute-centric workflow that enables efficient parallelization. We implement a prototype of ZipMoE and conduct extensive experiments on representative edge computing platforms using popular open-source MoE models and real-world workloads. Our evaluation reveals that ZipMoE achieves up to $72.77\%$ inference latency reduction and up to $6.76\times$ higher throughput than the state-of-the-art systems.Our code is available at: https://github.com/npnothard/ZipMoE-ICML26.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce ZipMoE, a system for on-device serving of Mixture-of-Experts models using a caching-scheduling co-design with lossless compression and cache-affinity scheduling that has a provable performance guarantee. It reports up to 72.77% reduction in inference latency and 6.76× higher throughput than state-of-the-art on edge platforms with real-world workloads.
Significance. Should the claims be substantiated, particularly the semantically lossless nature of the compression and the provable guarantee, this could have substantial impact on enabling large MoE models on edge devices without relying on quantization, by exploiting statistical redundancy and hardware properties to shift to compute-centric inference. Code availability supports reproducibility.
minor comments (1)
- [Abstract] The abstract asserts specific quantitative gains and a 'provable performance guarantee' without any supporting derivation, controls, or error analysis visible, which is typical for an abstract but requires the full text for evaluation.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript on ZipMoE. We appreciate the recognition of the potential substantial impact on enabling large MoE models on edge devices. The recommendation is listed as uncertain, with emphasis on substantiating the semantically lossless compression and provable guarantee. The manuscript provides formal proofs for the performance guarantee along with empirical evaluations confirming semantic losslessness via preserved model accuracy on real workloads. As the report contains no enumerated major comments, we have no specific points to address below.
Circularity Check
No significant circularity identified
full rationale
The abstract and available context present ZipMoE as an implemented system with experimental results on latency and throughput, plus a claimed provable guarantee on the co-design. No equations, fitted parameters, self-citations, or derivation steps are supplied that would allow any reduction of outputs to inputs by construction. The central performance claims are framed as measured outcomes from prototype evaluation on edge platforms, not as quantities defined from the same data or prior self-work. This is the expected non-finding for a systems paper whose abstract contains no load-bearing mathematical steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
FluxMoE: Decoupling Expert Residency for High-Performance MoE Serving
FluxMoE decouples MoE expert weights from persistent GPU residency via on-demand paging, achieving up to 3x throughput gains over vLLM in memory-constrained inference without accuracy loss.
Reference graph
Works this paper leans on
-
[1]
URL http: //www.jstor.org/stable/2337119
ISSN 00063444. URL http: //www.jstor.org/stable/2337119. Collet, Y . et al. LZ4: Extremely fast compression algorithm. https://github.com/lz4/lz4,
-
[2]
Eliseev, A. and Mazur, D. Fast inference of mixture-of- experts language models with offloading.arXiv preprint arXiv:2312.17238,
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. GPTQ: Accurate post-training compression for generative pretrained transformers.arXiv preprint arXiv:2210.17323,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hao, Y ., Cao, Y ., and Mou, L. Neuzip: Memory-efficient training and inference with dynamic compression of neu- ral networks.arXiv preprint arXiv:2410.20650,
-
[5]
A Study of BFLOAT16 for Deep Learning Training
Kalamkar, D., Mudigere, D., Mellempudi, N., Das, D., Banerjee, K., Avancha, S., V ooturi, D. T., Jammala- madaka, N., Huang, J., Yuen, H., et al. A study of 9 ZipMoE: Efficient On-Device MoE Serving via Lossless Compression and Cache-Affinity Scheduling bfloat16 for deep learning training.arXiv preprint arXiv:1905.12322,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[6]
Kamahori, K., Tang, T., Gu, Y ., Zhu, K., and Kasikci, B. Fid- dler: Cpu-gpu orchestration for fast inference of mixture- of-experts models.arXiv preprint arXiv:2402.07033,
-
[7]
In- creased llm vulnerabilities from fine-tuning and quantiza- tion.arXiv preprint arXiv:2404.04392,
Kumar, D., Kumar, A., Agarwal, S., and Harshangi, P. In- creased llm vulnerabilities from fine-tuning and quantiza- tion.arXiv preprint arXiv:2404.04392,
-
[8]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model.arXiv preprint arXiv:2405.04434,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Liu, R., Sun, Y ., Zhang, M., Bai, H., Yu, X., Yu, T., Yuan, C., and Hou, L. Quantization hurts reasoning? an empirical study on quantized reasoning models.arXiv preprint arXiv:2504.04823,
-
[10]
doi: 10.1109/TE.2024. 3467912. NVIDIA. nvCOMP: GPU-accelerated compression and decompression library. https://developer. nvidia.com/nvcomp,
-
[11]
doi: 10.1109/COMST. 2025.3527641. Sheng, Y ., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P., R´e, C., Stoica, I., and Zhang, C. Flexgen: High-throughput generative inference of large language models with a single gpu. InInternational Conference on Machine Learning, pp. 31094–31116. PMLR,
-
[12]
Promoe: Fast moe-based llm serving using proactive caching.arXiv preprint arXiv:2410.22134,
Song, X., Zhong, Z., Chen, R., and Chen, H. Promoe: Fast moe-based llm serving using proactive caching.arXiv preprint arXiv:2410.22134,
-
[13]
doi: 10.1109/ICRA57147.2024. 10610948. Wang, H., Zhou, Q., Hong, Z., and Guo, S. D2moe: Dual routing and dynamic scheduling for efficient on-device moe-based llm serving. InProceedings of the 31st An- nual International Conference on Mobile Computing and Networking, pp. 574–588,
-
[14]
L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jer- nite, Y ., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Transformers: State- of-the-art natural language processing. InProceedings of the 2020 Confe...
work page 2020
-
[15]
Association for Compu- tational Linguistics. URL https://www.aclweb. org/anthology/2020.emnlp-demos.6. Xu, M. Sharegpt-gpt4. https://huggingface.co/ datasets/shibing624/sharegpt_gpt4,
work page 2020
-
[16]
Xue, L., Fu, Y ., Lu, Z., Mai, L., and Marina, M
Hugging Face dataset. Xue, L., Fu, Y ., Lu, Z., Mai, L., and Marina, M. Moe- infinity: Offloading-efficient moe model serving.arXiv preprint arXiv:2401.14361,
-
[17]
Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., Xu, J., Zhou, J., Bai, J., He, J., Lin, J., Dang, K., Lu, K., Chen, K., Yang, K., Li, M., Xue, M., Ni, N., Zhang, P., Wang, P., Peng, R., Men, R., Gao, R., Lin, R., Wang, S., Bai...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
doi: 10.1109/TMC.2025. 3546466. Yu, H., Cui, X., Zhang, H., and Wang, H. Taming latency- memory trade-off in moe-based llm serving via fine- grained expert offloading
-
[19]
Q., Joshi, S., Hegde, C., et al
Yubeaton, P., Mahmoud, T., Naga, S., Taheri, P., Xia, T., George, A., Khalil, Y ., Zhang, S. Q., Joshi, S., Hegde, C., et al. Huff-llm: End-to-end lossless compression for efficient llm inference.arXiv preprint arXiv:2502.00922,
-
[20]
that for any feasible set of inclusion probabilities {fi}N i=1, there exists a unique set of positive weights {w∗ i }N i=1 (up to a scaling factor) such that the resulting distribution satisfies:(i) P(S)∝ Q i∈S w∗ i ;(ii)P S∋i,|S|=k P(S) =f i,∀i∈ N ;and (iii)P i∈N fi =k . Such set of w∗ i can be found via amodified iterative proportional fitting algorithm...
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.