Recognition: 2 theorem links
· Lean TheoremGenerative Modeling of Discrete Data Using Geometric Latent Subspaces
Pith reviewed 2026-05-16 09:43 UTC · model grok-4.3
The pith
Low-dimensional latent subspaces in Riemannian geometry suffice to accurately model high-dimensional discrete data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing latent subspaces in the exponential parameter space of product manifolds of categorical distributions equipped with Riemannian geometry that relates the latent subspace and induced data manifold by isometries, low-dimensional latent representations suffice to accurately model high-dimensional discrete data.
What carries the argument
Latent subspaces in the exponential parameter space of product manifolds of categorical distributions, equipped with Riemannian geometry that induces isometries to the data manifold and straight-line geodesics in latent space.
If this is right
- Geodesics on the data manifold map to straight lines in latent parameter space, simplifying optimization.
- Flow matching training becomes consistent and effective under the isometry.
- Geometric PCA reduces redundant degrees of freedom while encoding statistical dependencies among categorical variables.
- High-dimensional discrete data can be generated from low-dimensional latent representations without loss of accuracy.
- The induced geometry removes unnecessary parameters from the categorical product manifold.
Where Pith is reading between the lines
- The isometry property could support more stable inversion from latent codes back to discrete observations in practice.
- Similar geometric constructions might apply to other discrete structures such as graphs or sequences.
- The straight-line geodesics suggest the latent space could serve as a natural coordinate system for interpolation tasks on discrete data.
Load-bearing premise
Equipping the parameter domain with Riemannian geometry makes the latent subspace and induced data manifold related by isometries.
What would settle it
Finding a high-dimensional categorical dataset where the geometric PCA objective still produces large Riemannian reconstruction distances or where flow matching yields inconsistent samples despite the low-dimensional latent space would disprove the claim.
Figures










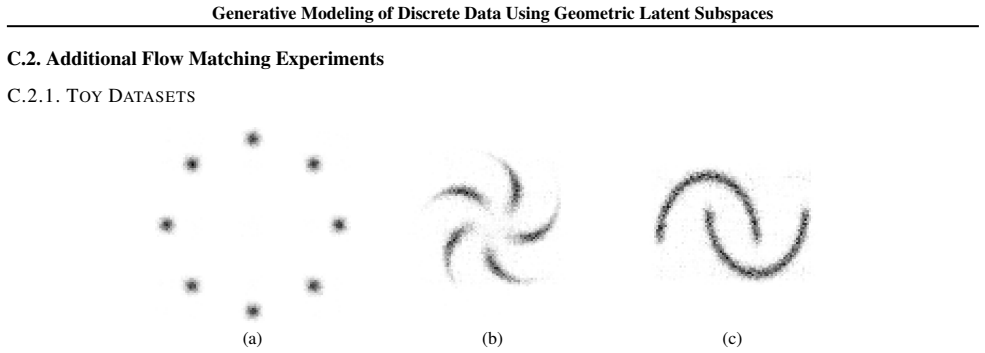


read the original abstract
We propose a geometric latent-subspace framework for generative modeling of discrete data. Specifically, we introduce latent subspaces in the exponential parameter space of product manifolds of categorical distributions as a novel method for learning generative models of discrete data. The resulting low-dimensional latent space encodes statistical dependencies and removes redundant degrees of freedom among the categorical variables. We equip the parameter domain with a Riemannian geometry such that the latent subspace and induced data manifold are related by isometries enabling consistent flow matching. Exploiting this structure, we propose a geometry-aware dimensionality reduction objective, called geometric PCA (GPCA), which we formulate as a regularized cross-entropy minimization that encourages small Riemannian distances between the data and their reconstructions. In particular, under the induced geometry, geodesics become straight lines in the latent parameter space which makes model training by flow matching effective. Empirical results show that low-dimensional latent representations suffice to accurately model high-dimensional discrete data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a geometric latent-subspace framework for generative modeling of discrete data. It introduces latent subspaces in the exponential parameter space of product manifolds of categorical distributions, equips this domain with a Riemannian geometry designed so that the latent subspace and induced data manifold are related by isometries, and uses this to enable straight-line geodesics for flow matching. The authors formulate geometric PCA (GPCA) as a regularized cross-entropy minimization objective for dimensionality reduction and report empirical results indicating that low-dimensional latent representations suffice to model high-dimensional discrete data.
Significance. If the isometry construction is rigorously established, the work could offer a principled geometric route to generative modeling of discrete data that simplifies flow matching and yields interpretable low-dimensional encodings of statistical dependencies among categorical variables. The reduction of GPCA to regularized cross-entropy and the reported empirical performance would then constitute a concrete advance over standard latent-variable approaches for discrete data.
major comments (1)
- [Abstract] Abstract: the assertion that the parameter domain is equipped with a Riemannian geometry 'such that' the latent subspace and induced data manifold are related by isometries (enabling straight-line geodesics for flow matching) is load-bearing for the entire framework, yet the manuscript supplies neither an explicit metric tensor on the exponential parameter space nor a derivation showing that the restriction to the latent subspace yields Euclidean structure while the exponential map produces an isometric embedding of the data manifold. No verification is given that the metric is positive-definite or compatible with the Fisher information metric of the product categorical distributions.
minor comments (1)
- The abstract would benefit from a concise statement of the concrete datasets and evaluation metrics used to support the empirical claim that low-dimensional latents suffice.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We agree that the geometric construction is central to the framework and will strengthen the manuscript by adding the requested explicit details and derivations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the parameter domain is equipped with a Riemannian geometry 'such that' the latent subspace and induced data manifold are related by isometries (enabling straight-line geodesics for flow matching) is load-bearing for the entire framework, yet the manuscript supplies neither an explicit metric tensor on the exponential parameter space nor a derivation showing that the restriction to the latent subspace yields Euclidean structure while the exponential map produces an isometric embedding. No verification is given that the metric is positive-definite or compatible with the Fisher information metric of the product categorical distributions.
Authors: We appreciate this observation and acknowledge that the current manuscript does not supply an explicit metric tensor or full derivation in the main text. In the revised version we will add a new subsection (Section 3.2) that (i) defines the Riemannian metric on the exponential parameter space as the pullback of the Fisher information metric of the product categorical manifold, (ii) proves that this metric restricts to the Euclidean metric on the latent subspace, (iii) shows that the exponential map is an isometry onto the induced data manifold, and (iv) verifies positive-definiteness on the interior of the probability simplex together with compatibility with the Fisher metric. These additions will make the isometry relation and the resulting straight-line geodesics for flow matching fully rigorous. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs a Riemannian geometry on the exponential parameter space explicitly chosen so that latent subspaces and induced data manifolds are isometric, then derives GPCA as regularized cross-entropy and flow-matching training from that structure. This is a definitional modeling choice rather than a claim that some independent quantity is predicted or derived from prior results. No equations reduce to their own inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing steps rely on self-citations or unverified uniqueness theorems. The central claims remain independent of the target empirical performance.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We equip the parameter domain with a Riemannian geometry such that the latent subspace and induced data manifold are related by isometries... geodesics become straight lines in the latent parameter space
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 3.1 (e-metric)... Proposition 3.4 (isometry relations)... ∂ψ maps geodesics in U... to e-geodesics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Albergo, M. S., Boffi, N. M., and Vanden-Eijnden, E. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Boffi, N. M., Albergo, M. S., and Vanden-Eijnden, E. How to Build a Consistency Model: Learning Flow Maps via Self-Distillation.arXiv:2505.18825, Oct 5
-
[3]
Boll, B., Gonzalez-Alvarado, D., and Schn ¨orr, C. Gen- erative Modeling of Discrete Joint Distributions by E- Geodesic Flow Matching on Assignment Manifolds. arXiv:2402.07846,
-
[4]
Categorical Flow Matching on Statistical Manifolds.arXiv:2405.16441,
Cheng, C., Li, J., Peng, J., and Liu, G. Categorical Flow Matching on Statistical Manifolds.arXiv:2405.16441,
-
[5]
α-Flow: A Unified Framework for Continuous-State Discrete Flow Matching Models.arXiv:2504.10283,
Cheng, C., Li, J., Fan, J., and Liu, G. α-Flow: A Unified Framework for Continuous-State Discrete Flow Matching Models.arXiv:2504.10283,
-
[6]
Flow Match- ing in Latent Space.arXiv:2307.08698,
Dao, Q., Phung, H., Nguyen, B., and Tran, A. Flow Match- ing in Latent Space.arXiv:2307.08698,
-
[7]
I., Bronstein, M., and Bose, A
Davis, O., Kessler, S., Petrache, M., Ceylan, I. I., Bronstein, M., and Bose, A. J. Fisher Flow Matching for Generative Modeling over Discrete Data.arXiv:2405.14664,
-
[8]
Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577,
Liu, Q. Rectified flow: A marginal preserving approach to optimal transport.arXiv preprint arXiv:2209.14577,
-
[9]
Y ., Klein, M., and Cu- turi, M
Mousavi-Hosseini, A., Zhang, S. Y ., Klein, M., and Cu- turi, M. Flow Matching with Semidiscrete Couplings. arXiv:2509.25519,
-
[10]
Samaddar, A., Sun, Y ., Nilsson, V ., and Madireddy, S
arXiv:2304.14772 [cs]. Samaddar, A., Sun, Y ., Nilsson, V ., and Madireddy, S. Effi- cient flow matching using latent variables.arXiv preprint arXiv:2505.04486,
-
[11]
Dirichlet Flow Matching with Applications to DNA Sequence Design.arXiv preprint arXiv:2402.05841,
Stark, H., Jing, B., Wang, C., Corso, G., Berger, B., Barzi- lay, R., and Jaakkola, T. Dirichlet Flow Matching with Applications to DNA Sequence Design.arXiv preprint arXiv:2402.05841,
-
[12]
M., Hartmann, M., and Klami, A
Williams, B., Yeom-Song, V . M., Hartmann, M., and Klami, A. Simplex-to-Euclidean Bijections for Categorical Flow Matching.arXiv:2510.27480,
-
[13]
Basic Notation Spaces and particular vectors L:={1,2,
10 Generative Modeling of Discrete Data Using Geometric Latent Subspaces A. Basic Notation Spaces and particular vectors L:={1,2, . . . , c}=: [c], c∈Nlabel set Ln := [c]n space of discrete data X:={e 1, . . . , ec} ⊂ {0,1} c one-hot encoding ofL X n :=X × · · · × Xone-hot encoding ofL n X n N :={x 1, . . . , xN } ⊂ X n given data, training set 1 n := (1,...
work page 2014
-
[14]
14 Generative Modeling of Discrete Data Using Geometric Latent Subspaces Figure 8.Latent space approximations.A random sample of MNIST data points xi and their GPCA-based approximations bxi =∂ψ(θ i). The vast majority of MNIST digits xi ∈ {0,1} 784 can be accurately approximated using a fixed 30-dimensional latent GPCA-subspace U. The alternatingly colore...
work page 2048
-
[15]
The remaining panels depict the five closest training samples in terms of Hamming distance
using a GPCA latent dimension of d= 64 . The remaining panels depict the five closest training samples in terms of Hamming distance. This figure illustrates the model’s ability to generate novel data. C.2.3. PROMOTER We report here the training results from Section 6.2 for theENHANCERDNA sequence data. The test metric that we used for PROMOTERsequences is...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.