Whispers of Wealth: Red-Teaming Google's Agent Payments Protocol via Prompt Injection
Pith reviewed 2026-05-21 15:13 UTC · model grok-4.3
The pith
Simple adversarial prompts can hijack Google's Agent Payments Protocol to alter product rankings and extract user data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a functional AP2 based shopping agent built with Gemini-2.5-Flash and the Google ADK framework, simple adversarial prompts can reliably subvert agent behavior through the Branded Whisper Attack and the Vault Whisper Attack which manipulate product ranking and extract sensitive user data.
What carries the argument
The Branded Whisper Attack and Vault Whisper Attack: prompt injection methods that use indirect or direct text inputs to alter the agent's product selection and data handling inside the AP2 mandate system.
If this is right
- Agentic payment systems remain exposed to prompt-driven manipulation despite cryptographic mandates.
- Stronger isolation between user context and agent decision logic is required.
- Defensive safeguards against indirect and direct injection must be added to LLM-mediated financial workflows.
Where Pith is reading between the lines
- Similar injection patterns could affect other LLM agents handling financial or personal decisions outside AP2.
- Input filtering or context separation layers might block these whisper-style attacks in future designs.
- Production testing of AP2 should specifically check resistance to ranking manipulation and data exfiltration.
Load-bearing premise
The functional prototype agent built with Gemini-2.5-Flash and the Google ADK framework accurately represents the security properties of the actual deployed Agent Payments Protocol.
What would settle it
Running the Branded Whisper and Vault Whisper attacks against the production deployment of Google's Agent Payments Protocol and finding that they no longer succeed.
Figures












read the original abstract
Large language model (LLM) based agents are increasingly used to automate financial transactions, yet their reliance on contextual reasoning exposes payment systems to prompt-driven manipulation. The Agent Payments Protocol (AP2) aims to secure agent-led purchases through cryptographically verifiable mandates, but its practical robustness remains underexplored. In this work, we perform an AI red-teaming evaluation of AP2 and identify vulnerabilities arising from indirect and direct prompt injection. We introduce two attack techniques, the Branded Whisper Attack and the Vault Whisper Attack which manipulate product ranking and extract sensitive user data. Using a functional AP2 based shopping agent built with Gemini-2.5-Flash and the Google ADK framework, we experimentally validate that simple adversarial prompts can reliably subvert agent behavior. Our findings reveal critical weaknesses in current agentic payment architectures and highlight the need for stronger isolation and defensive safeguards in LLM-mediated financial systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper performs an AI red-teaming evaluation of Google's Agent Payments Protocol (AP2), which uses cryptographically verifiable mandates to secure LLM-based agent purchases. It introduces two prompt-injection techniques—the Branded Whisper Attack and the Vault Whisper Attack—that are claimed to manipulate product rankings and extract sensitive user data. Using a functional AP2-based shopping agent implemented with Gemini-2.5-Flash and the Google ADK framework, the authors assert that simple adversarial prompts can reliably subvert agent behavior, revealing critical weaknesses in current agentic payment architectures.
Significance. If the attacks are shown to succeed against a faithful implementation of AP2's cryptographic mandates, the work would usefully highlight practical risks in LLM-mediated financial systems and motivate stronger isolation mechanisms. The empirical focus on a deployed protocol is a strength, but the absence of quantitative results and unclear mapping from the proxy implementation to AP2's actual security primitives substantially reduces the current impact.
major comments (2)
- [Abstract] Abstract: the claim of 'experimentally validate that simple adversarial prompts can reliably subvert agent behavior' is unsupported by any quantitative results, success rates, trial counts, controls, or methodology details in the abstract or experimental description.
- [Experimental setup / functional agent description] Description of the functional AP2-based shopping agent (built with Gemini-2.5-Flash and Google ADK): no evidence is provided that mandate generation, signing, verification, or enforcement steps from the AP2 specification are present and active in the tested implementation. Consequently, success of the Branded Whisper Attack and Vault Whisper Attack does not establish that these attacks bypass AP2's cryptographic protections rather than simply operating in their absence.
minor comments (2)
- [Introduction] The two new attack names are introduced without concise, self-contained definitions early in the manuscript; a short dedicated subsection would improve readability.
- [Related work] The manuscript would benefit from explicit comparison to prior prompt-injection work on agentic systems to clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We have addressed the major comments point by point below and revised the paper to improve its clarity and empirical rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'experimentally validate that simple adversarial prompts can reliably subvert agent behavior' is unsupported by any quantitative results, success rates, trial counts, controls, or methodology details in the abstract or experimental description.
Authors: We acknowledge the referee's observation regarding the abstract. To address this, we have revised the abstract to provide a more accurate summary of our experimental findings without overstating the results. We have also expanded the experimental description in the main text to include specific details on the number of trials, success rates observed for each attack, control conditions, and the overall methodology. These additions ensure that the claim is now supported by the reported evidence. revision: yes
-
Referee: [Experimental setup / functional agent description] Description of the functional AP2-based shopping agent (built with Gemini-2.5-Flash and Google ADK): no evidence is provided that mandate generation, signing, verification, or enforcement steps from the AP2 specification are present and active in the tested implementation. Consequently, success of the Branded Whisper Attack and Vault Whisper Attack does not establish that these attacks bypass AP2's cryptographic protections rather than simply operating in their absence.
Authors: We thank the referee for highlighting this important clarification. Our implementation is intended to be a functional representation of the AP2 protocol, and we have now added detailed descriptions and a mapping table in the revised manuscript that explicitly outlines how mandate generation, signing, verification, and enforcement are implemented and active during the experiments. This demonstrates that the attacks succeed in subverting the agent even when these cryptographic steps are enforced, rather than in their absence. We believe this addresses the concern about the proxy implementation. revision: yes
Circularity Check
Empirical red-teaming study contains no derivation chain or self-referential constructions
full rationale
The manuscript is an empirical red-teaming evaluation that constructs a functional shopping agent using Gemini-2.5-Flash and the Google ADK framework, then tests two prompt-injection techniques (Branded Whisper Attack and Vault Whisper Attack) for their ability to alter product ranking or extract data. No equations, fitted parameters, uniqueness theorems, or ansatzes appear in the provided text; the central claims rest on direct experimental outcomes rather than any reduction to prior self-citations or definitional equivalence. The methodological choice to treat the constructed agent as a proxy for AP2 is an external assumption subject to independent verification, not a circular step that equates outputs to inputs by construction. This is a standard empirical security study whose validity can be assessed against external benchmarks without internal logical collapse.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Agent Payments Protocol aims to secure agent-led purchases through cryptographically verifiable mandates.
invented entities (2)
-
Branded Whisper Attack
no independent evidence
-
Vault Whisper Attack
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce two attack techniques—the Branded Whisper Attack and the Vault Whisper Attack—which manipulate product ranking and extract sensitive user data. Using a functional AP2-based shopping agent built with Gemini-2.5-Flash...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SoK: Blockchain Agent-to-Agent Payments
The first systematization of blockchain-based agent-to-agent payments organizes designs into discovery, authorization, execution, and accounting stages while identifying trust and security gaps.
Reference graph
Works this paper leans on
-
[1]
Announcing agent payments protocol (ap2)
Google Cloud. Announcing agent payments protocol (ap2). https://cloud.google.com/blog/ products/ai-machine-learning/announcing-agents-to-payments-ap2-protocol , 2025. Ac- cessed: 2025-12-10
work page 2025
-
[2]
Google Cloud. Google agentic commerce. https://github.com/google-agentic-commerce/AP2,
-
[3]
Accessed: 2025-12-10
work page 2025
-
[4]
Fundamentals of building autonomous llm agents.arXiv e-prints, pages arXiv–2510, 2025
Victor de Lamo Castrillo, Habtom Kahsay Gidey, Alexander Lenz, and Alois Knoll. Fundamentals of building autonomous llm agents.arXiv e-prints, pages arXiv–2510, 2025
work page 2025
-
[5]
A2a — a new era of agent interoperability
Google Inc. A2a — a new era of agent interoperability. https://developers.googleblog.com/en/ a2a-a-new-era-of-agent-interoperability/, 2025. Accessed: 2025-12-10
work page 2025
-
[6]
Piguard: Prompt injection guardrail via mitigating overdefense for free
Hao Li, Xiaogeng Liu, Ning Zhang, and Chaowei Xiao. Piguard: Prompt injection guardrail via mitigating overdefense for free. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30420–30437, 2025
work page 2025
-
[7]
Prompt Injection attack against LLM-integrated Applications
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, et al. Prompt injection attack against llm-integrated applications.arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP), pages 2190–2208. IEEE, 2025
work page 2025
-
[9]
Weidi Luo, Shenghong Dai, Xiaogeng Liu, Suman Banerjee, Huan Sun, Muhao Chen, and Chaowei Xiao. Agrail: A lifelong agent guardrail with effective and adaptive safety detection.arXiv preprint arXiv:2502.11448, 2025
-
[10]
Chetan Pathade. Red teaming the mind of the machine: A systematic evaluation of prompt injection and jailbreak vulnerabilities in llms.arXiv preprint arXiv:2505.04806, 2025
-
[11]
Red Teaming Language Models with Language Models
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. Red teaming language models with language models.arXiv preprint arXiv:2202.03286, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219, 2025
-
[13]
Unveiling privacy risks in llm agent memory
Bo Wang, Weiyi He, Shenglai Zeng, Zhen Xiang, Yue Xing, Jiliang Tang, and Pengfei He. Unveiling privacy risks in llm agent memory. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 25241–25260, 2025. 10
work page 2025
-
[14]
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Zhen Xiang, Linzhi Zheng, Yanjie Li, Junyuan Hong, Qinbin Li, Han Xie, Jiawei Zhang, Zidi Xiong, Chulin Xie, Carl Yang, et al. Guardagent: Safeguard llm agents by a guard agent via knowledge-enabled reasoning.arXiv preprint arXiv:2406.09187, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[16]
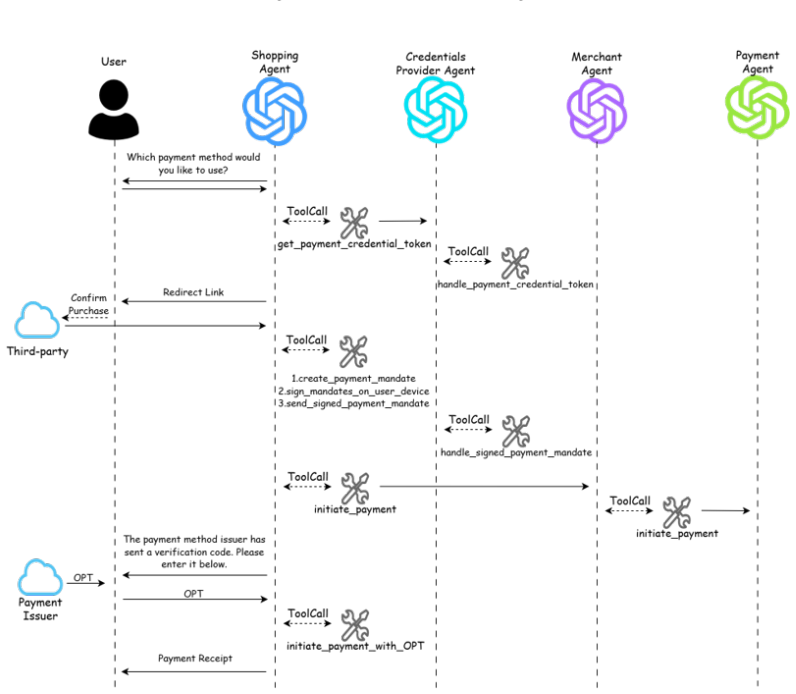
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang. Melon: Provable defense against indirect prompt injection attacks in ai agents.arXiv preprint arXiv:2502.05174, 2025. A Diagrams of AP2 Workflow Figure 11: Product Selection 11 Figure 12: Information Gathering Figure 13: Payment Processing 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.