Recognition: no theorem link
Learning Vision-Based Omnidirectional Navigation: A Teacher-Student Approach Using Monocular Depth Estimation
Pith reviewed 2026-05-15 18:11 UTC · model grok-4.3
The pith
A monocular depth student policy outperforms its 2D LiDAR teacher when navigating real-world obstacles with complex 3D shapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A teacher policy trained via PPO with privileged 2D LiDAR observations that account for the full robot footprint is distilled into a student policy that relies solely on monocular depth maps predicted from four RGB cameras, enabling the student to navigate around complex 3D obstacles more reliably than the teacher while running the entire inference pipeline onboard.
What carries the argument
Teacher-student distillation of a PPO navigation policy from privileged 2D LiDAR observations to a monocular depth estimation student using four RGB cameras.
If this is right
- The approach eliminates the need for LiDAR sensors while maintaining or improving navigation performance.
- Success rates in simulation reach 82-96.5% for the student versus 50-89% for the teacher.
- The student outperforms the teacher on obstacles with complex 3D geometries such as overhangs and low-profile objects.
- The complete inference pipeline of depth estimation, policy execution, and motor control runs entirely onboard without external computation.
Where Pith is reading between the lines
- Replacing 2D LiDAR with cameras could reduce hardware costs while providing fuller 3D coverage for industrial robots.
- The distillation method could be adapted to other sensor modalities or multi-camera setups on different robot platforms.
- Improved depth model fine-tuning on domain-specific data might further close the gap between simulation and real-world performance.
Load-bearing premise
The fine-tuned monocular depth estimation model must produce accurate and consistent depth maps under real-world lighting and texture conditions to support reliable policy decisions.
What would settle it
A real-world navigation test on a course containing overhanging beams and ground-level boxes under natural lighting, measuring whether the monocular depth student collides more often than the 2D LiDAR teacher.
Figures









read the original abstract
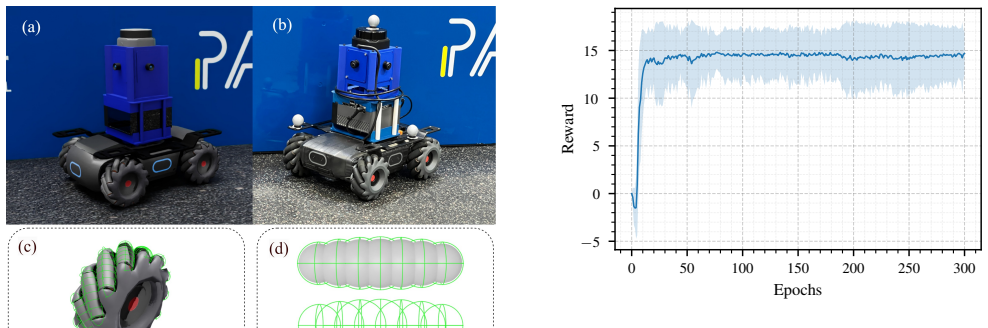
Reliable obstacle avoidance in industrial settings demands 3D scene understanding, but widely used 2D LiDAR sensors perceive only a single horizontal slice of the environment, missing critical obstacles above or below the scan plane. We present a teacher-student framework for vision-based mobile robot navigation that eliminates the need for LiDAR sensors. A teacher policy trained via Proximal Policy Optimization (PPO) in NVIDIA Isaac Lab leverages privileged 2D LiDAR observations that account for the full robot footprint to learn robust navigation. The learned behavior is distilled into a student policy that relies solely on monocular depth maps predicted by a fine-tuned Depth Anything V2 model from four RGB cameras. The complete inference pipeline, comprising monocular depth estimation (MDE), policy execution, and motor control, runs entirely onboard an NVIDIA Jetson Orin AGX mounted on a DJI RoboMaster platform, requiring no external computation for inference. In simulation, the student achieves success rates of 82-96.5%, consistently outperforming the standard 2D LiDAR teacher (50-89%). In real-world experiments, the MDE-based student outperforms the 2D LiDAR teacher when navigating around obstacles with complex 3D geometries, such as overhanging structures and low-profile objects, that fall outside the single scan plane of a 2D LiDAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a teacher-student distillation framework for vision-based omnidirectional robot navigation. A teacher policy is trained via PPO in NVIDIA Isaac Lab using privileged 2D LiDAR observations that account for the full robot footprint. This behavior is distilled into a student policy that operates solely on monocular depth maps generated by a fine-tuned Depth Anything V2 model from four onboard RGB cameras. The full pipeline (MDE, policy, and control) runs onboard an NVIDIA Jetson Orin AGX on a DJI RoboMaster platform. Simulation results report student success rates of 82-96.5% versus 50-89% for the teacher; real-world trials claim the student outperforms the teacher on complex 3D obstacles (overhangs, low-profile objects) outside the 2D LiDAR plane.
Significance. If the real-world performance advantage is substantiated, the work provides a concrete demonstration that monocular depth estimation can replace 2D LiDAR for 3D-aware navigation in industrial settings, with fully onboard inference. The teacher-student approach successfully transfers privileged simulation information to a vision-only policy, addressing a practical sensor limitation. Strengths include the end-to-end onboard deployment and direct empirical comparison of teacher and student under identical task conditions.
major comments (1)
- [Real-world experiments] Real-world experiments section: the headline claim that the MDE-based student outperforms the 2D LiDAR teacher on overhanging and low-profile obstacles rests on the unverified assumption that the fine-tuned Depth Anything V2 produces sufficiently accurate and temporally consistent depth maps under real lighting and texture. No MAE/RMSE statistics, no ground-truth depth comparison (e.g., stereo or LiDAR), and no lighting-ablation results are reported for the exact obstacle set used in the trials. Without these data the observed advantage cannot be confidently attributed to 3D perception rather than sensor placement or policy robustness.
minor comments (1)
- [Abstract] Abstract: success rates are stated as ranges (82-96.5%, 50-89%) without specifying the number of trials per condition, statistical tests, or failure-mode breakdown, making it difficult to assess the reliability of the reported margins.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address the major comment point-by-point below, providing clarifications and committing to revisions that strengthen the presentation of our real-world results without overstating the evidence.
read point-by-point responses
-
Referee: Real-world experiments section: the headline claim that the MDE-based student outperforms the 2D LiDAR teacher on overhanging and low-profile obstacles rests on the unverified assumption that the fine-tuned Depth Anything V2 produces sufficiently accurate and temporally consistent depth maps under real lighting and texture. No MAE/RMSE statistics, no ground-truth depth comparison (e.g., stereo or LiDAR), and no lighting-ablation results are reported for the exact obstacle set used in the trials. Without these data the observed advantage cannot be confidently attributed to 3D perception rather than sensor placement or policy robustness.
Authors: We agree that direct quantitative validation of depth accuracy (MAE/RMSE, ground-truth comparisons, or lighting ablations) would provide stronger causal evidence linking the performance gains specifically to 3D perception. Our primary evaluation metric remains navigation success rate under identical task conditions, where the student policy consistently outperforms the teacher on obstacles outside the 2D LiDAR plane. This empirical advantage is measured by task completion rather than intermediate depth error. In the revised manuscript we will (1) expand the real-world section with additional qualitative depth-map visualizations overlaid on the actual obstacle geometries from the trials, (2) include a brief discussion of the fine-tuning dataset and observed temporal consistency during deployment, and (3) add an explicit limitations paragraph noting the absence of synchronized ground-truth depth sensors in the real-world setup. No lighting-ablation experiments were conducted because all trials occurred under the same controlled indoor lighting; we will state this clearly. These changes will be marked as partial revisions. revision: partial
Circularity Check
No significant circularity detected in empirical teacher-student pipeline
full rationale
The manuscript describes a standard PPO-trained teacher policy using privileged 2D LiDAR observations followed by behavioral cloning/distillation into a student policy that consumes monocular depth maps from a fine-tuned Depth Anything V2 model. All reported results consist of direct empirical success-rate measurements in simulation (82-96.5%) and real-world trials; no equations, uniqueness theorems, or parameter predictions are presented that reduce by construction to the training inputs or to self-citations. The core claims rest on observable performance differences rather than any self-definitional or fitted-input renaming step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monocular depth maps from fine-tuned Depth Anything V2 are accurate enough for policy execution in real environments
- domain assumption Simulation-to-real transfer via distillation preserves policy robustness
Reference graph
Works this paper leans on
-
[1]
T. Lackner, J. Hermann, C. Kuhn, and D. Palm, “Review of autonomous mobile robots in intralogistics: state-of-the-art, limitations and research gaps,”Procedia CIRP, vol. 130, pp. 930–935, 2024. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S2212827124013441
work page 2024
-
[2]
Y . Han, I. H. Zhan, W. Zhao, J. Pan, Z. Zhang, Y . Wang, and Y .-J. Liu, “Deep reinforcement learning for robot collision avoidance with self-state-attention and sensor fusion,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 6886–6893, 2022
work page 2022
-
[3]
H. Gim, S. Baek, J. Park, H. Lee, C. Sung, K.-T. Kim, and S. Han, “Suitability of various lidar and radar sensors for application in robotics: A measurable capability comparison,”IEEE Robotics & Automation Magazine, vol. 30, no. 3, pp. 28–43, 2023
work page 2023
-
[4]
Evaluation of on-robot depth sensors for industrial robotics,
O. A. Adamides, A. Avery, K. Subramanian, and F. Sahin, “Evaluation of on-robot depth sensors for industrial robotics,” in2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), 2023, pp. 1014–1021
work page 2023
-
[5]
A survey on deep stereo matching in the twenties,
F. Tosi, L. Bartolomei, and M. Poggi, “A survey on deep stereo matching in the twenties,”International Journal of Computer Vision, vol. 133, pp. 4245–4276, 2025
work page 2025
-
[6]
U. Rajapaksha, F. Sohel, H. Laga, D. Diepeveen, and M. Bennamoun, “Deep learning-based depth estimation methods from monocular image and videos: A comprehensive survey,”ACM Comput. Surv., vol. 56, no. 12, Oct. 2024. [Online]. Available: https: //doi.org/10.1145/3677327
-
[7]
M. Hu, W. Yin, C. Zhang, Z. Cai, X. Long, H. Chen, K. Wang, G. Yu, C. Shen, and S. Shen, “Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 579–10 596, Dec. 2024. [Online]. Available: http://dx.doi.o...
-
[8]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 21 875–21 911
work page 2024
-
[9]
D. Chen, B. Zhou, V . Koltun, and P. Kr ¨ahenb¨uhl, “Learning by cheating,” inProceedings of the Conference on Robot Learning, ser. Proceedings of Machine Learning Research, L. P. Kaelbling, D. Kragic, and K. Sugiura, Eds., vol. 100. PMLR, 2020, pp. 66–75. [Online]. Available: https://proceedings.mlr.press/v100/chen20a.html
work page 2020
-
[10]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Duet al., “Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025. [Online]. Available: https://arxiv.org/abs/2511.04831
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ International Con- ference on Intelligent Robots and Systems (IROS), 2017, pp. 23–30
work page 2017
-
[12]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science Robotics, vol. 7, no. 62, p. eabk2822,
-
[13]
Available: https://www.science.org/doi/abs/10.1126/ scirobotics.abk2822
[Online]. Available: https://www.science.org/doi/abs/10.1126/ scirobotics.abk2822
-
[14]
Deep reinforcement learning for robotics: A survey of real-world successes,
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Mart ´ın-Mart´ın, and P. Stone, “Deep reinforcement learning for robotics: A survey of real-world successes,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 8, no. 1, pp. 153–188, 2025. [Online]. Available: https://www.annualreviews.org/content/journals/ 10.1146/annurev-control-030323-022510
-
[15]
Navigating to objects in the real world,
T. Gervet, S. Chintala, D. Batra, J. Malik, and D. S. Chaplot, “Navigating to objects in the real world,”Science Robotics, vol. 8, no. 79, p. eadf6991, 2023
work page 2023
-
[16]
Murosim – a fast and efficient multi-robot simulation for learning-based navigation,
C. Jestel, K. R ¨osner, N. Dietz, N. Bach, J. Eßer, J. Finke, and O. Urbann, “Murosim – a fast and efficient multi-robot simulation for learning-based navigation,” in2024 IEEE International Conference on Robotics and Automation (ICRA), 2024, pp. 16 881–16 887
work page 2024
-
[17]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on Robot Learning (CoRL). PMLR, 2022, pp. 91–100
work page 2022
-
[19]
Towards real-time monocular depth estimation for robotics: A survey,
X. Dong, M. A. Garratt, S. G. Anavatti, and H. A. Abbass, “Towards real-time monocular depth estimation for robotics: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 10, pp. 16 940–16 961, 2022
work page 2022
-
[20]
Monocular camera-based complex obstacle avoidance via efficient deep reinforcement learning,
J. Ding, L. Gao, W. Liu, H. Piao, J. Pan, Z. Du, X. Yang, and B. Yin, “Monocular camera-based complex obstacle avoidance via efficient deep reinforcement learning,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 2, pp. 756–770, 2023
work page 2023
-
[21]
Fastdepth: Fast monocular depth estimation on embedded systems,
D. Wofk, F. Ma, T.-J. Yang, S. Karaman, and V . Sze, “Fastdepth: Fast monocular depth estimation on embedded systems,” in2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 6101–6108
work page 2019
-
[22]
Real-time monocular depth estimation on embedded systems,
C. Feng, C. Zhang, Z. Chen, W. Hu, and L. Ge, “Real-time monocular depth estimation on embedded systems,” in2024 IEEE International Conference on Image Processing (ICIP), 2024, pp. 3464–3470
work page 2024
-
[23]
A vision-based irregular obstacle avoidance framework via deep reinforcement learning,
L. Gao, J. Ding, W. Liu, H. Piao, Y . Wang, X. Yang, and B. Yin, “A vision-based irregular obstacle avoidance framework via deep reinforcement learning,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 9262–9269
work page 2021
-
[24]
A. B. Mortensen, E. T. Pedersen, L. V . Benedicto, L. Burg, M. R. Madsen, and S. Bøgh, “Two-stage reinforcement learning for planetary rover navigation: Reducing the reality gap with offline noisy data,” in 2024 International Conference on Space Robotics (iSpaRo), 2024, pp. 266–272
work page 2024
-
[25]
Dune: Sim2real transfer for depth-based navigation in unstructured dynamic indoor environments,
C. Xu, W. Liu, J. Wang, L. Ma, F. Yin, and Z. Deng, “Dune: Sim2real transfer for depth-based navigation in unstructured dynamic indoor environments,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
work page 2025
-
[26]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind, “Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding,” inInterna- tional Conference on Computer Vision (ICCV) 2021, 2021
work page 2021
-
[27]
Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,
L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V . Mnih, T. Ward, Y . Doron, V . Firoiu, T. Harley, I. Dunninget al., “Impala: Scalable dis- tributed deep-rl with importance weighted actor-learner architectures,” inInternational conference on machine learning. PMLR, 2018, pp. 1407–1416
work page 2018
-
[28]
Visual-inertial mapping with non-linear factor recovery,
V . C. Usenko, N. Demmel, D. Schubert, J. St ¨uckler, and D. Cre- mers, “Visual-inertial mapping with non-linear factor recovery,”IEEE Robotics and Automation Letters, vol. 5, pp. 422–429, 2019
work page 2019
-
[29]
Apriltag: A robust and flexible visual fiducial system,
E. Olson, “Apriltag: A robust and flexible visual fiducial system,” in 2011 IEEE International Conference on Robotics and Automation, 2011, pp. 3400–3407
work page 2011
-
[30]
A generic camera calibration method for fish-eye lenses,
J. Kannala and S. Brandt, “A generic camera calibration method for fish-eye lenses,” in2004 International Conference on Pattern Recognition (ICPR), vol. 1, 2004, pp. 10–13
work page 2004
-
[31]
Simulation modeling of highly dynamic omnidirectional mobile robots based on real-world data,
M. Wiedemann, O. Ahmed, A. Dieckh ¨ofer, R. Gasoto, and S. Kerner, “Simulation modeling of highly dynamic omnidirectional mobile robots based on real-world data,” in2024 IEEE International Confer- ence on Robotics and Automation (ICRA), 2024, pp. 16 923–16 929
work page 2024
-
[32]
Automated tuning of non-differentiable rigid body simulation models for wheeled mobile robots,
M. Wiedemann, O. Ahmed, M. Hatwar, R. Gasoto, P. Detzner, and S. Kerner, “Automated tuning of non-differentiable rigid body simulation models for wheeled mobile robots,” in2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), 2025, pp. 2436–2443
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.