Recognition: 2 theorem links
· Lean TheoremPlaneCycle: Training-Free 2D-to-3D Lifting of Foundation Models Without Adapters
Pith reviewed 2026-05-15 16:40 UTC · model grok-4.3
The pith
Cycling feature aggregation through three orthogonal planes lifts any pretrained 2D backbone to 3D tasks without training or new parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By cyclically distributing spatial aggregation across the three orthogonal planes HW, DW, and DH at successive depths, a standard 2D pretrained network acquires intrinsic 3D fusion capability, yielding competitive performance on volumetric tasks without any structural change, adapter, or retraining.
What carries the argument
PlaneCycle operator that cycles 2D spatial operations sequentially across the HW, DW, and DH planes through network depth.
If this is right
- Lifted models exhibit 3D fusion ability immediately, without any training step.
- Under linear probing the models surpass slice-wise 2D baselines and several strong 3D counterparts.
- After full fine-tuning the models reach parity with standard 3D architectures on the same tasks.
- The operator applies unchanged to any 2D network backbone.
- No additional parameters are introduced at any stage.
Where Pith is reading between the lines
- The same cyclic routing might be tested on video or 4D data by adding a temporal plane to the cycle.
- Pure transformer backbones without convolutions could be evaluated to check whether the plane cycle still suffices for 3D fusion.
- If the method works across many 2D architectures, it suggests that 3D structure can be recovered from repeated 2D plane views rather than requiring native 3D kernels from the first layer.
- The approach could be applied to other pretrained 2D models beyond DINOv3 to test generality.
Load-bearing premise
Cycling spatial aggregation across orthogonal planes produces progressive 3D fusion without disrupting the pretrained 2D inductive biases.
What would settle it
If linear-probe accuracy on the nine 3D benchmarks equals that of a pure slice-wise 2D baseline, the claim of progressive 3D fusion from the plane cycle would be falsified.
Figures
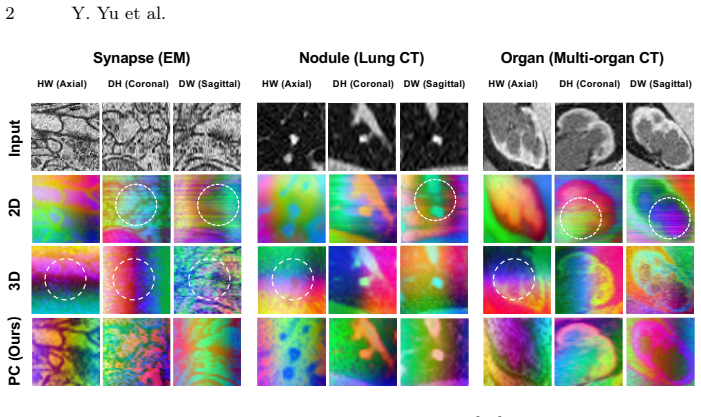


read the original abstract
Large-scale 2D foundation models exhibit strong transferable representations, yet extending them to 3D volumetric data typically requires retraining, adapters, or architectural redesign. We introduce PlaneCycle, a training-free, adapter-free operator for architecture-agnostic 2D-to-3D lifting of foundation models. PlaneCycle reuses the original pretrained 2D backbone by cyclically distributing spatial aggregation across orthogonal HW, DW, and DH planes throughout network depth, enabling progressive 3D fusion while preserving pretrained inductive biases. The method introduces no additional parameters and is applicable to arbitrary 2D networks. Using pretrained DINOv3 models, we evaluate PlaneCycle on six 3D classification and three 3D segmentation benchmarks. Without any training, the lifted models exhibit intrinsic 3D fusion capability and, under linear probing, outperform slice-wise 2D baselines and strong 3D counterparts, approaching the performance of fully trained models. With full fine-tuning, PlaneCycle matches standard 3D architectures, highlighting its potential as a seamless and practical 2D-to-3D lifting operator. These results demonstrate that 3D capability can be unlocked from pretrained 2D foundation models without structural modification or retraining. Code is available at https://github.com/HINTLab/PlaneCycle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PlaneCycle, a training-free, adapter-free operator that lifts arbitrary pretrained 2D foundation models to 3D volumetric tasks by cyclically applying spatial aggregation across the orthogonal HW, DW, and DH planes at successive network depths. This reuses the exact pretrained weights with zero added parameters. Using DINOv3 backbones, the lifted models are evaluated on six 3D classification and three 3D segmentation benchmarks; under linear probing they outperform slice-wise 2D baselines and strong 3D counterparts, while full fine-tuning matches standard 3D architectures. The central claim is that 3D capability can thereby be unlocked from 2D foundation models without structural modification or retraining.
Significance. If the empirical results hold under detailed scrutiny, the work provides a simple, parameter-free route to 3D inference from existing 2D foundation models, reducing the need for 3D-specific pretraining or adapters. The explicit architectural operator, zero-parameter guarantee, and public code release are concrete strengths that would make the method immediately usable across vision backbones.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of outperformance on nine benchmarks under linear probing and full fine-tuning is stated at a high level only, without naming the precise 2D slice-wise and 3D baselines, reporting statistical significance, or specifying data splits and preprocessing; these omissions are load-bearing for the central empirical claim and must be supplied with tables or supplementary material.
- [§3] §3 (Method): the assertion that cycling aggregation across HW/DW/DH planes enables 'progressive 3D fusion while preserving pretrained inductive biases' is presented without an ablation isolating the contribution of the cyclic schedule versus a fixed-plane or random-plane alternative; a controlled ablation would be required to substantiate that the observed gains are due to the proposed mechanism rather than generic multi-view aggregation.
minor comments (3)
- [Figure 1 and §3.1] Figure 1 and §3.1: the diagram of the PlaneCycle operator should explicitly annotate the exact tensor reshaping steps and the reuse of the original 2D convolution weights to avoid ambiguity in implementation.
- [§4.2] §4.2: all benchmark names, dataset sizes, and evaluation metrics should be listed in a single table for quick reference rather than scattered across paragraphs.
- The paper should add a short limitations paragraph discussing any failure cases (e.g., highly anisotropic volumes) where the cyclic plane schedule may degrade performance.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments on empirical clarity and methodological justification. We address each major point below and will incorporate the requested details and analysis in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of outperformance on nine benchmarks under linear probing and full fine-tuning is stated at a high level only, without naming the precise 2D slice-wise and 3D baselines, reporting statistical significance, or specifying data splits and preprocessing; these omissions are load-bearing for the central empirical claim and must be supplied with tables or supplementary material.
Authors: We agree that greater specificity is required to substantiate the central empirical claims. In the revised manuscript we will expand the abstract to name the exact 2D slice-wise baselines (DINOv3 applied independently per slice) and 3D counterparts (3D ResNet-50, 3D ViT, and other volumetric models from the literature). Section 4 will include a new table (or move existing results to a more detailed table) that lists all nine benchmarks, precise data splits and preprocessing pipelines drawn from the standard datasets, and all metrics reported as mean ± std over five random seeds. These additions will appear in the main text where feasible or in the supplementary material, directly addressing the load-bearing omissions while preserving the reported performance numbers. revision: yes
-
Referee: [§3] §3 (Method): the assertion that cycling aggregation across HW/DW/DH planes enables 'progressive 3D fusion while preserving pretrained inductive biases' is presented without an ablation isolating the contribution of the cyclic schedule versus a fixed-plane or random-plane alternative; a controlled ablation would be required to substantiate that the observed gains are due to the proposed mechanism rather than generic multi-view aggregation.
Authors: We acknowledge the value of a controlled ablation to isolate the cyclic schedule. The current manuscript motivates the design via the progressive-fusion argument in §3, but does not contain the requested comparison. In the revision we will add an ablation (in §3 or the supplementary material) that evaluates three controlled variants on the same backbones and benchmarks: (1) the proposed cyclic schedule (HW→DW→DH repeating across depth), (2) fixed-plane aggregation (always HW), and (3) random-plane selection per layer. All other factors, including pretrained weights and aggregation operators, will remain identical. This will quantify whether the cyclic ordering yields superior progressive 3D fusion relative to static or random multi-view aggregation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines PlaneCycle explicitly as a drop-in architectural operator that cycles spatial aggregation over HW/DW/DH planes in frozen 2D backbones. No equations, parameters, or claims reduce by construction to their own inputs; the operator is stated directly without self-definition, fitted inputs relabeled as predictions, or load-bearing self-citations. Performance is evaluated on external benchmarks rather than internal tautologies, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 2D foundation models contain transferable representations that can be extended to 3D via cyclic plane-wise aggregation.
Lean theorems connected to this paper
-
Foundation/AlexanderDuality.leanalexander_duality_circle_linking matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
cyclically distributing spatial aggregation across orthogonal HW, DW, and DH planes throughout network depth, enabling progressive 3D fusion while preserving pretrained inductive biases. ... four-operator cycle: HW(axial)→DW(coronal)→DH(sagittal)→HW
-
Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The method introduces no additional parameters and is applicable to arbitrary 2D networks. ... yields well-aligned 3D features across HW, DW, and DH without additional supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Medical Physics38(2), 915–931 (2011)
Armato III, S.G., McLennan, G., Bidaut, L., others.: The lung image database con- sortium (lidc) and image database resource initiative (idri): A completed reference database of lung nodules on ct scans. Medical Physics38(2), 915–931 (2011)
work page 2011
-
[2]
In: International Conference on Computer Vision
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: A video vision transformer. In: International Conference on Computer Vision. pp. 6836–6846 (2021)
work page 2021
-
[3]
Bilic, P., Christ, P.F., et al.: The liver tumor segmentation benchmark (lits). arXiv Preprint (2019)
work page 2019
-
[4]
In: International Conference on Computer Vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: International Conference on Computer Vision. pp. 9650–9660 (2021)
work page 2021
-
[5]
In: Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
work page 2017
-
[6]
In: International Con- ference on Learning Representations (2021)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. In: International Con- ference on Learning Representations (2021)
work page 2021
-
[7]
Nature Biomedical Engineering pp
Hamamci, I.E., Er, S., Wang, C., Almas, F., Simsek, A.G., Esirgun, S.N., Dogan, I., Durugol, O.F., Hou, B., Shit, S., et al.: Generalist foundation models from a multimodal dataset for 3d computed tomography. Nature Biomedical Engineering pp. 1–19 (2026)
work page 2026
-
[8]
In: Conference on Computer Vision and Pattern Recogni- tion
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Conference on Computer Vision and Pattern Recogni- tion. pp. 16000–16009 (2022) 10 Y. Yu et al
work page 2022
-
[9]
In: Conference on Computer Vision and Pattern Recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
work page 2016
-
[10]
International Confer- ence on Learning Representations1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. International Confer- ence on Learning Representations1(2), 3 (2022)
work page 2022
-
[11]
In: Conference on Medical Image Computing and Computer Assisted Intervention
Isensee, F., Wald, T., Ulrich, C., Baumgartner, M., Roy, S., Maier-Hein, K., Jaeger, P.F.: nnu-net revisited: A call for rigorous validation in 3d medical image seg- mentation. In: Conference on Medical Image Computing and Computer Assisted Intervention. pp. 488–498. Springer (2024)
work page 2024
-
[12]
Bioinformatics40(7), btae368 (2024)
Jain, S., Li, X., Xu, M.: Knowledge transfer from macro-world to micro-world: enhancing 3d cryo-et classification through fine-tuning video-based deep models. Bioinformatics40(7), btae368 (2024)
work page 2024
-
[13]
EBioMedicine 62, 103106 (2020)
Jin, L., Yang, J., Kuang, K., Ni, B., Gao, Y., Sun, Y., Gao, P., Ma, W., Tan, M., Kang, H., Chen, J., Li, M.: Deep-learning-assisted detection and segmentation of rib fractures from ct scans: Development and validation of fracnet. EBioMedicine 62, 103106 (2020)
work page 2020
-
[14]
In: International Conference on Computer Vision
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: International Conference on Computer Vision. pp. 4015–4026 (2023)
work page 2023
-
[15]
Li, Y., Wu, Y., Lai, Y., Hu, M., Yang, X.: Meddinov3: How to adapt vision foun- dation models for medical image segmentation? arXiv Preprint (2025)
work page 2025
-
[16]
Liu, C., Chen, Y., Shi, H., Lu, J., Jian, B., Pan, J., Cai, L., Wang, J., Zhang, Y., Li, J., et al.: Does dinov3 set a new medical vision standard? arXiv Preprint (2025)
work page 2025
-
[17]
Liu, H., Georgescu, B., Zhang, Y., Yoo, Y., Baumgartner, M., Gao, R., Wang, J., Zhao, G., Gibson, E., Comaniciu, D., et al.: Revisiting 2d foundation models for scalable 3d medical image classification. arXiv Preprint (2025)
work page 2025
-
[18]
In: International Conference on Learning Representations (2018)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (2018)
work page 2018
-
[19]
Nature communications15(1), 654 (2024)
Ma, J., He, Y., Li, F., Han, L., You, C., Wang, B.: Segment anything in medical images. Nature communications15(1), 654 (2024)
work page 2024
-
[20]
Roy, S., Kirchhoff, Y., Ulrich, C., Rokuss, M., Wald, T., Isensee, F., Maier-Hein, K.: Mednext-v2: Scaling 3d convnexts for large-scale supervised representation learning in medical image segmentation. arXiv Preprint (2025)
work page 2025
-
[21]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv Preprint (2025)
work page 2025
-
[22]
Neurocomputing568, 127063 (2024)
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing568, 127063 (2024)
work page 2024
-
[23]
Wald, T., Roy, S., Isensee, F., Ulrich, C., Ziegler, S., Trofimova, D., Stock, R., Baumgartner, M., Köhler, G., Maier-Hein, K.: Primus: enforcing attention usage for 3d medical image segmentation (2025)
work page 2025
-
[24]
In: European Conference on Computer Vision
Wang, Y., Li, K., Li, X., Yu, J., He, Y., Chen, G., Pei, B., Zheng, R., Wang, Z., Shi, Y., et al.: Internvideo2: Scaling foundation models for multimodal video un- derstanding. In: European Conference on Computer Vision. pp. 396–416. Springer (2024)
work page 2024
-
[25]
Wei, X., Liu, X., Zang, Y., Dong, X., Zhang, P., Cao, Y., Tong, J., Duan, H., Guo, Q., Wang, J., et al.: Videorope: What makes for good video rotary position embedding? arXiv Preprint (2025)
work page 2025
-
[26]
Medical Image Analysis102, 103547 (2025) P laneCycle: Training-Free 2D-to-3D Model Lifting 11
Wu, J., Wang, Z., Hong, M., Ji, W., Fu, H., Xu, Y., Xu, M., Jin, Y.: Medical sam adapter: Adapting segment anything model for medical image segmentation. Medical Image Analysis102, 103547 (2025) P laneCycle: Training-Free 2D-to-3D Model Lifting 11
work page 2025
-
[27]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Wu, L., Zhuang, J., Chen, H.: Large-scale 3d medical image pre-training with geometric context priors. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
work page 2025
-
[28]
IEEE Transactions on Medical Imaging38(8), 1885–1898 (2019)
Xu, X., Zhou, F., et al.: Efficient multiple organ localization in ct image using 3d region proposal network. IEEE Transactions on Medical Imaging38(8), 1885–1898 (2019)
work page 2019
-
[29]
Nature Computa- tional Science4(7), 473–474 (2024)
Yang, J.: Multi-task learning for medical foundation models. Nature Computa- tional Science4(7), 473–474 (2024)
work page 2024
-
[30]
In: Conference on Medical Image Computing and Computer Assisted Intervention
Yang, J., He, Y., Kuang, K., Lin, Z., Pfister, H., Ni, B.: Asymmetric 3d context fusion for universal lesion detection. In: Conference on Medical Image Computing and Computer Assisted Intervention. pp. 571–580. Springer (2021)
work page 2021
-
[31]
IEEE Journal of Biomedical and Health Informatics 25(8), 3009–3018 (2021)
Yang, J., Huang, X., He, Y., Xu, J., Yang, C., Xu, G., Ni, B.: Reinventing 2d convolutions for 3d images. IEEE Journal of Biomedical and Health Informatics 25(8), 3009–3018 (2021)
work page 2021
-
[32]
Scientific Data10(1), 41 (2023)
Yang,J.,Shi,R.,Wei,D.,Liu,Z.,Zhao,L.,Ke,B.,Pfister,H.,Ni,B.:Medmnistv2- a large-scale lightweight benchmark for 2d and 3d biomedical image classification. Scientific Data10(1), 41 (2023)
work page 2023
-
[33]
In: Conference on Computer Vision and Pattern Recognition (June 2020)
Yang, X., Xia, D., Kin, T., Igarashi, T.: Intra: 3d intracranial aneurysm dataset for deep learning. In: Conference on Computer Vision and Pattern Recognition (June 2020)
work page 2020
-
[34]
Medical Image Analysis 58, 101537 (2019)
Zhuang, X., Li, L., Payer, C., Štern, D., Urschler, M., Heinrich, M.P., Oster, J., Wang, C., Smedby, Ö., Bian, C., et al.: Evaluation of algorithms for multi-modality whole heart segmentation: an open-access grand challenge. Medical Image Analysis 58, 101537 (2019)
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.