Recognition: no theorem link
Poisoning the Inner Prediction Logic of Graph Neural Networks for Clean-Label Backdoor Attacks
Pith reviewed 2026-05-15 16:12 UTC · model grok-4.3
The pith
Coordinating a poisoned node selector with a logic-poisoning trigger generator lets graph neural networks learn to treat triggers as dominant predictors while training labels remain unchanged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that existing backdoor methods cannot succeed in clean-label settings because they leave the prediction logic unpoisoned, so triggers remain unimportant; coordinating a poisoned node selector and a logic-poisoning trigger generator solves this by making the triggers control the model's output on triggered test nodes without any label modification during training.
What carries the argument
BA-Logic, which pairs a poisoned node selector that identifies suitable training nodes with a logic-poisoning trigger generator that produces triggers capable of dominating the GNN's internal decision process.
If this is right
- Attack success rates rise above those of prior graph backdoor methods when labels must stay fixed.
- Triggers attached only at test time become the dominant factor in the model's output.
- The poisoned logic persists through ordinary training without special detection steps.
- The same coordination works across multiple real-world graph datasets.
Where Pith is reading between the lines
- Defenses that rely solely on label-consistency checks would miss the attack entirely.
- The same selector-generator pattern could be tested on other GNN tasks such as link prediction or graph classification.
- Inspecting changes in node embedding importance or attention scores after training might reveal the poisoned logic before deployment.
- Extending the approach to dynamic or heterogeneous graphs would test whether the logic-poisoning effect generalizes beyond static homogeneous cases.
Load-bearing premise
The inner prediction logic of a GNN can be altered independently of label changes so that a specific trigger reliably overrides normal predictions at test time.
What would settle it
Training a GNN with the proposed selector and generator on a standard dataset and measuring that triggered test nodes are not classified as the target class at rates higher than baseline clean-label attacks.
Figures














read the original abstract
Graph Neural Networks (GNNs) have achieved remarkable results in various tasks. Recent studies reveal that graph backdoor attacks can poison the GNN model to predict test nodes with triggers attached as the target class. However, apart from injecting triggers to training nodes, these graph backdoor attacks generally require altering the labels of trigger-attached training nodes into the target class, which is impractical in real-world scenarios. In this work, we focus on the clean-label graph backdoor attack, a realistic but understudied topic where training labels are not modifiable. According to our preliminary analysis, existing graph backdoor attacks generally fail under the clean-label setting. Our further analysis identifies that the core failure of existing methods lies in their inability to poison the prediction logic of GNN models, leading to the triggers being deemed unimportant for prediction. Therefore, we study a novel problem of effective clean-label graph backdoor attacks by poisoning the inner prediction logic of GNN models. We propose BA-Logic to solve the problem by coordinating a poisoned node selector and a logic-poisoning trigger generator. Extensive experiments on real-world datasets demonstrate that our method effectively enhances the attack success rate and surpasses state-of-the-art graph backdoor attack competitors under clean-label settings. Our code is available at https://anonymous.4open.science/r/BA-Logic
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies that existing clean-label graph backdoor attacks on GNNs fail because they do not poison the models' inner prediction logic, leaving triggers unimportant to predictions. It proposes BA-Logic, which coordinates a poisoned node selector with a logic-poisoning trigger generator to alter this logic under clean labels, and reports that extensive experiments on real-world datasets yield higher attack success rates than prior methods.
Significance. If the central mechanism is mechanistically validated, the work would demonstrate a practical route to clean-label backdoor attacks that reliably make triggers dominate GNN predictions, exposing a previously under-appreciated vulnerability in graph models used for node classification and similar tasks.
major comments (3)
- [Abstract and §3] Abstract and §3 (preliminary analysis): the assertion that existing methods fail specifically because they leave the prediction logic unpoisoned is presented without quantitative support such as trigger importance scores, attention weights, or gradient attributions comparing poisoned vs. clean models; this makes the diagnosis of the 'core failure' difficult to verify.
- [§4] §4 (BA-Logic): the coordination of the poisoned node selector and logic-poisoning trigger generator is claimed to poison inner prediction logic independently of label changes, yet no before/after analysis (e.g., parameter inspection, feature attribution maps, or ablation isolating the generator from the selector) is described to rule out the alternative that success arises from selector bias toward high-influence nodes rather than genuine logic alteration.
- [§5] §5 (experiments): while the abstract states that the method 'surpasses state-of-the-art' under clean-label settings, the provided description supplies no dataset sizes, model architectures, attack success rate tables, or ablation results that would allow assessment of whether the reported gains are robust or merely reflect particular graph structures.
minor comments (2)
- [Abstract] The anonymous code link should be replaced with a permanent repository or removed if the review process requires reproducibility checks.
- [§4] Notation for the trigger generator and selector should be introduced with explicit equations or pseudocode early in §4 to clarify their interaction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our paper addressing clean-label backdoor attacks on GNNs via inner logic poisoning. We clarify the supporting analyses in Sections 3-5 and outline targeted revisions to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (preliminary analysis): the assertion that existing methods fail specifically because they leave the prediction logic unpoisoned is presented without quantitative support such as trigger importance scores, attention weights, or gradient attributions comparing poisoned vs. clean models; this makes the diagnosis of the 'core failure' difficult to verify.
Authors: Section 3 presents a preliminary analysis demonstrating that prior clean-label methods yield low attack success rates because triggers do not influence predictions, supported by comparative success rate drops when triggers are removed. To strengthen this, we will add explicit quantitative metrics including trigger importance scores via attention weights and gradient attributions on poisoned versus clean models in the revised Section 3. revision: yes
-
Referee: [§4] §4 (BA-Logic): the coordination of the poisoned node selector and logic-poisoning trigger generator is claimed to poison inner prediction logic independently of label changes, yet no before/after analysis (e.g., parameter inspection, feature attribution maps, or ablation isolating the generator from the selector) is described to rule out the alternative that success arises from selector bias toward high-influence nodes rather than genuine logic alteration.
Authors: BA-Logic's design ensures the trigger generator directly modifies prediction logic while the selector only identifies nodes; Section 5 already includes ablations isolating the generator's contribution from the selector. We will add before/after feature attribution maps and parameter inspections in the revised Section 4 to explicitly rule out selector bias as the sole source of success. revision: yes
-
Referee: [§5] §5 (experiments): while the abstract states that the method 'surpasses state-of-the-art' under clean-label settings, the provided description supplies no dataset sizes, model architectures, attack success rate tables, or ablation results that would allow assessment of whether the reported gains are robust or merely reflect particular graph structures.
Authors: The full Section 5 details dataset sizes (e.g., Cora: 2708 nodes, CiteSeer: 3327 nodes), architectures (GCN, GAT, GraphSAGE), comprehensive ASR tables versus baselines, and component ablations across multiple real-world graphs to confirm robustness. We will expand the abstract with a brief summary of key experimental settings for accessibility. revision: partial
Circularity Check
No significant circularity; empirical attack design without derivations or self-referential reductions
full rationale
The paper presents BA-Logic as a coordinated selector-generator method for clean-label graph backdoor attacks, supported by preliminary analysis and extensive experiments on real-world datasets. No equations, mathematical derivations, or first-principles claims are present that could reduce to fitted inputs or self-definitions by construction. The core claim (that selector-generator coordination poisons inner prediction logic) is positioned as an empirical solution rather than a derived result; success is measured via attack success rate comparisons, not via any chain that loops back to the method's own parameters or prior self-citations as load-bearing. This is a standard empirical contribution with no circularity patterns matching the enumerated kinds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GNNs possess an identifiable inner prediction logic that can be altered independently of training labels
invented entities (1)
-
logic-poisoning trigger generator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Explainability techniques for graph convolutional networks
Federico Baldassarre and Hossein Azizpour. Explainability techniques for graph convolutional networks. InInternational Conference on Machine Learning (ICML) Workshops, 2019 Workshop on Learning and Reasoning with Graph-Structured Representations,
work page 2019
-
[2]
Yang Chen and Bin Zhou. Agsoa: Graph neural network targeted attack based on average gradient and structure optimization.arXiv preprint arXiv:2406.13228,
-
[3]
Enyan Dai and Suhang Wang. Say no to the discrimination: Learning fair graph neural networks with limited sensitive attribute information. InWSDM, pp. 680–688, 2021a. Enyan Dai and Suhang Wang. Towards self-explainable graph neural network. InCIKM, pp. 302–311, 2021b. Enyan Dai, Wei Jin, Hui Liu, and Suhang Wang. Towards robust graph neural networks for n...
work page 2023
-
[4]
A backdoor attack against link prediction tasks with graph neural networks
Jiazhu Dai and Haoyu Sun. A backdoor attack against link prediction tasks with graph neural networks. arXiv preprint arXiv:2401.02663,
-
[5]
Asemanticandclean-labelbackdoorattackagainstgraphconvolutionalnetworks
JiazhuDaiandHaoyuSun. Asemanticandclean-labelbackdoorattackagainstgraphconvolutionalnetworks. arXiv preprint arXiv:2503.14922,
-
[6]
James Kennedy and Russell Eberhart. Particle swarm optimization. InProceedings of ICNN’95-international conference on neural networks, volume 4, pp. 1942–1948. ieee,
work page 1942
-
[7]
Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann
Christopher Morris, Nils M. Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs. InICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020),
work page 2020
-
[8]
Xuelian Ni, Fei Xiong, Yu Zheng, and Liang Wang
URLwww.graphlearning.io. Xuelian Ni, Fei Xiong, Yu Zheng, and Liang Wang. Graph contrastive learning with kernel dependence maximization for social recommendation. InProceedings of the ACM Web Conference 2024, pp. 481–492,
work page 2024
-
[9]
Poster: clean-label backdoor attack on graph neural networks
Jing Xu and Stjepan Picek. Poster: clean-label backdoor attack on graph neural networks. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pp. 3491–3493,
work page 2022
-
[10]
18 A.2 Additional Results of Attack Performance on Industry-Scale Graph
17 Table of Contents for Appendix A Additional Experiments 18 A.1 Additional Discussion on Extending Method . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 A.2 Additional Results of Attack Performance on Industry-Scale Graph . . . . . . . . . . . . . . . 20 A.3 Additional Results of Attack Performance towards Sampling-Based GNNs . . . . . . . ....
work page 2020
-
[11]
•Combined with the results of Tab
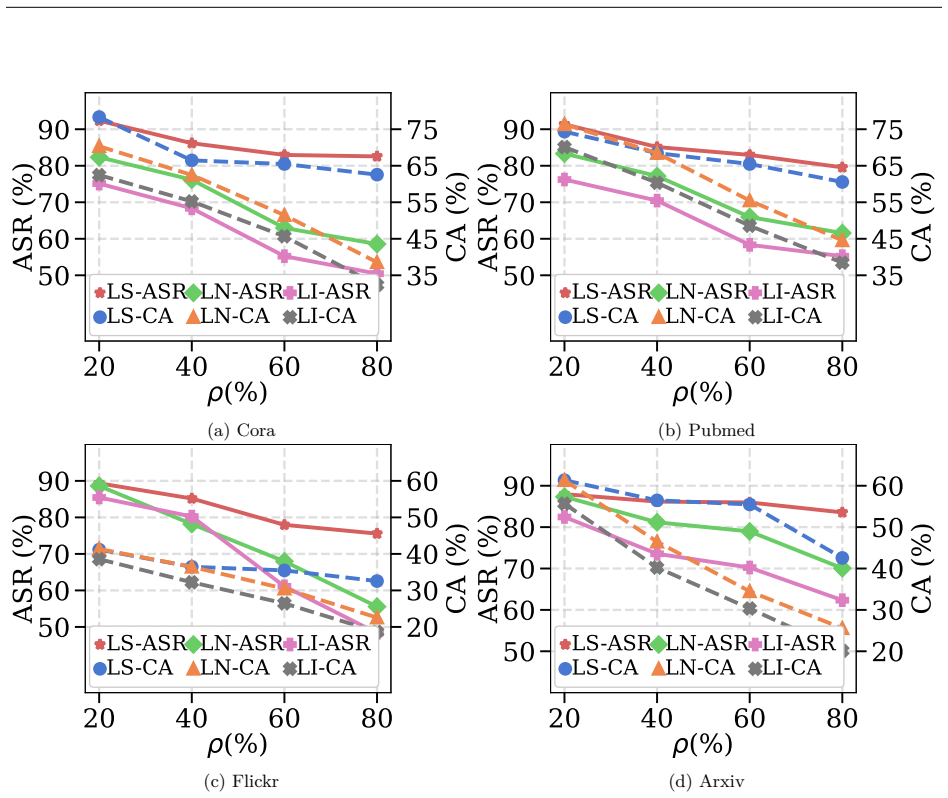
From the figure, we can observe that: •Nearly all methods show a decrease in clean accuracy, indicating that their backdoor attack process damages the normal behavior of the model, thereby weakening its practicality. •Combined with the results of Tab. 3, certain baselines (e.g., EBA-C and ECGBA) severely degrade the clean accuracy of target models, which ...
work page 2023
-
[12]
Compared to competitors,Ba-Logicstill shows significantly higher ASR. Notably, the competitors also achieve better ASR onCoraandPubmedthan the records for larger graphArxivin Tab. 5, likely due to the graphs being smaller, which aids the attack methods in generalizing trigger patterns. We further analyze why the existing defense methods in Tab. 9 fall sho...
work page 1993
-
[13]
For each dataset, we report the IRT distributions averaged over the three clean models in Tab. 3, i.e., GCN, GIN, and GAT. From these figures, we have the following key observations: •Ba-LogicshowsconcentrationofnodeswithlargeIRTvalues, withpeaksclosetothemaximalimportance score. Thisindicatesthatthelogicpoisoningtriggersareidentifiedasimportantbythelogic...
work page 2023
-
[14]
F.2 Details of Compared Methods In the main text of our work, we compareBa-Logicwith representative and state-of-the-art graph backdoor attack methods, such asDPGBA-CZhang et al. (2024b), andUGBA-CDai et al. (2023). These methods originally required altering the labels of poisoned nodes. In our experiments, we extend them to the clean- label setting by se...
work page 2023
-
[15]
The results are consistent with the time complexity analysis in Appendix D, indicating that theBa-Logicrequires only approximately 60 seconds more training time than the two most powerful competitors on a larger graph. The additional time is acceptable given that ourBa-Logicachieves an ASR over 90%, while these competitors achieve an ASR over 60%. This de...
work page 2016
-
[16]
The gray cell indicates the competitor with the highest ASR. From the table, we obtain the following key observations: •The adaptive defense can partially weaken the backdoor, indicating promising directions against logic poisoning. However, under ourBa-Logic, the ASR remains generally high, while clean accuracy signifi- cantly drops after applying adapti...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.