Recognition: 2 theorem links
· Lean TheoremUnsupervised domain adaptation for radioisotope identification in gamma spectroscopy
Pith reviewed 2026-05-15 15:48 UTC · model grok-4.3
The pith
Unsupervised domain adaptation aligns simulated gamma spectra features to real data, raising radioisotope identification accuracy from 75 to 90 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
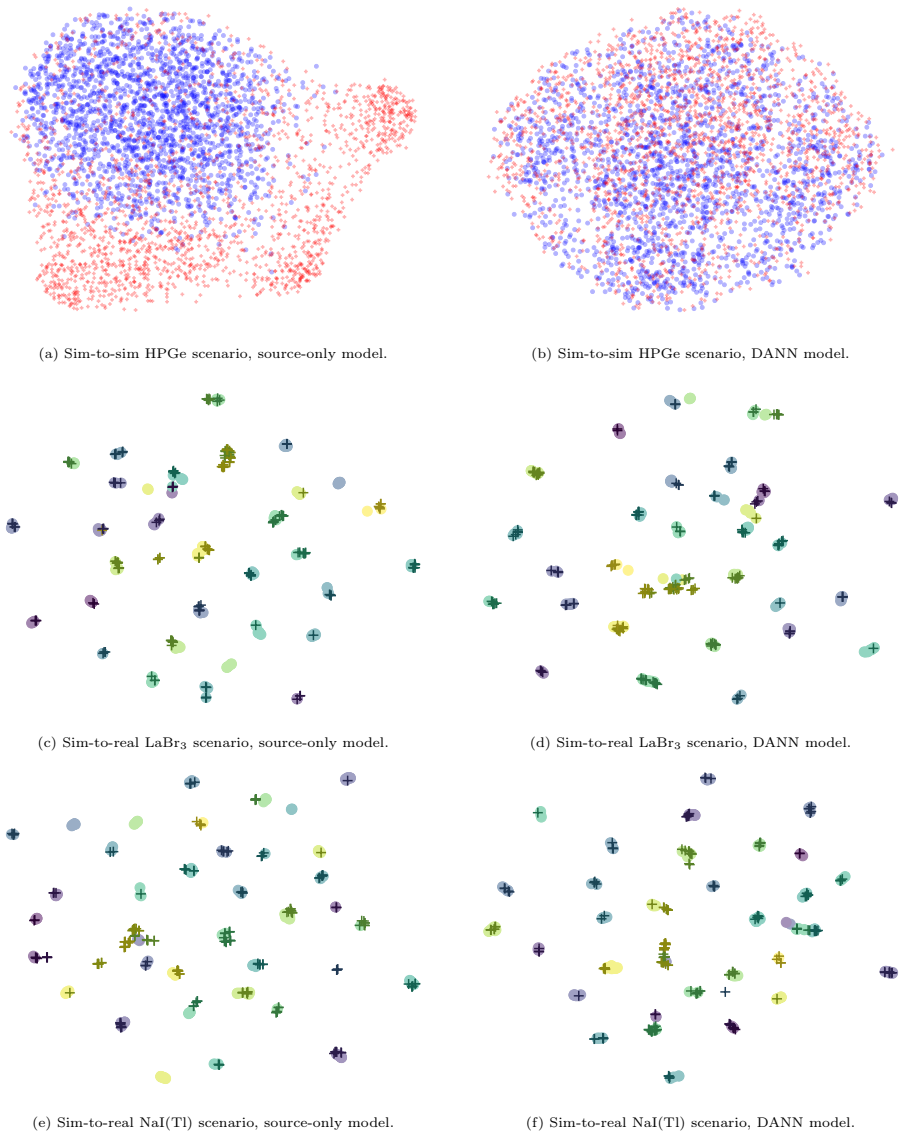
Using a custom transformer-based neural network trained on synthetic gamma spectra, unsupervised feature alignment via maximum mean discrepancy minimization achieves a testing accuracy of 0.904 ± 0.022 on an experimental LaBr3 test set, compared to 0.754 ± 0.014 without alignment. Feature alignment strategies, including MMD minimization and domain-adversarial training, provide the most consistent improvements among tested UDA techniques. This enables the model to generalize from simulated training data to real operational environments using only unlabeled target data.
What carries the argument
Unsupervised feature alignment through maximum mean discrepancy (MMD) minimization, which matches the statistical properties of features extracted from simulated and real spectra.
Load-bearing premise
The primary mismatch between simulated and real gamma spectra consists of feature distribution differences that can be aligned using only unlabeled target-domain data and standard UDA losses.
What would settle it
Observing no significant accuracy improvement or a decrease after applying MMD-based feature alignment to the transformer model on the experimental LaBr3 dataset would indicate the claim does not hold.
Figures

read the original abstract
Training machine learning models for radioisotope identification using gamma spectroscopy remains an elusive challenge for many practical applications, largely stemming from the difficulty of acquiring and labeling large, diverse experimental datasets. Simulations can mitigate this challenge, but the accuracy of models trained on simulated data can deteriorate substantially when deployed to an out-of-distribution operational environment. In this study, we demonstrate that unsupervised domain adaptation (UDA) can improve the ability of a model trained on synthetic data to generalize to a new testing domain, provided unlabeled data from the target domain is available. Conventional supervised techniques are unable to utilize this data because the absence of isotope labels precludes defining a supervised classification loss. We compare a range of different UDA techniques, finding that feature alignment strategies, particularly via maximum mean discrepancy (MMD) minimization or domain-adversarial training, yield the most consistent improvement to testing scores. For instance, using a custom transformer-based neural network, we achieve a testing accuracy of $0.904 \pm 0.022$ on an experimental LaBr$_3$ test set after performing unsupervised feature alignment via MMD minimization, compared to $0.754 \pm 0.014$ before alignment. Overall, our results highlight the potential of using UDA to adapt a radioisotope classifier trained on synthetic data for real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript demonstrates that unsupervised domain adaptation (UDA) techniques, particularly feature alignment via maximum mean discrepancy (MMD) minimization and domain-adversarial training, can improve the generalization of a transformer-based neural network trained on simulated gamma spectra to real experimental data for radioisotope identification. On an experimental LaBr3 test set, MMD alignment raises accuracy from 0.754 ± 0.014 to 0.904 ± 0.022, with comparisons across multiple UDA methods showing consistent gains when unlabeled target-domain data is available.
Significance. If the reported gains hold under scrutiny, the work provides a practical route to deploying ML classifiers for gamma spectroscopy without requiring large labeled experimental datasets, which are costly to obtain. The use of concrete accuracy metrics with standard deviations on held-out real data, combined with standard UDA objectives that avoid circularity, supports the central claim and could influence applications in nuclear security and environmental monitoring.
major comments (2)
- [Abstract and Results section] The headline result rests on the assumption that the dominant sim-to-real mismatch is a feature-distribution shift correctable by MMD (or adversarial) alignment on the transformer embeddings. The manuscript provides no explicit analysis or ablation showing that detector-specific physical effects (energy resolution variation, calibration offsets, background continuum) are mitigated by this alignment rather than remaining as residual domain gaps; if these effects dominate, the observed 0.15 accuracy gain may not generalize beyond the single LaBr3 target.
- [Experimental Results] Table reporting the accuracy numbers (with ±0.022 and ±0.014) does not specify the number of independent trials, the exact train/validation/test splits for the simulated source data, or whether the unlabeled target samples were strictly held out from any hyperparameter tuning; these details are load-bearing for interpreting the statistical significance of the improvement.
minor comments (3)
- The abstract states that 'a range of different UDA techniques' were compared, but a summary table listing each method, its objective, and the corresponding accuracy on the LaBr3 set would improve readability and allow direct comparison of MMD versus adversarial variants.
- [Methods] The transformer architecture is described as 'custom' without explicit values for embedding dimension, number of attention heads, or layer count; adding these hyperparameters (or a reference to the exact configuration) would aid reproducibility.
- [Introduction] A few citations to prior UDA work in spectroscopy or similar sensor domains are missing; including them would better situate the contribution relative to existing sim-to-real efforts.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address each major comment below and have revised the manuscript to provide the requested clarifications and additional discussion.
read point-by-point responses
-
Referee: [Abstract and Results section] The headline result rests on the assumption that the dominant sim-to-real mismatch is a feature-distribution shift correctable by MMD (or adversarial) alignment on the transformer embeddings. The manuscript provides no explicit analysis or ablation showing that detector-specific physical effects (energy resolution variation, calibration offsets, background continuum) are mitigated by this alignment rather than remaining as residual domain gaps; if these effects dominate, the observed 0.15 accuracy gain may not generalize beyond the single LaBr3 target.
Authors: We acknowledge that the manuscript lacks an explicit ablation isolating the contribution of individual physical effects such as energy resolution or calibration offsets. The transformer embeddings are trained to extract isotope-discriminative features, and the consistent gains from both MMD and adversarial alignment indicate that the procedure reduces the overall domain discrepancy. In the revised manuscript we have added a paragraph in the Results section explaining how the learned representations are expected to be robust to these effects, drawing on the architecture's attention mechanism and the nature of gamma spectra. While the evaluation is limited to a single detector, the approach itself is detector-agnostic provided unlabeled target data are available; we view the reported improvement on held-out real spectra as evidence that the dominant mismatch is being addressed. revision: partial
-
Referee: [Experimental Results] Table reporting the accuracy numbers (with ±0.022 and ±0.014) does not specify the number of independent trials, the exact train/validation/test splits for the simulated source data, or whether the unlabeled target samples were strictly held out from any hyperparameter tuning; these details are load-bearing for interpreting the statistical significance of the improvement.
Authors: The reported standard deviations are computed over five independent training runs that differ only in random seed. The simulated source data were partitioned 70/15/15 into train/validation/test sets. All hyperparameter selection, including choice of UDA method and regularization strength, was performed solely on the source-domain validation set; the unlabeled target-domain samples were never used for tuning or early stopping. We have updated the Experimental Results section and the table caption to state these details explicitly. revision: yes
Circularity Check
No significant circularity; empirical UDA results are directly measured
full rationale
The paper applies standard unsupervised domain adaptation (MMD minimization and domain-adversarial training) to align simulated source embeddings with unlabeled real target embeddings, then evaluates classification accuracy on a separate labeled experimental LaBr3 test set. The reported lift (0.904 vs 0.754) is an observed performance difference on held-out real data, not a quantity derived by construction from fitted parameters or self-citations. No self-definitional equations, no renaming of known results, and no load-bearing self-citations appear in the core claim. The derivation chain consists of conventional neural-network training plus off-the-shelf UDA losses whose validity is tested externally by the accuracy metric.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
using a custom transformer-based neural network, we achieve a testing accuracy of 0.904 ± 0.022 on an experimental LaBr3 test set after performing unsupervised feature alignment via MMD minimization
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MMD2(zs, zt) = ... kernel trick
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Breitenmoser, A. Stabilini, M. M. Kasprzak, S. Mayer, Quantitative mobile gamma-ray spectrometry through Bayesian inference (Jan. 2026).arXiv:2512.18769,doi:10.48550/arXiv.2512.18769
-
[2]
P. R. Fernández, C. Svinth, A. Hagen, Improvement of Nuclide Detection through Graph Spectroscopic Analysis Framework and its Application to Nuclear Facility Upset Detection (Jun. 2025).arXiv: 2506.16522,doi:10.48550/arXiv.2506.16522
-
[3]
S. E. Labov, K. E. Nelson, C. M. Mattoon, N. J. McFerran, M. H. Pham, L. Her, J. S. Brzosko, S. Ray, D. Howarth, A. W. Dubrawski, Improving operational performance using machine learning analysis of Radiation Portal Monitor measurements, Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Eq...
-
[4]
P. Lalor, H. Adams, A. Hagen, Sim-to-real supervised domain adaptation for radioisotope identification, Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detec- tors and Associated Equipment 1083 (2026) 171159.doi:https://doi.org/10.1016/j.nima.2025. 171159. URLhttps://www.sciencedirect.com/science/article/pii/S01...
-
[5]
G. F. Knoll, Radiation Detection and Measurement, 4th Edition, Wiley, Hoboken, NJ, 2010
work page 2010
-
[6]
M. A. Mariscotti, A method for automatic identification of peaks in the presence of background and its application to spectrum analysis, Nuclear Instruments and Methods 50 (2) (1967) 309–320.doi: 10.1016/0029-554X(67)90058-4
-
[7]
Genie 2000 Operations Manual
work page 2000
-
[8]
P. Viola, M. Jones, Rapid object detection using a boosted cascade of simple features, in: Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Vol. 1, 2001, pp. I–I.doi:10.1109/CVPR.2001.990517
-
[9]
Z. Zou, K. Chen, Z. Shi, Y. Guo, J. Ye, Object Detection in 20 Years: A Survey (Jan. 2023).arXiv: 1905.05055,doi:10.48550/arXiv.1905.05055
-
[10]
F. James, MINUIT: Function Minimization and Error Analysis Reference Manual, CERN Program Library Long Writeup D506, Conseil Européen pour la Recherche Nucléaire (CERN), Geneva (1994)
work page 1994
-
[11]
L. Reuter, G. D. Pietro, S. Stefkova, T. Ferber, V. Bertacchi, G. Casarosa, L. Corona, P. Ecker, A. Glazov, Y. Han, M. Laurenza, T. Lueck, L. Massaccesi, S. Mondal, B. Scavino, S. Spataro, C. Wessel, L. Zani, End-to-End Multi-Track Reconstruction using Graph Neural Networks at Belle II (Nov. 2024). arXiv:2411.13596,doi:10.48550/arXiv.2411.13596
-
[12]
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet Classification with Deep Convolutional Neural Networks, in: Advances in Neural Information Processing Systems, Vol. 25, Curran Associates, Inc., 2012
work page 2012
-
[13]
Deep Learning Scaling is Predictable, Empirically
J. Hestness, S. Narang, N. Ardalani, G. Diamos, H. Jun, H. Kianinejad, M. M. A. Patwary, Y. Yang, Y. Zhou, Deep Learning Scaling is Predictable, Empirically (Dec. 2017).arXiv:1712.00409,doi: 10.48550/arXiv.1712.00409
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1712.00409 2017
-
[14]
I. Alabdulmohsin, B. Neyshabur, X. Zhai, Revisiting Neural Scaling Laws in Language and Vision (Nov. 2022).arXiv:2209.06640,doi:10.48550/arXiv.2209.06640
-
[15]
J. M. Ghawaly, A. D. Nicholson, D. E. Archer, M. J. Willis, I. Garishvili, B. Longmire, A. J. Rowe, I. R. Stewart, M. T. Cook, Characterization of the autoencoder radiation anomaly detection (arad) model, Engineering Applications of Artificial Intelligence 111 (2022) 104761.doi:10.1016/j.engappai.2022. 19 104761. URLhttps://www.sciencedirect.com/science/a...
-
[16]
M. S. Bandstra, J. C. Curtis, J. M. Ghawaly, Jr, A. C. Jones, T. H. Y. Joshi, Explaining machine- learning models for gamma-ray detection and identification, PLOS ONE 18 (6) (2023) 1–21.doi: 10.1371/journal.pone.0286829. URLhttps://doi.org/10.1371/journal.pone.0286829
-
[17]
K. J. Bilton, T. H. Y. Joshi, M. S. Bandstra, J. C. Curtis, D. Hellfeld, K. Vetter, Neural network approaches for mobile spectroscopic gamma-ray source detection, Journal of Nuclear Engineering 2 (2) (2021) 190–206.doi:10.3390/jne2020018. URLhttps://www.mdpi.com/2673-4362/2/2/18
-
[18]
A. Farahani, S. Voghoei, K. Rasheed, H. R. Arabnia, A Brief Review of Domain Adaptation (Oct. 2020). arXiv:2010.03978,doi:10.48550/arXiv.2010.03978
-
[19]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, in: Advances in Neural Information Processing Systems, Vol. 2017-Decem, Neural information processing systems foundation, 2017, pp. 5999–6009.arXiv:1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C.Berner, S.McCandlish, A.Radford, I.Sutskever, D.Amodei, Langu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2020
-
[21]
A. Radford, K. Narasimhan, T. Salimans, I. Sutskever, Improving Language Understanding by Gener- ative Pre-Training
-
[22]
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language Models are Unsupervised Multitask Learners
-
[23]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (May 2019).arXiv:1810.04805,doi:10.48550/arXiv.1810.04805
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805 2019
-
[24]
C. Ly, W. Frazier, A. Olsen, I. Schwerdt, L. W. McDonald, A. Hagen, Improving microstructures segmentation via pretraining with synthetic data, Computational Materials Science 249 (2025) 113639. doi:10.1016/j.commatsci.2024.113639
-
[25]
A. Jain, A. Montanari, E. Sasoglu, Scaling laws for learning with real and surrogate data, Advances in Neural Information Processing Systems 37 (2024) 110246–110289
work page 2024
-
[26]
J. G. Moreno-Torres, T. Raeder, R. Alaiz-Rodríguez, N. V. Chawla, F. Herrera, A unifying view on dataset shift in classification, Pattern Recognition 45 (1) (2012) 521–530.doi:https://doi.org/10. 1016/j.patcog.2011.06.019. URLhttps://www.sciencedirect.com/science/article/pii/S0031320311002901
work page 2012
-
[27]
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, N. D. Lawrence (Eds.), Dataset Shift in Machine Learning, MIT Press, Cambridge, MA, 2009
work page 2009
-
[28]
P.Olmos, J.Diaz, J.Perez, P.Gomez, V.Rodellar, P.Aguayo, A.Bru, G.Garcia-Belmonte, J.dePablos, A new approach to automatic radiation spectrum analysis, IEEE Transactions on Nuclear Science 38 (4) (1991) 971–975.doi:10.1109/23.83860
-
[29]
P. Olmos, J. Diaz, J. Perez, G. Garcia-Belmonte, P. Gomez, V. Rodellar, Application of neural network techniques in gamma spectroscopy, Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment 312 (1) (1992) 167–173.doi:https: 20 //doi.org/10.1016/0168-9002(92)90148-W. URLhttps://www.sc...
-
[30]
M. Kamuda, J. Zhao, K. Huff, A comparison of machine learning methods for automated gamma-ray spectroscopy, Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrom- eters, Detectors and Associated Equipment 954 (2020) 161385, symposium on Radiation Measurements and Applications XVII.doi:10.1016/j.nima.2018.10.063. URLhttps://...
-
[31]
D. Liang, P. Gong, X. Tang, P. Wang, L. Gao, Z. Wang, R. Zhang, Rapid nuclide identification algorithm based on convolutional neural network, Annals of Nuclear Energy 133 (2019) 483–490.doi:10.1016/ j.anucene.2019.05.051. URLhttps://www.sciencedirect.com/science/article/pii/S0306454919303044
work page 2019
- [32]
- [33]
-
[34]
G. Daniel, F. Ceraudo, O. Limousin, D. Maier, A. Meuris, Automatic and real-time identification of radionuclides in gamma-ray spectra: A new method based on convolutional neural network trained with synthetic data set, IEEE Transactions on Nuclear Science 67 (4) (2020) 644–653.doi:10.1109/TNS. 2020.2969703
work page doi:10.1109/tns 2020
-
[35]
N. Barradas, A. Vieira, M. Felizardo, M. Matos, Nuclide identification of radioactive sources from gamma spectra using artificial neural networks, Radiation Physics and Chemistry 232 (2025) 112692. doi:https://doi.org/10.1016/j.radphyschem.2025.112692. URLhttps://www.sciencedirect.com/science/article/pii/S0969806X25001847
-
[36]
F. Li, C.-Y. Luo, Y.-Z. Wen, S. Lv, F. Cheng, G.-Q. Zeng, J.-F. Jiang, B.-H. Li, A nuclide identification method ofγspectrum and model building based on the transformer, Nuclear Science and Techniques 36 (1) (2024) 7.doi:10.1007/s41365-024-01564-5. URLhttps://doi.org/10.1007/s41365-024-01564-5
-
[37]
doi:10.1016/j.anucene.2024.110777
A.VanOmen, T.Morrow, C.Scott, E.Leonard, Multilabelproportionpredictionandout-of-distribution detection on gamma spectra of short-lived fission products, Annals of Nuclear Energy 208 (2024) 110777. doi:10.1016/j.anucene.2024.110777. URLhttps://www.sciencedirect.com/science/article/pii/S0306454924004407
-
[38]
M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke...
work page 2015
-
[39]
Adversarial Discriminative Domain Adaptation
E. Tzeng, J. Hoffman, K. Saenko, T. Darrell, Adversarial discriminative domain adaptation (2017). arXiv:1702.05464. URLhttps://arxiv.org/abs/1702.05464 21
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
M. Long, Y. Cao, J. Wang, M. I. Jordan, Learning transferable features with deep adaptation networks (2015).arXiv:1502.02791. URLhttps://arxiv.org/abs/1502.02791
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[41]
Domain-Adversarial Training of Neural Networks
Y.Ganin, E.Ustinova, H.Ajakan, P.Germain, H.Larochelle, F.Laviolette, M.Marchand, V.Lempitsky, Domain-adversarial training of neural networks (2016).arXiv:1505.07818. URLhttps://arxiv.org/abs/1505.07818
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[42]
B. Sun, K. Saenko, Deep coral: Correlation alignment for deep domain adaptation (2016).arXiv: 1607.01719. URLhttps://arxiv.org/abs/1607.01719
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[43]
B. B. Damodaran, B. Kellenberger, R. Flamary, D. Tuia, N. Courty, Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation (2018).arXiv:1803.10081. URLhttps://arxiv.org/abs/1803.10081
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
A. Tarvainen, H. Valpola, Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results (2018).arXiv:1703.01780. URLhttps://arxiv.org/abs/1703.01780
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
J. Stomps, P. Wilson, K. Dayman, M. Willis, J. Ghawaly, D. Archer, Data augmentations for nuclear feature extraction in semi-supervised contrastive machine learning, in: Proceedings of the INMM/ESARDA Joint Annual Meeting 2023, Institute of Nuclear Materials Management (INMM), Vienna, Austria, 2023. URLhttps://resources.inmm.org/annual-meeting-proceedings...
work page 2023
-
[46]
T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations (2020).arXiv:2002.05709. URLhttps://arxiv.org/abs/2002.05709
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[47]
J. Allison, K. Amako, J. Apostolakis, P. Arce, M. Asai, T. Aso, E. Bagli, A. Bagulya, S. Banerjee, G. Barrand, B. Beck, A. Bogdanov, D. Brandt, J. Brown, H. Burkhardt, P. Canal, D. Cano-Ott, S. Chauvie, K. Cho, G. Cirrone, G. Cooperman, M. Cortés-Giraldo, G. Cosmo, G. Cuttone, G. De- paola, L. Desorgher, X. Dong, A. Dotti, V. Elvira, G. Folger, Z. Francis...
-
[48]
B. Archambault, B. Pierson, B. Loer, G4ares-geant4 advanced radio-emission simulation framework, available fromhttps://gitlab.pnnl.gov/ares/g4ares[accessed November 20, 2024] (2023)
work page 2024
-
[49]
B. D. Pierson, B. C. Archambault, L. R. Greenwood, M. M. Haney, M. G. Cantaloub, A. R. Hagen, S. M. Herman, N. E. Uhnak, J. M. Bowen, J. H. Estrada, Alpha/beta-gated gamma–gamma spectroscopy of mixed fission products for trace analysis, Journal of Radioanalytical and Nuclear Chemistry 331 (12) 22 (2022) 5453–5467.doi:10.1007/s10967-022-08606-5. URLhttps:/...
-
[50]
T. Morrow, N. Price, T. McGuire, Pyriid v.2.0.0, [Computer Software] (apr 2021).doi:10.11578/dc. 20221017.2. URLhttps://doi.org/10.11578/dc.20221017.2
work page doi:10.11578/dc 2021
-
[51]
S. M. Horne, G. G. Thoreson, L. A. Theisen, D. J. Mitchell, L. Harding, W. A. Amai, Gadras-drf 18.6 user’s manual (5 2016).doi:10.2172/1431293. URLhttps://www.osti.gov/biblio/1431293
-
[52]
T. Akiba, S. Sano, T. Yanase, T. Ohta, M. Koyama, Optuna: A next-generation hyperparameter opti- mization framework, in: Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, Association for Computing Machinery, New York, NY, USA, 2019, p. 2623–2631.doi:10.1145/3292500.3330701. URLhttps://doi.org/10.114...
-
[53]
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, J. Vaughan, A theory of learning from different domains, Machine Learning 79 (2010) 151–175.doi:10.1007/s10994-009-5152-4
-
[54]
A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Schölkopf, A. Smola, A kernel two-sample test, J. Mach. Learn. Res. 13 (null) (2012) 723–773
work page 2012
-
[55]
G. Peyré, M. Cuturi, Computational optimal transport, Found. Trends Mach. Learn. 11 (5–6) (2019) 355–607.doi:10.1561/2200000073. URLhttps://doi.org/10.1561/2200000073
-
[56]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, J. Melville, Umap: Uniform manifold approximation and projection for dimension reduction (2020).arXiv:1802.03426. URLhttps://arxiv.org/abs/1802.03426
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[57]
K. P. Murphy, Machine learning: a probabilistic perspective, MIT press, 2012
work page 2012
-
[58]
W. B. Glenn, et al., Verification of forecasts expressed in terms of probability, Monthly weather review 78 (1) (1950) 1–3
work page 1950
- [59]
-
[60]
P. Bartlett, Y. Freund, W. S. Lee, R. E. Schapire, Boosting the margin: A new explanation for the effectiveness of voting methods, The annals of statistics 26 (5) (1998) 1651–1686
work page 1998
-
[61]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
D. Hendrycks, K. Gimpel, A baseline for detecting misclassified and out-of-distribution examples in neural networks (2018).arXiv:1610.02136. URLhttps://arxiv.org/abs/1610.02136
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and harnessing adversarial examples, arXiv preprint arXiv:1412.6572 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [63]
-
[64]
X. Zhu, Z. Ghahramani, J. D. Lafferty, Semi-supervised learning using gaussian fields and harmonic functions, in: Proceedings of the 20th International conference on Machine learning (ICML-03), 2003, pp. 912–919
work page 2003
-
[65]
C. E. Shannon, A mathematical theory of communication, The Bell system technical journal 27 (3) (1948) 379–423. 23
work page 1948
-
[66]
S. M. Lundberg, S.-I. Lee, A unified approach to interpreting model predictions, Curran Associates, Inc., 2017. URLhttp://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions. pdf
work page 2017
-
[67]
J. Bergstra, R. Bardenet, Y. Bengio, B. Kégl, Algorithms for hyper-parameter optimization, in: Ad- vances in Neural Information Processing Systems 24, 2011, pp. 2546–2554. 24 Appendix A. Supplementary Materials Appendix A.1. Hyperparameter optimization Throughout the following tables, search spaces are annotated as follows:[a, b]denotes continuous uni- fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.