Recognition: no theorem link
Graph Property Inference in Small Language Models: Effects of Representation and Reasoning Strategy
Pith reviewed 2026-05-15 20:04 UTC · model grok-4.3
The pith
Small instruction-tuned language models cannot reliably estimate graph-theoretic properties from textual encodings, though adjacency-list formats and multi-branch reasoning reduce errors relative to edge lists and single-path inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
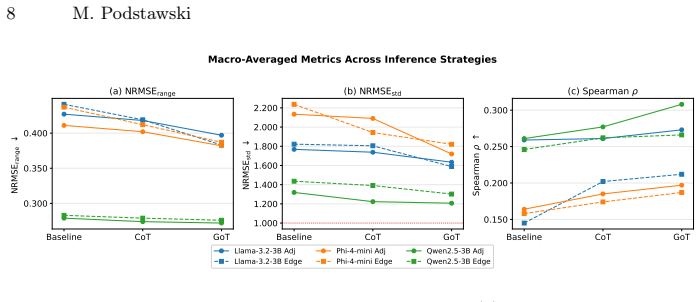
small language models fail to achieve reliable graph property estimation: normalized errors consistently exceed the intrinsic dispersion of target properties, and rank correlations remain weak across all configurations. However, the failure is structured rather than uniform. Adjacency-list encodings consistently reduce error and improve ordinal consistency relative to edge-lists, and multi-branch reasoning yields measurable aggregate gains across configurations.
Load-bearing premise
The tested models, graph properties, and textual encodings are representative of the broader space of small language models and structured reasoning tasks; the observed patterns would hold under different model families or property definitions.
Figures

read the original abstract
Recent progress in language modeling has expanded the range of tasks that can be approached through natural language interfaces, including problems that require structured reasoning. However, it remains unclear how effectively limited-capacity language models can infer formal properties of relational structures when those structures are presented in textual form. We conduct a systematic study of graph-theoretic property inference in small instruction-tuned language models, isolating the roles of input representation and reasoning strategy. Across a diverse set of local and global graph metrics evaluated on three models, we find that small language models fail to achieve reliable graph property estimation: normalized errors consistently exceed the intrinsic dispersion of target properties, and rank correlations remain weak across all configurations. However, the failure is structured rather than uniform. Adjacency-list encodings consistently reduce error and improve ordinal consistency relative to edge-lists, and multi-branch reasoning yields measurable aggregate gains across configurations. These results show that without task-specific fine-tuning or architectural adaptation, graph property inference in pretrained small language models remains fundamentally unreliable, but that representational organization and inference design produce consistent differences. The findings characterize the conditions under which structured inference degrades and identify which design choices yield improvements even under constrained model capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a systematic empirical evaluation of graph property inference in three small instruction-tuned language models. It isolates the effects of textual graph encodings (adjacency-list versus edge-list) and reasoning strategies (single-step versus multi-branch), measuring performance via normalized error and rank correlation on a set of local and global graph metrics. The central claim is that these models exhibit fundamentally unreliable inference—normalized errors exceed intrinsic property dispersion and rank correlations remain weak—yet the unreliability is structured, with adjacency-list encodings and multi-branch reasoning yielding consistent aggregate improvements.
Significance. If the reported error and correlation patterns hold under the tested conditions, the work provides concrete evidence that small pretrained language models lack reliable capacity for structured graph reasoning without task-specific adaptation. By quantifying the benefits of specific representational and procedural choices, it supplies actionable guidance for prompt and interface design in capacity-constrained settings and highlights the gap between natural-language interfaces and formal graph tasks.
major comments (2)
- [Abstract] Abstract and concluding section: the assertion that graph property inference 'remains fundamentally unreliable' for pretrained small language models generalizes beyond the three evaluated models and the chosen local/global metrics. The manuscript should either qualify the scope explicitly to the tested configurations or provide additional cross-family validation to support the broader claim.
- [Results] Results section (error and correlation tables): the claim that normalized errors consistently exceed intrinsic dispersion is load-bearing for the unreliability conclusion, yet the exact normalization procedure, property-specific dispersion calculation, and handling of graph-size variation are not fully detailed; a sensitivity check across alternative normalizations would strengthen the result.
minor comments (2)
- [Methods] The description of multi-branch reasoning would benefit from an explicit algorithmic outline or pseudocode to clarify branching criteria and aggregation method.
- [Figures] Figure captions should state the number of graphs, property definitions, and exact model sizes used in each panel to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to improve clarity and precision.
read point-by-point responses
-
Referee: [Abstract] Abstract and concluding section: the assertion that graph property inference 'remains fundamentally unreliable' for pretrained small language models generalizes beyond the three evaluated models and the chosen local/global metrics. The manuscript should either qualify the scope explicitly to the tested configurations or provide additional cross-family validation to support the broader claim.
Authors: We agree that the phrasing risks over-generalization. In the revised manuscript we have explicitly qualified the abstract and conclusion to the three evaluated models (Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.2, Gemma-2-9B-it) and the specific local and global metrics tested. We now state that the observed unreliability holds under these tested conditions and note that broader validation across model families remains an important direction for future work. revision: yes
-
Referee: [Results] Results section (error and correlation tables): the claim that normalized errors consistently exceed intrinsic dispersion is load-bearing for the unreliability conclusion, yet the exact normalization procedure, property-specific dispersion calculation, and handling of graph-size variation are not fully detailed; a sensitivity check across alternative normalizations would strengthen the result.
Authors: We appreciate the request for greater methodological transparency. The primary normalization divides absolute error by the standard deviation of each property across the full graph corpus; dispersion is computed identically per property. Graph-size effects are handled by reporting results in three size-stratified bins (small/medium/large). In the revision we have added a dedicated subsection in Methods that fully specifies these steps. We have also included a sensitivity analysis in the appendix that repeats the key comparisons under min-max and interquartile-range normalizations; the central finding that normalized errors exceed dispersion remains consistent. revision: yes
Circularity Check
No circularity: purely empirical measurements with direct performance comparisons
full rationale
The paper reports an empirical study that measures normalized errors and rank correlations for graph property inference across fixed model configurations, input encodings (adjacency-list vs edge-list), and reasoning strategies (multi-branch). All claims rest on experimental deltas between these configurations rather than any derivation, fitted parameter, or self-citation chain. No equations, ansatzes, or uniqueness theorems appear; the central finding that errors exceed intrinsic dispersion is a direct observational result, not a reduction to inputs by construction. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in LLM benchmarking that the chosen models and metrics are representative and that textual graph encodings preserve the underlying structure
Reference graph
Works this paper leans on
-
[1]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. Graph Property Inference in Small Language Models 11 In: Advances in Neural Information Processing Systems (NeurIPS), pp. 24824–24837 (2022)
work page 2022
-
[2]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
Besta, M., Blach, N., Kubicek, A., Gerstenberger, R., Podstawski, M., Gianinazzi, L., Gajda, J., Lehmann, T., Niewiadomski, H., Nyczyk, P., Hoefler, T.: Graph of thoughts: Solving elaborate problems with large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
work page 2024
-
[3]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 22199–22213 (2022)
work page 2022
-
[4]
In: International Conference on Learning Representations (ICLR) (2023)
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. In: International Conference on Learning Representations (ICLR) (2023)
work page 2023
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., Schulman, J.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Srivastava, A., Rastogi, A., Rao, A., et al.: Beyond the imitation game: Quan- tifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2024)
Ren,X.,Tang,J.,Yin,D.,Chawla,N.,Huang,C.:ASurveyofLargeLanguageMod- els for Graphs. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2024)
work page 2024
-
[8]
arXiv preprint arXiv:2507.03637 (2025)
Da Ros, F., Soprano, M., Di Gaspero, L., Roitero, K.: Large language models for combinatorial optimization: A systematic review. arXiv preprint arXiv:2507.03637 (2025)
-
[9]
In: International Conference on Learning Representations (ICLR) (2025)
Dai, X., Qu, H., Shen, Y., Zhang, B., Wen, Q., Fan, W., Li, D., Tang, J., Shan, C.: How do large language models understand graph patterns? A benchmark for graph pattern comprehension. In: International Conference on Learning Representations (ICLR) (2025)
work page 2025
-
[10]
In: International Conference on Learning Representations (ICLR) (2024)
Zhou, H., Bradley, A., Littwin, E., Razin, N., Saremi, O., Susskind, J., Bengio, S., Nakkiran, P.: What algorithms can transformers learn? A study in length general- ization. In: International Conference on Learning Representations (ICLR) (2024)
work page 2024
-
[11]
arXiv preprint arXiv:2510.08808 (2025)
Podstawski, M.: TinyGraphEstimator: Adapting lightweight language models for graph structure inference. arXiv preprint arXiv:2510.08808 (2025)
-
[12]
Generalization Boundaries of Fine-Tuned Small Language Models for Graph Structural Inference
Podstawski, M.: Generalization Boundaries of Fine-Tuned Small Language Models for Graph Structural Inference. arXiv preprint arXiv:2604.18092 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
In: Advances in Neural Information Processing Systems (NeurIPS), vol
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS), vol. 30 (2017)
work page 2017
-
[14]
arXiv preprint arXiv:1901.00596 (2019)
Wu, Z., Pan, S., Chen, F., Long, G., Zhang, C., Yu, P.S.: A comprehensive survey on graph neural networks. arXiv preprint arXiv:1901.00596 (2019)
-
[15]
Xu, K., Hu, W., Leskovec, J., Jegelka, S.: How powerful are graph neural networks? arXiv preprint arXiv:1810.00826 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [16]
-
[17]
Fatemi, B., Halcrow, J., Perozzi, B.: Talk like a Graph: Encoding Graphs for Large LanguageModels.In:InternationalConferenceonLearningRepresentations(ICLR) (2024)
work page 2024
-
[18]
Available at: https://llm- stats.com/leaderboards/llm-leaderboard (Accessed: February 2026) 12 M
llm-stats.com: LLM Leaderboard. Available at: https://llm- stats.com/leaderboards/llm-leaderboard (Accessed: February 2026) 12 M. Podstawski
work page 2026
-
[19]
Available at: https://github.com/noamgat/lm-format-enforcer (Accessed: April 2026)
lm-format-enforcer. Available at: https://github.com/noamgat/lm-format-enforcer (Accessed: April 2026)
work page 2026
-
[20]
Llama Team: The Llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Qwen Team: Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Phi Team: Phi-4 Technical Report. arXiv preprint arXiv:2412.08905 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Available at: https://www.anthropic.com/claude (Accessed: April 2026)
Anthropic, Claude. Available at: https://www.anthropic.com/claude (Accessed: April 2026)
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.