Recognition: 2 theorem links
· Lean TheoremC²FG: Control Classifier-Free Guidance via Score Discrepancy Analysis
Pith reviewed 2026-05-15 14:57 UTC · model grok-4.3
The pith
Upper bounds on score discrepancy between conditional and unconditional distributions justify replacing fixed guidance weights with time-dependent control in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
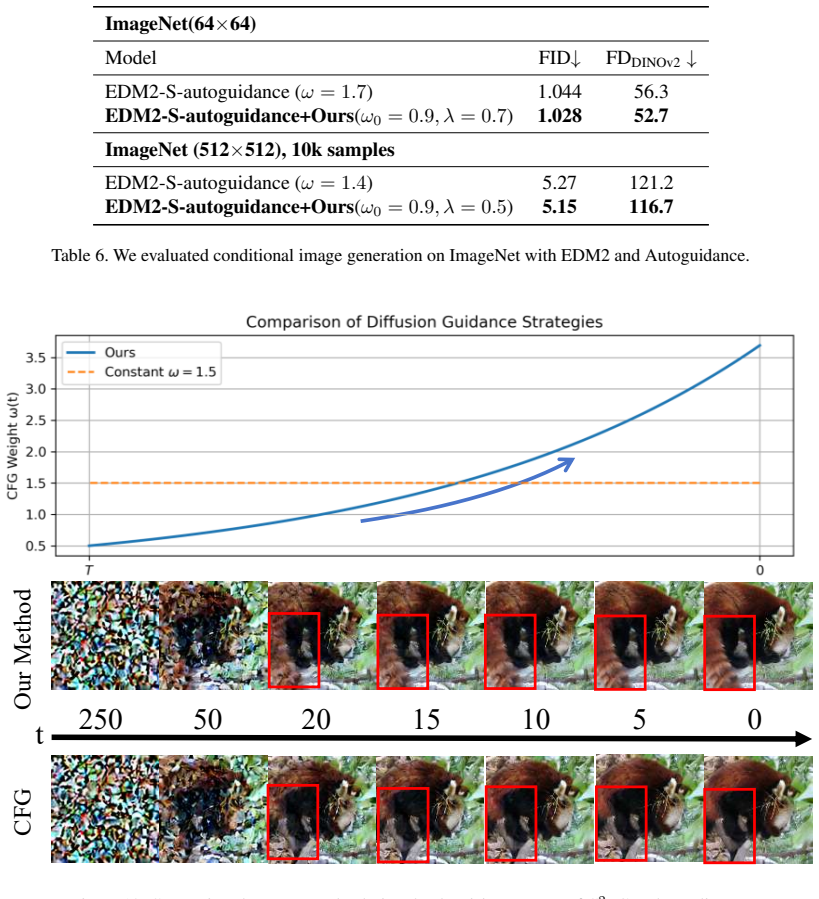
By establishing strict upper bounds on the score discrepancy between conditional and unconditional distributions at different timesteps based on the diffusion process, the paper demonstrates the limitations of fixed-weight Classifier-Free Guidance and introduces C²FG, a training-free method that applies an exponential decay control function to align guidance strength with the natural dynamics of the diffusion trajectory.
What carries the argument
The timestep-dependent upper bound on score discrepancy between conditional and unconditional score functions, which the exponential decay control function is constructed to respect.
If this is right
- Fixed guidance weights necessarily under- or over-correct at some timesteps because the allowable discrepancy shrinks as the process runs.
- Guidance strength can be scheduled once from the diffusion mathematics rather than tuned by trial and error for each new task.
- C²FG can be added to any existing conditional diffusion pipeline without changing model weights or training.
- The same discrepancy analysis supplies a concrete criterion for choosing or validating other dynamic guidance schedules.
Where Pith is reading between the lines
- The same bounding technique could be applied to other score-based samplers to derive schedules for noise levels or step sizes.
- If the bounds prove tight in practice, they could serve as a stopping criterion for early termination of the sampling loop.
- Task-specific fine-tuning of the decay rate may still be needed in domains where the diffusion process deviates strongly from the assumed forward process.
Load-bearing premise
The exponential decay schedule is assumed to be the right shape for staying within the derived discrepancy bounds across timesteps and tasks without needing per-task adjustment.
What would settle it
A direct comparison in which a linear or constant control function is substituted for the exponential decay on the same models and datasets, with the result that the non-exponential version produces higher-quality samples.
Figures










read the original abstract
Classifier-Free Guidance (CFG) is a cornerstone of modern conditional diffusion models, yet its reliance on the fixed or heuristic dynamic guidance weight is predominantly empirical and overlooks the inherent dynamics of the diffusion process. In this paper, we provide a rigorous theoretical analysis of the Classifier-Free Guidance. Specifically, we establish strict upper bounds on the score discrepancy between conditional and unconditional distributions at different timesteps based on the diffusion process. This finding explains the limitations of fixed-weight strategies and establishes a principled foundation for time-dependent guidance. Motivated by this insight, we introduce \textbf{Control Classifier-Free Guidance (C$^2$FG)}, a novel, training-free, and plug-in method that aligns the guidance strength with the diffusion dynamics via an exponential decay control function. Extensive experiments demonstrate that C$^2$FG is effective and broadly applicable across diverse generative tasks, while also exhibiting orthogonality to existing strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to derive strict upper bounds on the score discrepancy between conditional and unconditional distributions at different timesteps from the diffusion SDE. These bounds are said to explain the limitations of fixed-weight CFG and to provide a principled basis for time-dependent guidance. Motivated by this analysis, the authors introduce C²FG, a training-free plug-in method that uses an exponential decay control function to modulate guidance strength, and report that it is effective and orthogonal to existing strategies across diverse generative tasks.
Significance. If the upper bounds are rigorously derived and the exponential decay schedule is shown to follow directly from them, the work would supply a theoretical foundation for improving CFG, a widely used technique. The training-free character and claimed orthogonality are practical strengths. However, the absence of an explicit derivation linking the bound expression to the specific functional form of the control function weakens the claimed motivation and reduces the potential impact.
major comments (1)
- [Abstract and §4] Abstract and §4 (method): the exponential decay control function is presented as motivated by the derived upper bounds on score discrepancy, yet no derivation is supplied showing that this form saturates the bound, is obtained by setting the guidance weight equal to the bound at each t, or is optimal among functions consistent with the bound; the alignment is asserted rather than proven from the bound expression itself.
minor comments (2)
- [Abstract] The explicit mathematical form of the upper bound on score discrepancy should be stated in the abstract or early in the introduction to allow readers to assess the claimed motivation without reading the full derivation.
- [Experiments] The single free parameter (exponential decay rate) is introduced without discussion of how its value is chosen or whether it requires task-specific tuning, which should be clarified in the experimental section.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. The primary concern identified is the lack of an explicit derivation connecting the derived upper bounds on score discrepancy to the specific exponential decay form of the control function in C²FG. We address this comment below and commit to strengthening the presentation in the revised version.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (method): the exponential decay control function is presented as motivated by the derived upper bounds on score discrepancy, yet no derivation is supplied showing that this form saturates the bound, is obtained by setting the guidance weight equal to the bound at each t, or is optimal among functions consistent with the bound; the alignment is asserted rather than proven from the bound expression itself.
Authors: We agree that the manuscript presents the exponential decay as motivated by the bounds without supplying a fully explicit derivation of why this particular functional form follows from the bound expression. The upper bounds derived from the diffusion SDE show that the conditional-unconditional score discrepancy decays exponentially in t. In the revised manuscript we will add a dedicated paragraph (and supporting derivation) in §4 that (i) recalls the exact bound expression, (ii) shows that setting the guidance weight w(t) proportional to the bound at each t yields an exponential decay schedule, and (iii) briefly argues that this choice saturates the bound while remaining simple and training-free. This will convert the current motivational statement into a direct, step-by-step link between the bound and the control function. revision: yes
Circularity Check
No significant circularity; bounds derived from diffusion SDE and control function motivated independently
full rationale
The paper derives strict upper bounds on conditional-unconditional score discrepancy directly from the diffusion process SDE, which constitutes an independent first-principles analysis. The C²FG method adopts an exponential decay control function motivated by these bounds, but the provided text presents this as an alignment choice rather than a quantity obtained by construction, fitting, or reduction to the bound expression itself. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claims remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponential decay rate
axioms (1)
- domain assumption Diffusion forward and reverse processes admit well-defined score functions whose conditional-unconditional discrepancy admits strict upper bounds at each timestep.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; dAlembert_to_ODE_general echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theorem 1 (VP-SDE Score MSE Bound) ... ∥∇logp(x,t)−∇log˜p(x,t)∥ ≤ α(t)/σ²(t) C ... reparameterize t′=½∫βs ds ... O(e^{-t'}) decay rate
-
IndisputableMonolith/Foundation/ArrowOfTime.leanforward_accumulates; z_monotone_absolute echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
ω(t) = ω₀ exp(λ(1-t/t_max)) ... aligns the guidance strength with the diffusion dynamics via an exponential decay control function
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
P-Guide: Parameter-Efficient Prior Steering for Single-Pass CFG Inference
P-Guide achieves single-pass classifier-free guidance in flow matching by modulating the initial latent state and is equivalent to standard CFG under a first-order approximation while cutting latency by half.
Reference graph
Works this paper leans on
-
[1]
FD-DINOv2: FD Score via DINOv2.https: //github.com/justin4ai/FD-DINOv2 , 2024
Junyeong Ahn. FD-DINOv2: FD Score via DINOv2.https: //github.com/justin4ai/FD-DINOv2 , 2024. Ver- sion 0.1.0. 28
work page 2024
- [2]
-
[3]
Diffusions hypercon- tractives
Dominique Bakry and Michel Émery. Diffusions hypercon- tractives. InSéminaire de Probabilités XIX 1983/84: Proceed- ings, pages 177–206. Springer, 2006. 14, 19
work page 1983
-
[4]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Yogesh Balaji, Seungjun Nah, Xun Huang, Arash Vahdat, Jiaming Song, Qinsheng Zhang, Karsten Kreis, Miika Ait- tala, Timo Aila, Samuli Laine, et al. ediff-i: Text-to-image diffusion models with an ensemble of expert denoisers.arXiv preprint arXiv:2211.01324, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. InCVPR, 2023. 2, 6, 7
work page 2023
-
[6]
Arwen Bradley and Preetum Nakkiran. Classifier-free guid- ance is a predictor-corrector.Transactions on Machine Learn- ing Research, 2025. 3, 12
work page 2025
-
[7]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the International Conference on Computer Vision (ICCV), 2021. 6
work page 2021
-
[8]
Diffier: Optimizing diffusion models with iterative error reduction, 2025
Ao Chen, Lihe Ding, and Tianfan Xue. Diffier: Optimizing diffusion models with iterative error reduction, 2025. 11
work page 2025
-
[9]
S 2-guidance: Stochastic self guidance for training-free enhancement of diffusion models, 2025
Chubin Chen, Jiashu Zhu, Xiaokun Feng, Nisha Huang, Meiqi Wu, Fangyuan Mao, Jiahong Wu, Xiangxiang Chu, and Xiu Li. S 2-guidance: Stochastic self guidance for training-free enhancement of diffusion models, 2025. 3, 12
work page 2025
-
[10]
CFG++: Manifold-constrained clas- sifier free guidance for diffusion models
Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. CFG++: Manifold-constrained clas- sifier free guidance for diffusion models. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 11, 29
work page 2025
-
[11]
Danilo de Oliveira, Julius Richter, Tal Peer, and Timo Gerk- mann. Lipdiffuser: Lip-to-speech generation with conditional diffusion models.arXiv preprint arXiv:2505.11391, 2025. 1
-
[12]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 6
work page 2009
-
[13]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis.ArXiv, abs/2105.05233, 2021. 1, 2, 11
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
M. D. Donsker and S. R. S. Varadhan. Asymptotic evaluation of certain markov process expectations for large time, i.Com- munications on Pure and Applied Mathematics, 28(1):1–47,
-
[15]
Scaling rectified flow transformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024. 29
work page 2024
-
[16]
Evans.Partial Differential Equations
L.C. Evans.Partial Differential Equations. American Mathe- matical Society, 1998. 14
work page 1998
-
[17]
Crispin W Gardiner. Handbook of stochastic methods for physics, chemistry and the natural sciences.Springer series in synergetics, 1985. 2
work page 1985
-
[18]
Masked Autoencoders Are Scalable Vision Learners,
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners.arXiv:2111.06377, 2021. 6
-
[19]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017. 6
work page 2017
-
[20]
Classifier-Free Diffusion Guidance
Jonathan Ho. Classifier-free diffusion guidance.ArXiv, abs/2207.12598, 2022. 1, 3, 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Jonathan Ho, Ajay Jain, and P. Abbeel. Denoising diffusion probabilistic models.ArXiv, abs/2006.11239, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[22]
Stage-wise dynamics of classifier-free guidance in diffusion models, 2025
Cheng Jin, Qitan Shi, and Yuantao Gu. Stage-wise dynamics of classifier-free guidance in diffusion models, 2025. 3, 12
work page 2025
-
[23]
Guiding a diffusion model with a bad version of itself
Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. InProc. NeurIPS, 2024. 2, 7, 28
work page 2024
-
[24]
Analyzing and improving the training dynamics of diffusion models
Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. InProc. CVPR, 2024. 2, 6, 7, 28
work page 2024
-
[25]
Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32, 2019. 6
work page 2019
-
[26]
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models.Advances in Neural Information Processing Systems, 37:122458–122483, 2024. 1, 2, 3, 5, 6, 11, 12
work page 2024
-
[27]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space, 2025
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Fred- eric Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context imag...
work page 2025
-
[28]
Com- mon diffusion noise schedules and sample steps are flawed
Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Com- mon diffusion noise schedules and sample steps are flawed. InProceedings of the IEEE/CVF winter conference on appli- cations of computer vision, pages 5404–5411, 2024. 11
work page 2024
-
[29]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 6
work page 2014
-
[30]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maxi- milian Nickel, and Matt Le. Flow matching for generative modeling.ArXiv, abs/2210.02747, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Rectified flow: A marginal preserving approach to optimal transport.ArXiv, abs/2209.14577, 2022
Qiang Liu. Rectified flow: A marginal preserving approach to optimal transport.ArXiv, abs/2209.14577, 2022
-
[32]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.ArXiv, abs/2209.03003, 2022. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable in- terpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024. 2, 6
work page 2024
-
[34]
Classifier-free guidance with adap- tive scaling.arXiv preprint arXiv:2502.10574, 2025
Dawid Malarz, Artur Kasymov, Maciej Zi˛ eba, Jacek Tabor, and Przemysław Spurek. Classifier-free guidance with adap- tive scaling.arXiv preprint arXiv:2502.10574, 2025. 1, 6, 11, 27, 29
-
[35]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.arXiv preprint arXiv:2212.09748, 2022. 2, 6, 26
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Ge- oguide: Geometric guidance of diffusion models
Mateusz Poleski, Jacek Tabor, and Przemysław Spurek. Ge- oguide: Geometric guidance of diffusion models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 297–305. IEEE, 2025. 11
work page 2025
-
[37]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image genera- tion with clip latents.arXiv preprint arXiv:2204.06125, 1(2): 3, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 2, 6, 7, 29
work page 2022
-
[39]
Seyedmorteza Sadat, Manuel Kansy, Otmar Hilliges, and Romann M. Weber. No training, no problem: Rethinking classifier-free guidance for diffusion models, 2025. 3, 12
work page 2025
- [40]
-
[41]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 6
work page 2016
-
[42]
Rethinking the spatial inconsistency in classifier- free diffusion guidance
Dazhong Shen, Guanglu Song, Zeyue Xue, Fu-Yun Wang, and Yu Liu. Rethinking the spatial inconsistency in classifier- free diffusion guidance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9370–9379, 2024. 11
work page 2024
-
[43]
Information theoretic learning for diffusion models with warm start
Yirong Shen, Lu GAN, and Cong Ling. Information theoretic learning for diffusion models with warm start. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. 1
work page 2025
-
[44]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Jascha Narain Sohl-Dickstein, Eric A. Weiss, Niru Ma- heswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics.ArXiv, abs/1503.03585, 2015. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[45]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.ArXiv, abs/2010.02502, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[46]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InNeural Infor- mation Processing Systems, 2019
work page 2019
-
[47]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Narain Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differ- ential equations.ArXiv, abs/2011.13456, 2020. 1, 2, 3, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[48]
Philipp Vaeth, Alexander M Fruehwald, Benjamin Paassen, and Magda Gregorova. Gradcheck: Analyzing classifier guid- ance gradients for conditional diffusion sampling.arXiv preprint arXiv:2406.17399, 2024. 1
-
[49]
Fu-Yun Wang, Ling Yang, Zhaoyang Huang, Mengdi Wang, and Hongsheng Li. Rectified diffusion: Straightness is not your need in rectified flow.arXiv preprint arXiv:2410.07303,
-
[50]
Fu-Yun Wang, Yunhao Shui, Jingtan Piao, Keqiang Sun, and Hongsheng Li. Diffusion-npo: Negative preference optimiza- tion for better preference aligned generation of diffusion mod- els.arXiv preprint arXiv:2505.11245, 2025. 11
-
[51]
Analysis of classifier-free guidance weight schedulers
Xi Wang, Nicolas Dufour, Nefeli Andreou, Marie-Paule Cani, Victoria Fernández Abrevaya, David Picard, and Vicky Kalo- geiton. Analysis of classifier-free guidance weight schedulers. arXiv preprint arXiv:2404.13040, 2024. 3, 11, 26
-
[52]
Harmonyview: Harmonizing consis- tency and diversity in one-image-to-3d
Sangmin Woo, Byeongjun Park, Hyojun Go, Jin-Young Kim, and Changick Kim. Harmonyview: Harmonizing consis- tency and diversity in one-image-to-3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10574–10584, 2024. 1
work page 2024
-
[53]
Zhen Yang, Guibao Shen, Minyang Li, Liang Hou, Mushui Liu, Luozhou Wang, Xin Tao, Pengfei Wan, Di Zhang, and Ying-Cong Chen. Efficient training-free high-resolution syn- thesis with energy rectification in diffusion models, 2025. 12
work page 2025
-
[54]
Tfg: Unified training-free guidance for diffusion models
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models. 2024. 1, 12
work page 2024
-
[55]
Representa- tion alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representa- tion alignment for generation: Training diffusion transformers is easier than you think. InInternational Conference on Learning Representations, 2025. 6, 29
work page 2025
-
[56]
Tianyi Zheng, Jiayang Zou, Peng-Tao Jiang, Hao Zhang, Jin- wei Chen, Jia Wang, and Bo Li. Bidirectional beta-tuned diffusion model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(1):359–373, 2026. 1
work page 2026
-
[57]
Shangwen Zhu, Qianyu Peng, Yuting Hu, Zhantao Yang, Han Zhang, Zhao Pu, Ruili Feng, and Fan Cheng. Raag: Ratio aware adaptive guidance, 2025. 1, 3, 12, 27 Appendix Overview This appendix provides additional details and supplementary results to support the main paper. In Section A, we review related literature to place our work in a broader context. Sectio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.