Recognition: 2 theorem links
· Lean TheoremIntrinsic Concept Extraction Based on Compositional Interpretability
Pith reviewed 2026-05-15 12:12 UTC · model grok-4.3
The pith
HyperExpress extracts composable object and attribute concepts from one image using hyperbolic disentanglement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
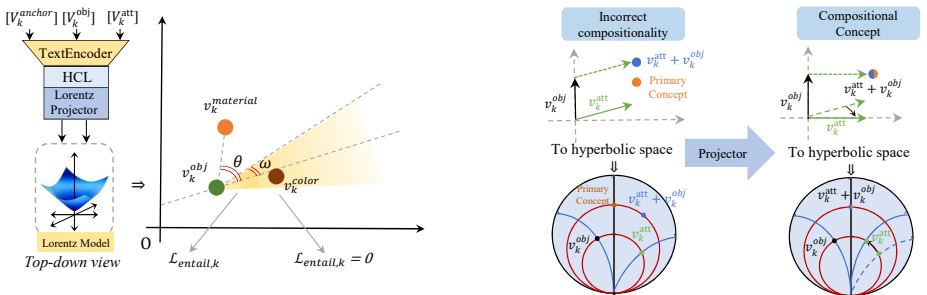
We propose HyperExpress to solve the CI-ICE task by leveraging hyperbolic space's hierarchical modeling capability for accurate concept disentanglement that preserves relational dependencies, together with a concept-wise optimization step that maps the embedding space to maintain inter-concept relationships while ensuring the concepts remain composable, thereby allowing reconstruction of the original image from their combination.
What carries the argument
Hyperbolic concept disentanglement, which models concepts in hyperbolic space to capture hierarchy and dependencies, paired with concept-wise optimization to ensure composability.
If this is right
- Extracted concepts can be recombined to reconstruct the input image with high fidelity.
- The method simultaneously handles object-level and attribute-level concepts from one image.
- Relational dependencies among concepts are preserved during the disentanglement process.
- The extraction requires no additional labeled data or multiple example images.
Where Pith is reading between the lines
- The extracted concepts could support targeted image editing by swapping or modifying single parts while leaving others unchanged.
- The same hyperbolic optimization approach might extend to other generative models to improve their interpretability.
- Collections of such concepts could serve as reusable visual primitives for building new images from everyday photos.
Load-bearing premise
Diffusion-based text-to-image models already contain accurate, disentangled concepts that can be isolated and recombined through hyperbolic mapping and optimization without further supervision.
What would settle it
A test where the extracted concepts are recombined in the diffusion model and the output image differs substantially from the input in layout, objects, or attributes.
Figures



read the original abstract
Unsupervised Concept Extraction aims to extract concepts from a single image; however, existing methods suffer from the inability to extract composable intrinsic concepts. To address this, this paper introduces a new task called Compositional and Interpretable Intrinsic Concept Extraction (CI-ICE). The CI-ICE task aims to leverage diffusion-based text-to-image models to extract composable object-level and attribute-level concepts from a single image, such that the original concept can be reconstructed through the combination of these concepts. To achieve this goal, we propose a method called HyperExpress, which addresses the CI-ICE task through two core aspects. Specifically, first, we propose a concept learning approach that leverages the inherent hierarchical modeling capability of hyperbolic space to achieve accurate concept disentanglement while preserving the hierarchical structure and relational dependencies among concepts; second, we introduce a concept-wise optimization method that maps the concept embedding space to maintain complex inter-concept relationships while ensuring concept composability. Our method demonstrates outstanding performance in extracting compositionally interpretable intrinsic concepts from a single image.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Compositional and Interpretable Intrinsic Concept Extraction (CI-ICE) task for unsupervised extraction of composable object-level and attribute-level concepts from a single image. It proposes the HyperExpress method, which uses hyperbolic geometry to model hierarchical concept structures and disentangle concepts while a concept-wise optimization maps embeddings to preserve inter-concept relationships and enable reconstruction of the original image semantics via linear or compositional recombination. The abstract asserts that the approach demonstrates outstanding performance.
Significance. If the central claims are validated, the work could advance unsupervised concept learning in computer vision by providing a framework for extracting reusable, hierarchically structured concepts directly from single images via diffusion models. The integration of hyperbolic embeddings for relational dependencies offers a potentially useful inductive bias for compositional interpretability. However, the absence of any quantitative results means the significance cannot yet be assessed beyond the conceptual level.
major comments (2)
- [Abstract] Abstract: the claim of 'outstanding performance' is unsupported because no quantitative metrics (PSNR, CLIP similarity, reconstruction error, composability scores, or human interpretability ratings), baselines, or experimental protocol are reported, rendering the central claim unverifiable.
- [Method] Method description: no equations are supplied for the hyperbolic embedding loss, the concept-wise optimization objective, or any regularizers (reconstruction, orthogonality, hierarchy), so it is impossible to check whether the optimization actually enforces composability or collapses to trivial solutions.
minor comments (1)
- [Title/Abstract] The title refers to 'Intrinsic Concept Extraction Based on Compositional Interpretability' while the abstract defines the task as CI-ICE; align the terminology for consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the current version lacks sufficient quantitative evidence and explicit mathematical details to fully substantiate the claims. We will revise the paper accordingly by adding experiments and equations.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'outstanding performance' is unsupported because no quantitative metrics (PSNR, CLIP similarity, reconstruction error, composability scores, or human interpretability ratings), baselines, or experimental protocol are reported, rendering the central claim unverifiable.
Authors: We acknowledge that the abstract's claim of 'outstanding performance' is not supported by quantitative results in the current manuscript. In the revised version, we will add a comprehensive experimental section reporting metrics such as PSNR, CLIP similarity, reconstruction error, and composability scores, along with baselines and a detailed experimental protocol. The abstract will be updated to reflect these results rather than asserting outstanding performance without evidence. revision: yes
-
Referee: [Method] Method description: no equations are supplied for the hyperbolic embedding loss, the concept-wise optimization objective, or any regularizers (reconstruction, orthogonality, hierarchy), so it is impossible to check whether the optimization actually enforces composability or collapses to trivial solutions.
Authors: We agree that the absence of explicit equations makes it difficult to verify the optimization details. The revised manuscript will include the full mathematical formulations for the hyperbolic embedding loss, the concept-wise optimization objective, and all regularizers (including reconstruction, orthogonality, and hierarchy terms). These additions will clarify how the objectives enforce composability and prevent collapse to trivial solutions. revision: yes
Circularity Check
No circularity: method claims rest on proposed hyperbolic disentanglement and optimization without reduction to fitted inputs or self-citations
full rationale
The provided abstract and description introduce the CI-ICE task and HyperExpress method via two components (hyperbolic hierarchical modeling for disentanglement and concept-wise optimization for composability), but contain no equations, loss definitions, or self-citations that reduce any prediction or result to the inputs by construction. No self-definitional loops, fitted parameters called predictions, or load-bearing uniqueness theorems from prior author work are visible. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hyperbolic space possesses inherent hierarchical modeling capability suitable for concept disentanglement
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost definition via reciprocal echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
hyperbolic distance dD(x,y) = cosh⁻¹(1 + 2∥x−y∥² / ((1−∥x∥²)(1−∥y∥²))) ... entailment cone ... horosphere projection πH ... isometry dH(π(x),π(y)) = dH(x,y)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt; LogicNat orbit hierarchy echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Hyperbolic Entailment Learning ... object-level concepts entail attribute-level concepts via cones ... hierarchical modeling capability of hyperbolic space
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hurst A, Lerer A, and et al. Goucher A P. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Break-a-scene: Extracting multiple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multiple concepts from a single image. InSIGGRAPH Asia, 2023. 1, 2, 7
work page 2023
-
[3]
Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst
Michael M. Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: Going beyond euclidean data.IEEE Signal Processing Mag- azine, 2017. 3
work page 2017
-
[4]
Unsupervised learn- ing of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised learn- ing of visual features by contrasting cluster assignments. In NeurIPS, 2020. 3
work page 2020
-
[5]
Ice: Intrinsic con- cept extraction from a single image via diffusion models
Fernando Julio Cendra and Kai Han. Ice: Intrinsic con- cept extraction from a single image via diffusion models. In CVPR, 2025. 1, 2, 3, 4, 5, 6, 7, 8
work page 2025
-
[6]
Horopca: Hyperbolic dimensionality reduction via horo- spherical projections
Ines Chami, Albert Gu, Dat Nguyen, and Christopher R ´e. Horopca: Hyperbolic dimensionality reduction via horo- spherical projections. InICML, 2021. 6
work page 2021
-
[7]
Wenhu Chen, Hexiang Hu, Yandong Li, Nataniel Ruiz, Xuhui Jia, Ming-Wei Chang, and William W. Cohen. Subject-driven text-to-image generation via apprenticeship learning. InNeurIPS, 2023. 2
work page 2023
-
[8]
Au- toconcept: Unsupervised extraction of constituent concepts from single image
Pranav Singh Chib, Kirtankumar Vijaykumar Patel, Mudit Gupta, Pise Ashutosh Kalidas, and Pravendra Singh. Au- toconcept: Unsupervised extraction of constituent concepts from single image. InICCV Workshops, 2025. 1, 2, 7
work page 2025
-
[9]
Hyperbolic image- text representations
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Ramakrishna Vedantam. Hyperbolic image- text representations. InICML, 2023. 3, 5
work page 2023
-
[10]
Bermano, Gal Chechik, and Daniel Cohen-Or
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image gen- eration using textual inversion. InICLR, 2023. 2
work page 2023
-
[11]
Bermano, Gal Chechik, and Daniel Cohen-Or
Rinon Gal, Moab Arar, Yuval Atzmon, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. Encoder-based domain tuning for fast personalization of text-to-image models.ACM Transactions on Graphics (TOG), 2023. 2
work page 2023
-
[12]
Hyperbolic entailment cones for learning hierarchical em- beddings
Octavian Ganea, Gary Becigneul, and Thomas Hofmann. Hyperbolic entailment cones for learning hierarchical em- beddings. InICML, 2018. 5
work page 2018
-
[13]
Octavian-Eugen Ganea, Gary B ´ecigneul, and Thomas Hof- mann. Hyperbolic neural networks. InNeurIPS, 2018. 3, 4, 5
work page 2018
- [14]
-
[15]
Shaozhe Hao, Kai Han, Zhengyao Lv, Shihao Zhao, and Kwan-Yee K. Wong. ConceptExpress: Harnessing diffusion models for single-image unsupervised concept extraction. In ECCV, 2024. 1, 2, 6, 7
work page 2024
-
[16]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 3, 4
work page 2020
-
[17]
Sarah Ibrahimi, Mina Ghadimi Atigh, Pascal Mettes, and Marcel Worring. Intriguing properties of hyperbolic embed- dings in vision-language models.Transactions on Machine Learning Research, 2024. 3
work page 2024
- [18]
-
[19]
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, and Philip Teare. An image is worth multiplewords: dis- covering object level concepts using multi-concept prompt learning. InICML, 2024. 1, 2
work page 2024
-
[20]
Mixco: Mix-up contrastive learning for visual representa- tion.arXiv preprint arXiv:2010.06300, 2020
Sungnyun Kim, Gihun Lee, Sangmin Bae, and Seyoung Yun. Mixco: Mix-up contrastive learning for visual representa- tion.arXiv preprint arXiv:2010.06300, 2020. 3
-
[21]
Attention-based ensemble for deep met- ric learning
Wonsik Kim, Bhavya Goyal, Kunal Chawla, Jungmin Lee, and Keunjoo Kwon. Attention-based ensemble for deep met- ric learning. InECCV, 2018. 3
work page 2018
-
[22]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. InCVPR, 2023. 2
work page 2023
-
[23]
Diffusion models already have a semantic latent space
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space. InICLR, 2023. 3
work page 2023
-
[24]
Inferring concept hierarchies from text corpora via hyperbolic embeddings
Matthew Le, Stephen Roller, Laetitia Papaxanthos, Douwe Kiela, and Maximilian Nickel. Inferring concept hierarchies from text corpora via hyperbolic embeddings. InACL, 2019. 5
work page 2019
-
[25]
Dongxu Li, Junnan Li, and Steven C. H. Hoi. Blip-diffusion: Pre-trained subject representation for controllable text-to- image generation and editing. InNeurIPS, 2023. 2
work page 2023
-
[26]
Enhancing hyperbolic graph embeddings via contrastive learning.arXiv preprint arXiv:2201.08554, 2022
Jiahong Liu, Menglin Yang, Min Zhou, Shanshan Feng, and Philippe Fournier-Viger. Enhancing hyperbolic graph embeddings via contrastive learning.arXiv preprint arXiv:2201.08554, 2022. 3
-
[27]
Tenenbaum, and Antonio Torralba
Nan Liu, Yilun Du, Shuang Li, Joshua B. Tenenbaum, and Antonio Torralba. Unsupervised compositional concepts dis- covery with text-to-image generative models. InICCV, 2023. 2
work page 2023
-
[28]
Ma, Huan Yang, Wenjing Wang, Jianlong Fu, and Jiay- ing Liu
Y . Ma, Huan Yang, Wenjing Wang, Jianlong Fu, and Jiay- ing Liu. Unified multi-modal latent diffusion for joint sub- ject and text conditional image generation.arXiv preprint arXiv:2303.09319, 2023. 2
-
[29]
Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image genera- tion and editing with text-guided diffusion models. InICML,
-
[30]
Compositional entailment learning for hyperbolic vision-language models
Avik Pal, Max van Spengler, Guido Maria D’Amely di Me- lendugno, Alessandro Flaborea, Fabio Galasso, and Pascal Mettes. Compositional entailment learning for hyperbolic vision-language models. InICLR, 2025. 3
work page 2025
-
[31]
Wei Peng, Tuomas Varanka, Abdelrahman Mostafa, Henglin Shi, and Guoying Zhao. Hyperbolic deep neural networks: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021. 4, 5
work page 2021
-
[32]
Hyperbolic safety-aware vision-language models
Tobia Poppi, Tejaswi Kasarla, Pascal Mettes, Lorenzo Baraldi, and Rita Cucchiara. Hyperbolic safety-aware vision-language models. InCVPR, 2025. 5
work page 2025
-
[33]
Controlling text-to-image diffusion by orthogo- nal finetuning
Zeju Qiu, Weiyang Liu, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, and Bernhard Sch¨olkopf. Controlling text-to-image diffusion by orthogo- nal finetuning. InNeurIPS, 2023. 2
work page 2023
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InICML, 2021. 4
work page 2021
-
[35]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gen- eration with clip latents.arXiv preprint arXiv:2204.06125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 2, 3, 4
work page 2022
-
[37]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR, 2023. 2
work page 2023
-
[38]
Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Lit, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Raphael Gontijo-Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022. 3, 4
work page 2022
-
[39]
Instant- booth: Personalized text-to-image generation without test- time finetuning
Jing Shi, Wei Xiong, Zhe Lin, and Hyun Joon Jung. Instant- booth: Personalized text-to-image generation without test- time finetuning. InCVPR, 2024. 2
work page 2024
-
[40]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[41]
Towards compositionality in concept learning
Adam Stein, Aaditya Naik, Yinjun Wu, Mayur Naik, and Eric Wong. Towards compositionality in concept learning. InICML, 2024. 1, 2, 3, 4, 6
work page 2024
-
[42]
Key-locked rank one editing for text-to-image personaliza- tion
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. Key-locked rank one editing for text-to-image personaliza- tion. InSIGGRAPH Asia, 2023. 2
work page 2023
-
[43]
Yael Vinker, Andrey V oynov, Daniel Cohen-Or, and Ariel Shamir. Concept decomposition for visual exploration and inspiration.ACM Transactions on Graphics (TOG), 2023. 3
work page 2023
-
[44]
Concept algebra for (score-based) text-controlled generative models
Zihao Wang, Lin Gui, Jeffrey Negrea, and Victor Veitch. Concept algebra for (score-based) text-controlled generative models. InNeurIPS, 2023. 3
work page 2023
-
[45]
Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation
Yuxiang Wei, Yabo Zhang, Zhilong Ji, Jinfeng Bai, Lei Zhang, and Wangmeng Zuo. Elite: Encoding visual con- cepts into textual embeddings for customized text-to-image generation. InICCV, 2023. 2
work page 2023
-
[46]
Zhenlin Xu, Marc Niethammer, and Colin Raffel. Compo- sitional generalization in unsupervised compositional repre- sentation learning: a study on disentanglement and emergent language. InNeurIPS, 2022. 3
work page 2022
-
[47]
Guanting Ye, Qiyan Zhao, Wenhao Yu, Liangyu Yuan, Mingkai Li, Xiaofeng Zhang, Jianmin Ji, Yanyong Zhang, Qing Jiang, and Ka-Veng Yuen. Sope: Spherical coordinate- based positional embedding for enhancing spatial perception of 3d lvlms.arXiv preprint arXiv:2602.22716, 2026. 1
-
[48]
Cˆ2rope: Causal continuous rotary positional encoding for 3d large multimodal-models reasoning
Guanting Ye, Qiyan Zhao, Wenhao Yu, Xiaofeng Zhang, Jianmin Ji, Yanyong Zhang, and Ka-Veng Yuen. Cˆ2rope: Causal continuous rotary positional encoding for 3d large multimodal-models reasoning. InICRA, 2026. 1
work page 2026
-
[49]
Understanding hyperbolic metric learning through hard neg- ative sampling
Yun Yue, Fangzhou Lin, Guanyi Mou, and Ziming Zhang. Understanding hyperbolic metric learning through hard neg- ative sampling. InWACV, 2024. 3
work page 2024
-
[50]
Hallucination be- gins where saliency drops
Xiaofeng Zhang, Yuanchao Zhu, Chaochen Gu, Xiaosong Yuan, Qiyan Zhao, Jiawei Cao, Feilong Tang, Sinan Fan, Yaomin Shen, Chen Shen, and Hao Tang. Hallucination be- gins where saliency drops. InICLR, 2026. 1
work page 2026
-
[51]
Attention calibration for disentangled text-to-image person- alization
Yanbing Zhang, Mengping Yang, Qin Zhou, and Zhe Wang. Attention calibration for disentangled text-to-image person- alization. InCVPR, 2024. 2
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.