Recognition: no theorem link
Graph In-Context Operator Networks for Generalizable Spatiotemporal Prediction
Pith reviewed 2026-05-15 11:51 UTC · model grok-4.3
The pith
In-context operator learning outperforms classical single-operator models on spatiotemporal air quality prediction across regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
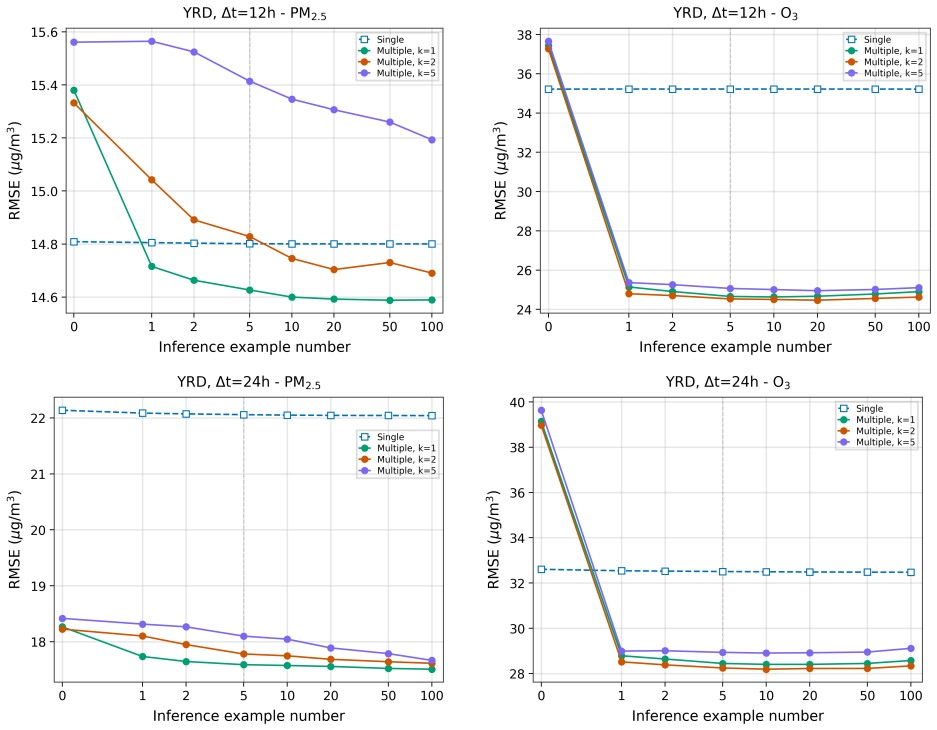
By proposing GICON, which integrates graph message passing for geometric generalization with example-aware positional encoding for cardinality generalization, the authors show that in-context operator learning outperforms classical operator learning on complex spatiotemporal tasks like air quality prediction, achieving better generalization across spatial domains and robust scaling from few to 100 examples at inference under matched training data and steps.
What carries the argument
GICON, the Graph In-Context Operator Network, which combines graph message passing to generalize across geometries with example-aware positional encoding to handle different numbers of contextual examples.
If this is right
- In-context operator learning generalizes better across different spatial regions than single-operator training on the same data.
- Performance scales reliably as the number of contextual examples provided at inference increases up to 100.
- The approach succeeds on complex real-world spatiotemporal tasks such as air quality forecasting with matched training budgets.
- Contextual examples enable inference of solution operators without requiring weight updates during testing.
- Controlled experiments with identical training data and steps isolate the advantage of in-context mechanisms.
Where Pith is reading between the lines
- Similar in-context methods could extend generalization benefits to other spatiotemporal domains such as weather forecasting or traffic flow.
- Further experiments that swap architectures while holding the in-context mechanism fixed would better isolate the paradigm's contribution.
- Adoption in dynamic environments could lower costs by avoiding full retraining when conditions or locations change.
- Testing on datasets with greater spatial diversity would clarify the boundaries of the geometric generalization provided by graph passing.
Load-bearing premise
The performance gains in the controlled comparisons stem specifically from the in-context learning mechanism rather than from the graph message passing or positional encoding components of the GICON architecture.
What would settle it
Training a classical single-operator model with the same graph message passing and positional encoding but without contextual examples, then finding it matches or exceeds GICON accuracy on the air quality prediction tasks across regions, would falsify the claim.
Figures










read the original abstract
In-context operator learning enables neural networks to infer solution operators from contextual examples without weight updates. While prior work has demonstrated the effectiveness of this paradigm in leveraging vast datasets, a systematic comparison against single-operator learning using identical training data has been absent. We address this gap through controlled experiments comparing in-context operator learning against classical operator learning (single-operator models trained without contextual examples), under the same training steps and dataset. To enable this investigation on real-world spatiotemporal systems, we propose GICON (Graph In-Context Operator Network), combining graph message passing for geometric generalization with example-aware positional encoding for cardinality generalization. Experiments on air quality prediction across two Chinese regions show that in-context operator learning outperforms classical operator learning on complex tasks, generalizing across spatial domains and scaling robustly from few training examples to 100 at inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GICON (Graph In-Context Operator Network), which augments operator learning with graph message passing for geometric generalization and example-aware positional encoding for cardinality generalization. It claims that in-context operator learning with GICON outperforms classical single-operator learning (models trained without contextual examples) on air quality prediction across two Chinese regions, under identical training data and steps, with improved generalization across spatial domains and robust scaling from few-shot to 100-example inference.
Significance. If the central empirical comparison holds after isolating the in-context mechanism, the result would strengthen the case for in-context paradigms in operator networks for real-world spatiotemporal systems, offering a route to domain-generalizable predictions without per-domain retraining.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the claim that in-context operator learning outperforms classical operator learning rests on a controlled comparison under identical data and training steps, but the manuscript does not state that the classical baselines use the identical GICON backbone with only the in-context components removed. Because GICON introduces graph message passing and example-aware positional encoding, any performance gap could be driven by these new inductive biases rather than the in-context training/inference procedure itself.
- [Abstract] Abstract: the central empirical claim of outperformance, generalization across regions, and scaling from few to 100 examples is asserted without any quantitative metrics, error bars, dataset sizes, or implementation details in the provided text, leaving the result unverifiable from the manuscript as presented.
minor comments (1)
- [Experiments] Add explicit statements of dataset sizes, number of spatial locations, and exact training/inference protocols in the Experiments section to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and describe the revisions that will be made.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim that in-context operator learning outperforms classical operator learning rests on a controlled comparison under identical data and training steps, but the manuscript does not state that the classical baselines use the identical GICON backbone with only the in-context components removed. Because GICON introduces graph message passing and example-aware positional encoding, any performance gap could be driven by these new inductive biases rather than the in-context training/inference procedure itself.
Authors: We agree that the manuscript text should explicitly confirm the architecture used for the baselines to isolate the in-context mechanism. The controlled experiments employ the identical GICON backbone for both the in-context and classical settings, with the classical models trained on single examples and without the example-aware positional encoding. To eliminate ambiguity, we will revise the Abstract and Experiments section to state that classical baselines use the same GICON architecture with only the in-context components removed. This change will be incorporated in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim of outperformance, generalization across regions, and scaling from few to 100 examples is asserted without any quantitative metrics, error bars, dataset sizes, or implementation details in the provided text, leaving the result unverifiable from the manuscript as presented.
Authors: The abstract provides a high-level summary of the findings. All quantitative metrics, error bars from repeated runs, dataset sizes, and implementation details appear in the Experiments section. To improve verifiability from the abstract itself, we will add concise quantitative highlights (e.g., average error reduction and scaling behavior) while respecting length limits. This constitutes a partial revision. revision: partial
Circularity Check
No circularity: empirical comparison rests on controlled experiments, not self-referential definitions or fitted predictions
full rationale
The paper's central claim is an empirical result from controlled experiments on air quality data: in-context operator learning (via GICON) outperforms single-operator classical learning under identical training steps and dataset. GICON is introduced as an enabling architecture (graph message passing + example-aware positional encoding) rather than a derived quantity. No equations, parameters, or self-citations reduce the reported outperformance to a tautology or input by construction. The comparison is presented as isolating the in-context paradigm; any architectural confounding is a methodological question, not a circular reduction in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Graph message passing captures geometric structure for generalization across spatial domains
- domain assumption Example-aware positional encoding enables cardinality generalization without retraining
Forward citations
Cited by 2 Pith papers
-
Evolutionary Ensemble of Agents
EvE uses co-evolving populations of solvers and guidance states with Elo-based evaluation to autonomously discover a rescale-then-interpolate mechanism for better generalization in In-Context Operator Networks.
-
Evolutionary Ensemble of Agents
EvE co-evolves code solvers and guidance states via synchronous races and Elo updates, discovering a rescale-then-interpolate mechanism that enables example-count generalization in ICON.
Reference graph
Works this paper leans on
-
[1]
Weinan E, Jiequn Han, and Arnulf Jentzen. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Communications in Mathematics and Statistics, 5(4):349–380, 2017
work page 2017
-
[2]
Jiequn Han, Arnulf Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning.Proceedings of the National Academy of Sciences, 115(34):8505– 8510, 2018
work page 2018
-
[3]
Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations.Journal of Computational Physics, 375:1339–1364, 2018
work page 2018
-
[4]
Weinan E and Bing Yu. The deep ritz method: A deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6(1):1–12, 2018
work page 2018
-
[5]
PDE-Net: Learning PDEs from data
Zichao Long, Yiping Lu, Xianzhong Ma, and Bin Dong. PDE-Net: Learning PDEs from data. InInternational Conference on Machine Learning (ICML), pages 3208–3216. PMLR, 2018
work page 2018
-
[6]
Maziar Raissi, Paris Perdikaris, and George Em Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019
work page 2019
-
[7]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, 2021
work page 2021
-
[8]
Fourier neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[9]
Liu Yang, Siting Liu, Tingwei Meng, and Stanley J. Osher. In-context operator learning with data prompts for differential equation problems.Proceedings of the National Academy of Sciences, 120(39):e2310142120, 2023
work page 2023
-
[10]
Liu Yang, Siting Liu, and Stanley J. Osher. Fine-tune language models as multi-modal differential equation solvers.Neural Networks, 2025
work page 2025
-
[11]
Liu Yang and Stanley J. Osher. PDE generalization of in-context operator networks: A study on 1D scalar nonlinear conservation laws.Journal of Computational Physics, 519:113379, 2024
work page 2024
-
[12]
Yadi Cao, Yuxuan Liu, Liu Yang, Rose Yu, Hayden Schaeffer, and Stanley J. Osher. VICON: Vision in-context operator networks for multi-physics fluid dynamics prediction.Transactions on Machine Learning Research, 2026
work page 2026
-
[13]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019
work page 2019
-
[14]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 1877–1901, 2020. 15
work page 1901
-
[15]
KnowAir-V2: A benchmark dataset for air quality forecasting with PCDCNet, 2025
Shuo Wang, Yun Cheng, Qingye Meng, Olga Saukh, Jiang Zhang, Jingfang Fan, Yuanting Zhang, Xingyuan Yuan, and Lothar Thiele. KnowAir-V2: A benchmark dataset for air quality forecasting with PCDCNet, 2025. Data set
work page 2025
-
[16]
Tianping Chen and Hong Chen. Approximation capability to functions of several variables, nonlinear functionals, and operators by radial basis function neural networks.IEEE Transactions on Neural Networks, 6(4):904–910, 1995
work page 1995
-
[17]
Tianping Chen and Hong Chen. Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems.IEEE Transactions on Neural Networks, 6(4):911–917, 1995
work page 1995
-
[18]
Lu Lu, Xuhui Meng, Shengze Cai, Zhiping Mao, Somdatta Goswami, Zhongqiang Zhang, and George Em Karniadakis. A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data.Computer Methods in Applied Mechanics and Engineering, 393:114778, 2022
work page 2022
-
[19]
Pengzhan Jin, Shuai Meng, and Lu Lu. MIONet: Learning multiple-input operators via tensor product.SIAM Journal on Scientific Computing, 44(6):A3490–A3514, 2022
work page 2022
-
[20]
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023
work page 2023
-
[21]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. Learning the solution operator of para- metric partial differential equations with physics-informed DeepONets.Science Advances, 7(40):eabi8605, 2021
work page 2021
-
[22]
Zecheng Zhang, Christian Moya, Wing Tat Leung, Guang Lin, and Hayden Schaeffer. Bayesian deep operator learning for homogenized to fine-scale maps for multiscale PDE.Multiscale Modeling & Simulation, 22(3):956–972, 2024
work page 2024
-
[23]
U-FNO—an enhanced fourier neural operator-based deep-learning model for multiphase flow
Gege Wen, Zongyi Li, Kamyar Azizzadenesheli, Anima Anandkumar, and Sally M Benson. U-FNO—an enhanced fourier neural operator-based deep-learning model for multiphase flow. Advances in Water Resources, 163:104180, 2022
work page 2022
-
[24]
Zecheng Zhang, Wing Tat Leung, and Hayden Schaeffer. BelNet: Basis enhanced learning, a mesh-free neural operator.Proceedings of the Royal Society A, 479(2276):20230043, 2023
work page 2023
-
[25]
GNOT: A general neural operator transformer for operator learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. GNOT: A general neural operator transformer for operator learning. InInternational Conference on Machine Learning (ICML), volume 202, pages 12556–12569. PMLR, 2023
work page 2023
-
[26]
Geometry- informed neural operator for large-scale 3D PDEs
Zongyi Li, Nikola Kovachki, Chris Choy, Boyi Li, Jean Kossaifi, Shourya Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, et al. Geometry- informed neural operator for large-scale 3D PDEs. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
work page 2023
-
[27]
Zecheng Zhang, Christian Moya, Lu Lu, Guang Lin, and Hayden Schaeffer. D2NO: Efficient han- dling of heterogeneous input function spaces with distributed deep neural operators.Computer Methods in Applied Mechanics and Engineering, 428:117084, 2024. 16
work page 2024
-
[28]
Thorsten Kurth, Shashank Subramanian, Peter Harrington, Jaideep Pathak, Morteza Mardani, David Hall, Andrea Miele, Karthik Kashinath, and Anima Anandkumar. FourCastNet: Accel- erating global high-resolution weather forecasting using adaptive Fourier neural operators. In Proceedings of the Platform for Advanced Scientific Computing Conference (PASC ’23), D...
work page 2023
-
[29]
Zhongyi Jiang, Min Zhu, and Lu Lu. Fourier-MIONet: Fourier-enhanced multiple-input neural operators for multiphase modeling of geological carbon sequestration.Reliability Engineering & System Safety, 251:110392, 2024
work page 2024
-
[30]
Trayanova, and Mauro Mag- gioni
Minglang Yin, Nicolas Charon, Ryan Brody, Lu Lu, Natalia A. Trayanova, and Mauro Mag- gioni. A scalable framework for learning the geometry-dependent solution operators of partial differential equations.Nature Computational Science, 4(12):928–940, 2024
work page 2024
-
[31]
Christian Moya, Amirhossein Mollaali, Zecheng Zhang, Lu Lu, and Guang Lin. Conformalized- DeepONet: A distribution-free framework for uncertainty quantification in deep operator networks.Physica D: Nonlinear Phenomena, 471:134418, 2025
work page 2025
-
[32]
Poseidon: Efficient foundation models for PDEs
Maximilian Herde, Bogdan Raoni´ c, Tobias Rohner, Roger K¨ appeli, Roberto Molinaro, Em- manuel de B´ ezenac, and Siddhartha Mishra. Poseidon: Efficient foundation models for PDEs. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
work page 2024
-
[33]
LeMON: Learning to learn multi-operator networks, 2024
Jingmin Sun, Zecheng Zhang, and Hayden Schaeffer. LeMON: Learning to learn multi-operator networks, 2024
work page 2024
-
[34]
Peter W. Battaglia, Jessica B. Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zam- baldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, Caglar Gulcehre, Francis Song, Andrew Ballard, Justin Gilmer, George Dahl, Ashish Vaswani, Kelsey Allen, Charles Nash, Victoria Langston, Chris Dyer, Nicolas Heess, Daan Wierst...
work page 2018
- [35]
- [36]
-
[37]
Message passing neural PDE solvers
Johannes Brandstetter, Daniel Worrall, and Max Welling. Message passing neural PDE solvers. InInternational Conference on Learning Representations (ICLR), 2022. Spotlight
work page 2022
-
[38]
Neural operator: Graph kernel network for partial differential equations, 2020
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Graph kernel network for partial differential equations, 2020
work page 2020
-
[39]
Multipole graph neural operator for parametric partial differential equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Multipole graph neural operator for parametric partial differential equations. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6755–6766, 2020. 17
work page 2020
-
[40]
Sepehr Mousavi, Shizheng Wen, Levi Lingsch, Maximilian Herde, Bogdan Raoni´ c, and Sid- dhartha Mishra. RIGNO: A graph-based framework for robust and accurate operator learning for PDEs on arbitrary domains. InAdvances in Neural Information Processing Systems (NeurIPS), volume 38, 2025
work page 2025
-
[41]
Benjamin J. Zhang, Siting Liu, Stanley J. Osher, and Markos A. Katsoulakis. Probabilistic operator learning: generative modeling and uncertainty quantification for foundation models of differential equations, 2025
work page 2025
-
[42]
Tingwei Meng, Moritz Voß, Nils Detering, Giulio Farolfi, Stanley J. Osher, and Georg Menz. Solving optimal execution problems via in-context operator networks, 2025
work page 2025
-
[43]
In-context operator learning on the space of probability measures, 2026
Frank Cole, Dixi Wang, Yineng Chen, Yulong Lu, and Rongjie Lai. In-context operator learning on the space of probability measures, 2026
work page 2026
-
[44]
Benjamin Erichson, Kush Bhatia, Michael W
Jerry Weihong Liu, N. Benjamin Erichson, Kush Bhatia, Michael W. Mahoney, and Christopher Re. Does in-context operator learning generalize to domain-shifted settings? InNeurIPS 2023 Workshop on the Symbiosis of Deep Learning and Differential Equations (DLDE III), 2023
work page 2023
-
[45]
Frank Cole, Yulong Lu, Wuzhe Xu, and Tianhao Zhang. In-context learning of linear systems: Generalization theory and applications to operator learning, 2024
work page 2024
-
[46]
Continuum transformers perform in-context learning by operator gradient descent, 2025
Abhiti Mishra, Yash Patel, and Ambuj Tewari. Continuum transformers perform in-context learning by operator gradient descent, 2025
work page 2025
-
[47]
Yuxuan Liu, Zecheng Zhang, and Hayden Schaeffer. Prose: Predicting operators and symbolic expressions using multimodal transformers.Neural Networks, 180:106707, 2024
work page 2024
-
[48]
Yuxuan Liu, Jingmin Sun, Xinjie He, Griffin Pinney, Zecheng Zhang, and Hayden Schaeffer. PROSE-FD: A multimodal PDE foundation model for learning multiple operators for forecasting fluid dynamics. InNeurIPS 2024 Workshop on Foundation Models for Science (FM4Science), 2024
work page 2024
-
[49]
Data-efficient operator learning via unsupervised pretraining and in-context learning
Wuyang Chen, Jialin Song, Pu Ren, Shashank Subramanian, Dmitriy Morozov, and Michael Mahoney. Data-efficient operator learning via unsupervised pretraining and in-context learning. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, 2024
work page 2024
-
[50]
Zebra: In-context and generative pretraining for solving parametric PDEs
Louis Serrano, Armand Kassa¨ ı Koupa¨ ı, Thomas X Wang, Pierre Erbacher, and Patrick Gallinari. Zebra: In-context and generative pretraining for solving parametric PDEs. InInternational Conference on Machine Learning (ICML). PMLR, 2025
work page 2025
-
[51]
ENMA: Tokenwise autoregression for continuous neural PDE operators
Armand Kassa¨ ı Koupa¨ ı, Lise Le Boudec, Louis Serrano, and Patrick Gallinari. ENMA: Tokenwise autoregression for continuous neural PDE operators. InAdvances in Neural Information Processing Systems (NeurIPS), volume 38, 2025
work page 2025
-
[52]
The Faiss library.IEEE Transactions on Big Data, 2025
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre- Emmanuel Mazar´ e, Maria Lomeli, Lucas Hosseini, and Herv´ e J´ egou. The Faiss library.IEEE Transactions on Big Data, 2025
work page 2025
-
[53]
Shuo Wang, Yun Cheng, Qingye Meng, Olga Saukh, Jiang Zhang, Jingfang Fan, Yuanting Zhang, Xingyuan Yuan, and Lothar Thiele. PCDCNet: A surrogate model for air quality forecasting with physical-chemical dynamics and constraints, 2025. 18
work page 2025
-
[54]
Ryan M. May, Kevin H. Goebbert, Jonathan E. Thielen, John R. Leeman, M. Drew Camron, Zachary Bruick, Eric C. Bruning, Russell P. Manser, Sean C. Arms, and Patrick T. Marsh. MetPy: A meteorological python library for data analysis and visualization.Bulletin of the American Meteorological Society, 103(10):E2273–E2284, 2022
work page 2022
-
[55]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019
work page 2019
-
[56]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. https://github. com/KellerJordan/Muon, 2024. 19 A Positional Encoding Algorithms Algorithm 1Positional Encoding for GICON Require:Hidden statesH∈R |V|×(2k+1)×d, number of attention headsH — Inte...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.