Recognition: 2 theorem links
· Lean TheoremSublime: Sublinear Error & Space for Unbounded Skewed Streams
Pith reviewed 2026-05-15 12:05 UTC · model grok-4.3
The pith
Sublime generalizes frequency sketches to achieve sublinear error and space for unbounded skewed streams by dynamically extending counters and expanding their number.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sublime generalizes frequency estimation sketches by starting with short counters that dynamically elongate as they overflow, storing their extensions within the same cache line through efficient bit manipulation routines, and by expanding the number of counters at a configurable rate. When applied to the Count-Min Sketch and Count Sketch, theoretical analysis and empirical evaluation show that it significantly improves accuracy and reduces memory footprint over the state of the art while maintaining competitive or superior performance on skewed unbounded streams.
What carries the argument
Dynamic counter elongation via in-cache-line extensions accessed by bit manipulation, paired with configurable expansion of the counter array.
If this is right
- Sublime applies to both Count-Min Sketch and Count Sketch with superior accuracy and memory.
- Applications can tune a spectrum of accuracy-memory tradeoffs via the expansion rate.
- Runtime remains competitive or better than baselines under the same workloads.
- Theoretical guarantees establish sublinear error and space under skew.
Where Pith is reading between the lines
- Similar dynamic-extension techniques could apply to other sketch families or hash-based structures facing skew.
- Stream systems could track frequencies over far longer horizons without memory scaling linearly with length.
- An adaptive version that adjusts the expansion rate from observed data skew might further improve practical results.
Load-bearing premise
Bit-manipulation routines can locate and access counter extensions with negligible overhead, and a single configurable expansion rate works across arbitrary skewed streams.
What would settle it
Measure error growth and memory usage of Sublime against standard Count-Min and Count Sketch on a synthetic skewed stream of increasing length; linear growth in either quantity would falsify the sublinear claim.
Figures








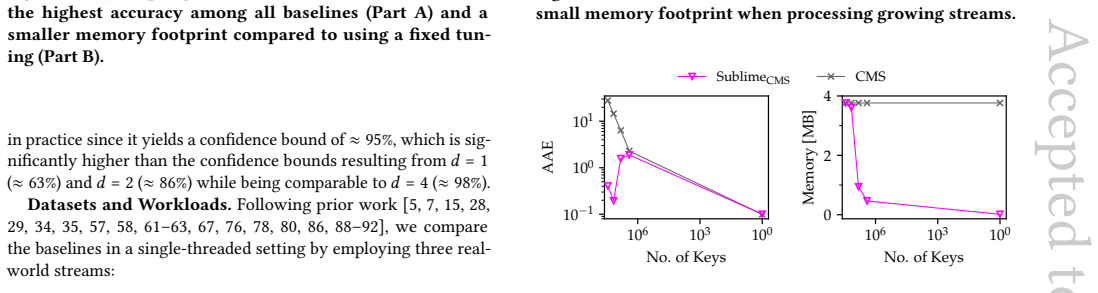


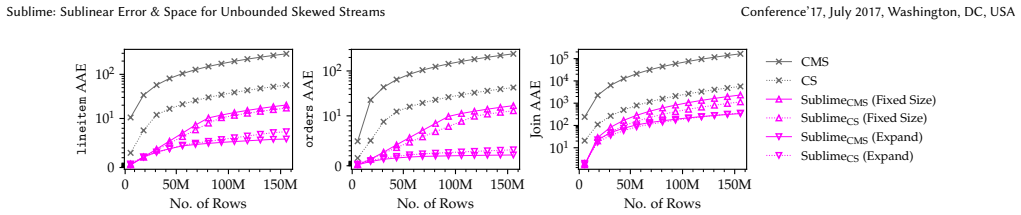

read the original abstract
Modern stream processing systems often need to track the frequency of distinct keys in a data stream in real-time. Since maintaining exact counts can require a prohibitive amount of memory, many applications rely on compact, probabilistic data structures known as frequency estimation sketches to approximate them. However, mainstream frequency estimation sketches fall short in two critical aspects. First, they are memory-inefficient under skewed workloads because they use uniformly-sized counters to count the keys, thus wasting memory on storing the leading zeros of many small counts. Second, their estimation error deteriorates at least linearly with the length of the stream--which may grow indefinitely--because they rely on a fixed number of counters. We present Sublime, a framework that generalizes frequency estimation sketches to address these challenges. To reduce memory footprint under skew, Sublime begins with short counters and dynamically elongates them as they overflow, storing their extensions within the same cache line. It employs efficient bit manipulation routines to quickly locate and access a counter's extensions. To maintain accuracy as the stream grows, Sublime also expands its number of counters at a configurable rate, exposing a new spectrum of accuracy-memory tradeoffs that applications can tune to their needs. We apply Sublime to both Count-Min Sketch and Count Sketch. Through theoretical analysis and empirical evaluation, we show that Sublime significantly improves accuracy and memory over the state of the art while maintaining competitive or superior performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Sublime, a framework generalizing frequency estimation sketches (applied to Count-Min Sketch and Count Sketch) for unbounded skewed streams. It dynamically elongates short counters as they overflow (storing extensions in the same cache line via bit manipulation) to reduce memory waste on small counts under skew, and expands the number of counters at a single configurable rate chosen in advance to achieve sublinear error growth with stream length while exposing tunable accuracy-memory tradeoffs. Theoretical analysis and empirical evaluation are claimed to show significant improvements over the state of the art.
Significance. If the analysis and bounds hold, Sublime would meaningfully advance streaming frequency estimation by addressing both memory inefficiency under skew and linear error growth with unbounded stream length, offering a practical tunable spectrum of tradeoffs for real-time systems.
major comments (2)
- [Theoretical analysis section (around the expansion-rate derivation)] The sublinear-error claim depends on a single fixed expansion rate for the counter array chosen in advance. For streams whose skew pattern changes over time (e.g., heavy-hitter set shifts midway), the hash-function independence and union-bound arguments used to bound collisions no longer apply uniformly across phases, so the per-item error may grow faster than the stated sublinear bound in later phases.
- [Abstract and theoretical analysis] No explicit error bound, proof sketch, or dependence on the expansion rate appears in the provided description; the central claim that error grows sublinearly while memory remains sublinear therefore cannot be verified from the given material.
minor comments (2)
- [Abstract] The abstract asserts 'theoretical analysis and empirical evaluation' but supplies neither equations nor quantitative results; adding a one-sentence statement of the key error bound (e.g., O(log n / w) or similar) would improve clarity.
- [Implementation / bit-manipulation routines] Clarify the precise definition of the configurable expansion rate and its relation to cache-line alignment and bit-manipulation overhead in the implementation section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on the theoretical analysis and indicate the revisions we will make to strengthen the presentation.
read point-by-point responses
-
Referee: [Theoretical analysis section (around the expansion-rate derivation)] The sublinear-error claim depends on a single fixed expansion rate for the counter array chosen in advance. For streams whose skew pattern changes over time (e.g., heavy-hitter set shifts midway), the hash-function independence and union-bound arguments used to bound collisions no longer apply uniformly across phases, so the per-item error may grow faster than the stated sublinear bound in later phases.
Authors: We acknowledge the concern regarding non-stationary skew. The analysis in Section 4 applies the union bound over the cumulative stream length with a fixed expansion rate chosen in advance, yielding a sublinear error bound that holds regardless of phase-wise shifts because the counter array grows monotonically. Later phases operate with strictly more counters, which can only tighten (not loosen) the collision probability. We will add a clarifying remark and a short discussion of non-stationary workloads, recommending a conservatively smaller expansion rate when high variability is expected. This does not change the main claims but improves robustness. revision: partial
-
Referee: [Abstract and theoretical analysis] No explicit error bound, proof sketch, or dependence on the expansion rate appears in the provided description; the central claim that error grows sublinearly while memory remains sublinear therefore cannot be verified from the given material.
Authors: We agree that the abstract and introductory description omit an explicit bound. Section 4 derives the error as O(ε · (1 + ρ)^log n) where ρ is the tunable expansion-rate parameter (0 < ρ < 1), which is sublinear in stream length n while memory grows as O(w · (1 + ρ)^log n). A proof sketch using successive union bounds on the expanding array is provided there. We will revise the abstract to state the bound and its dependence on ρ concisely, and add a one-sentence proof outline to the introduction. revision: yes
Circularity Check
No significant circularity in Sublime derivation chain
full rationale
The provided abstract and context describe Sublime as a generalization of standard sketches (Count-Min, Count Sketch) via dynamic counter elongation with bit-manipulation access and a single configurable expansion rate for the counter array. No equations, derivations, or predictions are shown that reduce claimed sublinear error bounds to fitted parameters, self-definitions, or self-citation chains. The expansion rate is explicitly presented as a tunable input chosen in advance rather than derived from the target result. Theoretical analysis and empirical evaluation are invoked as external support without load-bearing self-referential steps. This is the common case of an honest non-finding: the central claims remain independent of the inputs they are evaluated against.
Axiom & Free-Parameter Ledger
free parameters (1)
- counter expansion rate
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Sublime expands its number of counters at a configurable rate... size function W(N)=N^α/ε
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VALE... 2-bit fragments... base-3 digits... rank and select
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Anonymized Internet Traces 2018. https://catalog.caida.org/dataset/ passive_2018_pcap. doi:dataset/passive_2018_pcap Dates used: 2025-10-11. Accessed: 2025-10-11
work page 2018
-
[2]
Charu C. Aggarwal. 2013.An Introduction to Sensor Data Analytics. Springer US, Boston, MA, 1–8. doi:10.1007/978-1-4614-6309-2_1
-
[3]
Kook Jin Ahn, Sudipto Guha, and Andrew McGregor. 2012. Analyzing graph structure via linear measurements. InProceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms(Kyoto, Japan)(SODA ’12). Society for Industrial and Applied Mathematics, USA, 459–467
work page 2012
-
[4]
Noga Alon, Yossi Matias, and Mario Szegedy. 1999. The space complexity of approximating the frequency moments.J. Comput. System Sci.58, 1 (1999), 137–147. doi:10.1006/jcss.1998.1627
-
[5]
Daniel Anderson, Pryce Bevan, Kevin Lang, Edo Liberty, Lee Rhodes, and Justin Thaler. 2017. A high-performance algorithm for identifying frequent items in data streams. InProceedings of the 2017 Internet Measurement Conference(London, United Kingdom)(IMC ’17). ACM, New York, NY, USA, 268–282. doi:10.1145/ 3131365.3131407
-
[6]
Jim Apple. 2022. Stretching your data with taffy filters.Software: Practice and Experience(2022). Accepted to SIGMOD 2026 Conference’17, July 2017, Washington, DC, USA Navid Eslami, Ioana O. Bercea, Rasmus Pagh, and Niv Dayan
work page 2022
-
[7]
Ran Basat, Gil Einziger, Michael Mitzenmacher, and Shay Vargaftik. 2021. SALSA: Self-Adjusting Lean Streaming Analytics. 864–875. doi:10.1109/ICDE51399.2021. 00080
-
[8]
Ran Ben Basat, Gil Einziger, Michael Mitzenmacher, and Shay Vargaftik. 2020. Faster and More Accurate Measurement through Additive-Error Counters. In IEEE INFOCOM 2020 - IEEE Conference on Computer Communications. 1251–1260. doi:10.1109/INFOCOM41043.2020.9155340
-
[9]
Ran Ben Basat, Xiaoqi Chen, Gil Einziger, Roy Friedman, and Yaron Kassner
-
[10]
Randomized Admission Policy for Efficient Top-k, Frequency, and Volume Estimation.IEEE/ACM Trans. Netw.27, 4 (Aug. 2019), 1432–1445. doi:10.1109/ TNET.2019.2918929
-
[11]
Ran Ben Basat, Gil Einziger, Isaac Keslassy, Ariel Orda, Shay Vargaftik, and Erez Waisbard. 2022. Memento: Making Sliding Windows Efficient for Heavy Hitters. IEEE/ACM Transactions on Networking30, 4 (2022), 1440–1453. doi:10.1109/TNET. 2021.3132385
-
[12]
Ferenc Bodon. 2012. Frequent Itemset Mining Dataset Repository, Kosarak. http://fimi.uantwerpen.be/data/
work page 2012
-
[13]
F. Bostanci, Ismail Yüksel, Ataberk Olgun, Konstantinos Kanellopoulos, Yahya Tuğrul, Abdullah Giray Yaglikçi, Mohammad Sadrosadati, and Onur Mutlu. 2024. CoMeT: Count-Min-Sketch-based Row Tracking to Mitigate RowHammer at Low Cost. 593–612. doi:10.1109/HPCA57654.2024.00050
-
[14]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache Flink™: Stream and Batch Processing in a Single Engine.Bulletin of the IEEE Computer Society Technical Committee on Data Engineering36, 4 (2015), 28–38
work page 2015
-
[15]
Moses Charikar, Kevin Chen, and Martin Farach-Colton. 2004. Finding frequent items in data streams.Theoretical Computer Science312, 1 (2004), 3–15. doi:10. 1016/S0304-3975(03)00400-6 Automata, Languages and Programming
work page 2004
-
[16]
Min Chen, Shigang Chen, and Zhiping Cai. 2017. Counter Tree: A Scalable Counter Architecture for Per-Flow Traffic Measurement.IEEE/ACM Trans. Netw. 25, 2 (April 2017), 1249–1262. doi:10.1109/TNET.2016.2621159
-
[17]
Qizhi Chen, Yisen Hong, Yuhan Wu, Tong Yang, and Bin Cui. 2024. CodingSketch: A Hierarchical Sketch with Efficient Encoding and Recursive Decoding. InICDE. 1592–1605. https://doi.org/10.1109/ICDE60146.2024.00130
-
[18]
Yuvaraj Chesetti, Navid Eslami, Huanchen Zhang, Niv Dayan, and Prashant Pandey. 2026. Aeris Filter: A Strongly and Monotonically Adaptive Range Fil- ter. InProceedings of the 2026 International Conference on Management of Data (Bangalore, India)(SIGMOD ’26). ACM, New York, NY, USA, 1670–1684
work page 2026
-
[19]
David Clark. 1997.Compact PAT trees. Ph. D. Dissertation. http://hdl.handle.net/ 10012/64
work page 1997
-
[20]
2023.PDEP — Parallel Bits Deposit
Felix Cloutier. 2023.PDEP — Parallel Bits Deposit. https://www.felixcloutier.com/ x86/pdep
work page 2023
-
[21]
Graham Cormode and Minos Garofalakis. 2005. Sketching streams through the net: distributed approximate query tracking. InProceedings of the 31st Interna- tional Conference on Very Large Data Bases(Trondheim, Norway)(VLDB ’05). VLDB Endowment, 13–24
work page 2005
-
[22]
Graham Cormode and S. Muthukrishnan. 2005. An improved data stream sum- mary: the count-min sketch and its applications.J. Algorithms55, 1 (April 2005), 58–75. doi:10.1016/j.jalgor.2003.12.001
-
[23]
G. Cormode and S. Muthukrishnan. 2005. What’s new: finding significant dif- ferences in network data streams.IEEE/ACM Transactions on Networking13, 6 (2005), 1219–1232. doi:10.1109/TNET.2005.860096
-
[24]
2018.5-Level Paging and 5-Level EPT White Paper
Intel Corporation. 2018.5-Level Paging and 5-Level EPT White Paper. Technical Report 335252-002. Intel Corporation. https://www.intel.com/content/www/us/ en/content-details/671442/5-level-paging-and-5-level-ept-white-paper.html Re- vision 1.1
work page 2018
-
[25]
Intel Corporation. 2025.Intel®64 and IA-32 Architectures Software Devel- oper’s Manual, Volume 3A: System Programming Guide, Part 1. Intel Corpo- ration. https://www.intel.com/content/www/us/en/developer/articles/technical/ intel-sdm.html Order Number 253668
work page 2025
-
[26]
Zhenwei Dai, Aditya Desai, Reinhard Heckel, and Anshumali Shrivastava. 2021. Active Sampling Count Sketch (ASCS) for Online Sparse Estimation of a Trillion Scale Covariance Matrix. InProceedings of the 2021 International Conference on Management of Data(Virtual Event, China)(SIGMOD ’21). ACM, New York, NY, USA, 352–364. doi:10.1145/3448016.3457327
-
[27]
Niv Dayan, Ioana O. Bercea, and Rasmus Pagh. 2024. Aleph Filter: To Infinity in Constant Time.Proc. VLDB Endow.17, 11 (July 2024), 3644–3656. doi:10.14778/ 3681954.3682027
-
[28]
Bercea, Pedro Reviriego, and Rasmus Pagh
Niv Dayan, Ioana O. Bercea, Pedro Reviriego, and Rasmus Pagh. 2023. InfiniFilter: Expanding Filters to Infinity and Beyond. InProceedings of the 2023 International Conference on Management of Data(Seattle, Washington, USA)(SIGMOD ’23, Vol. 1). ACM, New York, NY, USA, Article 140, 27 pages. doi:10.1145/3589285
-
[29]
Fan Deng and Davood Rafiei. [n. d.]. New Estimation Algorithms for Streaming Data: Count-min Can Do More. https://webdocs.cs.ualberta.ca/~drafiei/papers/ cmm.pdf
-
[30]
Rui Ding, Shibo Yang, Xiang Chen, and Qun Huang. 2023. BitSense: Universal and Nearly Zero-Error Optimization for Sketch Counters with Compressive Sensing. InProceedings of the ACM SIGCOMM 2023 Conference(New York, NY, USA)(ACM SIGCOMM ’23). ACM, New York, NY, USA, 220–238. doi:10.1145/3603269.3604865
-
[31]
Otmar Ertl. 2024. UltraLogLog: A Practical and More Space-Efficient Alternative to HyperLogLog for Approximate Distinct Counting.Proc. VLDB Endow.17, 7 (March 2024), 1655–1668. doi:10.14778/3654621.3654632
-
[32]
Navid Eslami, Ioana O. Bercea, and Niv Dayan. 2025. Diva: Dynamic Range Filter for Var-Length Keys and Queries.Proc. VLDB Endow.18, 11 (July 2025), 3923–3936. doi:10.14778/3749646.3749664
-
[33]
Philippe Flajolet, Eric Fusy, Olivier Gandouet, and Frédéric Meunier. 2007. Hy- perLogLog: the analysis of a near-optimal cardinality estimation algorithm. In Analysis of Algorithms 2007 (AofA07), Philippe Jacquet (Ed.). Juan les pins, France, 127–146. https://hal.science/hal-00406166
work page 2007
-
[34]
Guoju Gao, Tianyu Ma, He Huang, Yu-E Sun, Haibo Wang, Yang Du, and Shigang Chen. 2024. Scout Sketch+: Finding Both Promising and Damping Items Simulta- neously in Data Streams.IEEE/ACM Trans. Netw.32, 6 (Oct. 2024), 5491–5506. doi:10.1109/TNET.2024.3469196
- [35]
-
[36]
Guoju Gao, Zhaorong Qian, He Huang, Yu-E Sun, and Yang Du. 2025. TailoredS- ketch: A Fast and Adaptive Sketch for Efficient Per-Flow Size Measurement. IEEE Transactions on Network Science and Engineering12, 1 (2025), 505–517. doi:10.1109/TNSE.2024.3503904
-
[37]
Lukasz Golab. 2009.Stream Models. Springer US, Boston, MA, 2834–2836. doi:10. 1007/978-0-387-39940-9_370
work page 2009
-
[38]
Michael Greenwald and Sanjeev Khanna. 2001. Space-efficient online compu- tation of quantile summaries. InProceedings of the 2001 ACM SIGMOD Inter- national Conference on Management of Data(Santa Barbara, California, USA) (SIGMOD ’01). Association for Computing Machinery, New York, NY, USA, 58–66. doi:10.1145/375663.375670
-
[39]
Yu Gu, Andrew McCallum, and Don Towsley. 2005. Detecting anomalies in network traffic using maximum entropy estimation. InProceedings of the 5th ACM SIGCOMM Conference on Internet Measurement(Berkeley, CA)(IMC ’05). USENIX Association, USA, 32
work page 2005
-
[40]
Mike Heddes, Igor Nunes, Tony Givargis, and Alex Nicolau. 2024. Convolution and Cross-Correlation of Count Sketches Enables Fast Cardinality Estimation of Multi-Join Queries.Proc. ACM Manag. Data2, 3, Article 129 (May 2024), 26 pages. doi:10.1145/3654932
-
[41]
Thomas Holterbach, Edgar Costa Molero, Maria Apostolaki, Alberto Dainotti, Stefano Vissicchio, and Laurent Vanbever. 2019. Blink: fast connectivity recov- ery entirely in the data plane. InProceedings of the 16th USENIX Conference on Networked Systems Design and Implementation(Boston, MA, USA)(NSDI’19). USENIX Association, USA, 161–176
work page 2019
-
[42]
William George Horner. 1819. IX. A new method of solving numerical equations of all orders, by continuous approximation.Philosophical Transactions of the Royal Society of London109 (1819), 308–335
-
[43]
2023.Query Optimization using Sketches in Relational Database Systems
Yesdaulet Izenov. 2023.Query Optimization using Sketches in Relational Database Systems. PhD thesis. University of California, Merced, Merced, CA. Available at https://escholarship.org/uc/item/5k8334fs
work page 2023
-
[44]
Yesdaulet Izenov, Asoke Datta, Florin Rusu, and Jun Hyung Shin. 2021. COM- PASS: Online Sketch-based Query Optimization for In-Memory Databases. InProceedings of the 2021 International Conference on Management of Data (Virtual Event, China)(SIGMOD ’21). ACM, New York, NY, USA, 804–816. doi:10.1145/3448016.3452840
-
[45]
J. L. W. V. Jensen. 1906. Sur les fonctions convexes et les inégalités entre les valeurs moyennes.Acta Mathematica30 (1906), 175–193. doi:10.1007/bf02418571
-
[46]
Hossein Jowhari, Mert Sağlam, and Gábor Tardos. 2011. Tight bounds for Lp samplers, finding duplicates in streams, and related problems. InProceedings of the Thirtieth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems(Athens, Greece)(PODS ’11). Association for Computing Machinery, New York, NY, USA, 49–58. doi:10.1145/1989284.1989289
-
[47]
Jonathan Kaldor, Jonathan Mace, Michał Bejda, Edison Gao, Wiktor Kuropatwa, Joe O’Neill, Kian Win Ong, Bill Schaller, Pingjia Shan, Brendan Viscomi, Vinod Venkataraman, Kaushik Veeraraghavan, and Yee Jiun Song. 2017. Canopy: An End-to-End Performance Tracing And Analysis System. InProceedings of the 26th Symposium on Operating Systems Principles(Shanghai,...
-
[48]
Zohar S. Karnin, Kevin J. Lang, and Edo Liberty. 2016. Optimal Quantile Approxi- mation in Streams.2016 IEEE 57th Annual Symposium on Foundations of Computer Science (FOCS)(2016), 71–78. https://api.semanticscholar.org/CorpusID:15640305
work page 2016
-
[49]
Matti Karppa and Rasmus Pagh. 2022. HyperLogLogLog: Cardinality Estima- tion With One Log More. InProceedings of the 28th ACM SIGKDD Confer- ence on Knowledge Discovery and Data Mining(Washington DC, USA)(KDD ’22). Association for Computing Machinery, New York, NY, USA, 753–761. doi:10.1145/3534678.3539246
-
[50]
The kernel development community. 2024. 5-level paging. Linux Kernel Documen- tation. https://docs.kernel.org/arch/x86/x86_64/5level-paging.html Accessed: 2026-01-19. Accepted to SIGMOD 2026 Sublime: Sublinear Error & Space for Unbounded Skewed Streams Conference’17, July 2017, Washington, DC, USA
work page 2024
-
[51]
Martin Kiefer, Ilias Poulakis, Eleni Tzirita Zacharatou, and Volker Markl. 2023. Optimistic Data Parallelism for FPGA-Accelerated Sketching.Proc. VLDB Endow. 16, 5 (Jan. 2023), 1113–1125. doi:10.14778/3579075.3579085
-
[52]
Hyuhng Min Kim, Navid Eslami, and Niv Dayan. 2026. Zeno Filter: To Infinity in Tiny Steps. InProceedings of the 2026 International Conference on Management of Data(Bangalore, India)(SIGMOD ’26). ACM, New York, NY, USA, 24 pages
work page 2026
-
[53]
Donald E. Knuth. 1997.The Art of Computer Programming, Volume 2 (3rd Ed.): Seminumerical Algorithms. Addison-Wesley Professional, USA
work page 1997
-
[54]
George Kollios, John Byers, Jeffrey Considine, Marios Hadjieleftheriou, and Feifei Li. 2005. Robust Aggregation in Sensor Networks.Bulletin of the IEEE Computer Society Technical Committee on Data Engineering(2005). https://www2.cs.arizona. edu/classes/cs645/fall05/cs645-papers/DataAggregation/dataC.pdf Special Issue on Data Management in Sensor Networks
work page 2005
-
[55]
Balachander Krishnamurthy, Subhabrata Sen, Yin Zhang, and Yan Chen. 2003. Sketch-based change detection: methods, evaluation, and applications. InPro- ceedings of the 3rd ACM SIGCOMM Conference on Internet Measurement(Miami Beach, FL, USA)(IMC ’03). ACM, New York, NY, USA, 234–247. doi:10.1145/ 948205.948236
-
[56]
Florian Kurpicz. 2022. Engineering Compact Data Structures for Rank and Select Queries on Bit Vectors. InString Processing and Information Retrieval – 29th International Symposium, SPIRE 2022, Concepción, Chile, November 8–10, 2022, Proceedings. Ed.: D. Arroyuelo (Lecture Notes in Computer Science, Vol. 13617). Springer International Publishing, 257–272. ...
-
[57]
2025.DataSketches: A Java software library of stochastic streaming algorithms
Rhodes Lee, Alaxander Lang, Kevin Saydakov, Justin Thaler, Edo Liberty, and Jon Malkin. 2025.DataSketches: A Java software library of stochastic streaming algorithms. https://datasketches.apache.org/
work page 2025
-
[58]
Haoyu Li, Qizhi Chen, Yixin Zhang, Tong Yang, and Bin Cui. 2022. Stingy sketch: a sketch framework for accurate and fast frequency estimation.Proc. VLDB Endow.15, 7 (March 2022), 1426–1438. doi:10.14778/3523210.3523220
-
[59]
Jizhou Li, Zikun Li, Yifei Xu, Shiqi Jiang, Tong Yang, Bin Cui, Yafei Dai, and Gong Zhang. 2020. WavingSketch: An Unbiased and Generic Sketch for Finding Top-k Items in Data Streams. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(Virtual Event, CA, USA) (KDD ’20). ACM, New York, NY, USA, 1574–1584. doi:1...
-
[61]
Shangsen Li, Lailong Luo, Deke Guo, Qianzhen Zhang, and Pengtao Fu. 2020. A survey of sketches in traffic measurement: Design, Optimization, Application and Implementation. https://api.semanticscholar.org/CorpusID:236140679
work page 2020
-
[62]
Weihe Li and Paul Patras. 2023. P-Sketch: A Fast and Accurate Sketch for Persistent Item Lookup.IEEE/ACM Trans. Netw.32, 2 (Aug. 2023), 987–1002. doi:10.1109/TNET.2023.3306897
-
[63]
Weihe Li and Paul Patras. 2023. Tight-Sketch: A High-Performance Sketch for Heavy Item-Oriented Data Stream Mining with Limited Memory Size. InPro- ceedings of the 32nd ACM International Conference on Information and Knowledge Management(Birmingham, United Kingdom)(CIKM ’23). ACM, New York, NY, USA, 1328–1337. doi:10.1145/3583780.3615080
-
[64]
Zirui Liu, Yixin Zhang, Yifan Zhu, Ruwen Zhang, Tong Yang, Kun Xie, Sha Wang, Tao Li, and Bin Cui. 2023. TreeSensing: Linearly Compressing Sketches with Flexibility.Proc. ACM Manag. Data1, 1, Article 56 (May 2023), 28 pages. doi:10.1145/3588910
-
[65]
Claudio Lucchese, Salvatore Orlando, Raffaele Perego, and Fabrizio Silvestri. 2012. Frequent Itemset Mining Dataset Repository, Webdocs. http://fimi.uantwerpen. be/data/
work page 2012
-
[66]
Aleksander Łukasiewicz, Jakub Tětek, and Pavel Veselý. 2025. SplineSketch: Even More Accurate Quantiles with Error Guarantees.Proc. ACM Manag. Data3, 6, Article 362 (Dec. 2025), 26 pages. doi:10.1145/3769827
-
[67]
2025.Algorithms and data structures for massive datasets
Dzejla Medjedovic, Emin Tahirovic, and Ines Dedovic. 2025.Algorithms and data structures for massive datasets. Manning Publications Co., Chapter 4
work page 2025
-
[68]
Ahmed Metwally, Divyakant Agrawal, and Amr El Abbadi. 2005. Efficient com- putation of frequent and top-k elements in data streams. InProceedings of the 10th International Conference on Database Theory(Edinburgh, UK)(ICDT’05). Springer-Verlag, Berlin, Heidelberg, 398–412. doi:10.1007/978-3-540-30570-5_27
-
[69]
1982.Finding Repeated Elements
Jayadev Misra and David Gries. 1982.Finding Repeated Elements. Technical Report. USA
work page 1982
-
[70]
Daisuke Okanohara and Kunihiko Sadakane. 2007. Practical entropy-compressed rank/select dictionary. InProceedings of the Meeting on Algorithm Engineering & Expermiments(New Orleans, Louisiana). Society for Industrial and Applied Mathematics, USA, 60–70
work page 2007
-
[71]
Rasmus Pagh, Gil Segev, and Udi Wieder. 2013. How to Approximate a Set without Knowing Its Size in Advance.2013 IEEE 54th Annual Symposium on Foundations of Computer Science(2013), 80–89. https://api.semanticscholar.org/CorpusID: 10365891
work page 2013
-
[72]
Bender, Rob Johnson, and Rob Patro
Prashant Pandey, Michael A. Bender, Rob Johnson, and Rob Patro. 2017. A General-Purpose Counting Filter: Making Every Bit Count. InProceedings of the 2017 ACM International Conference on Management of Data(Chicago, Illinois, USA) (SIGMOD ’17). ACM, New York, NY, USA, 775–787. doi:10.1145/3035918.3035963
-
[73]
Prashant Pandey, Martín Farach-Colton, Niv Dayan, and Huanchen Zhang. 2024. Beyond Bloom: A Tutorial on Future Feature-Rich Filters. InCompanion of the 2024 International Conference on Management of Data(Santiago AA, Chile) (SIGMOD/PODS ’24). ACM, New York, NY, USA, 636–644. doi:10.1145/3626246. 3654681
-
[74]
Mihai Patrascu. 2008. Succincter. InProceedings of the 2008 49th Annual IEEE Sym- posium on Foundations of Computer Science (FOCS ’08). IEEE Computer Society, USA, 305–313. doi:10.1109/FOCS.2008.83
-
[75]
2023.Insights from Engineering Sketches for Production and Using Sketches at Scale
Lee Rhodes. 2023.Insights from Engineering Sketches for Production and Using Sketches at Scale. https://simons.berkeley.edu/talks/lee-rhodes-yahoo-inc-2023- 10-12
work page 2023
-
[76]
Arik Rinberg, Alexander Spiegelman, Edward Bortnikov, Eshcar Hillel, Idit Keidar, Lee Rhodes, and Hadar Serviansky. 2022. Fast Concurrent Data Sketches.ACM Trans. Parallel Comput.9, 2, Article 6 (April 2022), 35 pages. doi:10.1145/3512758
-
[77]
Pratanu Roy, Arijit Khan, and Gustavo Alonso. 2016. Augmented Sketch: Faster and More Accurate Stream Processing. InProceedings of the 2016 International Conference on Management of Data(San Francisco, California, USA)(SIGMOD ’16). ACM, New York, NY, USA, 1449–1463. doi:10.1145/2882903.2882948
-
[78]
Simon Scherrer, Che-Yu Wu, Yu-Hsi Chiang, Benjamin Rothenberger, Daniele Asoni, Arish Sateesan, Jo Vliegen, Nele Mentens, Hsu-Chun Hsiao, and Adrian Perrig. 2021. Low-Rate Overuse Flow Tracer (LOFT): An Efficient and Scalable Algorithm for Detecting Overuse Flows. 265–276. doi:10.1109/SRDS53918.2021. 00034
-
[79]
Qilong Shi, Chengjun Jia, Wenjun Li, Zaoxing Liu, Tong Yang, Jianan Ji, Gaogang Xie, Weizhe Zhang, and Minlan Yu. 2024. BitMatcher: Bit-level Counter Adjust- ment for Sketches. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 4815–4827. doi:10.1109/ICDE60146.2024.00366
-
[80]
Yoshihiro Shibuya, Djamal Belazzougui, and Gregory Kucherov
-
[81]
Set-Min sketch: a probabilistic map for power-law distri- butions with application to k-mer annotation.bioRxiv(2021). arXiv:https://www.biorxiv.org/content/early/2021/02/25/2020.11.14.382713.full.pdf doi:10.1101/2020.11.14.382713
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.