A Synthesizable RTL Implementation of Predictive Coding Networks
Pith reviewed 2026-05-15 09:23 UTC · model grok-4.3
The pith
A synthesizable RTL design executes predictive coding learning dynamics directly in hardware using only local layer updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
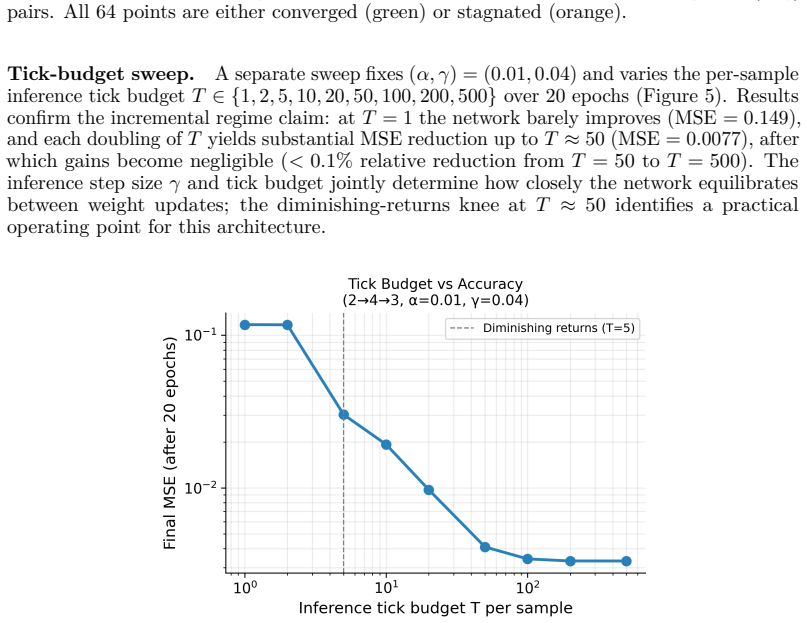
The central claim is a deterministic, synthesizable RTL architecture that directly implements discrete-time predictive coding updates. Each neural core maintains activity, prediction error, and synaptic weights and communicates solely with neighboring layers. Supervised learning and inference are realized by a uniform per-neuron clamping primitive that sets boundary conditions while leaving the fixed local update schedule unchanged. The design uses a sequential MAC datapath and finite-state controller so the hardware evolves under local prediction-error dynamics with task structure supplied externally through wiring and parameters.
What carries the argument
Per-neuron neural core that performs local prediction-error dynamics through a sequential MAC datapath and fixed finite-state schedule, controlled by a uniform clamping primitive for boundaries.
If this is right
- Local per-core updates remove the requirement for centralized memory traffic and global error propagation that backpropagation demands.
- The same hardware substrate performs both inference and learning phases without any change to its internal schedule.
- Replicating identical cores with hardwired inter-layer links produces larger networks while preserving the fixed local rule set.
- Different tasks can be realized on identical hardware simply by changing connectivity patterns and boundary clamping values.
- No program counter or instruction fetch is required inside the learning substrate because behavior is encoded in parameters and wiring.
Where Pith is reading between the lines
- Such an architecture could lower energy use in edge devices by eliminating the data movement costs typical of backpropagation implementations.
- The fixed schedule opens the possibility of very low-power ASIC realizations where timing is fully deterministic.
- Extending the design to asynchronous handshakes between layers could relax the strict synchronous assumption while retaining local dynamics.
- Direct hardware measurement of convergence speed versus software floating-point versions would test whether the discrete mapping introduces any systematic bias.
Load-bearing premise
The discrete-time predictive coding update equations can be mapped onto a fixed finite-state schedule and sequential MAC datapath without losing the essential local dynamics or needing extra global coordination.
What would settle it
Synthesize the RTL to an FPGA, configure a small two-layer network with known weights, apply identical input clamping, and verify whether the observed hardware weight changes and error signals match a software reference simulation of the same update equations.
Figures






read the original abstract
Backpropagation has enabled modern deep learning but is difficult to realize as an online, fully distributed hardware learning system due to global error propagation, phase separation, and heavy reliance on centralized memory. Predictive coding offers an alternative in which inference and learning arise from local prediction-error dynamics between adjacent layers. This paper presents a digital architecture that implements a discrete-time predictive coding update directly in hardware. Each neural core maintains its own activity, prediction error, and synaptic weights, and communicates only with adjacent layers through hardwired connections. Supervised learning and inference are supported via a uniform per-neuron clamping primitive that enforces boundary conditions while leaving the internal update schedule unchanged. The design is a deterministic, synthesizable RTL substrate built around a sequential MAC datapath and a fixed finite-state schedule. Rather than executing a task-specific instruction sequence inside the learning substrate, the system evolves under fixed local update rules, with task structure imposed through connectivity, parameters, and boundary conditions. The contribution of this work is not a new learning rule, but a complete synthesizable digital substrate that executes predictive-coding learning dynamics directly in hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver a complete synthesizable RTL digital substrate that directly executes discrete-time predictive-coding dynamics in hardware. Each neural core maintains local activity, prediction error, and weights; communication is restricted to hardwired adjacent-layer links; supervised learning and inference are realized by a uniform clamping primitive that leaves the internal fixed finite-state schedule unchanged. The architecture is built around a sequential MAC datapath and a deterministic FSM, with task structure imposed only through connectivity, parameters, and boundary conditions rather than instruction sequences.
Significance. If the mapping from the mathematical PC update rules to the fixed hardware schedule is shown to preserve strictly local dynamics, the work would supply a concrete, synthesizable hardware substrate for distributed online learning that avoids backpropagation’s global error propagation and centralized memory requirements. This would be a useful engineering contribution in the neural-engineering and hardware-ML communities.
major comments (2)
- [Architecture description (throughout)] The central claim that the design constitutes a working synthesizable RTL substrate rests on an unverified implementation. No simulation waveforms, timing diagrams, post-synthesis resource numbers, or functional verification results are presented to confirm that the sequential MAC operations and fixed FSM schedule correctly realize the discrete-time PC equations without introducing ordering or synchronization artifacts.
- [Update schedule and datapath mapping] The weakest assumption—that the discrete-time PC update equations map to a fixed finite-state schedule and sequential MAC datapath while preserving strictly local, per-neuron dynamics—is not demonstrated. The shared clock and global FSM schedule may implicitly enforce layer-wide synchronous updates that are not part of the original local prediction-error rules; no formal equivalence argument or cycle-accurate trace is supplied.
minor comments (1)
- [Notation and primitives] Notation for the clamping primitive and the per-neuron state variables could be made more explicit (e.g., by adding a small table relating mathematical symbols to RTL signals).
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential engineering contribution of a synthesizable RTL substrate for predictive coding. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Architecture description (throughout)] The central claim that the design constitutes a working synthesizable RTL substrate rests on an unverified implementation. No simulation waveforms, timing diagrams, post-synthesis resource numbers, or functional verification results are presented to confirm that the sequential MAC operations and fixed FSM schedule correctly realize the discrete-time PC equations without introducing ordering or synchronization artifacts.
Authors: We agree that the absence of explicit verification artifacts weakens the central claim. The current manuscript provides a detailed architectural description and RTL-level mapping but does not include simulation or synthesis results. In the revised version we will add post-synthesis resource numbers for a standard FPGA target, timing diagrams of the FSM schedule, and cycle-accurate simulation waveforms that confirm the sequential MAC operations realize the discrete-time PC equations without ordering or synchronization artifacts. revision: yes
-
Referee: [Update schedule and datapath mapping] The weakest assumption—that the discrete-time PC update equations map to a fixed finite-state schedule and sequential MAC datapath while preserving strictly local, per-neuron dynamics—is not demonstrated. The shared clock and global FSM schedule may implicitly enforce layer-wide synchronous updates that are not part of the original local prediction-error rules; no formal equivalence argument or cycle-accurate trace is supplied.
Authors: Each neural core updates its activity, error, and weights using only locally stored values and hardwired signals from adjacent layers; the global FSM merely sequences these local operations in an order that matches the discrete-time PC equations (error computation precedes weight update within the same time step). The shared clock does not propagate non-local information beyond the intended adjacent-layer connectivity. In the revision we will supply a formal mapping from each PC update rule to specific FSM states together with cycle-accurate execution traces demonstrating preservation of per-neuron locality. revision: yes
Circularity Check
No circularity: implementation paper maps existing equations to RTL without self-referential derivation
full rationale
The paper describes a synthesizable RTL hardware substrate for executing pre-existing discrete-time predictive coding update rules. No mathematical result is derived from fitted parameters, no self-citation chain is load-bearing for a uniqueness claim, and no ansatz or renaming is presented as a new prediction. The central contribution is the mapping to a fixed FSM and sequential MAC datapath, whose correctness is assessed against standard digital design rules rather than reducing to the paper's own outputs by construction. The provided abstract and reader's summary contain no equations or citations that exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard RTL synthesis and timing closure rules apply to the sequential MAC datapath and finite-state schedule.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The design is a deterministic, synthesizable RTL substrate built around a sequential MAC datapath and a fixed finite-state schedule... Each tick performs one explicit Euler-style state update together with one local synaptic update.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and 8-tick period forcing unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The architecture implements a tick-based discrete-time variant... FSM stages: PRED→ERR→BACKSUM→BACKVEC→WUP→STATE
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mike Davies, Narayan Srinivasa, Tsung-Han Lin, Gautham N. Chinya, Yongqiang Cao, Sri Harsha Choday, Georgios Dimou, Prasad Joshi, Nabil Imam, Shweta Jain, Yuyun Liao, Chit-Kwan Lin, Andrew Lines, Ruokun Liu, Deepak Mathaikutty, Steven McCoy, Arnab Paul, Jonathan Tse, Guruguhanathan Venkataramanan, Yi-Hsin Weng, Andreas Wild, Yoonseok Yang, and Hong Wang. ...
work page 2018
-
[2]
Karl Friston. A theory of cortical responses.Philosophical transactions of the Royal Society B: Biological sciences, 360(1456):815–836, 2005
work page 2005
-
[3]
Karl Friston. The free-energy principle: a rough guide to the brain?Trends in cognitive sciences, 13(7):293–301, 2009
work page 2009
-
[4]
TheSpiNNaker project.Proceedings of the IEEE, 102(5):652–665, 2014
StephenB.Furber, FrancescoGalluppi, SteveTemple, andLuisA.Plana. TheSpiNNaker project.Proceedings of the IEEE, 102(5):652–665, 2014
work page 2014
-
[5]
The forward-forward algorithm: Some preliminary investigations
Geoffrey Hinton. The forward-forward algorithm: Some preliminary investigations. arXiv preprint arXiv:2212.13345, 2022
-
[6]
Belhal Karimi, Hoi-To Wai, Eric Moulines, and Marc Lavielle. On the global con- vergence of (fast) incremental expectation maximization methods.arXiv preprint arXiv:1910.12521, 2019
-
[7]
Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
Timothy P Lillicrap, Adam Santoro, Luke Marris, Colin J Akerman, and Geoffrey E Hinton. Backpropagation and the brain.Nature Reviews Neuroscience, 21(6):335–346, 2020
work page 2020
-
[8]
Moravec.Mind Children: The Future of Robot and Human Intelligence
Hans P. Moravec.Mind Children: The Future of Robot and Human Intelligence. Harvard University Press, Cambridge, MA, 1988
work page 1988
-
[9]
Radford M Neal and Geoffrey E Hinton. A view of the em algorithm that justifies incremental, sparse, and other variants.Learning in graphical models, pages 355–368, 1998
work page 1998
-
[10]
Rajesh PN Rao and Dana H Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature neuroscience, 2(1):79– 87, 1999
work page 1999
-
[11]
Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.Nature, 323(6088):533–536, 1986
work page 1986
-
[12]
Tommaso Salvatori, Yuhang Song, Yordan Yordanov, Beren Millidge, Zhenghua Xu, Lei Sha, Cornelius Emde, Rafal Bogacz, and Thomas Lukasiewicz. A stable, fast, and fully automatic learning algorithm for predictive coding networks.arXiv preprint arXiv:2212.00720, 2023
-
[13]
Sebastian Schmitt, Johann Klähn, Guillaume Bellec, Andreas Grübl, Maurice Guettler, Andreas Hartel, Stephan Hartmann, Dan Husmann de Oliveira, Kai Husmann, Vitali Karasenko, Mitja Kleider, Christoph Koke, Christian Mauch, Eric Müller, Paul Müller, Johannes Partzsch, Mihai A. Petrovici, Stefan Schiefer, Stefan Scholze, Bernhard Vogginger, Robert Legenstein...
work page 2017
-
[14]
James C. R. Whittington and Rafal Bogacz. An approximation of the error backpropa- gation algorithm in a predictive coding network with local hebbian synaptic plasticity. Neural Computation, 29(6):1229–1262, 2017. 16
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.