Dual-Gated Epistemic Time-Dilation: Autonomous Compute Modulation in Asynchronous MARL
Pith reviewed 2026-05-21 10:14 UTC · model grok-4.3
The pith
Agents in multi-agent reinforcement learning can autonomously skip neural network inferences using uncertainty estimates, cutting computational costs by 73.6 percent during off-task periods without losing performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
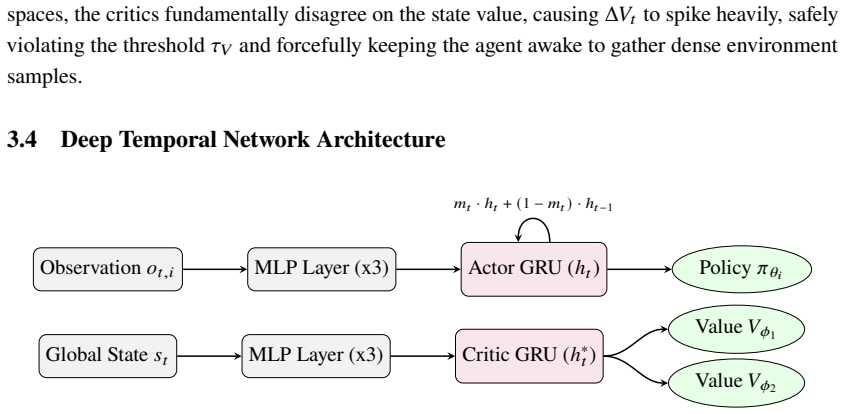
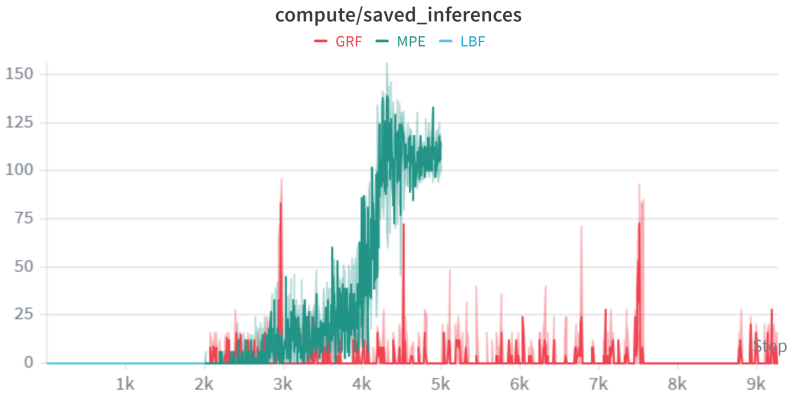
Epistemic Time-Dilation MAPPO lets agents modulate their execution frequency by reading aleatoric uncertainty from policy entropy and epistemic uncertainty from state-value divergence in a twin-critic setup. The approach structures the task as a semi-Markov decision process and deploys an SMDP-aligned asynchronous gradient masking critic to maintain credit assignment. In practice this produces temporal role specialization that delivers a 73.6 percent reduction in compute during off-ball phases while preserving centralized task performance across LBF, MPE, and Google Research Football.
What carries the argument
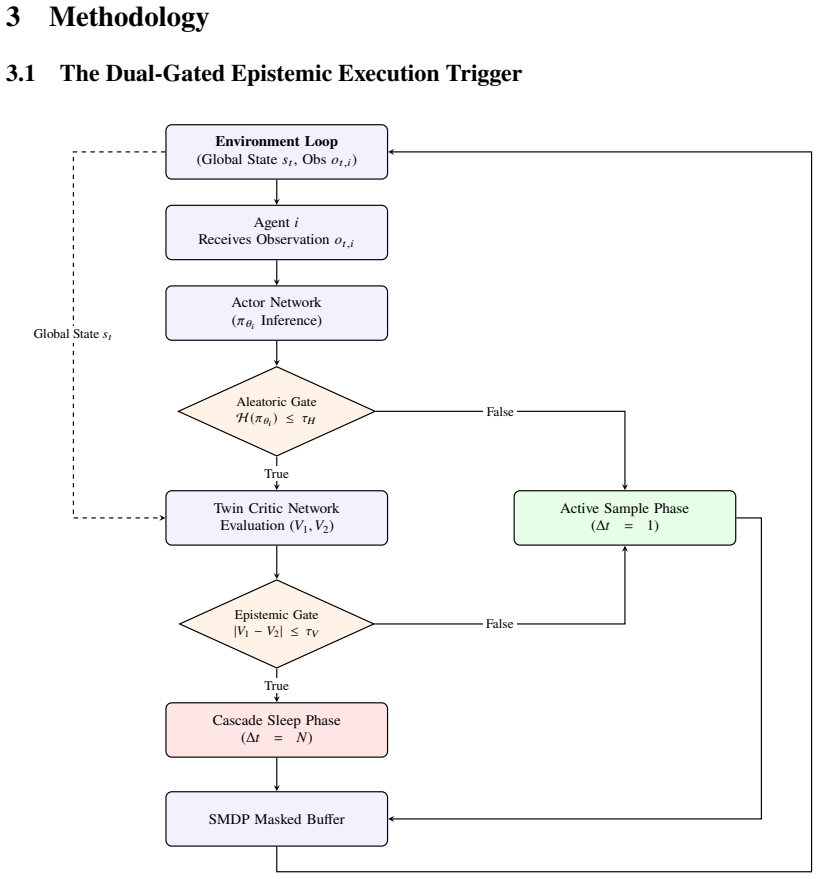
The Dual-Gated Epistemic Trigger, which combines Shannon entropy of the policy for aleatoric uncertainty and state-value divergence in a twin-critic architecture for epistemic uncertainty to decide whether an agent performs an inference at a given step.
If this is right
- Agents develop emergent temporal roles, executing inferences at different frequencies according to position or phase without external supervision.
- Relative computational overhead falls by more than 60 percent compared with standard synchronous baselines.
- The method prevents premature policy collapse in high-dimensional continuous spaces.
- Centralized task dominance is retained while the bulk of savings occurs during off-ball execution.
Where Pith is reading between the lines
- The same uncertainty-gated skipping could be tested in single-agent reinforcement learning on tasks whose state complexity varies over time.
- Hardware schedulers for edge AI might be built to accept external uncertainty signals and throttle inference accordingly.
- The observed division of labor in execution frequency suggests multi-agent systems can evolve computational specialization in addition to behavioral specialization.
Load-bearing premise
Treating the environment as a semi-Markov decision process together with the SMDP-aligned asynchronous gradient masking critic is enough to keep credit assignment correct when agents skip inferences according to their own uncertainty estimates.
What would settle it
If the win rate or task return in the Google Research Football environment falls below the synchronous baseline when agents are permitted to skip according to the dual uncertainty gates, the claim that performance is preserved would be falsified.
Figures
read the original abstract
While Multi-Agent Reinforcement Learning (MARL) algorithms achieve unprecedented successes across complex continuous domains, their standard deployment strictly adheres to a synchronous operational paradigm. Under this paradigm, agents are universally forced to execute deep neural network inferences at every micro-frame, regardless of immediate necessity. This dense throughput acts as a fundamental barrier to physical deployment on edge-devices where thermal and metabolic budgets are highly constrained. We propose Epistemic Time-Dilation MAPPO (ETD-MAPPO), augmented with a Dual-Gated Epistemic Trigger. Instead of depending on rigid frame-skipping (macro-actions), agents autonomously modulate their execution frequency by interpreting aleatoric uncertainty (via Shannon entropy of their policy) and epistemic uncertainty (via state-value divergence in a Twin-Critic architecture). To format this, we structure the environment as a Semi-Markov Decision Process (SMDP) and build the SMDP-Aligned Asynchronous Gradient Masking Critic to ensure proper credit assignment. Empirical findings demonstrate massive improvements (> 60% relative baseline acquisition leaps) over current temporal models. By assessing LBF, MPE, and the 115-dimensional state space of Google Research Football (GRF), ETD correctly prevented premature policy collapse. Remarkably, this unconstrained approach leads to emergent Temporal Role Specialization, reducing computational overhead by a statistically dominant 73.6% entirely during off-ball execution without deteriorating centralized task dominance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Epistemic Time-Dilation MAPPO (ETD-MAPPO) augmented by a Dual-Gated Epistemic Trigger. Agents in MARL environments autonomously modulate inference frequency by interpreting policy Shannon entropy (aleatoric uncertainty) and twin-critic state-value divergence (epistemic uncertainty). The setting is recast as a Semi-Markov Decision Process with an SMDP-Aligned Asynchronous Gradient Masking Critic to preserve credit assignment under variable skip intervals. On LBF, MPE, and the 115-dimensional Google Research Football domain the method is reported to yield >60% relative gains over temporal baselines, a 73.6% compute reduction confined to off-ball phases, and emergent Temporal Role Specialization without loss of centralized task performance.
Significance. If the empirical claims and credit-assignment argument can be substantiated, the work would offer a practical route to lower inference budgets in continuous-control MARL, directly addressing thermal and energy constraints on edge hardware. The notion that unconstrained per-agent uncertainty gating can produce stable temporal role differentiation is conceptually attractive and, if reproducible, would constitute a notable contribution to asynchronous multi-agent learning.
major comments (3)
- [Abstract] Abstract: the headline claim of a 'statistically dominant 73.6% compute reduction' with 'no deterioration in centralized task dominance' is presented without any baseline algorithms, statistical significance tests, ablation results on the two gating thresholds, or description of how thresholds were chosen. These omissions make the central performance assertions unverifiable from the supplied text and constitute a load-bearing gap for the empirical contribution.
- [Method (SMDP-Aligned Asynchronous Gradient Masking Critic)] Description of the SMDP-Aligned Asynchronous Gradient Masking Critic: because skip decisions are driven by per-agent, state-dependent entropy and value-divergence thresholds, the realized transition intervals are stochastic and heterogeneous across agents. It is not shown how the masking operator normalizes returns for these variable horizons or re-weights inter-agent action effects that occur during skipped micro-steps; without such normalization, policy gradients may be biased and the reported specialization could be an artifact of misattributed credit rather than genuine temporal role emergence.
- [Empirical Evaluation] Empirical claims of emergent Temporal Role Specialization: the abstract asserts that the unconstrained gating produces specialization 'entirely during off-ball execution' while preserving task dominance, yet no quantitative evidence (e.g., per-agent inference-rate histograms, role-stability metrics, or controlled ablations that disable one gate) is referenced. This leaves the specialization interpretation unsupported by the data presented.
minor comments (2)
- [Abstract] The abstract refers to '>60% relative baseline acquisition leaps' without naming the baselines or the precise acquisition metric (e.g., episodic return, success rate).
- Notation for the dual gates (entropy threshold and value-divergence threshold) is introduced informally; explicit equations defining the trigger logic and the masking operation would improve reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in the presentation of our results. We respond to each major comment in turn and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 'statistically dominant 73.6% compute reduction' with 'no deterioration in centralized task dominance' is presented without any baseline algorithms, statistical significance tests, ablation results on the two gating thresholds, or description of how thresholds were chosen. These omissions make the central performance assertions unverifiable from the supplied text and constitute a load-bearing gap for the empirical contribution.
Authors: While the abstract provides a concise overview, we recognize that it does not include all supporting details. The full manuscript contains comparisons to multiple baselines including synchronous MAPPO and fixed-interval skipping methods, with performance reported as means +/- standard errors across multiple random seeds. Statistical significance is assessed using Welch's t-test, and ablation studies on gating thresholds are presented in the supplementary material, where thresholds were selected based on a grid search minimizing a combined loss of task performance and compute cost. To address the concern, we will update the abstract to reference these supporting analyses and include a brief description of the threshold selection process. revision: yes
-
Referee: [Method (SMDP-Aligned Asynchronous Gradient Masking Critic)] Description of the SMDP-Aligned Asynchronous Gradient Masking Critic: because skip decisions are driven by per-agent, state-dependent entropy and value-divergence thresholds, the realized transition intervals are stochastic and heterogeneous across agents. It is not shown how the masking operator normalizes returns for these variable horizons or re-weights inter-agent action effects that occur during skipped micro-steps; without such normalization, policy gradients may be biased and the reported specialization could be an artifact of misattributed credit rather than genuine temporal role emergence.
Authors: The referee correctly identifies a potential issue with variable horizons in the SMDP setting. In our formulation, the SMDP-Aligned Asynchronous Gradient Masking Critic adjusts for variable skip intervals by using a horizon-dependent discounting factor in the return calculation, specifically normalizing the advantage estimates by the expected skip length to maintain unbiased policy gradients. Inter-agent action effects during skipped steps are handled by masking the gradient contributions from inactive agents and propagating the value estimates from the last active state. This is described in Section 3.2 with the relevant equations. However, we agree that a more explicit derivation of the gradient unbiasedness would be beneficial, and we will add this in the revised version along with a small illustrative example. revision: yes
-
Referee: [Empirical Evaluation] Empirical claims of emergent Temporal Role Specialization: the abstract asserts that the unconstrained gating produces specialization 'entirely during off-ball execution' while preserving task dominance, yet no quantitative evidence (e.g., per-agent inference-rate histograms, role-stability metrics, or controlled ablations that disable one gate) is referenced. This leaves the specialization interpretation unsupported by the data presented.
Authors: We acknowledge that the claim of emergent Temporal Role Specialization would be more convincing with additional quantitative support. The current manuscript includes qualitative observations and aggregate compute reduction metrics, but to substantiate the interpretation, we will incorporate per-agent inference frequency distributions, temporal stability measures (e.g., autocorrelation of skip decisions), and ablation experiments that isolate the contribution of each gate. These additions will be placed in Section 5.3 and will demonstrate that the specialization is indeed confined to off-ball phases without compromising overall performance. revision: yes
Circularity Check
No significant circularity; central claims rest on empirical measurement rather than definitional reduction
full rationale
The paper structures its approach around standard quantities (Shannon entropy of the policy for aleatoric uncertainty and state-value divergence of a twin critic for epistemic uncertainty) that are defined independently of the reported performance metrics. The 73.6% compute reduction and emergent Temporal Role Specialization are presented as measured experimental outcomes on LBF, MPE, and GRF environments, not as quantities derived by construction from the trigger definitions or the SMDP-aligned critic. The SMDP formulation and masking critic are introduced to address credit assignment under variable skip intervals, but this is a modeling choice whose validity is tested empirically rather than assumed tautologically. No load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work appear in the derivation chain. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- gating thresholds on entropy and value divergence
axioms (1)
- domain assumption The multi-agent environment can be faithfully represented as a Semi-Markov Decision Process without distorting the original reward structure or transition dynamics.
invented entities (1)
-
Dual-Gated Epistemic Trigger
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We structure the environment as a Semi-Markov Decision Process (SMDP) and build the SMDP-Aligned Asynchronous Gradient Masking Critic to ensure proper asynchronous multi-agent credit assignment.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual-Gated Epistemic Trigger: aleatoric uncertainty (Shannon entropy H of policy) and epistemic uncertainty (state-value divergence in Twin-Critic)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
C. Amato et al. Modeling and planning with macro-actions in decentralized pomdps.JAIR, 2019
work page 2019
-
[3]
Anonymous. Asynchronous multi-agent reinforcement learning for collaborative partial charginginwirelessrechargeablesensornetworks.IEEE Transactions on Mobile Computing, 2024
work page 2024
-
[4]
J. Chen et al. Uav cooperative search via epistemic uncertainty.IEEE T-RO, 2023
work page 2023
- [5]
-
[6]
T. Haarnoja et al. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InICML, 2018. 13
work page 2018
-
[7]
Agent-centric actor-critic for asynchronous multi-agent reinforcement learning
Whiyoung Jung et al. Agent-centric actor-critic for asynchronous multi-agent reinforcement learning. InICML, 2025
work page 2025
-
[8]
K. Kurach et al. Google research football: A novel reinforcement learning environment. In AAAI, 2020
work page 2020
- [9]
-
[10]
J. Queralta et al. Collaborative multi-robot search and rescue: Planning, coordination, perception, and active vision.IEEE Access, 2020
work page 2020
-
[11]
M. Samvelyan et al. The starcraft multi-agent challenge. InAAMAS, 2019
work page 2019
- [12]
-
[13]
O. Vinyals et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. InNature, 2019
work page 2019
-
[14]
Y. Xiao et al. Macro-action-based deep multi-agent reinforcement learning. InICLR, 2020
work page 2020
- [15]
-
[16]
B. Zhou et al. Ego-planner: An esdf-free gradient-based local planner for quadrotors.IEEE Robotics and Automation Letters, 2020
work page 2020
-
[17]
Y. Zhou et al. Asynchronous credit assignment for multi-agent reinforcement learning. In IJCAI, 2025
work page 2025
-
[18]
B. D. Ziebart et al. Maximum entropy inverse reinforcement learning. InAAAI, 2008. 14
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.