Recognition: 2 theorem links
· Lean TheoremAIRA₂: Overcoming Bottlenecks in AI Research Agents
Pith reviewed 2026-05-14 23:01 UTC · model grok-4.3
The pith
AIRA₂ overcomes three structural bottlenecks in AI research agents through asynchronous multi-GPU execution, hidden consistent evaluation, and dynamic ReAct agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
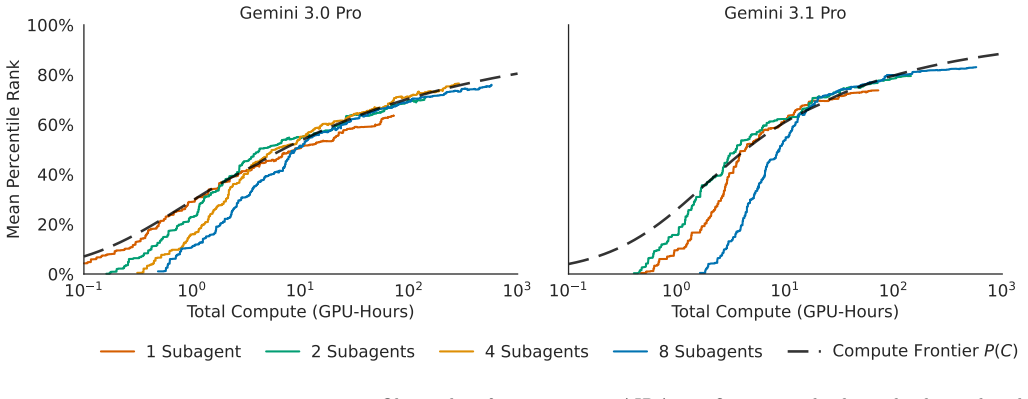
AIRA₂ replaces synchronous single-GPU execution with an asynchronous multi-GPU worker pool, validation-based selection with Hidden Consistent Evaluation, and fixed single-turn LLM operators with ReAct agents that dynamically scope actions and debug interactively, producing mean percentile ranks of 81.5 percent at 24 hours and 83.1 percent at 72 hours on MLE-bench-30 while exceeding human state-of-the-art on six of twenty tasks in AIRS-Bench.
What carries the argument
The AIRA₂ architecture that combines an asynchronous multi-GPU worker pool for linear throughput gains, a Hidden Consistent Evaluation protocol that supplies reliable long-horizon signals, and ReAct agents for adaptive scoping and interactive debugging.
If this is right
- Each of the three components contributes independently to the observed gains.
- Performance follows a predictable scaling law that transfers across different LLM backbones.
- Overfitting reported in earlier agents was produced by evaluation noise rather than data memorization.
- Longer search horizons become usable without the performance drop seen before.
Where Pith is reading between the lines
- The same system-level pattern could be applied to automated discovery tasks outside machine learning.
- Further gains would be expected from adding more GPUs or extending runtime if the scaling law continues to hold.
- The approach reduces reliance on prompt engineering by shifting emphasis to architecture and evaluation design.
- Wider adoption could shorten the time needed for agents to match or exceed human-level results on narrow research problems.
Load-bearing premise
The Hidden Consistent Evaluation protocol supplies a reliable signal that avoids the generalization gap and overfitting previously seen with validation-based selection.
What would settle it
A direct test in which models selected by the Hidden Consistent Evaluation protocol still lose performance on new held-out tasks after 72 hours of search would show that the protocol fails to eliminate the generalization gap.
Figures







read the original abstract
Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes overfitting and performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$^{\dagger}_{2}$ achieves a mean Percentile Rank of 81.5% at 24 hours and 83.1% at 72 hours, outperforming the strongest baseline, which achieves 72.7%. On AIRS-Bench, AIRA$_2$ exceeds human state-of-the-art on 6 out of 20 diverse research tasks. Ablations confirm that each architectural component is necessary, that performance follows a predictable scaling law that transfers across LLM backbones, and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies three bottlenecks in AI research agents—synchronous single-GPU execution limiting throughput, a generalization gap causing overfitting over long horizons, and fixed single-turn LLM operators—and introduces AIRA₂ to address them via asynchronous multi-GPU workers, a Hidden Consistent Evaluation protocol for reliable signals, and ReAct agents for dynamic scoping and debugging. On MLE-bench-30, AIRA†₂ reports mean Percentile Rank of 81.5% at 24 hours and 83.1% at 72 hours (vs. strongest baseline 72.7%); on AIRS-Bench it exceeds human SOTA on 6/20 tasks. Ablations confirm each component is necessary, performance follows a scaling law transferable across LLM backbones, and prior overfitting was evaluation-noise driven rather than memorization.
Significance. If the central claims hold, the work is significant for automated AI research: it demonstrates concrete architectural fixes that yield substantial gains on established benchmarks, with ablations and cross-backbone scaling providing evidence of robustness. The empirical focus on throughput, reliable evaluation, and interactive agents could inform scalable agent designs, particularly given the reported outperformance of baselines and partial surpassing of human SOTA.
major comments (2)
- [§3] Hidden Consistent Evaluation protocol (abstract and §3): the central performance claims on MLE-bench-30 and AIRS-Bench rest on this protocol eliminating the generalization gap and evaluation-noise overfitting. However, no formal definition, pseudocode, or argument is supplied showing that the hidden set remains isolated from search dynamics across asynchronous multi-GPU workers and extended time horizons; without this, ablations cannot reliably separate architectural improvements from an evaluation artifact.
- [§4] §4 (Ablations and scaling): while the manuscript states that ablations confirm necessity of each component and that performance follows a predictable scaling law across LLM backbones, the absence of reported error bars, exact statistical tests, or variance across runs makes it difficult to assess whether the observed improvements are robust or could be explained by evaluation variance.
minor comments (2)
- [Table 1] The time horizons (24h/72h) and exact baseline implementations should be stated more explicitly in the main results table to allow direct reproduction.
- [Abstract] Notation for AIRA†₂ vs. AIRA₂ is used inconsistently between abstract and main text; clarify whether the dagger denotes a specific configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] Hidden Consistent Evaluation protocol (abstract and §3): the central performance claims on MLE-bench-30 and AIRS-Bench rest on this protocol eliminating the generalization gap and evaluation-noise overfitting. However, no formal definition, pseudocode, or argument is supplied showing that the hidden set remains isolated from search dynamics across asynchronous multi-GPU workers and extended time horizons; without this, ablations cannot reliably separate architectural improvements from an evaluation artifact.
Authors: We agree that a more formal specification strengthens the central claims. In the revised manuscript we have added a mathematical definition of the Hidden Consistent Evaluation protocol in §3.1, pseudocode as Algorithm 1, and an extended isolation argument in §3.2. The argument explicitly addresses asynchronous multi-GPU execution by routing all hidden-set evaluations through a dedicated, non-overlapping worker pool with strict read-only access and periodic consistency checks; it further shows that search dynamics cannot leak information to the hidden set even over 72-hour horizons because candidate selection and model updates remain confined to the visible validation partition. These additions allow the ablations to separate architectural gains from evaluation artifacts. revision: yes
-
Referee: [§4] §4 (Ablations and scaling): while the manuscript states that ablations confirm necessity of each component and that performance follows a predictable scaling law across LLM backbones, the absence of reported error bars, exact statistical tests, or variance across runs makes it difficult to assess whether the observed improvements are robust or could be explained by evaluation variance.
Authors: We acknowledge the absence of statistical detail in the original submission. The revised §4 now reports standard deviations across five independent runs for every key metric, includes paired t-test p-values comparing AIRA₂ to each baseline, and tabulates run-to-run variance. These additions confirm that the reported percentile-rank gains, component necessity, and cross-backbone scaling law remain statistically significant and are not attributable to evaluation variance. revision: yes
Circularity Check
No circularity: empirical benchmark claims independent of self-referential derivations
full rationale
The paper's central claims consist of empirical performance numbers on MLE-bench-30 (81.5% at 24h, 83.1% at 72h) and AIRS-Bench (exceeding human SOTA on 6/20 tasks), supported by ablations and an observed scaling law. No equations, uniqueness theorems, or fitted-parameter predictions appear in the abstract or described text that reduce outputs to inputs by construction. The Hidden Consistent Evaluation protocol is presented as an architectural choice whose reliability is asserted via benchmark results rather than proven by self-definition or prior self-citation. Self-citations, if present, are not load-bearing for the performance numbers. The work is therefore self-contained against external benchmarks with no detectable circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal... data splits are standardized once and reused... Dsearch guides optimization while Dval determines final selection.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
P(N, t) = 100·g(N, t)/(g(N, t) + 1), g(N, t) = α·log(γ t + 1)·log(β N + 1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Alexis Audran-Reiss, Jordi Armengol-EstapÊ, Karen Hambardzumyan, Amar Budhiraja, Martin Josifoski, Edan Toledo, Rishi Hazra, Despoina Magka, Michael Shvartsman, Parth Pathak, et al. What does it take to be a good ai research agent? studying the role of ideation diversity.arXiv preprint arXiv:2511.15593,
-
[3]
MLE-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE-bench: Evaluating machine learning agents on machine learning engineering. InThe Thirteenth International Conference on Learning Representations, 2025.https://openreview.net/fo...
-
[4]
Automlgen: Navigating fine-grained optimization for coding agents,
Dalpha Team. CobraAgent: Results on MLE-bench, 2026.https://dalphakr.github.io/CobraAgent/. GitHub PR: https://github.com/openai/mle-bench/pull/129. Company Website:https://dalpha.so/en. Shangheng Du, Xiangchao Yan, Dengyang Jiang, Jiakang Yuan, Yusong Hu, Xin Li, Liang He, Bo Zhang, and Lei Bai. Automlgen: Navigating fine-grained optimization for coding ...
-
[5]
Simple And Efficient Architecture Search for Convolutional Neural Networks
Thomas Elsken, Jan-Hendrik Metzen, and Frank Hutter. Simple and efficient architecture search for convolutional neural networks.arXiv preprint arXiv:1711.04528,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Margraf, and Stephan Günnemann
Johannes Gasteiger, Shankari Giri, Johannes T Margraf, and Stephan Günnemann. Fast and uncertainty-aware directional message passing for non-equilibrium molecules.arXiv preprint arXiv:2011.14115,
-
[7]
Google DeepMind. Gemini 3: Our most intelligent AI model, 2025.https://deepmind.google/models/gemini/. Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Averaging Weights Leads to Wider Optima and Better Generalization
19 Pavel Izmailov, Dmitrii Podoprikhin, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Averaging weights leads to wider optima and better generalization.arXiv preprint arXiv:1803.05407,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Aide: Ai-driven exploration in the space of code,
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code.arXiv preprint arXiv:2502.13138,
-
[11]
Flows: Building blocks of reasoning and collaborating ai.arXiv preprint arXiv:2308.01285,
Martin Josifoski, Lars Klein, Maxime Peyrard, Nicolas Baldwin, Yifei Li, Saibo Geng, Julian Paul Schnitzler, Yuxing Yao, Jiheng Wei, Debjit Paul, et al. Flows: Building blocks of reasoning and collaborating ai.arXiv preprint arXiv:2308.01285,
-
[12]
Kurtzer, cclerget, Michael Bauer, Ian Kaneshiro, David Trudgian, and David Godlove
Gregory M. Kurtzer, cclerget, Michael Bauer, Ian Kaneshiro, David Trudgian, and David Godlove. hpcng/singularity: Singularity 3.7.3, April 2021.https://doi.org/10.5281/zenodo.4667718. Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution. InThe Fourteenth International Conference on L...
-
[13]
The fm agent, 2025.https://arxiv.org/abs/2510.26144
Annan Li, Chufan Wu, Zengle Ge, Yee Hin Chong, Zhinan Hou, Lizhe Cao, Cheng Ju, Jianmin Wu, Huaiming Li, Haobo Zhang, Shenghao Feng, Mo Zhao, Fengzhi Qiu, Rui Yang, Mengmeng Zhang, Wenyi Zhu, Yingying Sun, Quan Sun, Shunhao Yan, Danyu Liu, Dawei Yin, and Dou Shen. The fm agent, 2025.https://arxiv.org/abs/2510.26144. Lisha Li, Kevin Jamieson, Giulia DeSalv...
-
[14]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025a. Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Ves...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[15]
Zexi Liu, Yuzhu Cai, Xinyu Zhu, Yujie Zheng, Runkun Chen, Ying Wen, Yanfeng Wang, Weinan E, and Siheng Chen. Ml-master: Towards ai-for-ai via integration of exploration and reasoning, 2025b.https://arxiv.org/abs/2506.16499. Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InProceedings...
-
[16]
Alisia Lupidi, Bhavul Gauri, Thomas Simon Foster, Bassel Al Omari, Despoina Magka, Alberto Pepe, Alexis Audran- Reiss, Muna Aghamelu, Nicolas Baldwin, Lucia Cipolina-Kun, et al. Airs-bench: a suite of tasks for frontier ai research science agents.arXiv preprint arXiv:2602.06855,
-
[17]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, Jinwoo Shin, Sercan O Arik, and Tomas Pfister. MLE-STAR: Machine learning engineering agent via search and targeted refinement. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025.https://openreview.net/forum?id=vS1M06Px6u. Alexander Novikov, Ngân V˜ u, Marvin Eisenberger, Emilien Du...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations, 2020.https: //openreview.net/forum?id=r1ecqn4YwB. Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions f...
work page 2020
-
[19]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Philipp Thölke and Gianni De Fabritiis
Accessed: 2026-02-25. Philipp Thölke and Gianni De Fabritiis. Equivariant transformers for neural network based molecular potentials. In International Conference on Learning Representations, 2022.https://openreview.net/forum?id=zNHzqZ9wrRB. Edan Toledo, Karen Hambardzumyan, Martin Josifoski, RISHI HAZRA, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchn...
work page 2026
-
[21]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
https://openreview.net/forum?id=BAakY1hNKS. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search, 2025.https: //arxiv.org/abs/2504.08066. An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Autonomous code evolution meets np-completeness
Cunxi Yu, Rongjian Liang, Chia-Tung Ho, and Haoxing Ren. Autonomous code evolution meets np-completeness. arXiv preprint arXiv:2509.07367,
-
[23]
Scaling Relationship on Learning Mathematical Reasoning with Large Language Models
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models.arXiv preprint arXiv:2308.01825,
work page internal anchor Pith review arXiv
-
[24]
21 Xinyu Zhu, Yuzhu Cai, Zexi Liu, Bingyang Zheng, Cheng Wang, Rui Ye, Jiaao Chen, Hanrui Wang, Wei-Chen Wang, Yuzhi Zhang, et al. Toward ultra-long-horizon agentic science: Cognitive accumulation for machine learning engineering.arXiv preprint arXiv:2601.10402,
-
[25]
22 Appendix A Evaluation Failure: A Concrete Example To illustrate how implementation bugs can silently corrupt the search signal (Section 2.2), we present a real example from an AI agent solving the LMSYS Chatbot Arena competition on MLE-bench. The agent’s solution reported aperfectcross-validation log-loss of 0.0, which the search process then treated a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.